# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在过去的几年里,Scaling Law 被整个 AI 行业奉为圭臬。大家普遍认为,模型越大,参数越多,其涌现出的逻辑推理与世界知识就越强。
但大模型的巨额推理成本、不可控的网络延迟以及严苛的数据隐私风险,让真正的 AI 普惠成了一个伪命题。性能、时效、并发,构成了大模型落地时难以逾越的「不可能三角」。
今年是 AI 应用大规模落地的一年,当我们真正审视 AI 普惠的现实需求时,会发现一个反常识的演进趋势:在某些维度上,参数规模更小的模型,反而能爆发出更高的效率与特定场景下的性能优势。
其实早有厂商注意到了端侧落地和云端降本的现实需求,悄悄在 1B(十亿)参数规模以下的端侧模型赛道上开始布局。
有人可能会问,这么小的模型有什么用?
在真实的业务场景里,这些端侧模型正在干着最基础但最实用的活。
它们体积小巧,既能在手机端毫秒级离线运行、严格保护隐私,也能扛住千万级并发下的低延迟意图识别。在 RAG 系统里,充当着智能路由器和数据清洗工,分流闲聊请求、压缩大模型调用成本;配合超大模型推理时,又以投机采样技术将预测速度拉高 2 至 3 倍。更关键的是,在信息提取、格式转换等窄任务上,微调后的端侧模型几乎零幻觉,准确率甚至超过百亿大模型——论单点专精,云端大模型未必打得过它。
从阿里的 Qwen3.5-0.8B 到谷歌针对移动端的 Gemma 4 E2B-it,轻量级 LLM 正在快速接管那些追求快、稳、省资源的辅助性任务。
