# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“我把一段自己都说不清楚怎么工作的代码,上了生产环境。”
台下先是一阵笑声,接着是掌声。
在一场技术演讲中,Netflix 工程部的资深大牛 Jake Nations,开场就抛出了一个几乎所有工程师都心照不宣的“坦白”。
几乎每个正在使用 Copilot、Cursor、Claude 写代码的人,都干过同一件事:让 AI 生成代码,看起来没问题,就直接交付。测试通过、功能可用、部署成功,但当系统真的在凌晨三点出问题时,没人能再说清楚它为什么还能跑。
问题就在于,这一次不一样了。过去,写得慢至少意味着你还有时间理解;现在,代码几乎是“秒出”的,而理解却依然是线性的。于是一个诡异的局面出现了:
我们比任何时候都更高效,却也比任何时候都更不清楚自己在维护什么。

然而,Jake 并不反对 AI。相反,他已经摸索出了一套在大型工程系统中使用AI 工具落地的方法。在 Netflix,原本要几天的任务缩短到几小时,拖了多年的重构终于被“解锁”。
但Jake指出了一个核心问题,AI并不会改变一件事:软件是为什么失败的!AI并不知道纠缠在一起的两类复杂性:偶发复杂性和本质复杂性。
也正是在这里,他看到了上面提到的风险。软件行业的历史一次次证明:每一轮生产力跃迁,都会以“复杂度失控”的形式反噬工程师。每一代工程师都会撞上一堵墙!
1968 年,“软件危机”(Software Crisis)这个词首次出现,当时的软件系统已经复杂到开发者难以掌控。
此后每一代人似乎都靠更强大的工具“解决”了它,然而结果却只是制造出了更大的问题。
而今天,AI 同样把这一模式推向了极端,演化为“无限软件危机”。
“我们正在用 vibe coding 的方式,一路写向灾难。每一次跟AI聊天的澄清、每一次临时转向,都会被直接固化进系统架构中。”

如何在大模型的语境下,在“千百倍速提升效率”的同时,还能让开发者理解生成的代码呢?
Jake分享了自己在Netflix的三阶段方法论,作者也称为“上下文压缩”方法论:
最后,Jake 表示其实这个方法论并不是什么魔法,重要的不要丧失“理解代码“”和“模式识别”的能力:
真正能在这个时代持续成长的开发者,不是写代码最多的人,而是仍然理解自己在构建什么、能看见系统的“接缝”、能意识到自己正在解决错误问题的人。
话不多收,全程虽然只有18分钟,但干货全在其中。
下面是小编特别整理的演讲内容,希望能帮助到各位。
大家好,下午好。我想用一点“忏悔”来开始今天的分享。
我交付过自己并不完全理解的代码。代码是生成的,测试也跑过了,部署上线了。但你要我解释它是怎么工作的?我说不清。不过说实话,我敢打赌,在座的每一个人都干过同样的事。(现场一片掌声。)
所以,我要更直接一点地说:我们现在都在交付自己并不真正理解的代码。
今天我想带大家走一段路,看看事情是怎么一步步发展到现在的。
过去几年,我在 Netflix 负责推动 AI 工具的落地。
必须说一句:这种加速是真实存在的。以前要花几天才能完成的 backlog 任务,现在几个小时就能搞定;堆了好几年的大型重构,终于被动手完成了。但问题也在这里。
大型生产系统一定会以你预料不到的方式失败。看看最近 Cloudflare 发生的事情就知道了。
而当它真的出问题时,你必须理解你正在 debug 的那段代码。可现在的现实是:我们生成代码的速度和规模,已经快到——理解能力跟不上了。

