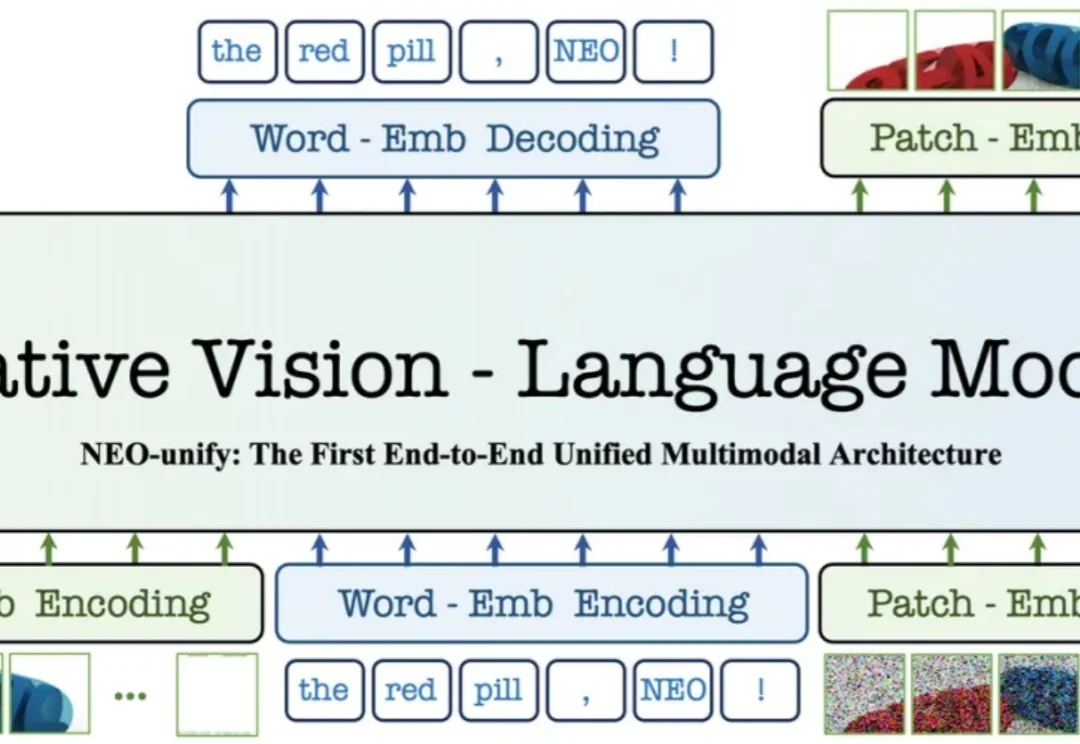
多模态迎来「架构换代」:商汤连出两张牌,划定大一统基座新标准
多模态迎来「架构换代」:商汤连出两张牌,划定大一统基座新标准刚刚结束的 2026 年世界人工智能大会(WAIC) ,具身智能与 AI 终端占据了最显眼的位置,人形机器人、灵巧手和各类智能硬件吸引了大量目光。
来自主题: AI技术研报
7212 点击 2026-07-22 10:08
 搜索
搜索
刚刚结束的 2026 年世界人工智能大会(WAIC) ,具身智能与 AI 终端占据了最显眼的位置,人形机器人、灵巧手和各类智能硬件吸引了大量目光。
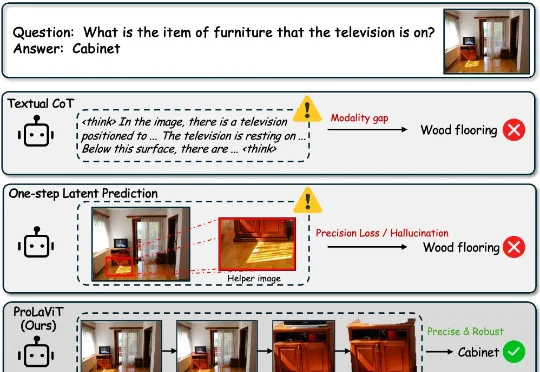
针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。

最近,世界人工智能大会上,中科闻歌磐石 ScienceOne 团队一口气亮出两张王牌:专攻科学场景下深入理解、预测与生成的科学多模态统一推理模型 —— S1-Omni;以 S1-Omni 为基座、贯穿整个科研生命周期的智能化服务平台 —— ScienceOne。

7 月 20 日,Meshy 宣布完成近 4 亿美元 B 轮融资,投后估值超过 100 亿元人民币。这是它成立以来第一次对外公布估值,一出手就刷新了 AI 3D 赛道单轮融资规模与估值两项纪录。据公司披露,这也是全球 AI 3D 领域迄今最高的一个估值。

AI体育赛道今年迎来了一波明星资本的押注。

人工智能(AI)模型在科学发现中的角色,正经历着一场从「工程缝合者」向「智能推演者」的深刻蜕变。

作为WAIC 2026最受关注的论坛,由商汤科技承办的“基座大模型架构创新与生态合作论坛”吸引了无数AI研究者、产业专家和投资机构的目光。因它直面了当前大模型行业最核心的焦虑:当Scaling Law在逼近物理极限,多模态究竟是破局的“解药”,还是新瓶装旧酒的延伸?
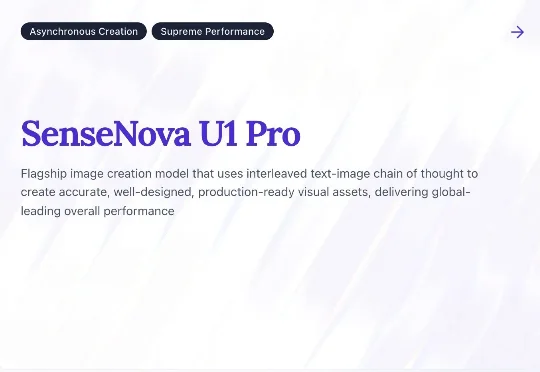
直出8K长卷,中国AI还是首次!就在今天,WAIC大会上,商汤正式发布下一代「满血旗舰」——日日新SenseNova-U1 Pro。 这是业界头一回,把「看懂、生成、动手」原生做进了同一个多模态基座的底层。

Z Potentials获悉,近日,总部位于硅谷与新加坡的Prana Labs正式完成近千万美金种子轮融资,由元生资本、XVC、Creekstone、三七互娱联合投资,澜松资本担任独家财务顾问。 与赛

时至今日,全球大模型格局已成定数,还有必要耗费巨资从零开始训练一个新模型吗?