# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

上个月我从旧金山去纽约参加了 AI Engineer Summit,这是 AI Engineering 里每年最值得关注的硬核会议,也是一年一度头部 AI 工程师们的“聚会”。 它采用邀请审核制,由 Swyx (“AI Engineer”的提出者和头部专栏 Latent Space 的作者) 联合 Anthropic、Google Deepmind等公司举办,之前曾来到旧金山、巴黎,今年也是 AI Engineer Summit 的第三年。

纽约、时代广场、曼哈顿,三天里可以说是走了一个作为 AI 工程师最时尚的红毯。

整个的体验其实很好玩, 高密度的人和信息量,高效、切身地感受到了 AI 模型当前发展的阶段、瓶颈以及各领域里“大家都在做什么”。讨论的内容除了被熟知的 context engineering(上下文工程), vibe coding, 还有更技术向的 continous training(持续训练), DSPy and prompt optimization (提示词优化和 DSPy:一个系统性开发 llm 应用的开源 python 框架)。
现场活动的分享视频官方已经上传发布到 Youtube,感兴趣的可以到 Youtube 搜 “AI Engineer”频道观看,以下是我个人比较推荐的几个分享,附视频链接,感兴趣的可以自行前往观看。
Anthropic:
Anthropic: Don't Build Agents, Build Skills Instead
– Barry Zhang & Mahesh Murag

关注 Anthropic 的朋友应该已经看到或用上了他们最近发布的“Skill”,这里 Barry 和 Mahesh 一起分享了 Anthropic 背后 building Prompt → Agent → Skills 的路线,已经他们是怎么从搭建 agent 发展到开始搭建 skill 的。
Netflix:
Netflix: The Infinite Software Crisis
– Jake Nations
Netflix 的软件工程师 Jake 分享了他们的一个企业级大型代码迁移项目,是如何运用 AI 编程提高大型软件生产环境级别的工作效率,而不仅仅是 vibe coding。 里面的洞察很有实践性, 比如如何压缩codebase的上下文, 如何最精细化的计划给 agent,即便在用 AI 写代码,也注意不要略去自己的思考(Don’t outsource your thinking.)
Every:
Every: Dispatch from the Future: building an AI-native Company
– Dan Shipper:
关注 Dan 很久了,他创立了 AI newsletter ‘Every’, 后面把整个媒体变成了 AI Product studio,这也是一个我很喜欢的组织模式,他们在一边写文章拥有读者群的同时一边以“超级个体式”的组织形式开发自己的产品,目前已经有正在运营的四个产品,每个产品均由一个工程师全权开发负责。在这里他分享了 AI 是如何放大产品开发的势能,以及如何打造一个 AI-Native 的组织。
The Browser Company
From Arc to Dia: Lessons learned building AI Browsers
– Samir Mody
Sam 是浏览器 Arc 和 Dia 的公司 The Browser Company 的 Head of AI Engineering, 分享了他们“为什么”以及“如何”会从 浏览器 Arc 转到做 AI-Native 的 AI 浏览器 Dia,以及对浏览器产品开发和团队内部 AI 工具开发和使用的思考。
Sizzy
Sizzy: Vibe Engineering
– Kitze

Kitze 是一个欧洲的独立开发者,他从前端开发入手分享为什么如今 vibe coding 还是没办法识别、更改某个css组件,并分享了如何 Vibe Engineering 而不是单纯的 vibe coding。他是全场最搞笑的人,一个欧洲人在美国的 AI 旅途视角。
Sam Altman 在之前的一次访谈中提到下一个 AI 的突破点不是推理,而是“记忆“,即如何记住用户的历史对话、邮件和各种文档,并从中识别、提取其中的”模式“。我最近几个月主要的工作也基本集中在如何让模型更好地拥有对用户的记忆,涉及对记忆的分析、存储和检索。