说实话,我自己也干过这种事。
我生成了一大堆代码,看了一眼,心想:“我完全不知道这段代码在干嘛。”
但测试是绿的,功能是好的。于是,我就把它交付了。关键在于:这件事并不新鲜。
每一代软件工程师,都会在某个阶段撞上同一堵墙:
软件的复杂度,超过了我们管理它的能力。我们并不是第一批遭遇“软件危机”的人。
只是第一次在这样一个“近乎无限生成”的规模下遭遇它。
时间回到 60 年代末、70 年代初。一群当时最聪明的计算机科学家聚在一起,说了一件事:“我们正处在一场软件危机中。”
需求巨大,交付跟不上;项目周期太长,进展太慢;整个行业都做得不太好。
这时,Dijkstra 说过一句很有名的话(我稍微意译一下):
当我们只有几台性能孱弱的计算机时,编程只是个小问题;
而当我们拥有了庞大的计算机,编程就变成了一个巨大的问题。
这里的意思是:硬件能力提升了一千倍,社会对软件的需求也同步放大了一千倍。而夹在“需求”和“能力”之间的,正是程序员。

这种循环不断重演:
而今天,我们迎来了 AI。
Copilot、Cursor、Claude、Codex、Gemini……只要你能描述出来,就能生成代码。这种模式还在重复,但规模已经彻底变了。
现在几乎是无限的。

1986 年,Fred Brooks 写了一篇论文,叫《No Silver Bullet(没有银弹)》。
他的核心观点是:不存在任何单一技术,能让软件生产率提升一个数量级。
为什么?因为真正难的,从来不是“写代码的机械动作”——不是语法、不是敲字、不是样板代码。
真正难的是:理解问题本身,并设计出正确的解决方案。
而这一点,没有任何工具可以替你完成。到目前为止,我们发明的所有工具,都只是让“机械部分”变得更轻松。

但核心挑战始终没变:你要构建什么?它应该如何运作?为什么我们一直在优化“容易”,而不是“简单”?
如果问题不在机械层面,那为什么经验丰富的工程师,还是会交付自己看不懂的代码?
答案在两个我们经常混用的词上:simple 和 easy。
我在演讲者晚宴上被“揭发”是个 Clojure 派,所以这个例子很自然。
Rich Hickey 在 2011 年的演讲《Simple Made Easy》中,对这两个词做过非常清晰的区分。
一句话总结:Simple 关乎结构,Easy 关乎距离。

问题在于:你无法靠“希望”让一件事变得简单。
