# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
告别碎片化!以全栈之姿,开启具身导航的 2026 新篇章。
【编者注】自 2018 年吴琦老师等人在CVPR发表第一篇 VLN(视觉-语言-导航)论文以来,这个领域已经走过了七年。在今年初AI科技评论的“具身先锋十人谈”中,吴琦老师曾回顾 VLN 与 VLA 的前世今生,并指出:数据匮乏、物理仿真缺失以及跨本体部署的鸿沟,是制约具身导航向前的三大“大山”。彼时,吴老师还透露,团队正在秘密打造一个全栈式平台,引发了圈内的无限遐想。
念念不忘,必有回响。 随着 2025 年步入尾声,吴琦老师带着他的深度思考与诚意之作正式回归。
在这篇文章中,吴琦老师正式推出了他在前一篇访谈中提及的那个“全栈梦”——VLNVerse,回顾并重构了 VLN 的版图。他指出,导航的本质是重感知与推理,而这正是模拟器的天下。针对目前领域内任务碎片化、实机部署难、sim2real 差距大等痛点,吴琦团队祭出了 2025 年的重磅贺礼——VLNVerse。这是一个涵盖了从场景生成(InteriorAnything)、高保真物理模拟(Isaac Sim 驱动)、五大统一任务基准,到跨本体通用模型(NavFoM)的全栈式“具身导航宇宙”。
从 InteriorAnything 的无限场景生成,到解决机器狗低视角难题的 Multi-view Transformer,吴老师团队不仅补全了此前未曾展开的技术版图,更在岁末之际,为 VLN 向 Embodied VLN 的跨越画上了圆满的句号。
旧岁将尽,万象更新。让我们随吴琦老师一起,走进这个打通 Real2Sim2Real 的具身导航新纪元。
要想理解具身智能导航是什么以及要解决什么就要先理解具身智能是什么。大家现在都在聊具身智能,但是到底什么是具身智能,很多人的概念其实还是很模糊,甚至单纯的把具身智能和机器人划等号,这是一种很错误的理解。具身智能分为两个词,一个‘具身’,一个‘智能’。先说‘智能’,我认为广义上的智能就是指一个‘智能体’能‘看’,能‘听’, 会‘说’,爱‘思考’还能‘动’。而‘具身’ (embodied)的含义,其实就是‘赋予身体’的意思,那么具身智能的概念便非常清晰了,就是给一个‘智能体’赋予一副‘身体’,而这个身体,可以是多种形态的,不一定非得是机器‘人’这么狭义的一个物理容器。

CVPR 2024 Embodied AI workshop上关于Embodied AI的定义
