# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
很多团队都撞墙的地方,有了新方向

最近一年,关于一句话的讨论特别热:
「Diffusion 就是比 VAE 更好。」
这句话之所以流行,其实不难理解。
在图像生成这类任务上,扩散模型确实交出了更好看的结果,细节更丰富,也更稳定。在大模型、大数据成为常态之后,这种优势就被进一步放大了。
但如果你真的去看现实世界里的产品,会发现事情没这么简单。
像 Stable Diffusion 这样的主流模型,本质上并没有「抛弃 VAE」,它们是 VAE + Diffusion 的组合体系:VAE 负责把图像压缩进一个潜空间,Diffusion 再在这个空间里做生成。
这种分工,至今仍然是学术、工业界的主流选择。
同样的思路,也出现在世界模型的实践中。
无论是 Google 的 Genie-3、腾讯的 HunYuan-GameCraft,还是 Mirage AI,它们在技术路径上都被认为依赖了 VAE 结构。
也正是在这个背景下,VAE 在学界和工业界的「地位」仍然很高,许多厂商都在往里投入大量的资源。
12 月 17 日,我们看到了一个技术项目被开源了:
MiniMax 海螺视频团队「首次开源」了 VTP(Visual Tokenizer Pre-training)项目。
他们同步发布了一篇相当硬核的论文,它最有意思的地方在于 3 个点:
【1】「重建做得越好,生成反而可能越差」,传统 VAE 的直觉是错的
【2】 真正能驱动生成的是「理解能力」,Visual Tokenizer 很有用。
【3】 VTP 首次打通了 Visual Tokenizer 的 Scaling Law(这是最重要的)。
一句话就是:过去大家默认的那条视觉生成 Scaling 路径,可能本身就有问题,而他们给出了新的路线。
要理解 VTP 的创新,我们需要先看看传统 VAE。
在 LDM、DiT 这类两阶段生成框架里,第一阶段的 visual tokenizer(常见是 VAE 或者是 AutoEncoder) 把图像压进 latent,第二阶段扩散模型在 latent 上学生成。
在传统范式下,大家默认遵循一个逻辑:
第一阶段压缩得越好(重建出的图片与原图越像),第二阶段的生成效果就应该越好。
然而,海螺团队在论文中通过大量实验,给出了一个反直觉的现象:这种正相关性不仅不存在,甚至可能呈现负相关。
传统做法是:tokenizer 只用重建损失预训练。论文认为这就是 pre-training scaling problem。
简单说就是,如果你给 tokenizer 砸更多算力和数据继续做重建训练,重建指标会持续变好(更像原图),但这对下游扩散模型的生成指标没有用,甚至还更差了。
我举个例子,这就好比让学生背诵课文,他能把每一个标点符号、每一个笔画都背下来了(重建极好),但实际上完全没读懂这篇文章讲了什么(语义极差),只会做题而已。