5 月 11 日面壁智能正式发布并开源了 MiniCPM-V 系列新一代基础模型——MiniCPM-V 4.6。这款模型的整体参数规模仅约 1B(1.3B),是该系列有史以来参数规模最小的一款。但在多模态综合能力上,它却成功超越了被视为标杆的阿里 Qwen3.5-0.8B 和谷歌 Gemma 4 E2B-it,做到了「尺寸更小、效率更高、性能更好」。
🤗 Hugging Face:https://huggingface.co/openbmb/MiniCPM-V-4.6
💻 GitHub:https://github.com/OpenBMB/MiniCPM-V
🔭 Modelscope:https://modelscope.cn/models/OpenBMB/MiniCPM-V-4.6
🌐 Web Demo:https://huggingface.co/spaces/openbmb/MiniCPM-V-4.6-Demo
📱 App Demo:https://github.com/OpenBMB/MiniCPM-V-Apps
从 2024 年 4 月初次惊艳亮相至今,MiniCPM-V 已经在汽车、PC、手机、智能家居等终端场景中实现了广泛的商业落地。
此次 MiniCPM-V 4.6 的发布,不仅在参数规模、推理速度、计算成本等多个维度都有明显提升,也让面壁智能在侧端多模态开源领域站稳了脚跟。这距离面壁智能「智周万物」的愿景,又迈出了坚实的一大步。
评价一款端侧模型,不能仅看参数大小,更要看它在极端受限的算力环境下,能爆发出多大的「智能密度」。不同尺寸的模型运行门槛截然不同,参数越小,意味着运行门槛越低、速度越快,能够完美适配更广泛的芯片和算力环境。
