# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?
来自香港科技大学(广州)与地平线 (Horizon Robotics) 的研究团队提出了 VGGT4D。该工作通过深入分析 Visual Geometry Transformer (VGGT) 的内部机制,发现并利用了隐藏在注意力层中的运动线索。
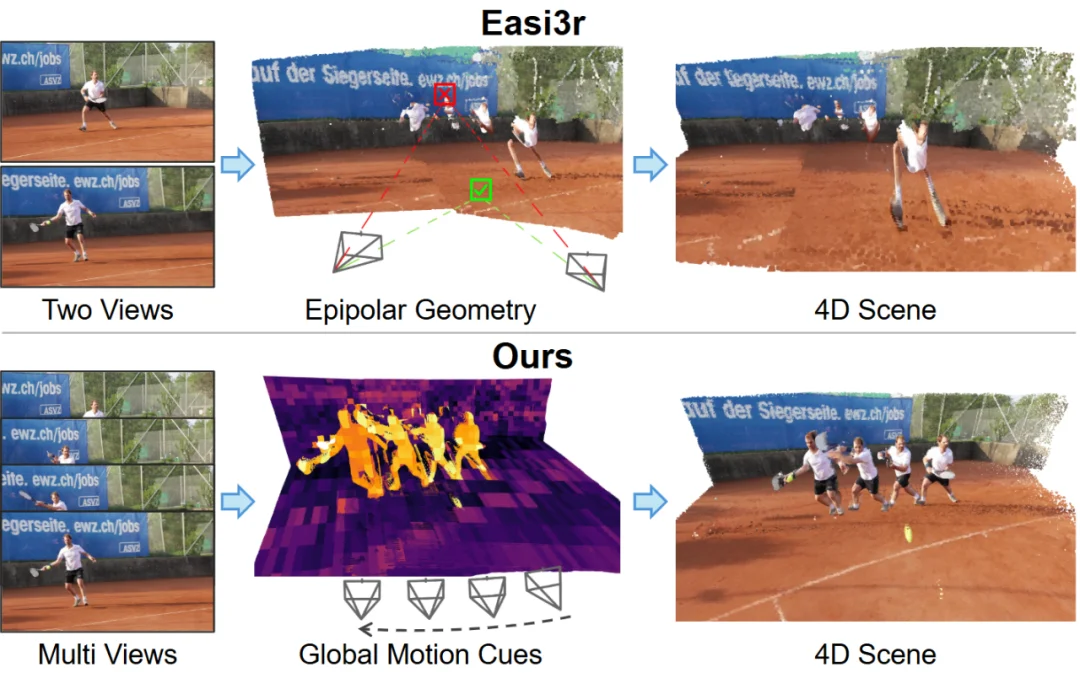

作为一种无需训练 (Training-free) 的框架,VGGT4D 在动态物体分割、相机位姿估计及长序列 4D 重建等任务上均取得了优异性能。

近年来,以 VGGT、DUSt3R 为代表的 3D 基础模型在静态场景重建中表现出色。然而,面对包含移动物体(如行人、车辆)的动态 4D 场景时,这些模型的性能往往显著下降。动态物体的运动不仅干扰背景几何建模,还会导致严重的相机位姿漂移。
现有的解决方案通常面临两类挑战:
VGGT4D 的核心设想:能否在不进行额外训练的前提下,直接从预训练的 3D 基础模型中挖掘出 4D 感知能力?
研究人员对 VGGT 的注意力机制进行了可视化分析,观察到一个关键现象:VGGT 的不同网络层对动态区域表现出截然不同的响应模式。
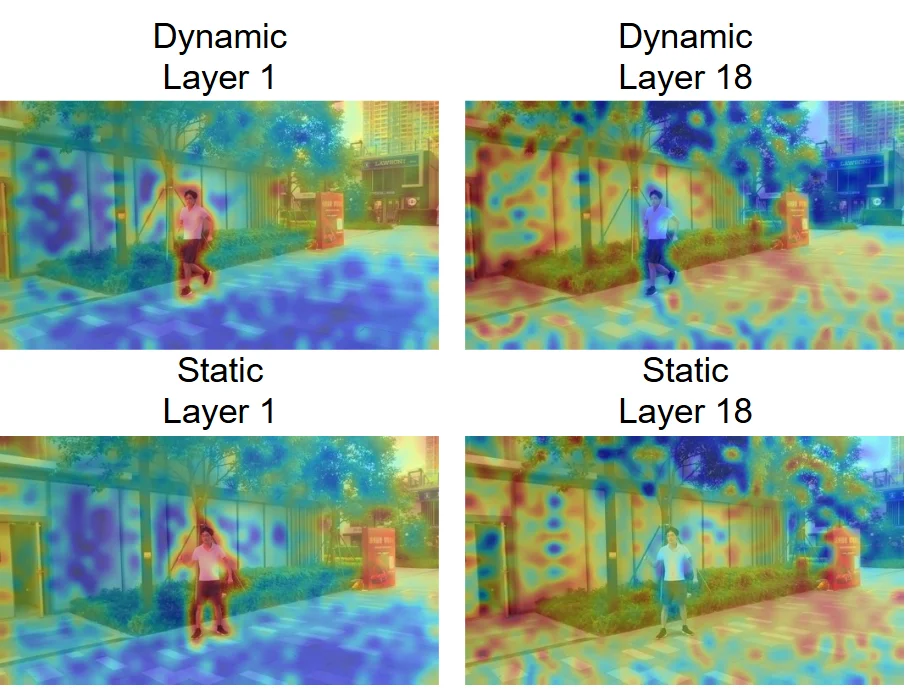
这一发现表明,VGGT 虽然是基于静态假设训练的,但其内部实际上已经 隐式编码 了丰富的动态线索。