它认为根因是:重建目标会强烈偏向低层细节(纹理、边缘、像素误差),而生成质量真正需要的是 latent 里更「紧凑」的高层语义结构。
你看论文的 Figure 4 就是这个现象的可视化:随着训练 FLOPs 增长,rFID(重建)改善,但 gFID(生成)变差。
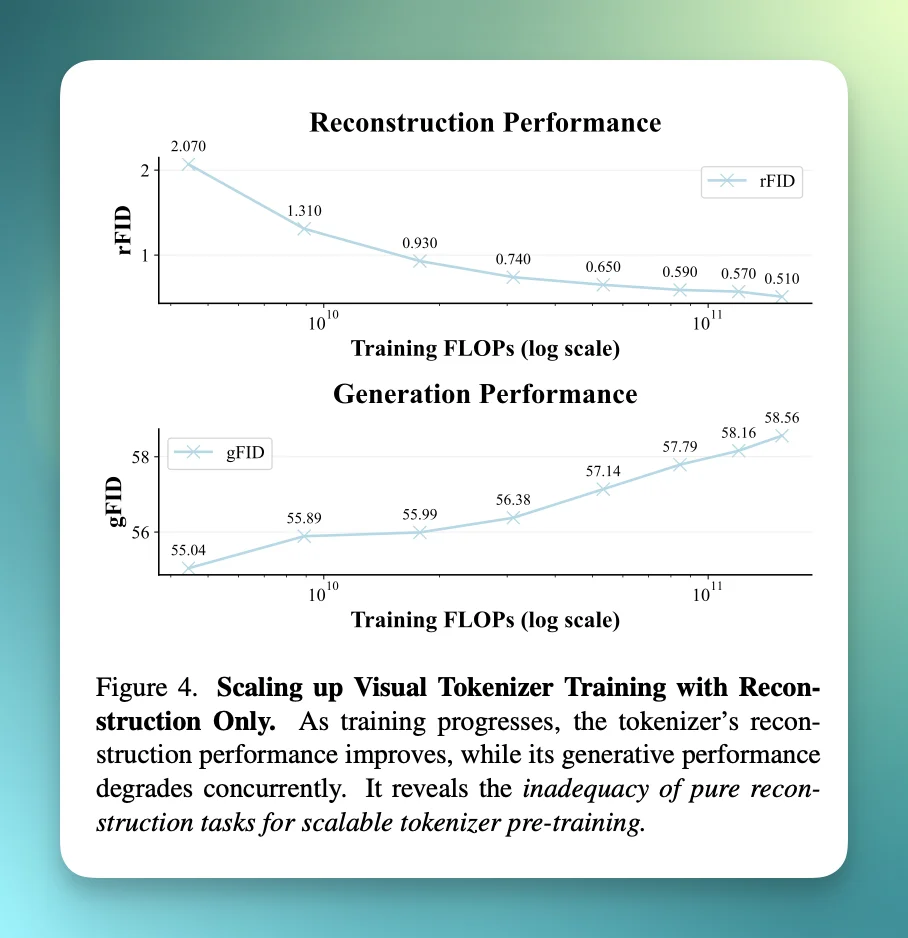
一句话总结就是:tokenizer 不是「压缩器」,更应该被当成一个「表征学习模型」。
所以,如果单纯追求重建是一条「死路」,出路在哪里?
海螺团队给出的答案很简洁:理解力,才是驱动生成的关键。
为了实现这一点,他们提出了 VTP(Visual Tokenizer Pre-training) 框架。这不仅仅是一个新的模型结构,也是一种新的思路。
相关项目也已经被开源在 GitHub 上:https://github.com/MiniMax-AI/VTP
ArXiv 的论文链接,我也放这了:https://arxiv.org/pdf/2512.13687
简单来说,VTP 的目标是将 Visual Tokenizer 进化一下,要让它不仅要看清画面,还要读懂画面。
海螺团队把整套 pipeline 画得很清楚:
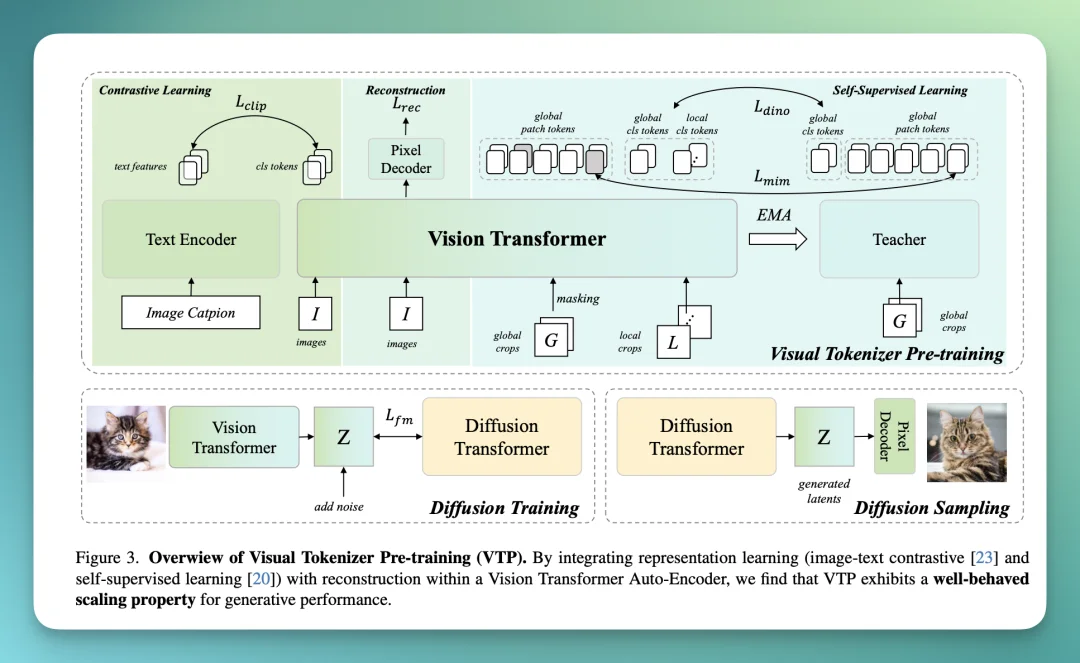
在架构选择上,VTP 全面转向了 ViT(Vision Transformer)。