简单,需要思考、设计、拆解和去缠绕。但让事情变得容易却很简单:装个包、让 AI 生成、从 Stack Overflow 抄一段。人类天生就会选择容易的路。
答案就在眼前,框架自带“魔法”,装完就能跑。
但——容易 ≠ 简单。
每一次选择“容易”,本质上都是在用现在的速度,交换未来的复杂性。
过去,这种权衡是成立的。复杂性积累得足够慢,我们还有时间重构、反思、推倒重来。
但 AI 改变了一切。它是终极的“easy button”。它让“容易”变得几乎没有摩擦。结果是:我们甚至不再考虑“简单”那条路了。当代码可以瞬间出现,谁还愿意停下来想架构?
我来给你演示一下,这种事情是怎么发生的:一个原本很简单的需求,如何在我们已经习以为常的对话式界面中,一步步演变成复杂度失控的烂摊子。
假设我们有一个应用,需要加认证功能。我们让 AI “加一个 auth”,它给了我们一个看起来很干净的 auth.js;继续迭代几轮,又多了一个 message 文件,一切都还算合理。
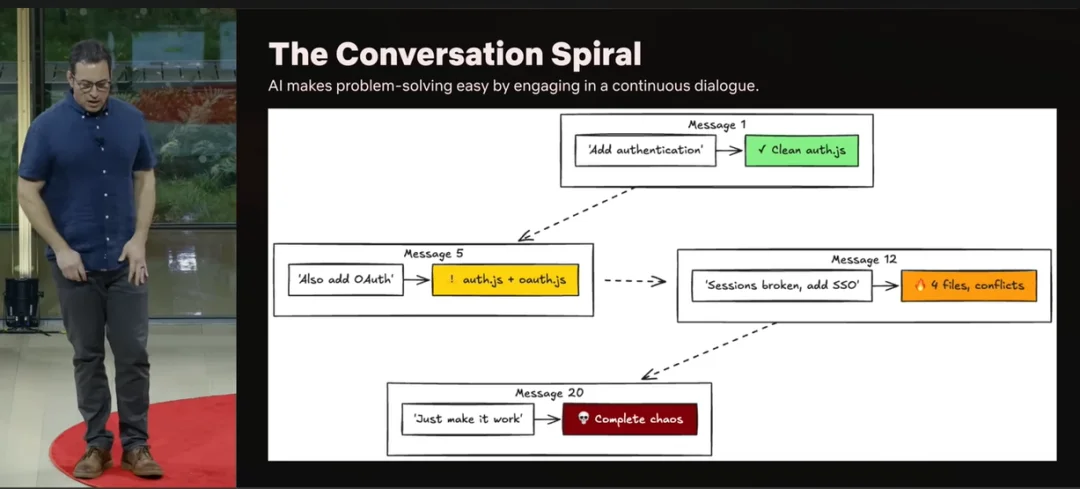
接着我们又说:再加 OAuth 吧,于是 auth.js、oauth.js 都出现了。再往后,session 开始出问题,冲突越来越多。到第 20 轮对话时,你已经不是在“讨论方案”了,而是在勉强维持一个你自己都记不清约束条件的上下文:有被放弃方案留下的死代码,有“为了让测试过而改”的测试,还有三套互相叠加的实现,因为每一次新指令,实际上都在覆盖原本的架构模式。你说“让这个能跑”,它就让它跑;你说“修这个报错”,它就修。系统对糟糕的架构决策没有任何阻力,只会不断形变以满足你最新的要求。
这正是迭代式 AI 对话接口的问题所在:每一次交互,本质上都是在选“容易”而不是“简单”,而“容易”的必然结果就是复杂度持续累积。我们其实都知道这一点,但当那条容易的路真的毫无摩擦时,人就会下意识地走上去,直到复杂度开始反噬,一切已经来不及。
AI 把“容易”推向了逻辑上的极限:你只需要决定想要什么,代码立刻出现。但危险也在这里——生成代码会把代码库里的所有模式一视同仁地保留下来。对代理来说,第 47 行那个认证判断是模式;2019 年遗留下来、用 gRPC 写得像 GraphQL 一样的怪代码也是模式。技术债在它眼里不是债,只是更多代码。真正的问题仍然是复杂性:它的本质就是“纠缠”,一旦系统变得复杂,任何一处改动都会牵动十处其他地方。

