# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今年我比较喜欢的 AI 产品中,一个是 Google 旗下的 NotebookLM,我觉得它的价值还没有真正体现出来。还有一个是国内团队做的 Kuse,其团队在没融资的情况下,3 个月做到了差不多 1000 万美金的 ARR。
我跟 Kuse 团队陆陆续续深度聊了不下 3 次,每次聊完都有不一样的收获,以至于我一直不知道怎么来介绍这个产品,直到最近再次回顾非结构化数据结构化这块的需求后《半年 ARR 增 10 倍达数千万美金,非结构化数据结构化的需求正在爆发》,我觉得可以写写了。
Kuse 和 Manus、Genspark 等通用 AI Agent 以及 NotebookLM 都有点像,但又有很大差别。大部分通用 AI Agent 是一次性生成模式(或者说用户的行为属于典型的一次性消费),在对话框通过一句话或者稍微复杂的 Prompt 让 AI 帮我实现某个需求,之后基本上就结束了,这是一次性消费行为。
而Kuse 走的则是资产沉淀路径,它更像 NotebookLM,首页不是对话框,而是和 NotebookLM 那样需要上传你的文件或者提交信息源,之后才通过 AI 进行各种处理。不过和 NotebookLM 侧重于个人学习不同,Kuse 面向的几乎都是知识工作者和企业场景。
kuse 的产品理念是以“上下文优先(Context First)”,围绕文件夹与素材源(sources)构建知识库,把用户的输入(文档、图片、音频、网页等)沉淀为可复用的上下文资产,驱动更高质量的 AI 生成与工作流迭代。
最新推出的 2.0 版本,团队将产品定位从之前的通用 AI 工具转为 AI 原生的“Context First”文件管理与资产沉淀系统。
相比于传统“文档即页面”的范式,Kuse 以苹果电脑 Finder 式结构组织素材与生成物,配合 AI 原生工作流,形成“输入—生成—沉淀—复用”的闭环。强调自动结构化、可复用上下文与工作流驱动,而非纯模块堆砌。
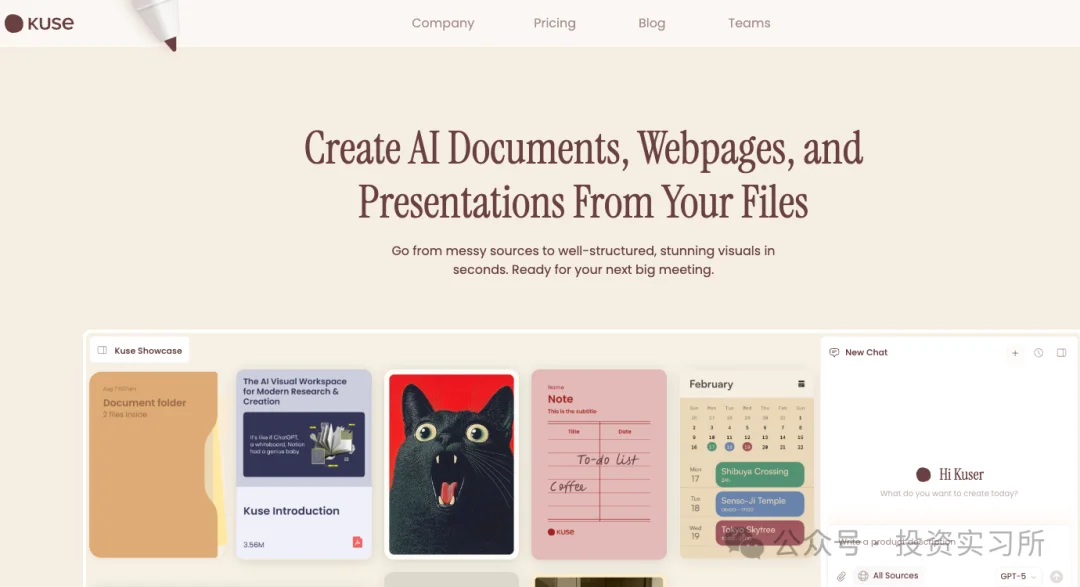
强调“Chaos in, Genius out”:也就是把复杂、杂乱的输入转化为清晰、可消费的网页与文档成果;从“聊天即生产”升级到“上下文驱动的生成与复利”。主打的是知识库+Webpage 交互模式,专注文档和网页生成而非应用开发,从而将复杂信息格式化为可消费的网页与文档。
因此它虽然也可以生成各种网页,但是其目的是为了更好的消费和传递信息,而不是为开发者去做一个 Vibe Coding 产品,这和 NotebookLM 也是非常相像的。
还有一个我比较喜欢的点就是其“把信息转化为网页与文档”的格式化引擎 AI定位,而不是走“应用开发平台”路线,避免复杂度和学习成本,提高产出效率与复用价值。
举个 Kuse 很典型的使用场景,学校或者辅导机构的老师经常要给学生出各种测验试卷,传统的模式是参考某个样板考卷的题型和难易程度,去找类似的考题,之后再将这些内容组合成一个考卷,整个流程非常繁琐。即使考题部分可以通过类似 ChatGPT 这样的 AI 来部分解决,最后组合成考卷也要在格式排版调整这块花费很多时间。