这是一个蛮有挑战的选择,因为 ViT 在像素级重建任务上一般不如 CNN 稳定。直白点说就是,当 GAN Loss(对抗损失)和 ViT 结合时,容易出现一堆问题,比如训练不稳定的情况。
为了解决这个问题,VTP 采用了一套两阶段训练策略:
【1】预训练阶段(Pre-training)
联合优化所有目标,但不使用 GAN Loss,专注于 L1 Loss 和感知损失(Perceptual Loss)。
【2】微调阶段(Fine-tuning)
冻结 Tokenizer 的主体,只训练解码器(Pixel Decoder),此时引入 GAN 目标来提升画质。
这种设计同时利用了 Transformer 比较强的表征学习能力,又避免了它在生成细节上的不稳定性。
总结一下就是,VTP 的两阶段训练,本质上是在刻意拆分 2 件事:
阶段一:让 tokenizer 学会「怎么看世界」
阶段二:再教它「怎么把世界画好看」。
举个让小孩学画画的例子:
传统方法下,第一步是让小孩直接临摹作品,把细节、阴影都模仿的很好,但是在第二步,让他自己画「一只猫、一只狗」,他根本就不会。
VTP 的 2 阶段方法就是,第一步先让小孩「认识 + 理解世界,先给他很多图片,让他知道猫和狗长什么样」,第二步再让他慢慢变好。
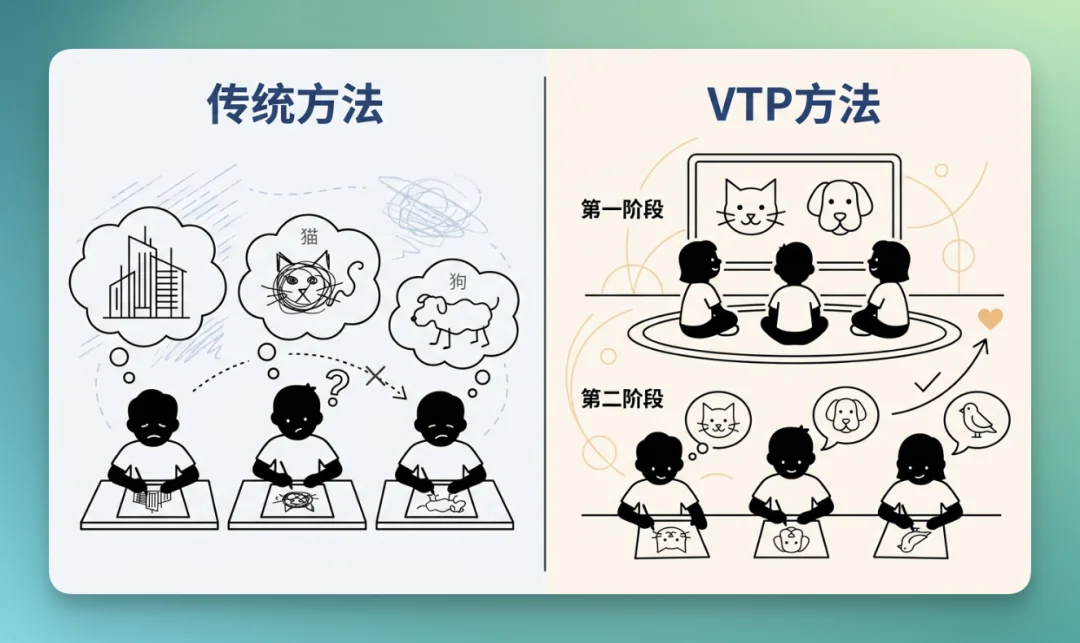
而这种「慢慢变好」的可能性,就是核心的创新。
VTP 的核心是它的损失函数(Loss Function),它不再单一依赖重建损失,而是引入了 3 个维度的联合优化目标。