MiniCPM-V 4.6 的「端侧第一」,是通过实打实的多模态综合能力与极致的推理效率双重验证的。
在业内公认的几大核心评测基准中,MiniCPM-V 4.6 展现出了远超其体量的综合实力。根据最新的评测数据,其在同尺寸模型范围内的智能密度位列最高。
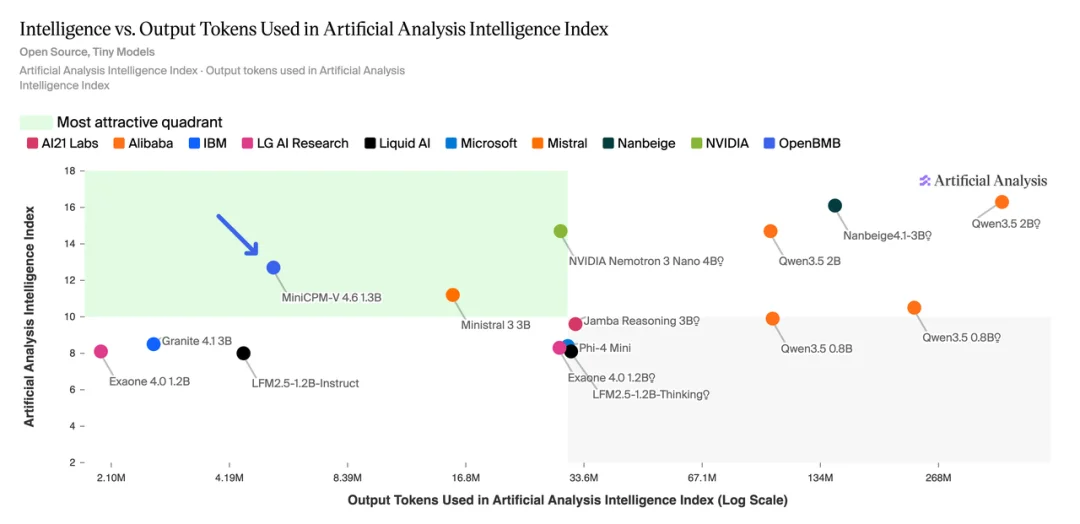
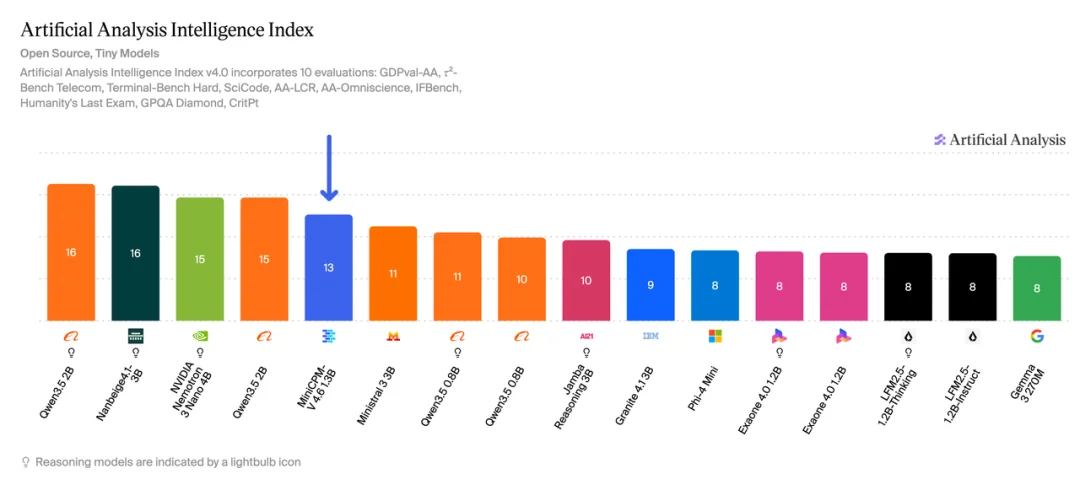
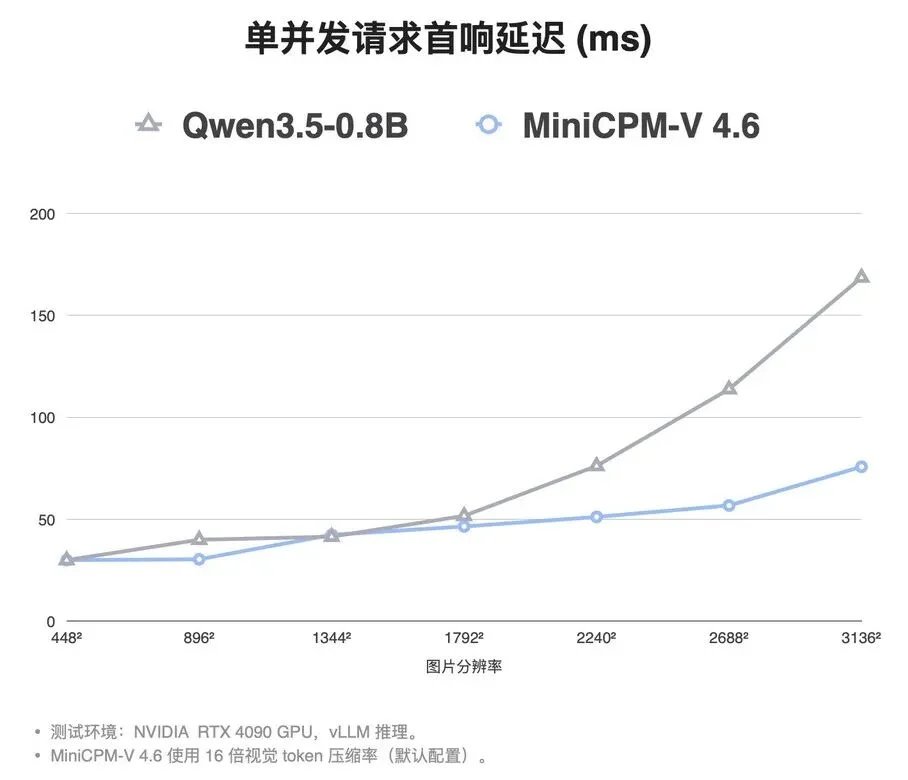
对于「高并发」的云端工业场景和算力功耗受限的终端硬件来说,推理速度和吞吐量是核心指标。得益于 16 倍视觉 Token 压缩这一核心技术,我们直接来看 MiniCPM-V 4.6 在 RTX 4090 + vLLM 推理环境下的实测表现,其在两大关键维度上同时建立起了显著的优势:
首先,在单并发首字响应延迟(TTFT)上,MiniCPM-V 4.6 表现出了极高的稳定性。它几乎把「分辨率——延迟」曲线压得平坦。当处理 3136² 的超高清大图时,其首响仅需 75.7 毫秒,较同基座规模的 Qwen3.5-0.8B 快 2.2 倍。这意味着用户在 4090 显卡上加载一张 4K 级别的照片进行提问时,模型几乎能做到「秒回」。
其次,在高并发吞吐量上优势同样亮眼。在输出长度为 200 token 的设定下,RTX 4090 单卡处理 1344² 分辨率图片的吞吐量可达 2624 token/s,即每秒可处理 14.3 张图片,是 Qwen3.5-0.8B 的 1.4 倍。这意味着同样的硬件部署 MiniCPM-V 4.6,可以承载数倍的线上业务流量。