理解了具身智能的概念,具身智能导航要研究的问题就呼之欲出 ----- 一个具有物理本体(不限于机器人,无人机,无人车)的智能体能够依靠自身‘视觉’理解能力,‘听从’人类语言指令,依靠空间‘推理’,在真实环境中完成‘导航’任务,并且在需要的情况下和人类或其他智能体进行‘交流’。看、说、听、想、动再加个本体,这就是具身智能导航,就是我们今天要解决的问题的本质,缺一不可。
那么,视觉语言导航(VLN)呢?VLN又是研究什么的?其实,VLN研究的就是在抛开‘本体’的情况下的智能体的看、说、听、想、动(导航)的能力。所以早期甚至现在很多的VLN工作,都是只在simulator中进行的。我并不认为这有什么问题,因为很显然,即使是在simulation的环境下,这些任务也都没有被很好的解决。真正对VLN工作了解过的,也不会相信 ‘导航’是一个简单,甚至是已经被‘解决’的任务。不然,也不会有了‘空间智能’这个衍生的方向。

Peter Anderson,吴琦等人在CVPR 2018年首先提出了VLN这个任务
在今年的各个论坛和场合中,大家都会有一个争论,就是具身智能到底应该走模拟数据路线,还是应该走真机收集数据路线。真机派认为模拟数据以及模拟器中训练出的模型始终和实际环境存在非常大sim2real gap,模拟器中再好的模型,放在真机上,真实环境中,往往成功率偏低。二模拟派认为真机数据获取难度大,多样性不够,训练费时费力,而且换个主机或者环境,训练的模型也不一定能迁移的过去。
关于这个问题,我也思考过很多次,但是以我目前的理解和经验,不敢妄言哪个流派是对的,是‘大道’。但是,如果仅仅是放在具身导航这个领域内,这个争论,也许就不那么难解决了。我们都知道,目前具身智能主要分上半身和下半身,上半身抓取(manipulation),下半身移动(locomotion),而这两个方向其实都遵循一个工作流,就是 ‘感知,推理,执行’。
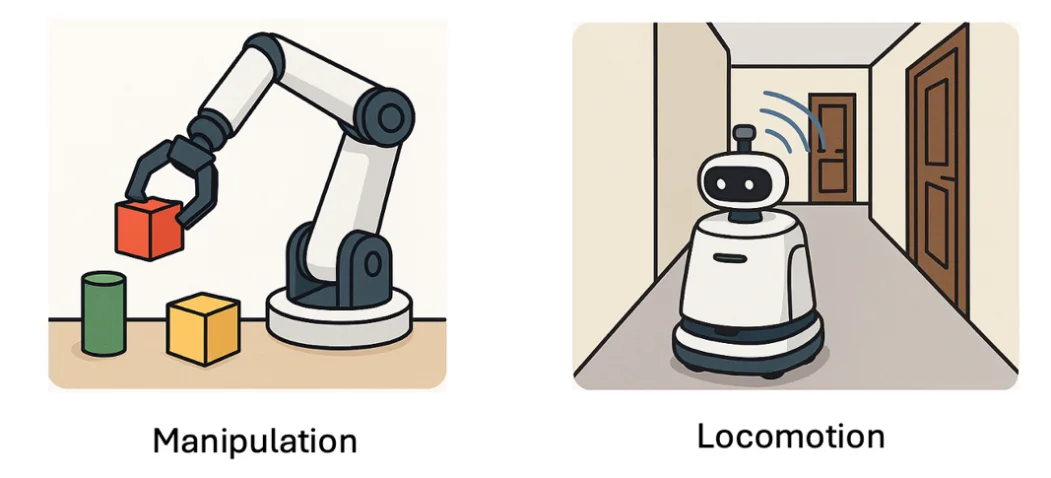
我认为(也许不一定对),manipulation应该重‘执行’,而轻‘感知和推理’,因为manipulation面对的操作环境不会特别复杂,甚至单一物体场景居多,那么相对来说对感知,理解,推理的要求会低一些,难点在于‘抓取和操作’本身,需要细粒度的控制信号。而这些控制信号,从真人演示,真机操作上可以获得很好很精准的数据,所以manipulation可能更倾向于真机派。