由 3 个部分组成:
REC 负责「别把细节全忘了」
SSL 负责「空间结构和局部语义」
CLIP 负责「全局语义 + 跨模态对齐」
VTP 借鉴了 CLIP 的思路,让 Tokenizer 生成的视觉特征与文本特征对齐,作用就是告诉模型「这是一只猫」还是「一只狗」。
这里有个工程上的细节亮点。
在训练中,这 3 个任务其实对 Batch Size 的要求是矛盾的。CLIP 需要巨大的 Batch(如 16k)来保证负样本数量,而重建任务只需要较小的 Batch(如 2k)。
所以,VTP 设计了一种采样策略:在一个大 Batch 中,所有样本都用于 CLIP 训练,然后随机抽取子集用于 SSL 和重建训练。
这种工程上的策略,让多目标联合训练成为可能。
论文最想证明的不是「此方法比另一个方法要强一点点」,而是:他们终于让 tokenizer 的预训练也出现类似大模型的 scaling 曲线。
这也是 VTP 最让技术社区关注的点,它打通了 Visual Tokenizer 的 Scaling Law。
在深度学习时代,如果一个方法不能 Scale,那它的潜力就是有限的。传统的 VAE 就卡在了这里,算力增加,效果不涨。
而 VTP 的实验数据证明,一旦引入了「语义理解」,Scaling Law 就有可能了。
这个地方比较复杂。
如果只做重建的话,Scale 越大越没用甚至反效果,像是在下面这个表里,rFID 从 2.0 → 0.5 变好,但 gFID 从 55.04 → 58.56 变差。