本文结合会议期间一个关于 AI Memory 和 RAG 的工作坊和我最近做 AI Memory 的思考来系统性梳理 AI Memory 的模型层路线,属于 AI Memory 系列的第二期,第一期是用 Context Engineering 来做 memory,即把 Memory 放到上下文里。如果想了解“什么是 AI memory” 、“什么是 context engineering” 以及如今 ai memory 的基本框架可以看我上一篇文章回到事物本身:从搭建Context Engineering到现象学记忆。
下文内容偏技术实操,感兴趣的读者可以继续,涉及以下内容:
我最近也在构建一个结合知识图谱的 AI Memory 开源项目,有兴趣 contribute 的朋友可以到文末获取我的微信号进行交流。
一、RAG 为什么不好用了
很多人说 ”RAG 已死“,但它的局限性到底在哪?今天我们大多数人都是这样用 RAG 的:
然而:这套技术栈虽然简单方便,但存在深层的局限性。
1. 传统的文本嵌入(embedding)过于单一
如今我们采用 OpenAI 或者 Cohere 等嵌入模型将文字转化成向量,这一通用的方法存在一个假设是:“存在一个通用的语义几何空间,所有的信息都可以在这个空间里表示”。但真实场景里并非如此。
Jack 分享了一个他博士期间研究的一个信用卡例子:他们构建了一个数据集,文档大约一半关于 Visa 卡,一半关于 MasterCard 卡。标准嵌入将所有这些信用卡文档放在了嵌入空间的一个紧密区域内。本应只检索 Visa 文档的查询却拉进了 MasterCard 的文档,因为两组数据几乎住在同一个"邻域"里。Visa 和 MasterCard 的聚类过于接近。
"单一全局语义空间"无法反应垂类信息
通用的嵌入模型最初的训练目标是捕捉整个网络或预训练语料库的全局语义。而当我们使用它嵌入垂类信息(比如支付、内部政策、气候数据、企业工作流),这种全局几何反而会损害检索质量:
→ 在专业场景下检索质量会下降,因为嵌入无法根据领域或任务调整其相似性概念。
文本嵌入的基本假设:存在一个通用的语义几何空间,所有的信息都可以在这个空间里表示。
2. 向量数据库并不一定安全
业界有一个普遍的信念:"我们只存储嵌入,不存原始文本,所以数据是安全的。"这可能是错的。“
嵌入有可逆性(embedding):Jack 在博士期间构建的一个系统中他发现:仅凭向量数据库中的嵌入向量,一个独立的模型就能重建底层文本。通过迭代、多轮纠正的过程,当序列达到一定长度时,系统可以精确恢复约 90% 的原始文本。
→ 嵌入不是某种不透明、无意义的噪声——它们是原始文本的有损但仍高度信息丰富的编码。
这意味着潜在的攻击者其实可以把你的向量数据库当明文处理。任何能访问嵌入且具备一定机器学习能力的人,都可以训练一个解码器模型来重建原始文档。Pinecone、Turbopuffer 等"只存向量"的架构通常假设"只有嵌入"是安全的——这个假设是错误的。
特别是对于敏感领域(金融、医疗、企业内部数据),向量数据库相比存储原始文本,基本上没有真正的安全优势。
3. 向量数据库的运维成本
除了安全问题,大规模高维索引的成本高昂且复杂。对于拥有海量敏感数据的组织,向量数据库带来了成本、复杂性和风险,却没有足够可靠的安全收益。
二、上下文嵌入(Contexual Embedding):嵌入领域上下文
为了解决 RAG 通用局限性的问题,Jack 提出一种上下文嵌入的路线(Contexual Embedding),它根据周围文档来调整文本的嵌入位置。这时候模型不再孤立地嵌入每个文档,而是输入两部分内容:
嵌入过程中,模型学会:
从架构上看,有两个阶段:
和一般的嵌入(embedding)有什么不同?
1.更清晰的领域区分
在 Visa/MasterCard 的设置中,上下文嵌入大幅降低了跨品牌的相似度。训练后,Visa 和 MasterCard 文档之间的相似度降至约 0.144,而 Visa-Visa 的相似度保持较高。对于以 Visa 为中心的查询,系统拉入 MasterCard 文档的可能性大大降低。
2.在小众/长尾任务上表现更好
在大型、广泛的基准测试如 MS MARCO(网络规模搜索)上,采用这种方式来添加上下文信息变化不大,因为通用的嵌入已经可以相当好地捕捉全局语义。但在更垂的领域——金融、气候、专业科学文章、更垂的领域公司语料库——上下文嵌入显著优于标准嵌入。