而我们反观locomotion,或者说navigation,其实真正的难点在于工作流的前端,‘感知和推理’。因为导航所要面对的环境是一个空间环境,而空间中的物体种类,位置千差万别,这就需要我们对空间理解,物理识别,语义理解有足够强的能力去拆解环境,推理出目的地的位置。而本体如何走到推理出的目标点位置,其实在目前的机器人领域,已经是解决的比较成熟的问题了。所以从研究的角度,我们可以说navigation其实是一个重‘感知推理’,而轻‘执行’的课题。而感知推理,空间理解,并不需要太多的真机数据和真人演示,simulator中模拟出的数据,只要仿真度够高,就可以训练出这些能力,尤其在数据多样性方面,模拟数据有天然的优势。所以可以说,单纯的从具身智能导航这个方向来看,我是妥妥的‘模拟派’。
既然信奉了‘模拟派’,那么我接下来思考的一个问题,就变成了‘如何打造一个足够好的模拟平台’去打通所有的VLN任务,以及最小化仿真与真实环境和本体的差距。于是,过去一年,我们从各角度发力,打造了一个全栈式’的Real to Sim to Real的Embodied VLN平台,VLNVerse。
何为全栈式?我认为的全栈式,应该是一个包含仿真环境生成(real2sim),具备物理仿真的模拟器(simulator),多种类和级别的任务数据(data and benchmark),端到端的VLA/VLN模型 (model)以及跨本体的真机部署(sim2real)。
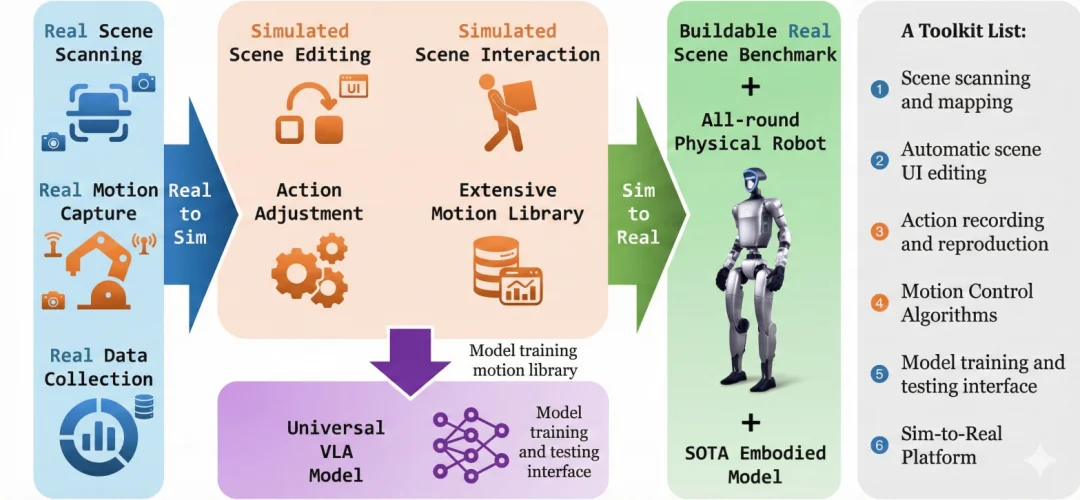
VLNVerse,全栈式Real 2 Sim 2 Real 具身视觉语言导航宇宙
我们又将这个全栈式的Real 2 Sim 2 Real宇宙分成了四个子宇宙,接下来给大家逐个介绍。
(1)宇宙一:Real to Sim
从构建训练平台的角度,这里的real to sim不是单纯意义上的数字孪生(Digital Twin),换句话说,像Mattport3D那样单纯的将真实环境扫描成点云或者模拟数据在模拟器中使用并不是我们所追求的。我们希望看到的是一个能够接受各种模态输入,然后可以生成无限个符合用户描述,但又具备一定随机性的3D环境。输入的模态可以是描述房间的文本,图像,视频,甚至是房间的设计草图等,而输出的3D环境需要足够真实(渲染,物理仿真),可编辑,可交互,又有足够的多样性。
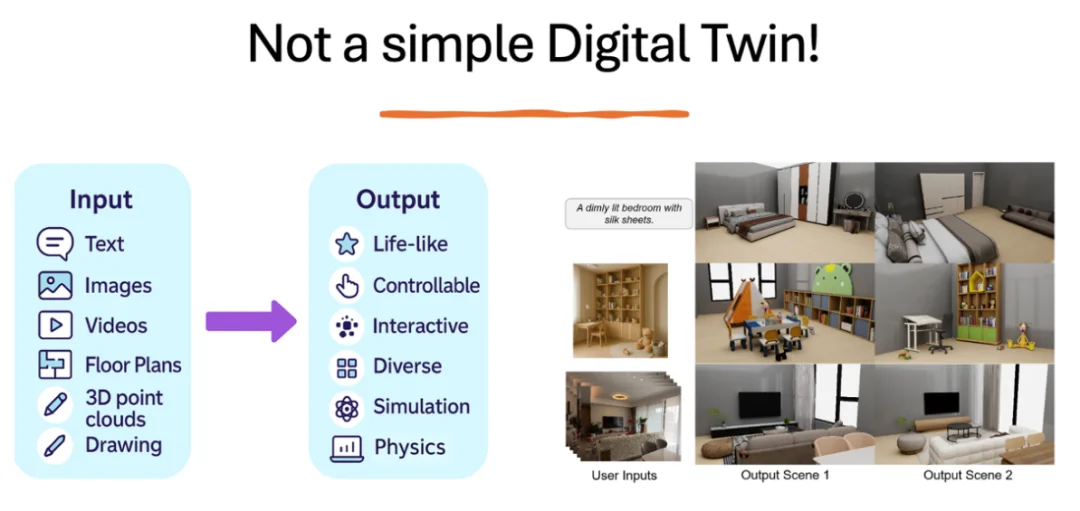
VLNVerse中的real to sim