回到 Fred Brooks 的观点:他把复杂性分成两类。第一类是本质复杂性,也就是问题本身不可避免的难度——用户要付钱、订单要履约,这些决定了系统为什么存在;第二类是偶发复杂性,包括各种权宜之计、防御性代码、曾经合理但早已过期的框架和抽象。在真实代码库里,这两种复杂性往往缠在一起,想要区分它们,需要背景、历史和经验,而生成式 AI 并没有这种判断力,于是所有模式都会被原样保留、不断叠加。
我们在 Netflix 就遇到过这样的真实案例:系统里有一层抽象,夹在五年前写的老授权逻辑和新的集中式认证系统之间,当初只是没时间重构,临时垫了个 shim。现在有了 AI,看起来是个“顺手重构”的好机会,但现实是老代码和授权模式耦合得太深:权限检查嵌在业务逻辑里,角色假设写死在数据模型中,授权调用散落在上百个文件里。代理一开始还能改几份文件,很快就卡在解不开的依赖上,要么直接放弃,要么更糟——用新系统把旧逻辑原封不动地再实现一遍。它看不到“场景”,只看得到“模式”。

它没法判断业务逻辑从哪里结束、认证逻辑从哪里开始,一切都纠缠在一起。复杂度一旦纠缠到这种程度,就算信息再完整,AI 也找不到一条清晰的路径。更现实的是,当偶发复杂性已经失控时,AI 并不会真正把事情变好,往往只是在原有基础上继续叠层。人是能分辨这些差异的,至少在我们肯慢下来思考的时候。我们知道哪些模式是本质的,哪些只是几年前某个人当时的解决方式。这些上下文是我们脑子里带着的,但前提是:在动手之前,先花时间把这些区分想清楚。
那具体该怎么做?
当你面对一个巨大的代码库,如何拆分本质复杂性和偶发复杂性?我在 Netflix 工作的代码库大约有一百万行 Java,核心服务按我上次看差不多有五百万个 token,任何我能用的上下文窗口都装不下。
我最初的直觉是:要不干脆把大段代码塞进上下文,看能不能自己浮现出模式。但结果和前面那个授权重构一样,生成结果很快迷失在自身的复杂性里。于是我被迫换一种方式:主动选择要给什么。设计文档、架构图、关键接口、核心约束,我把“组件如何协作、应遵循哪些模式”写得一清二楚。实际上,我是在写一份规格说明——五百万个 token,被压缩成两千字的 spec;接着我再把 spec 拆成一组精确的执行步骤,没有模糊指令,只有清晰的操作序列。结果是:生成的代码更干净、更聚焦,而且我自己能理解,因为它是我先定义、先规划过的。
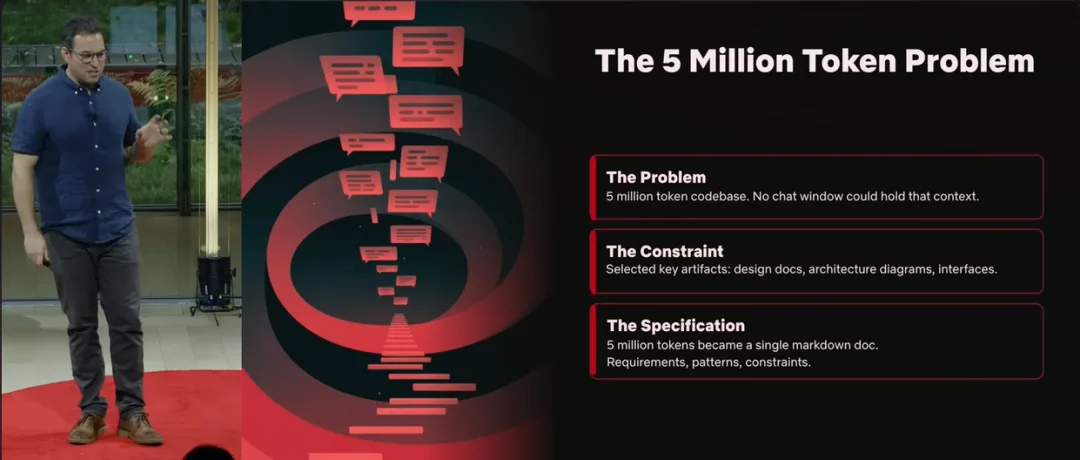
我把这种方法叫作“上下文压缩”,你也可以叫它“上下文工程”或者“规格驱动开发”,名字不重要,关键在于:思考和规划,占据了大部分工作量。实践中,我一般分三步。

第一阶段是研究:把与改动相关的一切上下文一次性喂进去——架构图、文档、Slack 讨论——然后让代理分析代码库,梳理组件和依赖关系。这不是一次性过程,我会不断追问缓存怎么做、失败如何处理,分析错了就纠正,缺上下文就补,每一轮都会让理解更精确。最终产出是一份研究文档:系统里有什么、彼此如何连接、这次改动会影响哪些地方,把原本几个小时的探索压缩成几分钟的阅读。这里的人类校验至关重要,这是全流程中杠杆最高的时刻,错误在这里被抓住,灾难才不会出现在后面。

第二阶段是实现方案设计:详细到代码结构、函数签名、类型定义和数据流,清晰到任何一个开发者照着做都能完成。我常把它比作“数字填色”,你可以把这份方案交给最初级的工程师,只要逐行照抄,就应该能跑。这一步是很多关键架构决策发生的地方,我们用经验提前发现问题,而 AI 没这个能力,它会把所有现有模式都当成必须遵守的要求。真正的优势在于评审速度:几分钟内就能确认到底会构建什么,也只有这样,我们才能在高速生成代码的同时,跟得上自己的理解速度。

最后才是实现阶段。有了清晰的研究和计划,这一步反而应该很简单——这正是目标所在。当 AI 跟着明确的规格执行时,上下文保持干净、聚焦,我们避免了冗长对话带来的复杂性螺旋,不再是 50 条消息不断“进化”的代码,而是三个彼此校验过的输出。没有被放弃的方案,没有冲突的模式,也没有“等等其实……”留下的满地死代码。对我来说,真正的回报在于:你可以把实现交给后台代理去跑,因为所有艰难的思考已经提前完成;你去做别的事,回来只需快速审查——你验证的是它是否遵循了你的计划,而不是判断它有没有凭空“发明”什么东西。