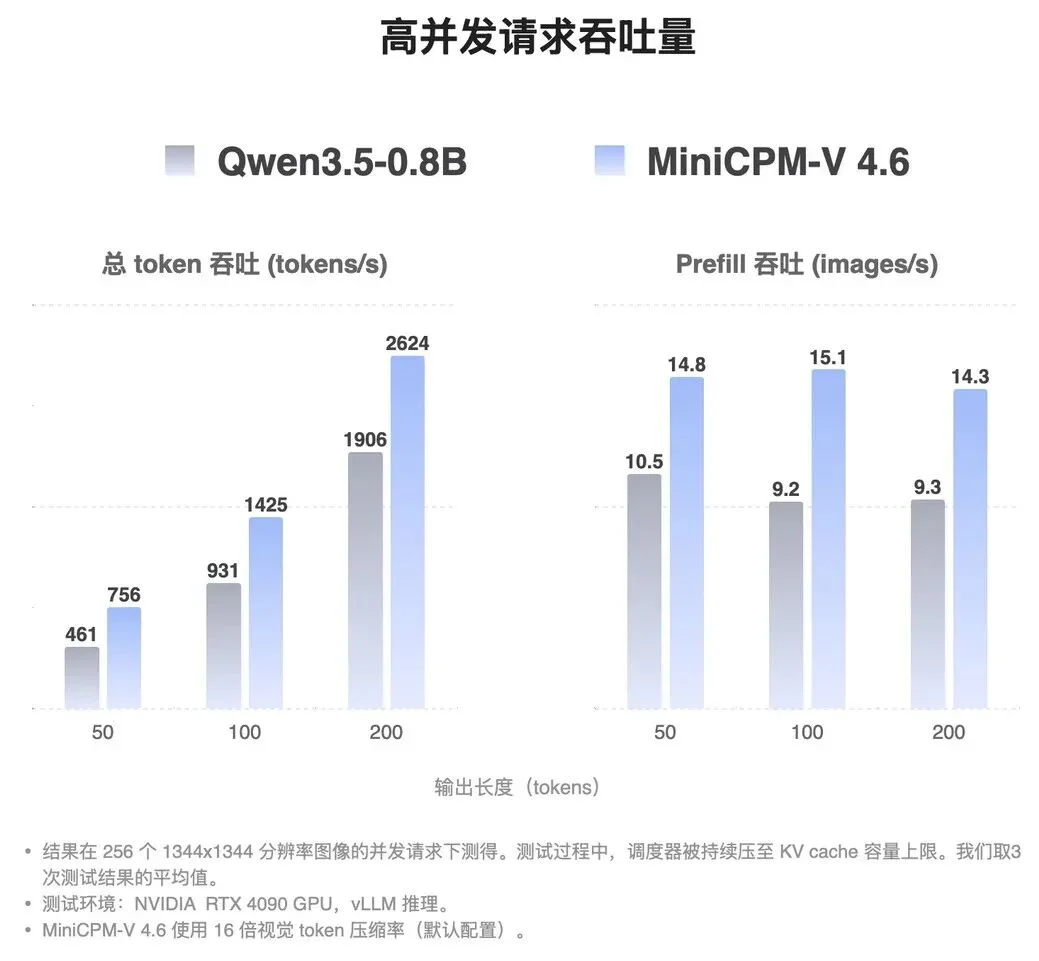
这两个维度共同指向同一个结论——MiniCPM-V 4.6 用更短的视觉序列、更小的 KV-Cache 占用,把多模态推理的端侧体感与云侧 ROI(投资回报率)同时推到了新的高度。
为了直观感受,我们来看看 MiniCPM-V 4.6 单在实际的移动端设备(iPhone 17)上的运行效果。
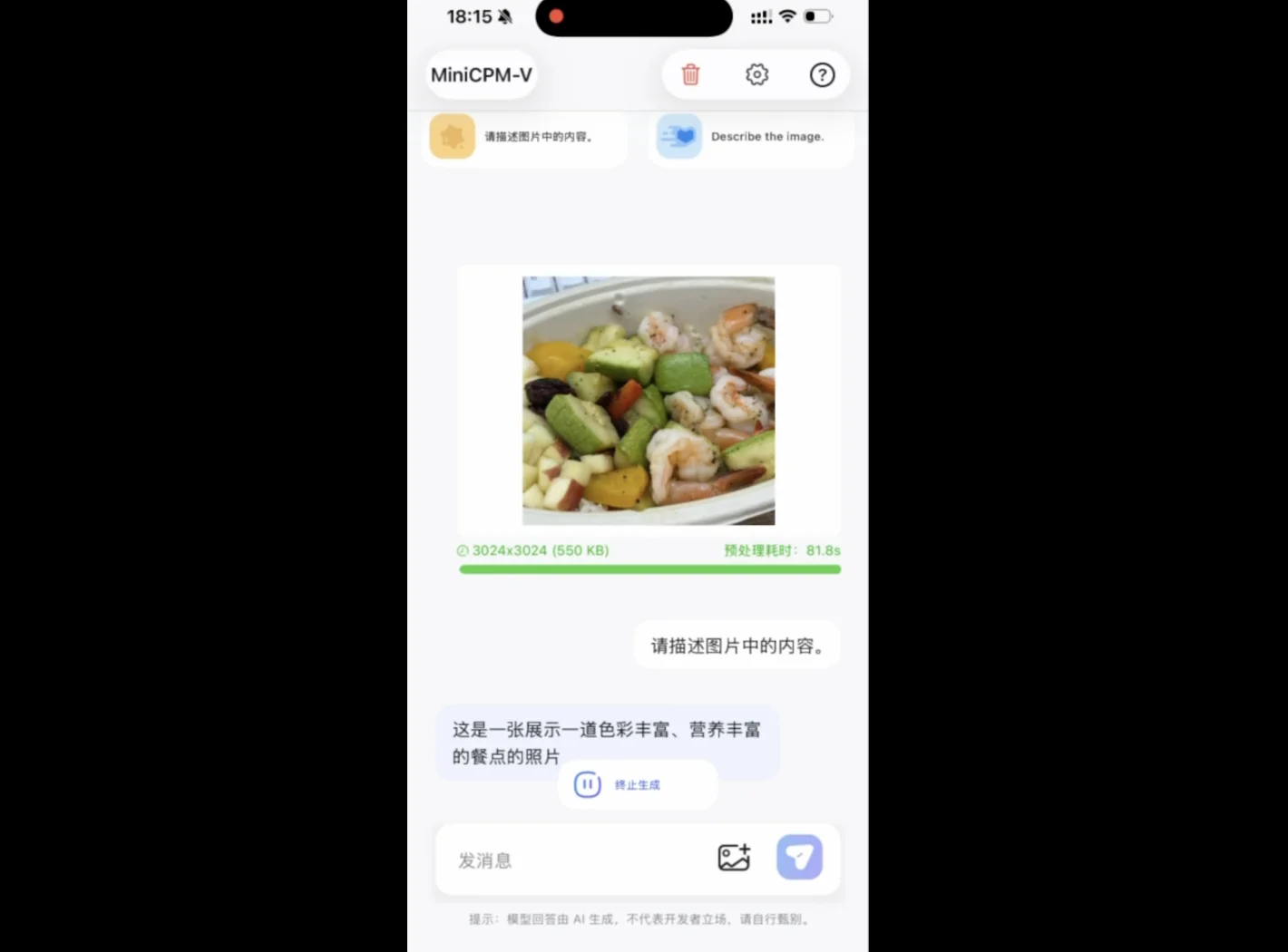
我们向 MiniCPM-V 4.6 喂入了一张 3024x3024 分辨率(近千万像素)的实拍食物原图,经过预处理后,正如前文数据所印证的那样,得益于模型极小的 KV-Cache 占用,一旦跨过最耗时的预处理门槛,极度精简的视觉序列交接给 1B 语言基座后,文本生成速度便瞬间起飞。在我们顺着图片细节进行二次追问时,不需要重新经历漫长的读图,直接实现了几乎「零预热」的秒回响应,真正做到了毫秒级的连续解码。
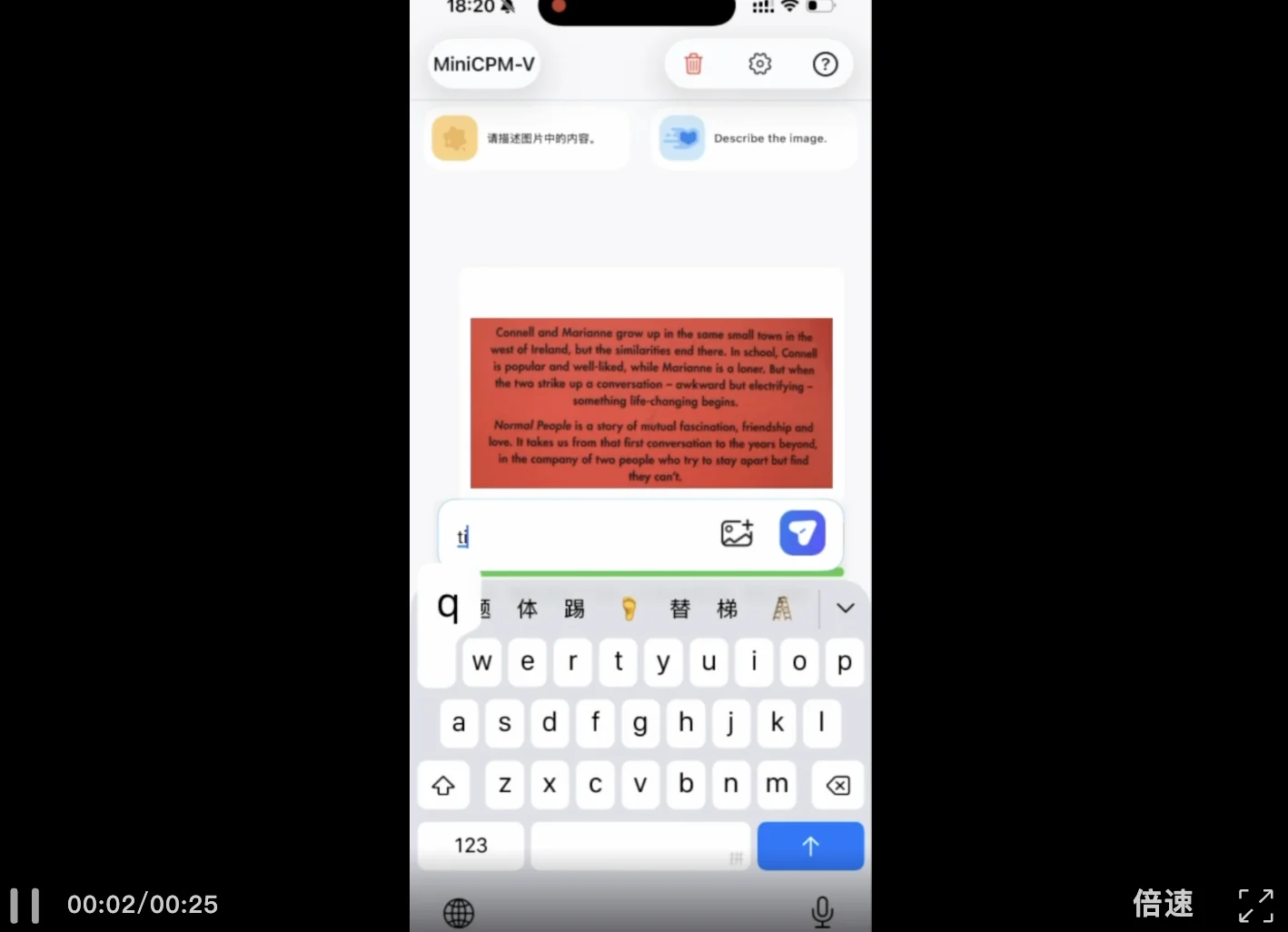
再看文本类任务,可以看到经过预处理后,无论是提取文本还是翻译成多种语言,MiniCPM-V 4.6 的表现都可以用「迅雷不及掩耳」来形容。按下发送键的瞬间,文字流便如流水般涌出,精准的图文解析能力和极低的首答延迟,真正让人感受到 AI 已经融入了设备的「血液」中,而非遥远的云端接口。
为什么在参数量极小(仅 1B)、甚至与竞品相近的情况下,MiniCPM-V 4.6 能够爆发出如此惊人的推理效率和算力性价比?甚至实现了「参数量略大,效率却大幅反超」的奇迹?