针对这个需求,在和群核科技(酷家乐)的合作下,我们提出了一个InteriorAnything的工作,能够基于各种模态的输入,生成符合要求的3D场景。
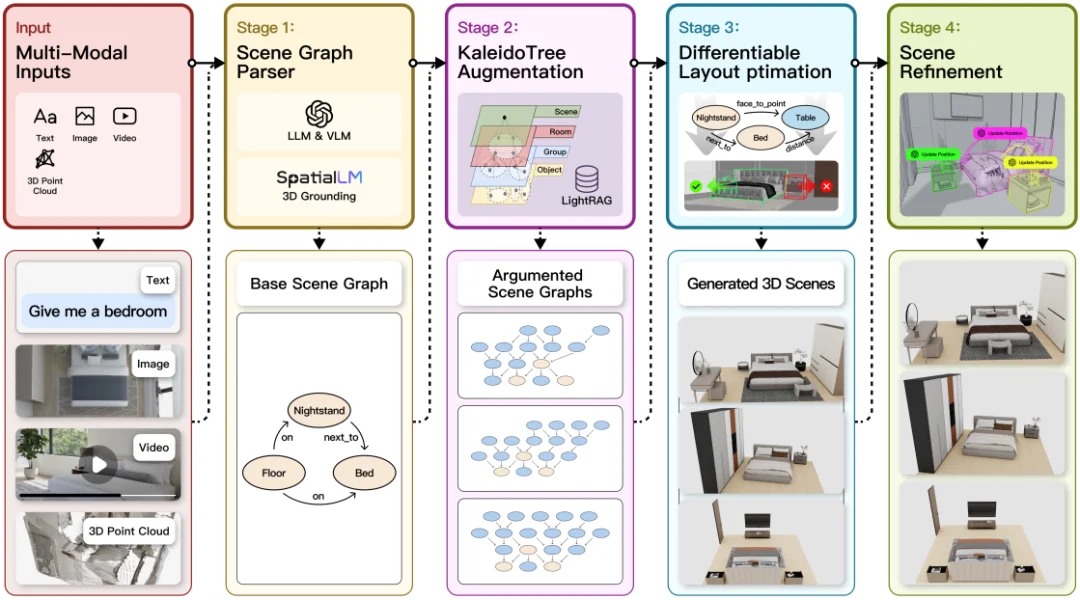
InteriorAnything 框架
如图中所示,我们的方法首先接收文本、图像、视频和三维点云等多模态输入 (一种或多种),综合获取场景语义与空间信息。随后在第一阶段利用大语言模型与视觉语言模型结合三维定位技术解析输入内容,自动识别场景中的对象及其空间关系,并构建基础场景图,这个基础图保证了后面生成的内容能与用户需求一致。第二阶段基于KaleidoTree(万花筒树) 结构对场景图进行增强与扩展,通过子结构替换与组合生成多种候选场景图以提升多样性与鲁棒性。在第三阶段,方法将增强后的场景图转化为三维布局,并通过可微优化将“相邻、支撑、面对”等语义关系约束为几何约束,从而自动调整物体的位置、朝向和尺度,筛除不合理的布局。最后在第四阶段对生成的三维场景进行细化与修正,进一步优化局部结构与视觉细节,提升整体真实感与一致性。总体而言,我们这个方法实现了从非结构化多模态输入到结构化三维场景生成与精修的端到端流程,兼顾语义理解、结构推理与几何优化。

值得一提的是,我们这个工作中采用的是Retrieval的方式去从一个庞大的3D资产库中找到最接近用户描述的部件,再进行组合。这样做的好处是场景中每个物体(部件)都是可交互的,比如柜子,抽屉,门,都可以打开或者关闭,物体可以移动等等。
(2)宇宙二:VLNVerse Simulator
VLN早期的simulator主要有两个,一个是当时和我们VLN R2R数据一起发布的MP3D simulator,还有一个是由Meta开发的Habitat。 MP3D的问题自不必说,采用的是静态图片的形式,也就是所谓的‘离散’环境,agent采用ghost-like的移动方式,某些情况下甚至可以穿越障碍物,不考虑碰撞,更谈不上和物体交互。Habitat由离散环境跨越到了连续环境,但是依然要面对场景不够真实,物理仿真不到位等问题。而最近一些基于 Isaac Sim 的新工作,实际上只是将旧的 Matterport3D (R2R) 或 Habitat 场景进行了格式转换 。