VGGT4D 的核心贡献在于提出了一套无需训练的注意力特征挖掘与掩膜精修机制。该方法深入特征流形内部,利用 Gram 矩阵和梯度流实现了高精度的动静分离。
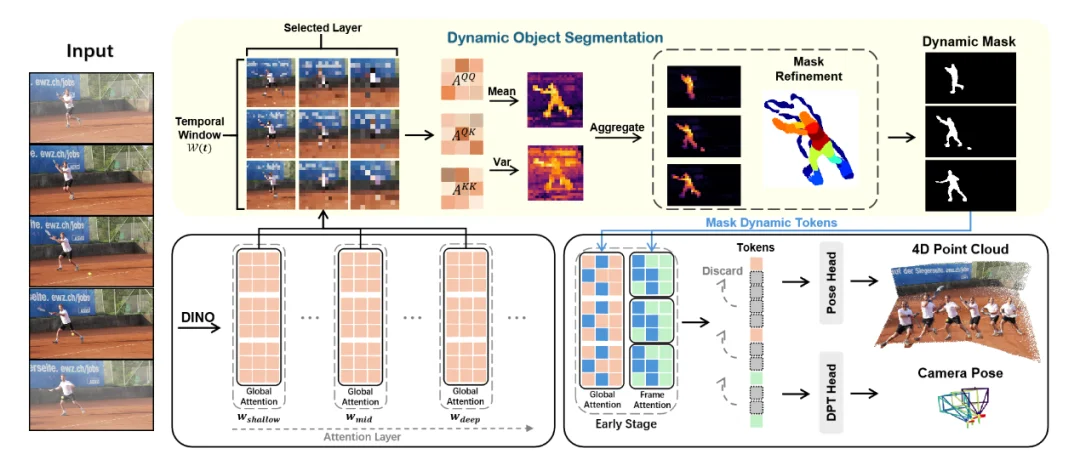

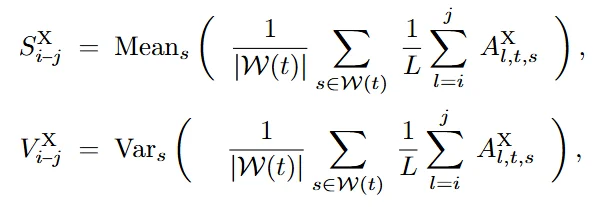
为了解决 Attention Map 分辨率不足导致的边界模糊问题,VGGT4D 引入了 投影梯度感知精修 (Projection Gradient-aware Refinement)。

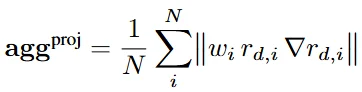
在推理阶段,直接的全层掩膜(Full Masking)会将模型推向分布外(OOD)状态,导致性能下降。
VGGT4D 提出了一种早期阶段干预策略:仅在浅层抑制动态 Token 的 Key 向量。这种设计既在早期切断了动态信息对深层几何推理的影响,又保证了深层 Transformer Block 依然在其预训练的特征流形上运行,从而保证了位姿估计的鲁棒性。
研究团队针对动态物体分割、相机位姿估计和 4D 点云重建三大核心任务,在六个基准数据集上进行了详尽的定量和定性评估。
实验首先评估了该方法的核心组件:动态物体分割。

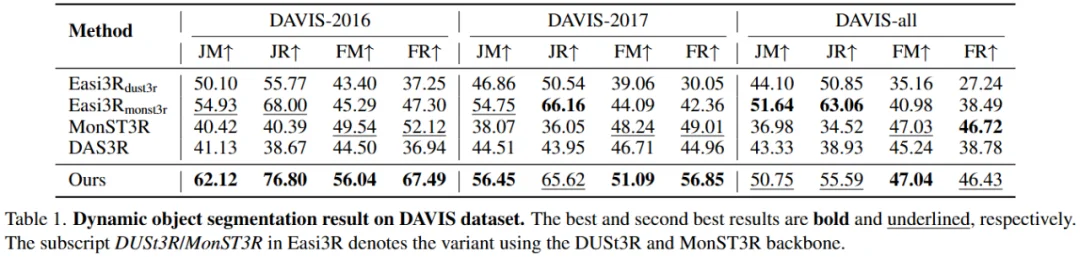
定性分析:定性结果清晰地展示了基线方法的不足:Easi3R 的掩码较为粗糙且遗漏细节;DAS3R 倾向于过度分割并渗入静态背景;MonST3R 则常常分割不足。相比之下,VGGT4D 生成的掩码更加准确,且边界更加清晰。这些结果有力地验证了研究团队的假设:VGGT 的 Gram 相似度统计信息中嵌入了丰富的、可提取的运动线索。