答案藏在面壁智能与清华大学团队最新联合研发的第四代 LLaVA-UHD (v4) 架构之中。针对高分辨率图像处理中的视觉编码效率问题,研发团队做了两项关键的技术改进。
目前社区处理高分辨率图像的主流方案通常是全局编码(Global Encoding),即保留原始分辨率,将全图直接送入视觉编码器。但这会导致注意力机制的计算开销随着分辨率的提升呈二次方级别爆炸。
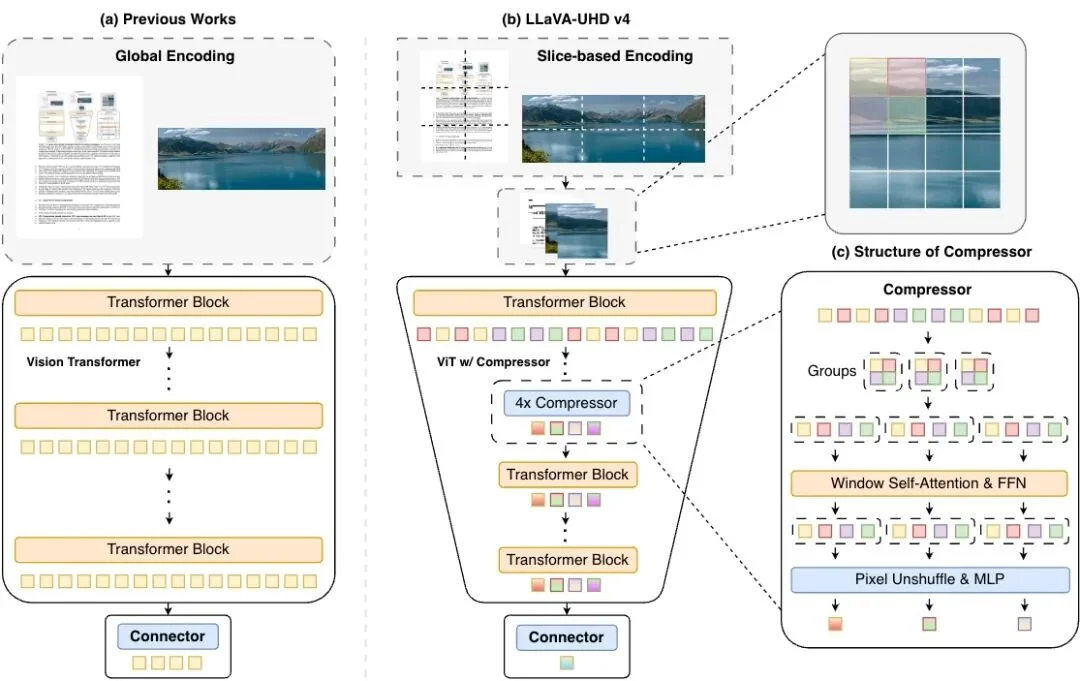
LLaVA-UHD v4 首先采用了切片编码,将大图分割为多个区块进行处理,从结构上规避了二次方的算力膨胀,并通过实验证明切片编码能提供比全局编码更丰富的特征表示,下游性能更好。
然而,切片编码虽然解决了全局注意力的计算爆炸,但高分辨率图片依然会生成极其庞大的视觉 Token 序列,给后端的语言模型带来沉重的推理负担。现有的主流优化方案,大多是在 ViT 提取完所有特征之后,再进行 Token 压缩。这种做法治标不治本,仅仅减轻了 LLM 的负担,却完全没有降低庞大的视觉编码器内部的计算量。
面壁智能的解法是:将压缩动作「前置」。
为了实现极致高效,LLaVA-UHD v4 设计了一种早期 ViT 内压缩模块。直觉上,压缩越早进行,后续绝大部分的 ViT 层需要处理的 Token 就越少,计算量自然大幅下降。但难点在于,如果在 ViT 浅层简单粗暴地插入随机初始化的下采样模块,会严重破坏模型在预训练阶段辛苦学到的视觉表征,不仅训练代价极其高昂,还会导致模型「变笨」。
为此,研发团队巧妙地引入了窗口注意力机制,在 Token 合并前增强邻近 Token 的上下文交互;同时,通过复用相邻预训练 ViT 层的参数,实现了参数的平滑初始化,最大限度地减小了对视觉表征的扰动。