我们近期刚刚发布的VLNVerse Simulator (https://arxiv.org/abs/2512.19021)基于 NVIDIA Isaac Sim 构建,包含 263 个高保真物理场景,并且统一了 细粒度 (Fine-grained)、粗粒度 (Coarse-grained)、视觉参考 (Visual-Reference)、长程 (Long-Horizon) 及对话式 (Dialogue-based) 五大导航任务。
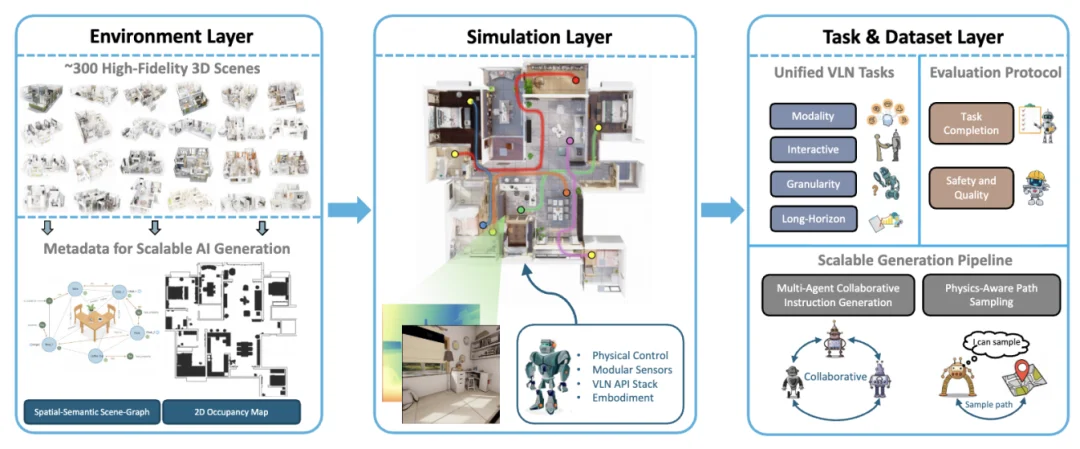
VLNVerse Simulator分成了环境层,模拟层以及任务&数据层
在环境层,我们提供了 263 个 全新构建的、具有独立拓扑结构的 USD (Universal Scene Description) 场景 ,这不仅仅是视觉上的高保真,更是拓扑结构上的全新设计,打破了场景数据的停滞局面。每个场景中的物体均可移动,交互。物体的物理属性,比如质量,摩擦系数,反光系数也都有提供。除此之外,我们还提供了详细的拓扑和语义标注,以及occupancy map。

VLNVerse Simulator中提供的新场景数据
在模拟层,我们基于 NVIDIA Isaac Sim 构建该层,利用其高保真渲染与强大的物理引擎,但我们的主要贡献并非仿真引擎本身,而是专门为 VLN 设计的高层抽象 API。该 API 具备三项关键能力:无缝地将物理仿真能力集成到 VLN 工作流中,通过标准化接口抽象复杂的机器人控制同时保持物理真实感,以及对不同机器人形态与多类传感器的通用兼容性。借助这一设计,我们可以无需再处理繁琐的底层机器人细节,可以专注于高层导航与交互逻辑。我们的模拟层在具身性、控制与感知三方面体现核心设计思想:在具身性上,我们提供可参数化的智能体建模接口,可灵活设定智能体的物理尺寸与运动学属性,从而满足碰撞、动量等真实物理约束并支持从仿真到现实的迁移;在控制上,我们提供统一的物理感知控制接口,实现连续、真实的运动与相机控制;在感知上,我们提供模块化传感器平台,使用户能够灵活配置 RGB、深度、LiDAR 等多种传感器及其采样频率、分辨率与视场角,以满足不同研究任务对观测与感知的需求。

VLNVerse Simulator
在任务数据层,以往的 VLN 研究往往“各自为战”,有的只做指令跟随,有的只做目标寻找。VLNVerse 首次在一个统一的框架下,定义并支持了 5 大核心任务,解决了任务碎片化的问题 :
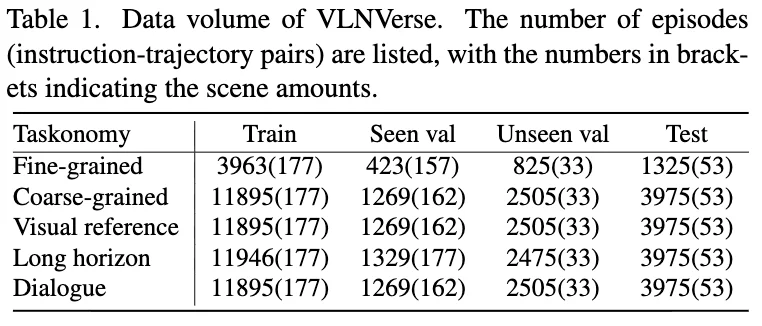
作为一个全面的 Benchmark,我们不仅仅是“跑个分”。VLNVerse系统地评测了当前 VLN 领域的代表性方法,旨在揭示物理仿真环境下的真实性能差距。
