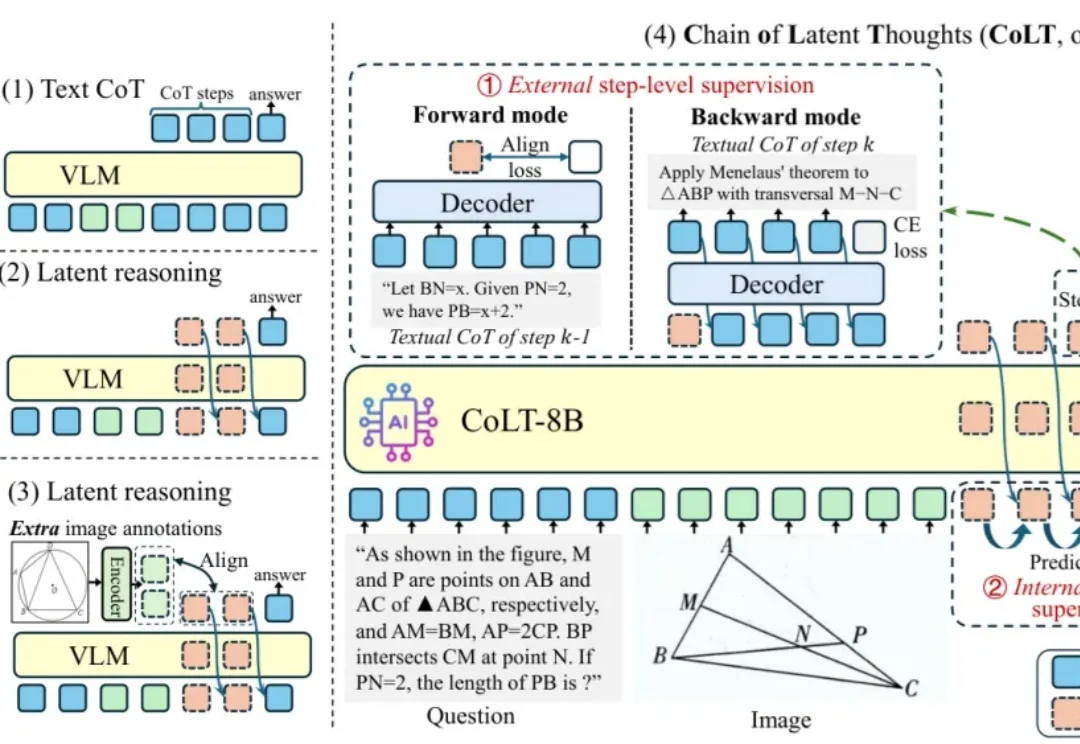
3步推理生成加速20+倍!CoLT教会多模态大模型用「潜思维链」思考
3步推理生成加速20+倍!CoLT教会多模态大模型用「潜思维链」思考近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。
来自主题: AI技术研报
6171 点击 2026-07-15 10:27
 搜索
搜索
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。

浙江大学计算机辅助设计与图形系统全国重点实验室杜鹏团队提出了一个支持多模态输入的CAD建模智能体:CADDesigner。该智能体致力于构建一个中间层,将大模型、智能体与传统几何引擎深度融合,帮助CAD设计师提升模型设计能力和生产效率。
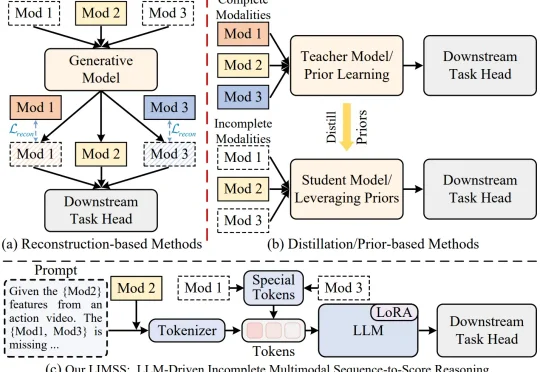
本文是北京大学彭宇新教授团队联合福州大学柯逍教授团队在细粒度多模态动作质量评价领域的最新研究成果,相关论文已被 ICML 2026 接收为 Spotlight,并已开源。真实世界中的多模态数据往往并不完整。在动作质量评价任务中,视频、光流、音频等模态能够从不同角度描述动作执行过程,但在实际采集时,传感器故障、环境噪声、隐私限制等因素都会导致模态缺失。
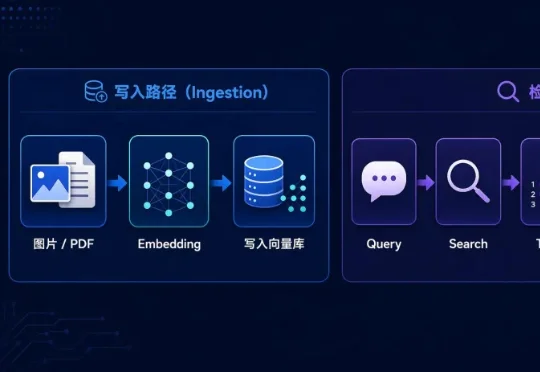
多模态 Agent 的记忆系统,过去很容易被理解成一个升级版 RAG:图片、图表、PDF 进来之后,先抽取内容、做 embedding、写进向量库;用户提问时,再用 query 做检索,把命中的top-k图片、文档页或图表一并塞进上下文,再交给多模态模型回答。整个过程中,所有原始模态信息都会不加选择的塞给大模型。

7月8日晚间,字节跳动Seed团队正式发布多模态图像创作模型Seedream 5.0 Pro。这距离今年2月10日Seedream 5.0预览版上线,已经过去近5个月。相比此前版本,Seedream 5.0 Pro在图文匹配、结构合理性、文字渲染与画面美感等基础能力上进行了升级,并重点强化了四项核心能力
智东西获悉,OpenAI前研究员田永龙(Yonglong Tian)已确认于近期加入腾讯大语言模型部,后续将参与VLM(视觉语言模型)相关研发。在OpenAI期间,田永龙曾参与GPT-5的研发工作。加入OpenAI之前,他在Google Research和DeepMind长期从事视觉表征学习和对比学习等方向研究,对后续视觉模型以及多模态表征学习的发展产生了广泛影响。
针对这一问题,openJiuwen社区正式发布Skill-Omni——业界最早工程化落地的多模态Skill范式。 它让Agent的经验从“读得懂”升级为“看得见”,把网页和视频中的视觉知识,沉淀为Agent可复用的多模态Skill。

乐鑫喵伴 EchoEar EchoEar 喵伴 AI 机器人搭载的 ESP-Brookesia 框架实现全双工语音交互、多模态识别与智能体控制,构建更具沉浸感的人机交互体验。 EchoEar 套件以端

如果是小白第一次上手,我会更建议从 Kimi 开始。Kimi 的中文理解、长文本处理、Coding、多模态综合能力都很强,是最适合 Codex 的国产模型。今天这篇内容,手把手教大家如何将第三方大模型接入 Codex 搞定日常任务。

来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。