这一架构创新,使得视觉 Token 压缩能够稳定前移至 ViT 浅层,在保持下游任务性能完全不掉点的前提下,将视觉编码阶段的浮点运算量暴降了 55.8%(节省了约一半的图像编码开销)。这也是为什么 MiniCPM-V 4.6 能够在处理高清大图时,不仅看得清,而且跑得飞快。
视觉 Token 的压缩率直接影响到显存占用、首响延迟、推理吞吐和功耗等关键指标。目前市面上的多模态模型,绝大部分只能做到 4 倍的压缩率。
面壁智能的 MiniCPM-V 系列从 2024 年初就开始死磕 16 倍压缩率。在此之前的版本中,开发者只能在「4 倍」和「16 倍」之间二选一。但在 MiniCPM-V 4.6 中,面壁智能实现了「鱼与熊掌兼得」:
16 倍压缩率的含金量有多高?我们可以看一个快手推荐算法的真实工业案例。
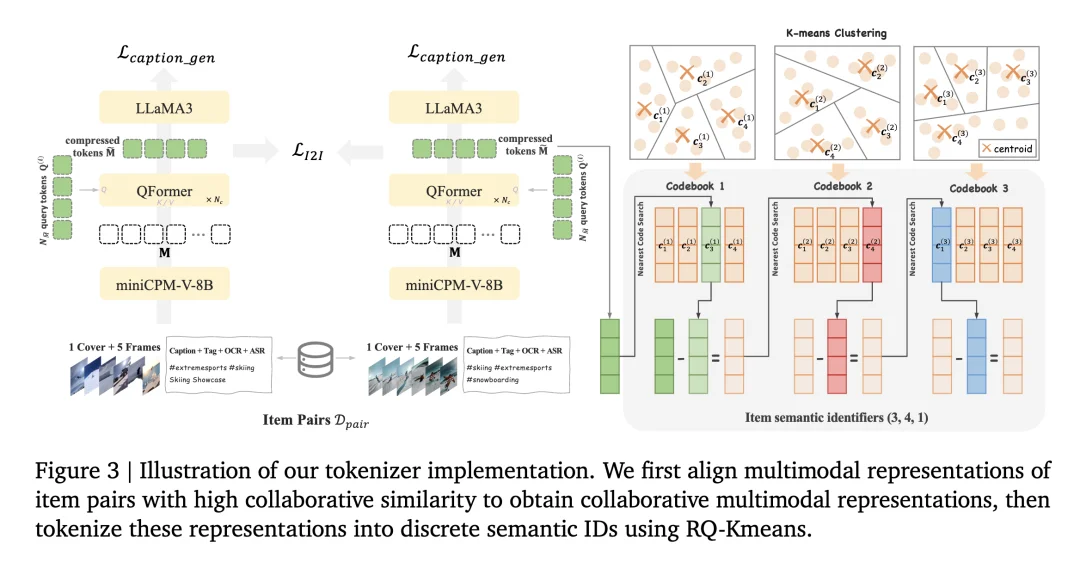
在快手 2025 年发布的 OneRec 推荐大模型中,系统需要处理海量短视频的字幕、标签、ASR、OCR、封面图等多模态数据。由于用户体量庞大,并发请求量极高,快手最终选用 MiniCPM-V-8B 来处理底层多模态数据的特征提取,承接了快手短视频推荐主场景高达 25% 的请求。这个案例说明 MiniCPM-V 系列在高并发工业场景下的可用性和成本优势是经过实际验证的。
评判一个开源模型的生命力,不仅要看它在榜单上如何称王,更要看它能否迅速落到开发者的代码库里、跑在业务的服务器上发光发热。