三、AI Memory:把 Memory 训练到模型里
单纯的 RAG 解决了基本检索扩展性和时效性问题,但有些问题是当前检索方法处理不好的:
对于这些,模型需要真正学习这个领域,而不仅仅是在上下文中"见过"它,而这需要在模型层面做训练,把“知识”存储到模型里。
语言模型可承载的信息容量是有限的
LLM 的一个重要约束:每个参数的信息容量是有限的。实证研究表明每个参数能承载的信息量是每参数约 3.6 比特。一个 10 亿参数的模型可以存储大约几个 GB 的信息(约 2,000-5,000 本书,一本书大约 500KB-1MB),而不是 TB。对比而言,LLM 的训练数据通常是 TB 级别的(比如几万亿 token),但模型实际能"记住"的信息只有几个 GB。
训练本质上是一个有损压缩过程:模型尽可能拟合训练分布,然后丢弃其余部分。这引出了一个问题:我们真的希望模型把可以记住的信息花在比如”塔吉克斯坦最小省份的首府是什么“这样的问题上吗?在构造产品的过程中我们关心的其实是领域知识、它需要专注且垂直。
这不是说如今的大语言模型”什么都知道“没有用,而是通用预训练让模型装满了大量可能与任何特定部署都不相关的琐碎知识。对于做应用的产品团队,这些容量可以更好地用于内化自己的数据。那么如何使用通用模型内化我们的领域数据?
监督微调(SFT)、强化学习和合成数据
如何在不干扰基座模型的情况下,真正把新知识或者记忆注入模型?下面总结几种目前领域里常用的训练范式:
1.朴素方法:SFT(监督微调,Supervised Fine-Tuning)
一个关于 3M 财务报告的实验说明了 SFT 的局限性:一个模型在 3M 的 10-K 报告上进行了微调,使用简单的下一个 token 预测(即对原始文本进行普通 SFT)。模型在该文档上实现了零损失——完美记忆。但当被问到一个稍有创意的问题,比如:
"写一首关于 3M 2025 财年的诗"
模型的输出退化成了没有智力的胡言乱语,类似于:
"一段话的段落是一首诗。"
所以:
记忆 ≠ 理解或泛化。
对原始文档进行完全 SFT 会用脆弱、过拟合的行为覆盖模型更广泛的能力。
2.强化学习(Reinforcement Learning)
大多数 LLM 的训练路径是 Pretrain → SFT → RLHF,SFT 让模型具备基础能力,RL 进一步优化对齐。对比 SFT 和 RL 的两种调模型机制:
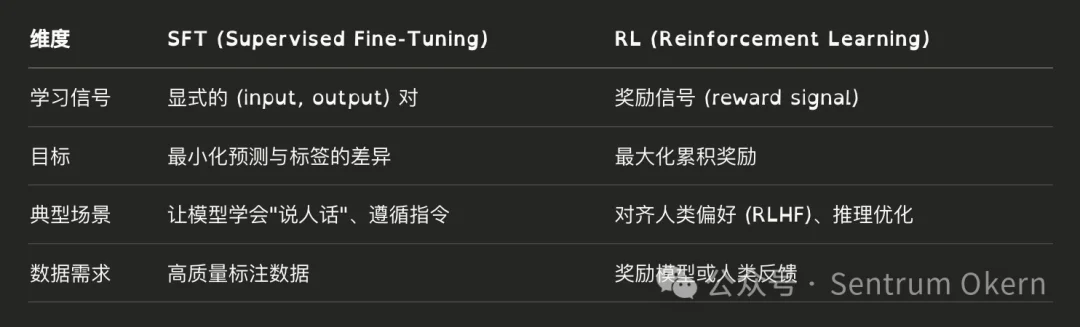
监督微调 SFT
强化学习 RL(如 GRPO)
Jack 分享了一个即将发布的实验结果:对于数学推理基准测试(GSM8K):
使用 RL 微调,通过精心设计的低秩适配器结构,只训练 14 个参数(不是 14M——是 14)就能达到约 91% 的准确率。在极端设置中,甚至 1 个可训练参数也能产生可测量的改进(约 5% 的提升),通过巧妙使用随机投影和一个控制它们的标量。
基于强化学习的微调可以在单位参数的表现上极其高效,因为微调的目标是稀疏且聚焦的。SFT 虽然强大,但往往需要修改更多参数来吸收密集的监督,这更容易导致遗忘。
3.合成数据与持续预训练
合成数据是模型训练过程中的一个核心突破口,这种方法已在近期工作中被形式化和验证,即从小型种子语料库使用模型生成合成训练数据,然后在此基础上训练,而不是仅仅使用原始文档。
数据合成的方式:
一个比较惊喜的发现:LLM 现在在数据生成方面已经足够好,只要流程设计得当,可以实现生成高质量训练数据。
合成持续预训练(Synthetic Continuous Pre-training):指在预训练后使用领域内的合成数据进一步进行预训练,
在规模化(数亿到约 10 亿 token)后,以这种方式训练的模型可以在特定目标领域上超越 GPT-4。
四、模型是怎么训练的,如何做 Post-training?
当模型在新数据上微调时,早期的能力有可能会退化。那么:
如何在不让模型忘记其他所有东西的情况下添加新知识与记忆?
首先来回顾一个大语言模型(比如 ChatGPT)是怎么被从 0~1 训练出来的。
LLM 训练分为两大阶段:Pretraining(预训练)和 Post-training(后训练)。预训练阶段用海量无标注文本通过 Next Token Prediction 让模型"学会语言",产出一个懂语言但不听话的基座模型。Post-training 阶段则让模型"学会做事",包括:

在 Post-training 阶段,一个关键问题是:我们真的需要更新所有参数吗?全参数训练代价高昂且容易让模型遗忘已有能力,因此业界发展出多种高效微调策略,核心思路是"冻结大部分参数,只更新关键部分",从而让模型在不忘记基本价值观和智力的同时,记住我们希望其获得的领域知识。
在 Post-training 的各阶段微调中,需要思考的一大问题是"更新哪些参数,根据是否改变模型结构,可分为两类:
三个参数层的模型微调方法:
1. 全参数微调
即更新 Transformer 的所有参数。容量最高,但:
2. LoRA(低秩适配)
LoRA(Low-Rank Adaptation),是一种经常被用到的微调方法。它不更新完整的权重矩阵,而是在线性层中插入低秩适配器。这些适配器相对较小(每个任务或每个用户几 MB),且可以在推理时组合、交换和批处理。
讨论的实证发现:"LoRA 学得少但忘得也少"。一篇被引用的论文表明,在 SFT 下:
RL 实验强化了这一点:对于 RL,即使是微小的 LoRA 风格更新也可以神奇地有效。
3. 前缀(Prefix)/ KV 缓存调优
Prefix Tuning 微调,又被称作 KV 微调,是指保持基础模型冻结,训练一个学习到的"前缀"或键值缓存,来调节模型的注意力层。它在模型每层 Attention 的 K 和 V 前面加可学习的"虚拟 token",让模型每次计算都能参考这些额外信息,而不用改动任何原始权重。
实际上,模型的行为就像每个输入都被预置了一个学习到的序列,这在注意力空间而不是在推理层实现的。一些发现:
从系统角度来看,Prefix 微调非常有吸引力,因为:
两个扩展模型架构的微调方法——先给模型加新组件,再训练新增部分:
1. MLP 专家和混合专家
MoE:(Mixture of Experts)是指把 Transformer 里的 MLP 层换成多个"专家",每次只激活其中几个。