Kuse 的解决方案将这个流程压缩到几分钟,你直接上传参考试卷,告诉它给你出题型、难度、考点都类似的多份试卷,它很快就可以给你生成了出来,同时也将考卷的格式排版给你处理好了。除了题目不同,其他方面可以做到和原参考考卷基本一样。
这个就是 Kuse 所说的格式化引擎 AI,除了内容的生成,它将人们消费内容的格式排版这些也给你处理好了。这种需求在个人和企业里都是非常常见的,比方说律师可能需要大量格式类似但内容可能稍微做一些修改的法律文件,求职者的简历也是以某个模板+上下文复用来形成,企业里大量的合同以及其它文档、通知都需要以某种规范的格式进行。
这些需求高频、刚需而且可复利,因此 Kuse 一直强调自己的差异点在于,从“一次性生成”到“长期资产”的可复利使用,从你第一次上传的信息源成为你的首个资产,后续基于这些信息生成的新内容会再次成为新的资产,支持持续迭代、复用与协作。
这和 Notion 的乐高式模块有点类似,但因为基于 AI 构建,因此其结构是 AI 原生结构化的,它自动处理与复用上下文,更适合高频生成与多格式分发。随着用户资产沉淀,生成质量与速度持续提升,它形成“越用越懂你”的记忆系统,因而具有 Context 复利能力。这是我觉得非常有价值的地方,特别是在企业级场景里。因此更像是在用 NotebookLM 的方法重做 Notion。
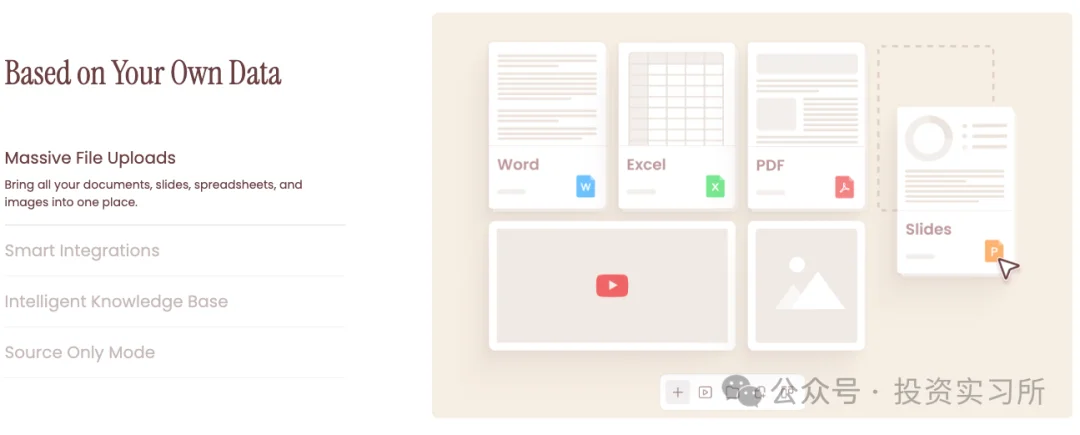
整个产品本质上来看也很简单,就是将一组杂乱的信息转化为更好消费的信息,也就是我之前说的非结构化数据结构这个需求,AI 极大提高了对非结构化数据的处理,而人们消费信息时是需要结构化的,这里的结构化就包含了格式排版等形态,它可能是网页、Docs、PDF 或者其他形态。
所以我觉得它契合了数据的处理能力和信息的分发场景以及消费需求,只是整体更注重生成结果与素材的整合,以及企业内的分享。
目前其产品的底层逻辑和 NotebookLM 比较类似,只不过产品更侧重商业信息的分发。但 Kuse 给我的感觉是,其未来很也有机会发展成类似 Box 创始人 Aaron Levied 和 Slow Venture 合伙人 Sam Lessin 所说的 AI 时代的 CRM+ERP。
不过这套模式,也是用户在使用 Kuse 的过程中逐渐发现的,联合创始人兼 CEO 吴显昆跟我说,因为他是设计师出身,最早是想做一个 AI 设计 Agent,于是构建了一个无限画布,用户可以上传需求,AI 会将其转化为海报和设计作品。
但没想到产品上线后用户的行为和之前的设想完全不同,用户上传 PDF、研究论文、课堂笔记和内部文档的频率,远远超过使用设计功能的频率。用户不是想要一个设计工具,他们想要的是一个能够理解和处理信息的智能工作空间,而理解信息是真正的痛点。
于是很快做了转型,不再构建垂直的设计代理,而是将 Kuse 重新定位为横向的 AI 知识引擎——一个能够理解你的上下文、处理多种格式文件、并将混乱输入转化为结构化输出的视觉化工作空间。