这里,我们可以重新再看一遍这张图:
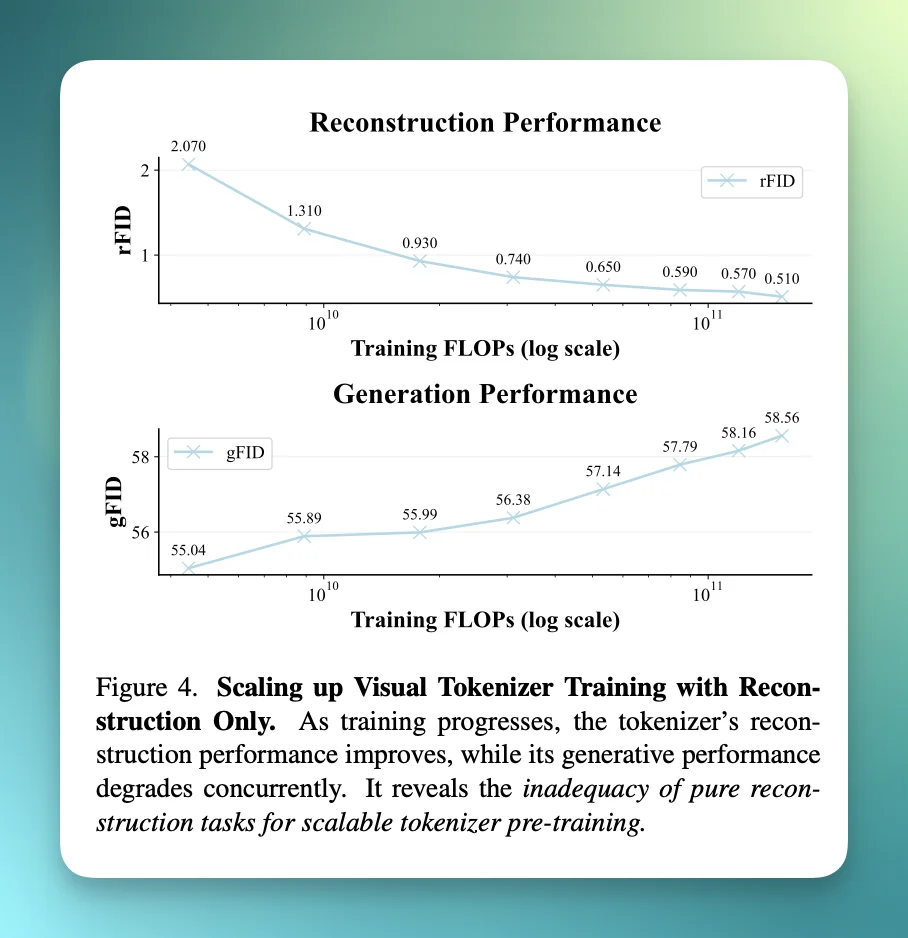
关键的来了。
如果加入「理解任务(CLIP+AE / SSL+AE)」,理解与生成就能一起涨。
不管是 CLIP 还是 SSL,只要把语义表征注入进去,generation vs understanding 就开始同向改善,而且随 FLOPs 增长持续提升。
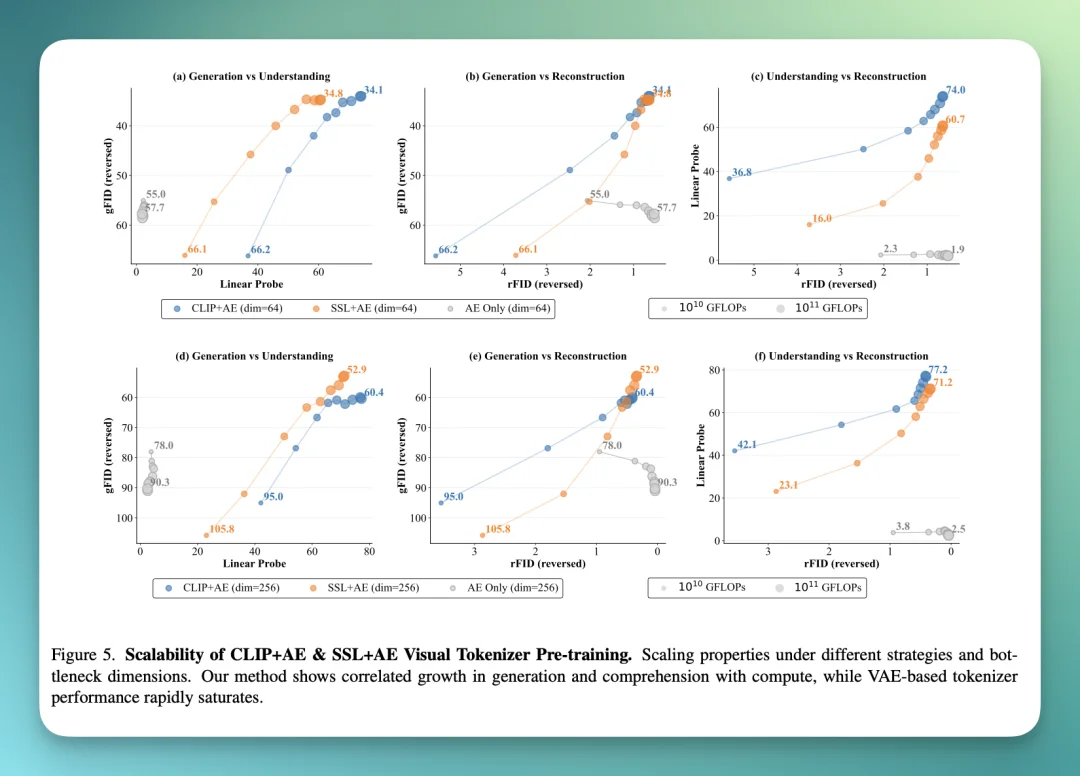
上面这条曲线应该是整个论文中最有美感的之一了。因为它展示了理解力(Linear Probe Accuracy)与生成力(gFID)呈现正相关。
而且,在同等算力预算下,CLIP+SSL+AE 的上限最好,生成与理解指标都最强。
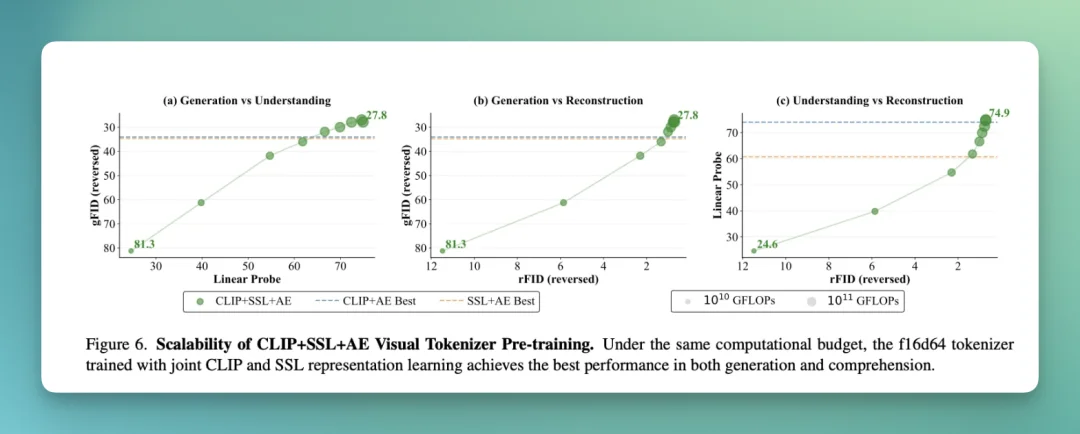
这可能意味着,以后就不用再碰运气。只要能把 Tokenizer 的语义理解能力提上去,下游生成的质量就大概率会提升。
而且,我还看见一张非常关键的图:VTP 有「新曲线」,传统 AE 没有。
当 Encoder 越大时,VTP 的 gFID 稳定下降(变好),AE 基本不动。数据越多,VTP 明显变好,AE 几乎没收益。
甚至 Decoder 规模也能带来额外改进:
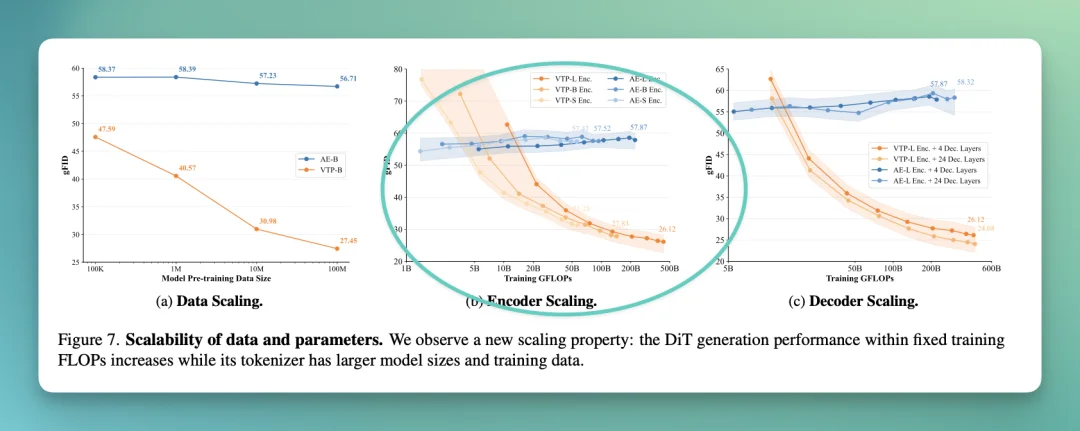
