# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在生成式 AI 技术日新月异的背景下,合成语音的逼真度已达到真假难辨的水平,随之而来的语音欺诈与信息伪造风险也愈演愈烈。作为应对手段,语音鉴伪技术已成为信息安全领域的研究重心。
然而,当前的语音鉴伪模型正面临严峻的「泛化性挑战」:许多在特定实验室数据集上表现优秀的模型,在面对现实世界中从未见过的生成算法时,检测性能往往会出现剧烈下滑。这种「泛化瓶颈」严重限制了鉴伪技术在复杂多变的真实场景中的应用价值。
针对这一难题,上海交通大学听觉认知与计算声学实验室和宇生月伴公司(VUI Labs)联合发表了最新研究成果,提出了一种以数据为中心的研究范式。该研究深入探究了训练数据分布与模型泛化能力之间的底层逻辑,通过系统性的实证研究与策略优化,构建了兼具高性能与高泛化性的语音鉴伪大模型。

不同于以往关注架构创新的路径,论文从数据中心视角切入,将数据版图重构为两个核心视角:
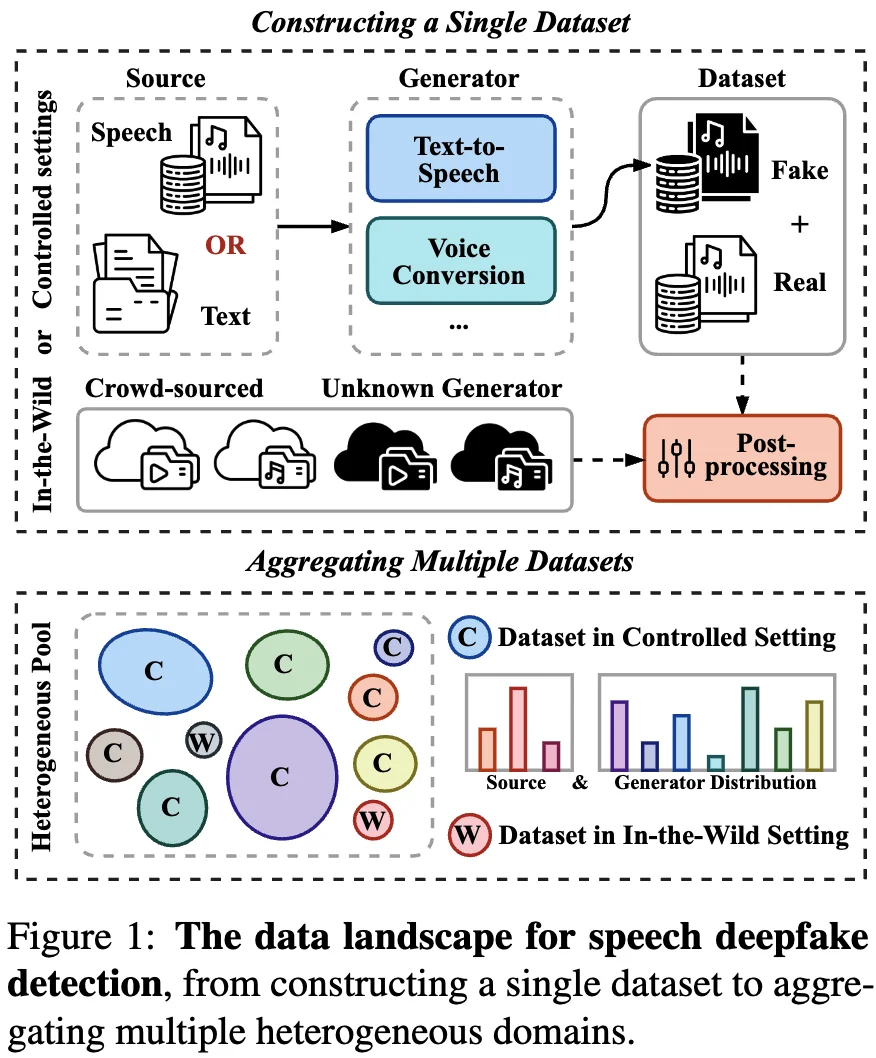
基于上述视角,论文旨在通过系统性的实证分析探索两个核心问题:
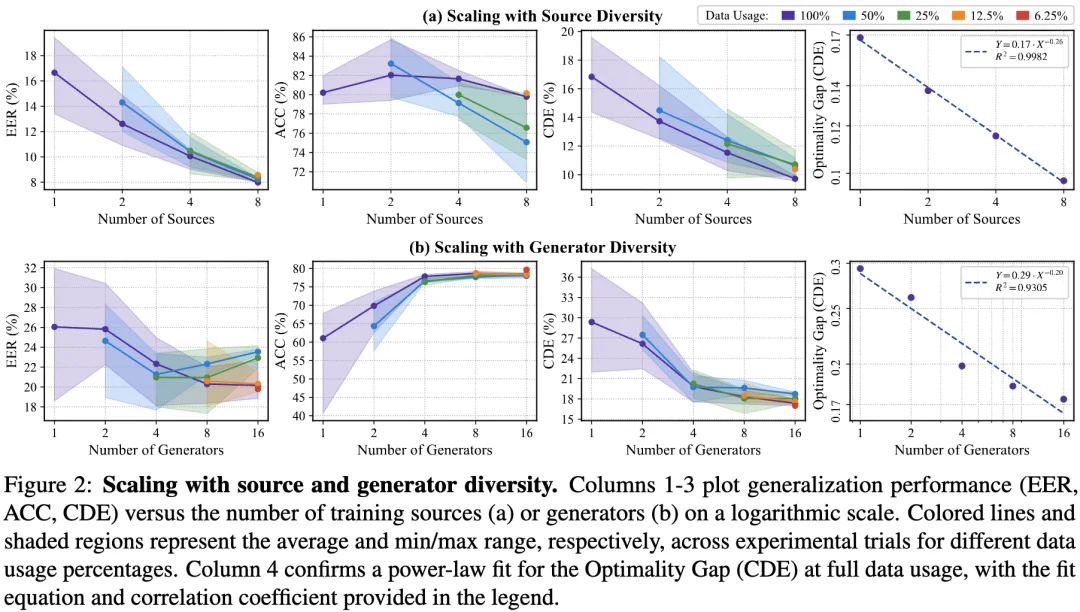
为了揭示资源分配的最优原则,论文针对训练数据的组成规律开展了大规模实证分析。通过量化信源多样性、生成器多样性与样本容量之间的复杂关系,揭示了语音鉴伪领域内在的「规模定律」。
核心发现:
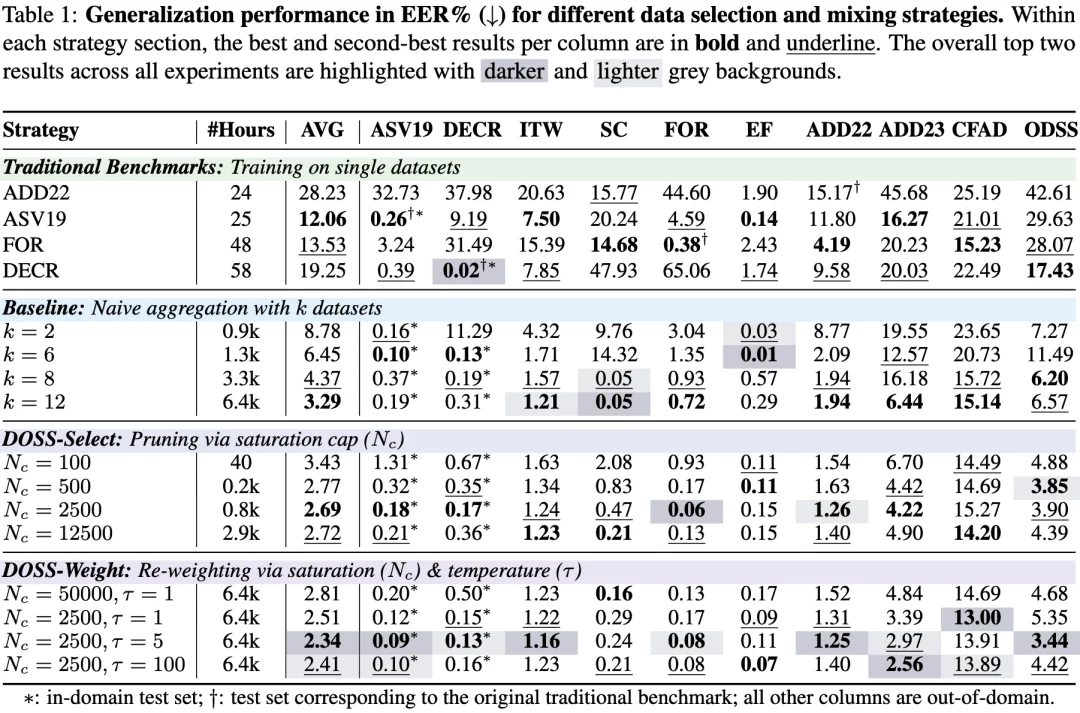