强大的基线与持续改进:数据表明,原始 VGGT 已经是一个非常强大的基线,其自身就优于 MonST3R、DAS3R 等许多专门的 4D 重建方法。这表明 VGGT 的预训练隐式地使其对动态物体具有一定的鲁棒性。然而,这种鲁棒性并不完美。 VGGT4D 在所有数据集上均持续改进了这一强大的 VGGT 基线。例如在 VKITTI 数据集上,VGGT4D 的 ATE 仅为 0.164,而 MonST3R 高达 2.272。
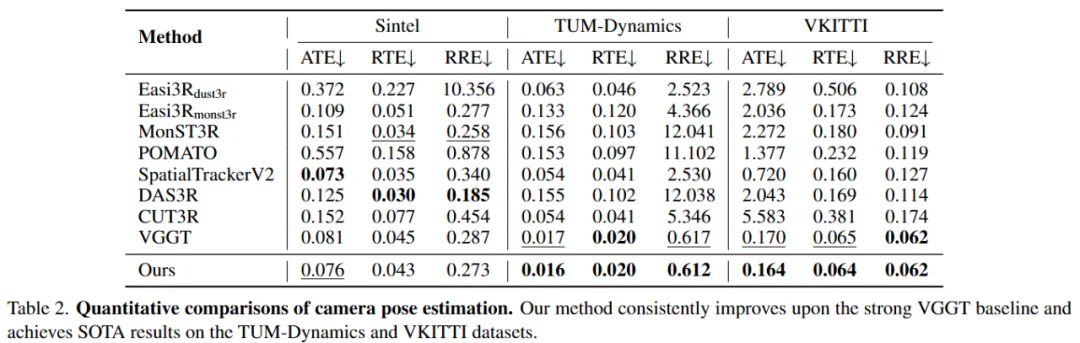
长序列鲁棒性突破:在极具挑战性的长序列 Point Odyssey 基准测试中,VGGT4D 在所有指标上均取得了最佳结果,同时保持了高度效率。许多其他 4D 方法由于内存不足(OOM)错误甚至无法在该 500 帧序列上运行。这表明 VGGT4D 提出的显式、无需训练的动态 - 静态分离方法成功地识别并消除了由运动引起的残余位姿不一致性,从而实现了更稳定、更准确的相机轨迹,尤其是在长且复杂的序列上。

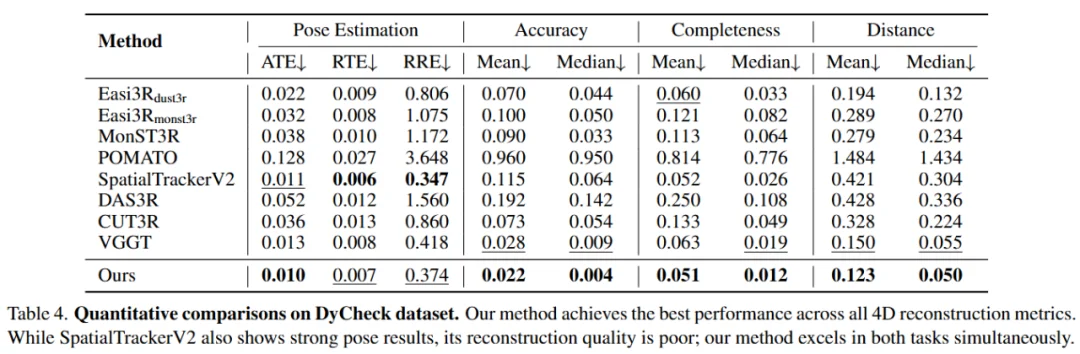
在 DyCheck 数据集上的评估显示,VGGT4D 在所有重建指标(准确度、完整度和距离)上均取得了最佳性能。与 VGGT 基线相比,中位准确度误差从 0.009 降低到 0.004,平均距离从 0.150 降低到 0.123。这证明了该方法不仅实现了精准的动静分离,更能实质性提升几何重建质量。

VGGT4D 提出了一种无需训练的新范式,成功将 3D 基础模型的能力扩展至 4D 动态场景。该工作证明了通过合理挖掘模型内部的 Gram 相似度统计特性,可以有效解耦动态与静态信息。这不仅为低成本的 4D 重建提供了新思路,也展示了基础模型在零样本迁移任务中的潜力。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