论文里还给了一个数字:在不改 DiT 标准训练配置的前提下,只靠把 tokenizer 预训练 FLOPs 放大,VTP 能带来 65.8% 的下游生成改进,而传统 AE 在 1/10 FLOPs 就已经饱和了。
这说明什么?
这说明,我们已经可以通过在预训练阶段「烧」更多的算力,来直接换取生成模型效果的提升。
Scaling Law 出现了。
那么理论之外,VTP 的实际成绩和效果如何?可以看下面这张图:
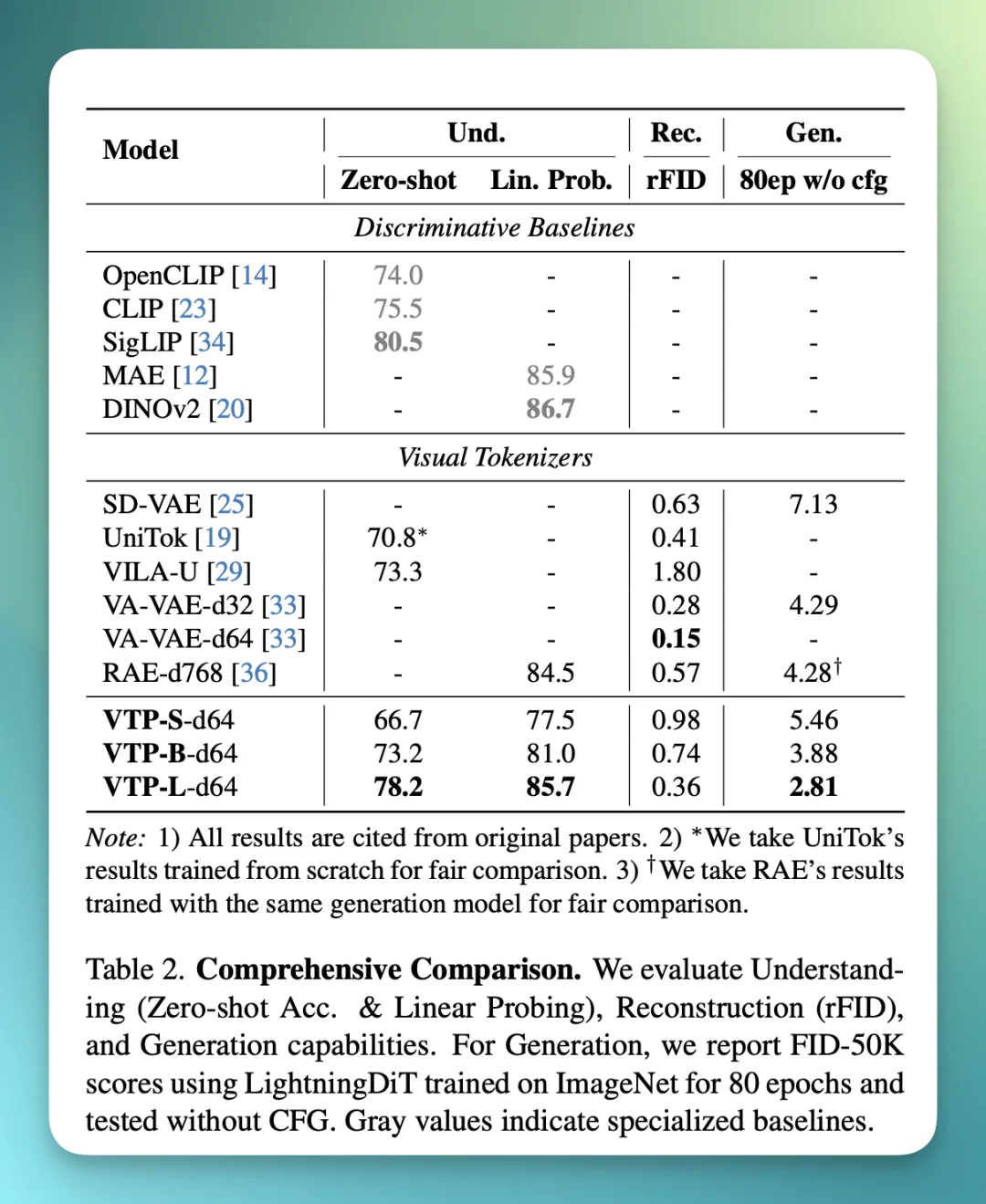
在标准的 ImageNet 基准测试中,VTP 交出了 SOTA 级别的成绩:
【1】零样本准确率 78.2%。
这说明它不需要微调就能极好地理解图像内容。
【2】重建质量(rFID):0.36。
证明引入语义理解并没有牺牲重建精度,反而相辅相成。

【3】收敛速度相比于基于蒸馏(Distillation)的方法(如 VA-VAE),VTP 在生成训练时的收敛速度快了 4.1 倍。
这意味着训练生成模型的时间和金钱成本将大幅下降。
总的来说,VTP 在 理解(zero-shot/linear probe)+ 重建(rFID)+ 生成(FID) 上都很强。
业界此前也有尝试过让 VAE 具备语义,比如通过蒸馏让 VAE 模仿预训练模型的特征。
比如,OpenReview 上就有一篇 ICLR 2026 的会议论文就指出了这一点:

但海螺团队说,这种「模仿」其实是有天花板的。
论文数据显示,VTP 这种从头开始联合预训练(Redesigned from the ground up) 的方式,比蒸馏方法拥有更高的性能上限。
此外,还有一种方案是直接用现成的 DINO 或 CLIP 特征做生成。
但 VTP 的对比实验显示,这种方法由于缺乏解码端的联合优化,重建出来的图片往往会存在色差和纹理丢失。而 VTP 在色彩准确性和微小纹理的保留上具有很大的优势。
总的来看,MiniMax 海螺视频团队的这次开源,意义不在于一个具体的代码库。
在学术层面,论文的结果告诉我们,Visual Tokenizer 不应该仅仅关注像素而要能够理解世界。
在工程层面,它找到了 Visual Tokenizer 的 Scaling Law。对于那些头秃于 DiT 效果没办法提升的团队来说,VTP 也许就是那个被忽视的「关键支点」。
当 Scaling Law 被证明能行、可行之后,下一代视频生成模型的能力,可能会再度被拉升。
这一次,模型将看得更清楚,理解得更深刻。
目前,VTP 的相关代码和论文已全部在 HuggingFace 和 GitHub 上开源。
对于想要学习 AI 视觉生成底层的朋友来说,推荐可以去看看,干货很多。
文章来自于微信公众号 “十字路口Crossing”,作者 “十字路口Crossing”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