本次发布,面壁智能不仅带来了一个极其能打的 1B 模型,更为社区开发者、高校研究团队以及初创公司准备了一套从微调(Fine-tuning)到部署(Deployment)开箱即用的「保姆级」二次开发基石。它天生就是为了被「爆改」而生的。
大模型的微调往往让人联想到昂贵的 A100/H100 算力集群,这让很多独立开发者和中小型企业望而却步。但 MiniCPM-V 4.6 得益于其极致精简的 1B 参数量,将定制微调的门槛大幅降低。
开发者只需一张 RTX 4090 等消费级显卡,就能跑通完整的微调流程。这意味着验证一个想法、定制一个垂类场景模型(如工业流水线上的缺陷检测、金融领域的复杂财报解析),不需要申请大量算力预算,在本地 PC 上就能完成。
「好用」是开源生态的核心。为了让开发者彻底告别配环境配到崩溃的「折磨」,MiniCPM-V 4.6 实现了与当前主流开源工具链的全面无缝对接:
如果你追求云端极致并发,可以使用 vLLM 或 SGLang;如果你要在没有独立显卡的轻薄本、Mac 甚至手机上进行纯 CPU/端侧推理,llama.cpp 和 Ollama 能够让你游刃有余地完成高效部署。
极低的显存占用、极高的并发吞吐量、完备的上下游工具链,使 MiniCPM-V 4.6 成为了构建高并发、极速响应多模态应用的高性价比首选。
MiniCPM-V 4.6 的这次表现,背后是面壁智能在端侧多模态领域多年的持续积累。回顾 MiniCPM-V 系列的发展路径,可以看到一条以「智能密度」为核心的清晰脉络:
从 2.0 到 4.6,MiniCPM-V 系列一步步拓展了端侧模型的能力边界:超高清长文档解析、连续视频理解、多图联合推理、高密度文本提取,这些任务在端侧模型上逐渐成为可能。这也让该系列在联想、吉利、上汽大众、广汽等企业的实际业务中落地。