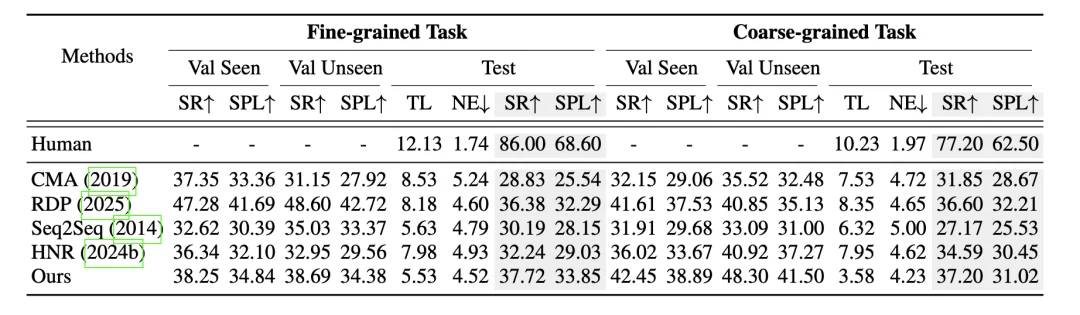
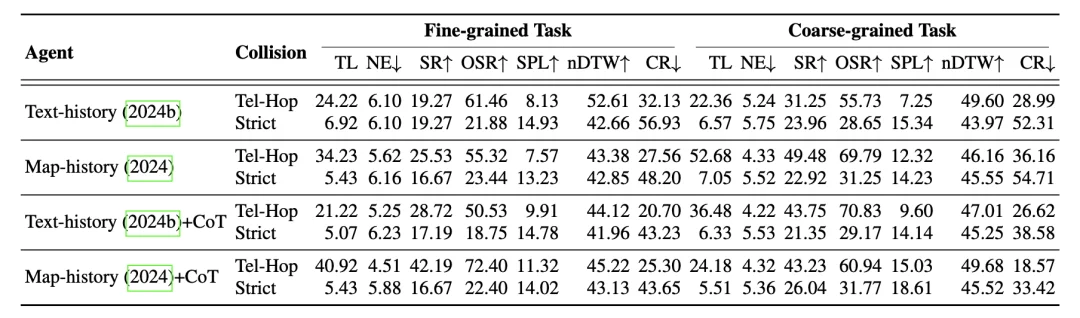
(3)宇宙三:Universal VLN Foundational Models
有了好的场景数据,Simulator以及一个全面的Benchmark,接下来就是考虑形成一个统一的模型去解决所有的视觉语言导航任务。
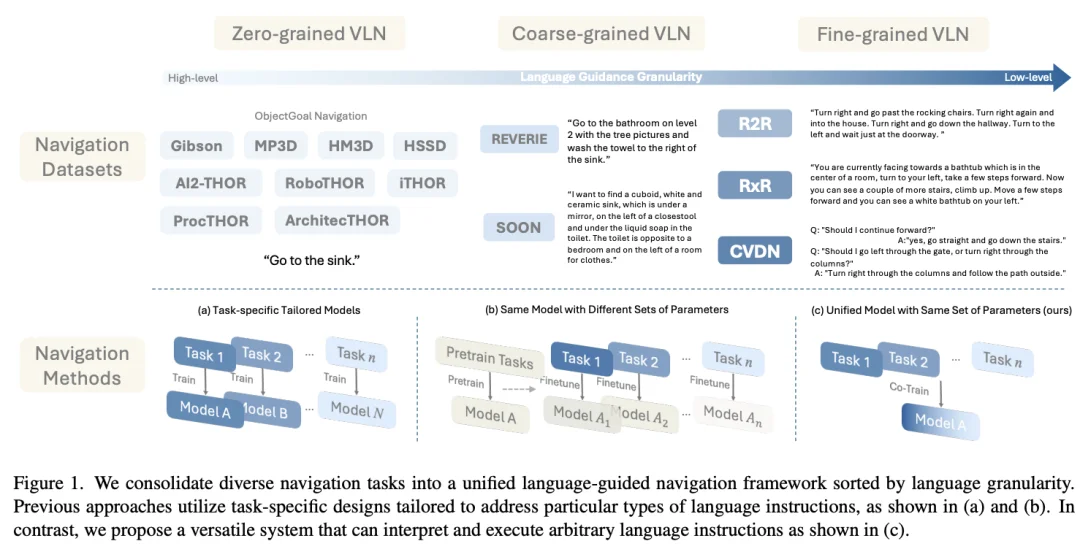
如上图所示,之前的VLN发展,无论从数据层面还是方法层面,都非常的‘碎片化’。从任务的角度来看,有不同‘粒度’的指令,比如只有‘物体’来作为指令的object-navigation,也有非常细粒度的R2R,RxR甚至是对话式的VLN 任务,更麻烦的是,不同的任务数据可能是在不同的simulator中形成的,这大大的增加了训练一个统一模型的难度。所以早期的方法是task-specific,即针对单一任务,设计并训练单独的模型。就导致虽然都是VLN任务,但是不同粒度任务的模型架构都不一样。后来引入‘预训练’的机制,会预训练一个统一的‘大’模型,然后再在各个VLN任务上微调。形成的格局就是虽然模型架构一样,但是不同任务之间的模型参数是不一样的。
这就给实机部署和应用带来了很大的难度,因为我们在实际使用的时候,给定的指令的粒度并不是固定的,那么就需要在同一个本体上,部署多个VLN模型,每个模型解决不同粒度的任务。而我们真正需要的,应该是一个统一的模型,只有一套参数,来解决不同粒度的视觉语言导航任务。也许有人会问,那么把所有VLN任务数据拿来训练一个模型不就可以了么?理论上可行,但是由于很多任务之间的互斥性,这样训练出来的模型结果并不好。
我们在今年的ICCV上,就提出了一个叫SAME (State-Adaptive Mixture of Experts, https://arxiv.org/abs/2412.05552)的方法,用MoE的方式去解决这个问题,并取得了不错的结果。这是因为传统的 MoE 往往是 Token 级别的,而 SAME 引入了 时间维度的路由机制。根据导航过程中的不同阶段(状态),动态选择最合适的专家网络。
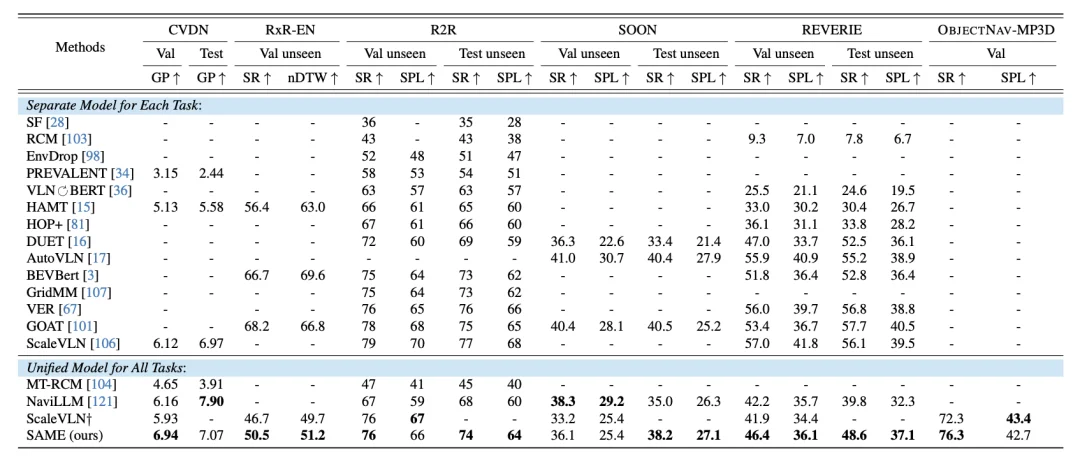
SAME在各个VLN任务上的表现 (单一模型参数解决所有类型任务)