关键在于:我们并不是让 AI 替我们思考,而是用它来加速那些机械性的部分,同时保留我们对系统的理解力。研究更快,规划更充分,实现也更干净;但真正的思考、综合判断与取舍,仍然必须掌握在我们自己手里。
还记得我前面提到过、AI 一开始完全搞不定的那个授权重构吗?现在我们已经在这件事上取得了实质性进展,但原因并不是我们找到了更好的 prompt。恰恰相反,一开始我们甚至没法直接进入“研究—规划—实现”这套流程,只能亲手去改:不用 AI,一行行读代码、理清依赖、边改边看哪里会坏。说实话,这次手工迁移非常痛苦,但它至关重要——它暴露了所有隐藏约束、哪些不变量(invariants)必须成立、哪些服务一旦改动就会崩,这些都是任何自动分析都不可能替我们发现的。
随后,我们把这次真实的迁移 PR 作为“种子”喂进研究流程里,让 AI 以它为基准继续往前。这样一来,AI 才真正看到了什么叫“干净的迁移”。

即便如此,每个实体依然略有不同,有的加密、有的没加密,我们仍然需要不断追问、补充上下文,经过多轮迭代,才勉强生成一份有可能一次成功的计划——注意,这里的“可能”依然是关键词,我们还在持续验证、调整,并发现新的边界情况。
这套三阶段方法并不是什么魔法,它之所以有效,只是因为我们先亲手完成了一次迁移,先把理解“赚”到手,再把它编码进流程里。我依然相信不存在银弹,也不存在什么“更好的提示词”“更强的模型”或者“更完美的规格说明”,真正有用的只有一件事:对系统理解得足够深入,深到你能安全地修改它。
那为什么要费这么大劲?为什么不直接跟 AI 一路对话迭代,直到它“能跑”为止?模型迟早会变强,事情不就解决了吗?
对我来说,“能跑”远远不够。能通过测试的代码,和能在生产环境里长期存活的代码,是两回事;今天能运行的系统,和未来还能被他人安全修改的系统,也是两回事。真正的问题在于认知鸿沟:AI 可以在几秒钟内生成上千行代码,而理解这些代码,可能要花上数小时,甚至数天;如果纠缠得足够深,也许永远都理解不了。
更危险的是,当我们为了跟上生成速度而跳过思考时,失去的不只是理解代码的能力,还包括识别问题的能力——那个提醒你“事情开始变复杂了”的直觉,会在你不理解系统的情况下逐渐退化。

模式识别来自经验。我之所以能一眼看出危险的架构,是因为我真的在凌晨三点为它们善过后;我之所以坚持更简单的方案,是因为我维护过别人留下的复杂替代品。AI 只会生成你要求它生成的东西,它不会自动携带过去失败中学到的教训。三阶段方法的价值,在于它把“理解”压缩成可审查的产物,让我们能以接近生成速度的节奏来校验认知;否则,我们只是在以远快于理解能力的速度堆积复杂性。
AI 确实改变了我们写代码的方式,但说到底,它并没有改变软件为什么会失败。每一代人都会遭遇自己的软件危机,Dijkstra 那一代用“软件工程”这门学科来回应,而我们这一代面对的是无限生成的代码。解法不在于新的工具或方法论,而在于重新记起一件我们一直都知道的事:软件,本质上是一项人类活动。
难的从来不是敲代码,而是知道一开始该敲什么。真正能在这个时代持续成长的开发者,不是写代码最多的人,而是仍然理解自己在构建什么、能看见系统的“接缝”、能意识到自己正在解决错误问题的人。这一点,依然只能由人来完成,也只会由人来完成。
最后我想留给大家一个问题:问题不在于我们会不会使用 AI——那已经是既成事实;真正的问题是,当 AI 写下我们大多数代码时,我们是否还理解自己的系统。
原视频地址:
https://www.youtube.com/watch?v=eIoohUmYpGI
文章来自于微信公众号 “51CTO技术栈”,作者 “51CTO技术栈”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