更令人振奋的是,面壁智能在端侧多模态的路线早已获得了国际顶尖学术共同体的认可。其关于「密度定律」的相关成果成功发表于国际顶级学术期刊《Nature Communications》。
2024 年 6 月,斯坦福一个团队被发现直接套用了 MiniCPM-V 2.5 的成果,随后公开致歉。这件事从另一个角度说明,中国多模态大模型的研究已经走到了全球开源社区的前列,不再只是在别人的基础上做二次开发。
回到文章开篇的问题:1B 以下的端侧模型,到底有什么实际意义?
当我们被云端千亿参数巨兽的发布会不断轰炸时,很容易陷入一种唯参数论的迷思。然而,AI 的最终目的不是停留在机房里炫技,而是融入人类生活的每一个角落。
MiniCPM-V 4.6 给出了一个具体的答案:端侧模型的意义,在于用更低的成本、更快的速度、更好的隐私保护,把视觉理解和认知推理能力塞进手机、电脑、汽车和智能家电里。
当一款 1B 参数的模型,通过架构优化和混合 Token 压缩,在性能上超过同类、在速度上实现单卡数千 Token 的秒级吞吐,且让开发者用一张消费级显卡就能定制,它就已经不再是一个简单的「技术 Demo」,而是加速整个边缘计算生态全面爆发的强劲催化剂。
大厂卷端侧模型,是因为未来属于边缘侧。而面壁智能与它的 MiniCPM-V 家族,正在这条通往「智周万物」的道路上,刻下属于中国架构的深刻印记。
文章来自于微信公众号 "机器之心",作者 "机器之心"



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