既然多样性的价值远胜于纯粹的数据堆叠,那么如何科学地混合来自不同源头的异构数据,就成为了解决泛化难题的第二个关键问题。基于规模定律的分析,论文提出了多样性优化采样策略(Diversity-Optimized Sampling Strategy,DOSS)。该策略的核心在于将复杂的异构数据按照信源或生成器划分为细粒度的域,并相对公平地对待每一种已知的生成模式:
实验结果验证了该策略在处理大规模异构数据时的优势:
为了验证上述策略的稳健性与可扩展性,论文构建了一个包含 1.2 万小时音频、涵盖 300+ 个伪造领域的大规模异构数据池。通过应用 DOSS 策略进行训练,最终得到了高性能高泛化的大模型,并在多个学术基准和商业接口上进行了实测,均取得了突破性表现:
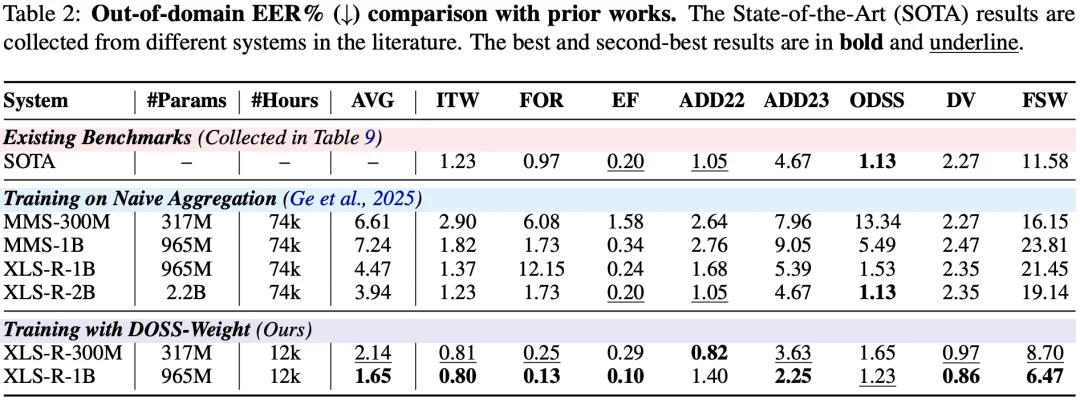
学术基准:刷新跨域性能记录
在多个公开测试集的评估中,模型平均等错误率(EER)降至 1.65%,在多个主流基准测试中均刷新了记录,确立了新的技术基准和 SOTA。此外,数据与模型效率的表现尤为出色:相较于之前最好的来自日本 NII 的系统——在 7.4 万小时数据上训练的 2B 规模模型(平均 EER 3.94%),提出的新方案仅凭约 1/6 的训练数据与更精简的参数规模,便实现了检测误差的倍数级削减。即便是在更轻量的 300M 版本下,其性能表现依然稳健,证明了科学的数据策略比单纯的规模堆叠更能有效释放模型的泛化潜力。
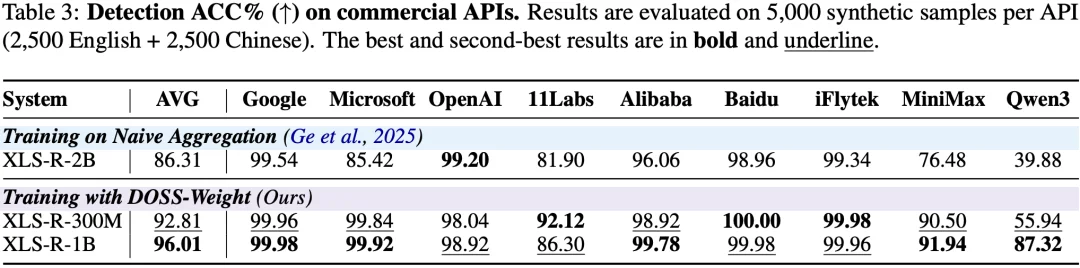
商业接口:直面现实安全威胁