现代大型模型通常有混合专家(MoE)MLP 层,其中路由网络选择应用哪个专家。
一个自然的想法是添加专门针对新数据或用户的新专家,并只将某些输入路由通过这些专家。这提供了一种选择性扩展模型容量的方式,而无需重新训练所有东西。例如 Cursor 最近发布的自研 Composer 模型就采用了 MoE 架构,不同专家可能分别擅长 Python、TypeScript、系统设计、Debug 等任务,Router 根据输入自动选择合适的专家处理,既保持了模型的通用能力,又能在特定编程任务上表现出色。
2. 记忆层
Memory Layers 是在 Transformer 网络内部引入的"记忆层":一个大型可微分查找表,根据输入相似度检索相关信息。微调时主要或完全限制更新到这些记忆层,同时保持核心 Transformer 权重不变。记忆层通常加在 Transformer Block 的 MLP 之后(或替换部分 MLP),只在部分层添加,作为可训练的"知识检索模块"。
这种方式的优势是在相对局部化的组件中拥有高容量,并且强有力地控制什么被更新以及基础模型改变多少。研究表明,Memory Layers 提供了最佳的权衡:几乎没有遗忘(旧任务性能保持不变),同时新知识上的收益几乎与全参数微调一样多。这种"核心推理能力与知识存储分离"的思路,也被应用在 RAG(检索增强生成)和各类 Agent 记忆系统中——模型本身负责推理,外挂记忆负责存储和检索事实知识。
五、用 RAG (短期记忆)还是训练模型(长期记忆)?
RAG 不好,那我们还应该用 RAG 吗?答案是:RAG 和上下文窗口不会消失,它会被用于存储、检索短期记忆。
对于新鲜数据、不断变化的来源,或高度个性化、短期的信息,检索将是必不可少的。存在实际的经济权衡:频繁重新训练是昂贵的;RAG 在推理时满足适应性。
而从系统的角度思考,一个AI 系统由三部分模块组成,更好的系统在某处会有更高成本:
Deep Research 风格的智能体搜索(多步骤、搜索-反思-推理的智能体),衍生的一个问题是"我们是在训练时付出更多(训练进权重),还是在推理时(智能体搜索配合 RAG),还是在数据策划上(合成数据生成)?"
目前还没有单一技术栈会在所有用例中占主导地位,当前对于把记忆/知识"训练进权重"这一研究的实验才刚刚开始。正确的平衡取决于:
模型训练从最底层训练、记忆领域知识,它适用于:
模型训练的可扩展性
这种"权重即记忆"的范式能扩展到数千万或数亿用户吗?
可以但只能使用参数高效的方法。
因为我们不可能为每个用户存储和服务一个万亿参数模型的完整副本,但却可以存储每用户的 LoRA 适配器或类似模块,大小在几 MB 范围内,想象成每个用户在共享基础模型之上有一个小的、个人的"叠加层"。如今像 Thinking Machines 这样的公司已经开始构建起这一的基础设施:
模型训练的更新频率
真正的实时持续学习仍然很难。
一个现实的近期方案是类似于每天或每会话批量更新,而不是每次交互都更新。
随着时间推移,随着工具改进(如热交换适配器、高效多适配器内核),这可能会向更频繁的更新方向发展。
六、未来的 AI Memory:混合记忆模型架构
从数据存储角度而言,知识图谱、SQL 和结构化工具:知识图谱可以显式编码嵌入难以处理的关系:像"是...的子公司"、"是...的卡网络"、"与...不兼容"等边。对于细粒度区分(如卡网络逻辑、产品层次结构),图可以提供纯连续嵌入缺失的结构。
展望未来的 AI,它会从如今的一个静态、单体的模型,"知道整个互联网",依赖 RAG 来补充具体细节,走向专业化、可教的模型,每个都深度熟悉特定领域、组织,甚至个人用户。
我想,未来一个好的记忆系统应该是一个混合系统,它有:
因为单靠某一种嵌入或 RAG 是不够的,而我们也需要探索自己的混合记忆系统。未来的 AI memory 记忆架构也将包括两部分:
在那时,“每个人都拥有一个个人助手”这一 Sam Atman 所说的未来将会实现。
它拥有我们所有的记忆,并在持续从当前积累新的记忆、形成新的“自我”。
我最近在开发一个结合知识图谱的 AI Memory 开源项目,感兴趣 contribute 的 读者可以加我的微信(la_vela)进行备注,希望你有开源精神和 AI Engineering 的实操代码经验 。
推荐视频:
1.https://www.youtube.com/@aiDotEngineer
2. https://www.youtube.com/watch?v=CEvIs9y1uog
3. https://youtu.be/eIoohUmYpGI?si=HyLwIgPZVzWZIKq5
4. https://youtu.be/MGzymaYBiss?si=mB8RF2vhKiOQ5dtM
5. https://youtu.be/o4scJaQgnFA?si=31Fdv3AxYEP_LSFh
6. https://youtu.be/JV-wY5pxXLo?si=VUwnS3C61E5n3089
“在技术发展的过程中保持人文的清醒,在人文反思的过程中拥抱技术的可能。”

Vela
AI Engineer
San Francisco, California, US
文章来自于微信公众号 “Sentrum Okern”,作者 “Sentrum Okern”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