此时上下文工程(Context Engineering)就成为了其核心理念,但 Kuse 不太一样的地方在于,其他 AI 工具的交互模式是:上传文件—>写提示词—>获得答案—>上下文消失,下次使用时,你又要从零开始;Kuse 的则是:将所有材料上传到一个地方—> AI 在后台持续处理所有内容(即使你不在)—>上下文随时间累积—>每次交互都变得更好。
所以它不是简单的提示词工程,而是包括 RAG(检索增强生成)、状态记忆、结构化输出在内的完整上下文工程系统。
这次转型让其找到了 PMF,用户群体从设计师扩展到:咨询顾问(需要快速生成客户报告),教育工作者(需要自动生成考试试卷),法律专业人士(需要处理大量文档),产品经理、营销人员和各类知识工作者。
而这个过程中,他们发现用户更深处未被解决的痛点,其实是咨询、教育和法律领域的专业人士需要 AI 工具能够创建高精度、模板驱动的文档——保持完全一致的格式,无需手动调整。
也就是我上面所说的格式化 AI,目前的 AI 产品基本上都做不到这一点。依靠这一个痛点,Kuse 在短时间就做到了近 1000 万美金 ARR。
而其增长策略也比较独特,大部分产品把渠道放到 X 或者 TikTok 等社交媒体,但Kuse 的增长几乎来自:Meta 旗下的 Threads 和 Instagram,目前各占一半左右,而且就一位大三的实习生负责。而之所以选择 Threads,主要有这 3 个因素:
推广策略也很简单:雇佣实习生团队,创建数百个账号,每天发布实用案例:比方说 Markdown 转精美排版、考试试卷自动生成、文档处理示例、网页演示文稿制作等,由于主要针对台湾和香港市场,所有内容用繁体中文发布。

在经历转型初步取得成功后,吴显昆说他们发现,Kuse 用户的主要使用场景包括了互动式网页、试卷、简历、学习笔记、行政通知等,与 Office 的场景重合度较高,因此也考虑过将其定位为 AI 时代的 Office,只不过与传统 Office 的逻辑不同,它是用 AI 处理信息并生成内容,交付方式以网页为主。
不过他现在觉得核心还是聚焦,专注在那些高频需求上,特别是用网页或图片生成重格式的文本、文件或 Web page,满足更朴实、高频的需求,如排版、文档和网页生成等,不关注后端开发和应用制作。这也就是其 2.0 版本核心提到的:Creating docs and web pages。
Kuse 这个产品给我的感觉就是,未来可延展的方向很多,因此也是最考验团队能力的地方。目前其全职团队不到 20 人,成员来自 Meta、Nvidia、Google、字节跳动和 Grab 等,CEO 吴显昆之前是 rct.ai 的联合创始人。
End!
文章来自于“投资实习所”,作者 “StartupBoy”。



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】ai-renamer是一个用AI帮你做文件夹或者图片命名的项目。该项目会根据文件夹或者图片内容来为文件进行重新命名,让你的文件管理更加便利。
项目地址:https://github.com/ozgrozer/ai-renamer
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