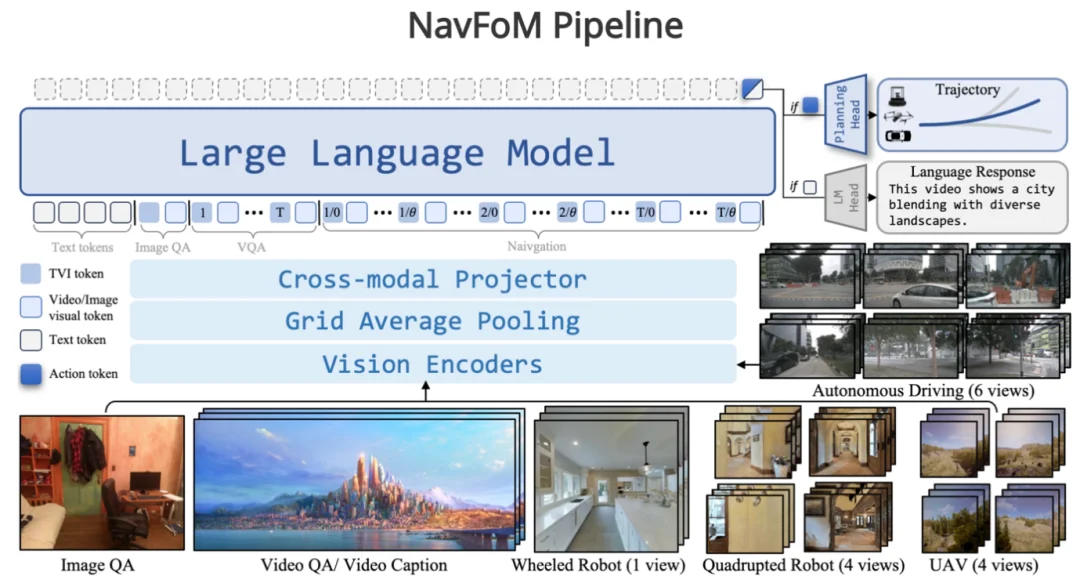
除了任务的统一,最近,和北大王鹤老师团队合作,我们还尝试了用一个统一的模型去解决跨本体(机器人,机器狗,无人车,无人机)的视觉语言导航任务。文章叫NavFom: Embodied Navigation Foundation Model ,大家感兴趣可以到https://pku-epic.github.io/NavFoM-Web/ 看相关的细节和demo。(https://arxiv.org/abs/2509.12129)
(4)宇宙四:Sim to Real
有了一个统一的模型,接下来就是部署的问题,如何将模型部署在实机上,那么我们要解决的一大难题就是sim2real。
首先要面对的问题就是open-world的domain shift问题,现实场景中的很多物体,环境或者是用户需求,很有可能是在simulator训练中没有见过的。一种思路就是利用大语言模型(LLM)去拆解任务和理解场景,结构成一个个在simulator中训练的模型可理解可执行的任务。我们在ICRA 2025上提出一个Open-Nav (https://arxiv.org/abs/2409.18794),就是试图利用LLM解决真机在open-world遇到的问题。

Open-Nav Pipeline
另外一个sim2real的挑战来自于物理设备的限制,比如机器狗和人的视角高度差问题。在VLN当中,指令一般是由人类给出的,也就是说,是人类根据自己的视角高度来给出指令,这个高度在1.7m左右。而假设执行该指令的是机器狗,那个高度可能在0.3m左右,很多人类指令中所描述的参照物,对于机器狗来说,可能甚至观测不到,比如下图中的例子,一个关键的参照物是足球桌,而对于机器狗来说,在当前视角下,只能观测到桌子的腿。如果只靠当前信息,就无法完成该任务。
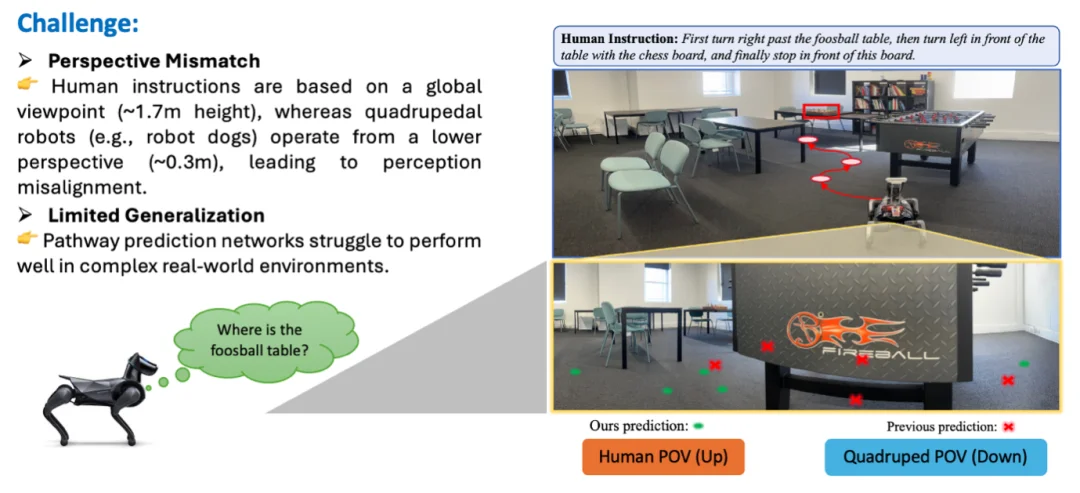
在ICRA 2025 上,我们提出了一个multi-view transformer(https://arxiv.org/abs/2502.19024)的方案,依靠调取低视角机器人(比如机器狗,扫地机器人等)在其他位置获得的相关视觉信息,来补全当前视角,完成导航。

