一张4090就能爆改!面壁智能MiniCPM-V 4.6开源,1B多模态卷出新高度
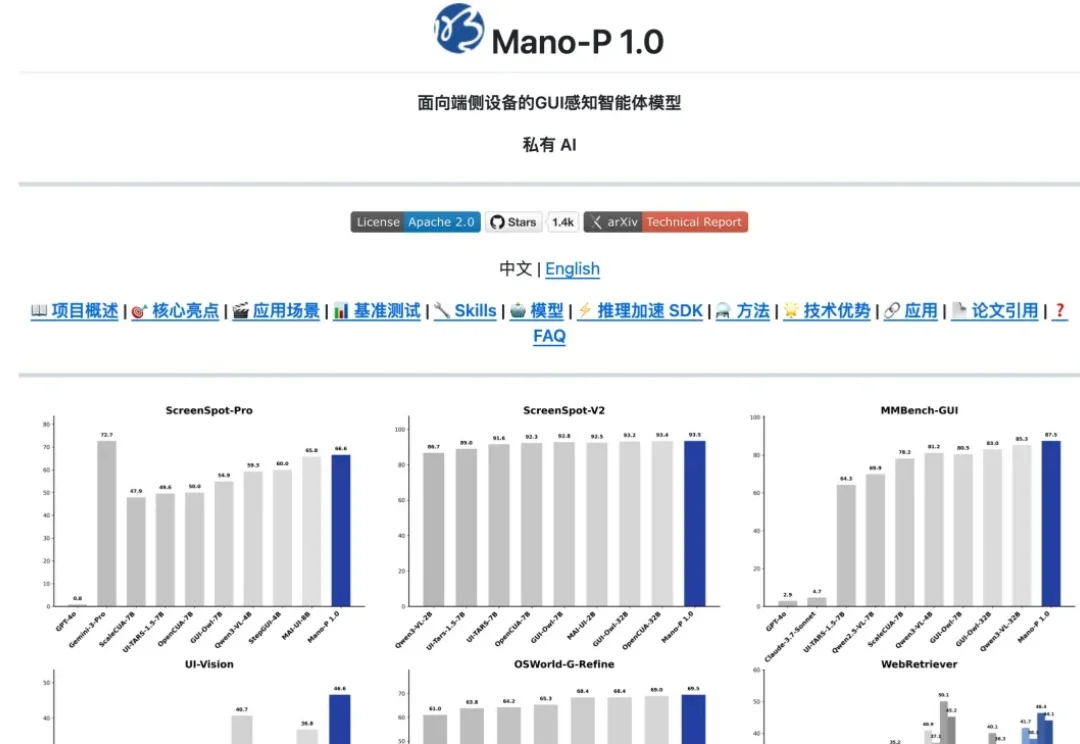
一张4090就能爆改!面壁智能MiniCPM-V 4.6开源,1B多模态卷出新高度面壁智能正式发布并开源了 MiniCPM-V 系列新一代基础模型——MiniCPM-V 4.6。这款模型的整体参数规模仅约 1B(1.3B),是该系列有史以来参数规模最小的一款。但在多模态综合能力上,它却成功超越了被视为标杆的阿里 Qwen3.5-0.8B 和谷歌 Gemma 4 E2B-it,做到了「尺寸更小、效率更高、性能更好」。
来自主题: AI资讯
8738 点击 2026-05-13 11:57