针对从 Google、Microsoft 等主流云服务到 ElevenLabs、MiniMax 等前沿高拟真引擎的 9 类最新商业接口进行评估,模型平均检测准确率达到了 96.01%。即便在面对目前极具挑战性的高保真合成引擎 Qwen3 时,模型仍能保持 87.32% 的高准度识别。这进一步印证了从多样化训练数据中学习到的表征,能够有效迁移并泛化至现实中不断进化的商业生成方式。
不同于以往在模型架构与算法优化上的迭代,深挖训练数据组成的底层逻辑正在成为重塑语音安全防线的关键。本论文通过量化多样性的规模效应并引入优化采样机制,成功实现了对异构数据资源的高效调度与深度挖掘。这种向「数据中心」范式的深刻转变,为构建高性能、高泛化的语音安全大模型提供了全新的探索思路。
研究团队来自于上海交通大学计算机学院听觉认知与计算声学实验室(SJTU Auditory Cognition and Computational Acoustics Lab,AudioCC Lab)和宇生月伴公司(VUI Labs),该团队由语音对话和听觉处理领域知名学者,教育部长江学者钱彦旻教授领导,专注于完整的听觉人工智能与计算声学领域的前沿研究。
实验室集结了一支由青年教师、博士生、硕士生、本科生及专职科研人员等组成的近 40 人科研团队,在语音、音频、音乐及自然声信号处理等领域积累了丰富的技术经验。实验室依托国家重点项目及企业合作支持,拥有数百块先进 GPU 计算资源,致力于解决产业级技术难题。
近年来,团队在国际顶级期刊和会议上发表了数百项学术成果,并在多项国际评测中斩获冠军。团队成员全面发展,毕业生均进入国内外顶级企业和研究机构,持续推动人工智能技术的创新与应用。
文章来自于“机器之心”,作者 “机器之心”。