除此之外,sim2real的另外一个难点就是计算效率的问题。由于VLN使用的模型较大(大部分给予transformer),有些也使用了LLM等大语言模型, 目前大部分的部署和实现方式都是机器人传感器获得信息,传回给server,在server端完成计算和推理,再将预测的动作指令传回给机器人执行,这自然就会造成一定程度的延迟。所以减少模型大小,提升模型计算效率,就成为一个必须要解决的问题。
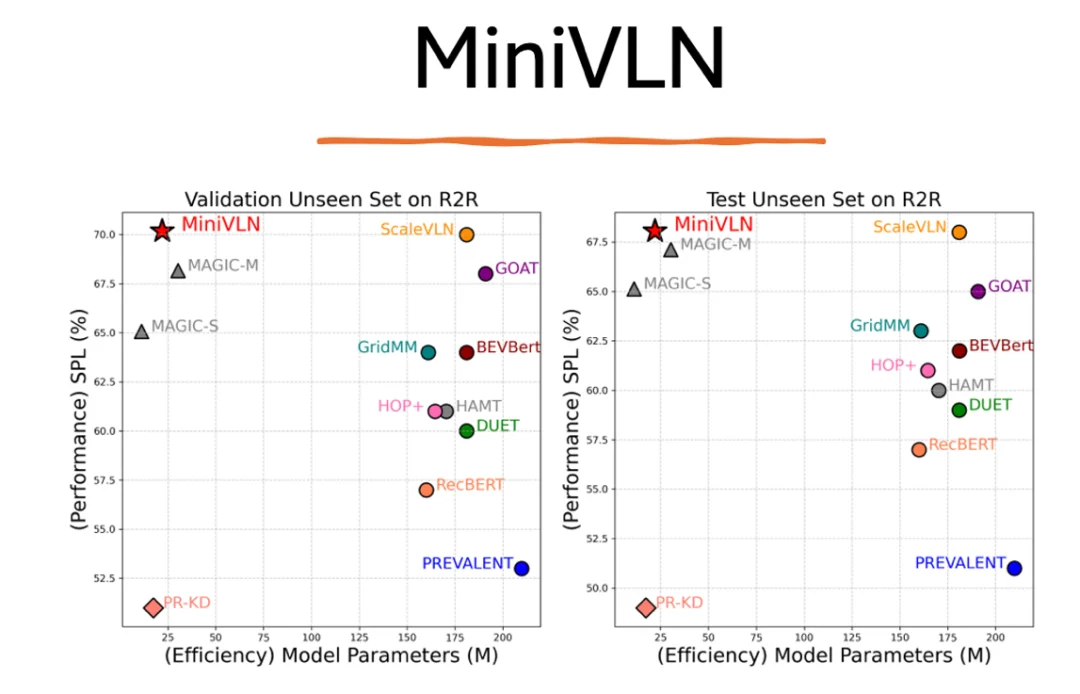
今年(2025)的ICRABest paper Final List, MiniVLN (https://arxiv.org/abs/2409.18800)就提出了用蒸馏的方式,大大的降低了模型的大小,在ScaleVLN仅1/7的大小下,达到了相同的准确率。
而像Fast-SmartWay ,则通过减少获取全景图的方式,来起到加速的效果。(https://arxiv.org/abs/2511.00933)

视觉语言导航(VLN)起始于2018年,到现在已是‘七年之痒’,很多设计和任务可能已经不再适合今天的方法和需求。比如我们当时设计这个任务时,初衷是解决视觉与语言对齐的问题的,所以对动作的输出上并没有很好的进行设计,也使得和真实应用场景有了一定的gap。随着这几年的发展,尤其是具身智能的兴起,新的数据和任务层出不穷,无论学术界还是业界,都对VLN这个任务越来越关注。但是正如我前面所说,VLN 在模拟器,任务,数据和方法上的过度碎片化,导致一直无法出现一个统一的模型出现,离落地更是还有一段距离。所以在2025年的年初,我们团队就着手开始打造一个全栈式的视觉语言导航平台,从数据生成,数据收集,任务定义,到仿真模拟和基座模型,再到跨本体的部署,全栈打通,统一但是又能高度定制。终于在新年来到前,VLNVerse和大家见面,希望能够真正的服务VLN 社区。除了整个平台以及训练/验证集数据完全开源之外,我们后面也将提供测试平台和leaderboard,供大家公平测试。我们后续还会陆续加入Mobile Manipulation,Multi-agent VLN等新任务,使用相同的VLNVerse平台。而我们于2018年提出的R2R,REVERIE的一系列数据,我们也将陆续把之前未公开的测试集开源,并停止testing server的维护。
旧的终将过去,新的总会到来。希望VLN跨越到Embodied VLN,在VLNVerse的加持下,越‘走’越好。
文章来自于“AI科技评论”,作者 “吴琦”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
