# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当全行业还在为昂贵的多视角数据焦头烂额时,中科院和CreateAI重磅推出NeoVerse,直接用百万单目视频砸开了4D世界模型的大门,让AI真正学会了理解开放世界。

李飞飞团队提出的 Marble 极大地推动了空间智能的边界,但因其应用场景仍局限于静态环境,本质上归属于 3D 世界模型的范畴。相比之下,4D 世界模型作为空间智能的演进形态,在数字内容创作、游戏开发、自动驾驶仿真及具身智能等领域展现出巨大的应用潜力。然而,当前的 4D 世界模型训练方案正面临严峻的扩展性(Scalability)瓶颈。
模型的训练通常需要成对的视频,即输入给模型的原视角视频,和作为监督的时间同步的新视角目标视频。这种特殊的数据需求使得训练难以扩展到海量的数据上。现有的研究往往受困于以下两点:
这些限制构成了重重壁垒,将互联网上最廉价、最丰富的资源——开放场景单目视频数据阻隔在外。
为此,来自中科院自动化研究所和 CreateAI 的研究者提出了 NeoVerse。NeoVerse 彻底抛弃了昂贵的多视角数据和沉重的离线预处理,直接拥抱互联网上的海量单目视频,首次利用100万段开放场景单目视频进行大规模训练。

项目主页:https://neoverse-4d.github.io/
论文链接:https://arxiv.org/abs/2601.00393
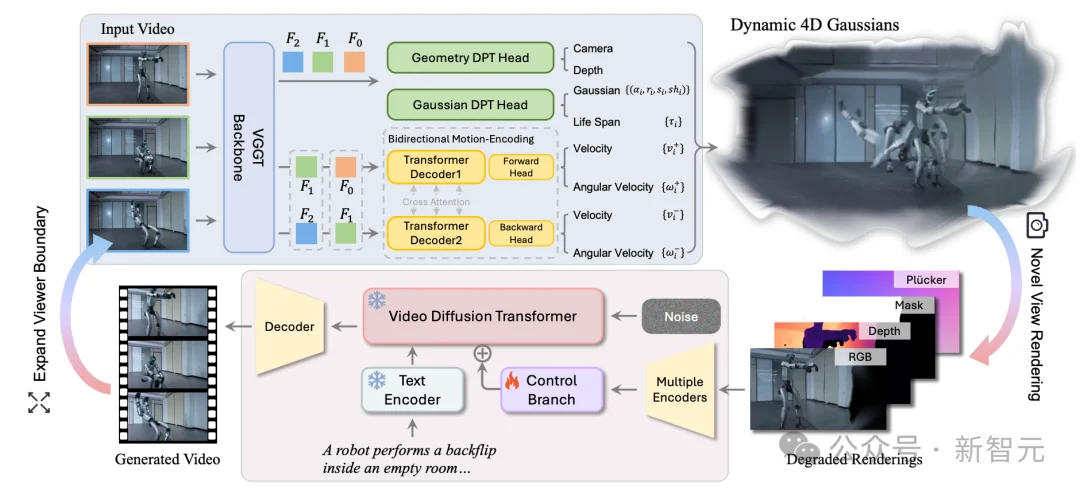
NeoVerse 是一种重建-生成混合式的架构,其首先重建出 4D 表示,然后将其用于生成模型的作为新视角的几何引导。要实现训练管线的 scaling up,第一步必须解决「重建速度」问题。NeoVerse 提出了一种免姿态输入(Pose-free)的前馈式 4DGS 模型。
与传统针对专一场景迭代优化的重建方法不同,NeoVerse 基于视觉几何基础变换器(VGGT)进行动态化和高斯化改进。这种前馈式重建无需复杂离线预处理,一次预测即可在几秒内完成动态场景 4D 建模。
双向运动建模

4D高斯化

稀疏帧重建 × 密集帧渲染

单目退化模拟

在单目视频训练中,最大的挑战是缺乏「新视角」的监督信号。NeoVerse 并没有尝试寻找完美的数据,而是反其道而行之,引入了单目退化模拟机制,在训练的每一次迭代中,NeoVerse 并不是简单地从输入视角渲染,而是刻意「模拟」了单目重建在不同视角下的退化规律,从而建立起一套自监督训练范式:
退化渲染引导
NeoVerse 通过控制分支将模拟的渲染结果(包含渲染图像、深度、不透明度图以及相机位姿的 Plüker 嵌入)注入视频生成模型。在训练过程中,NeoVerse 仅训练控制分支,同时冻结视频生成主干模型,这不仅可以提升训练效率,更重要的是,使其能够支持步数蒸馏 LoRAs,以加速生成过程。
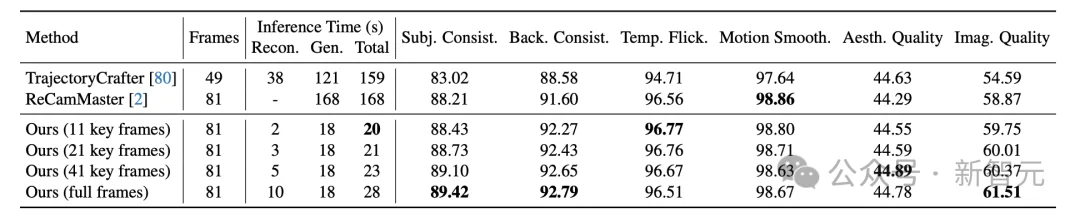
NeoVerse 通过 VBench 测评了共计400个测试样例,无论是从重建和生成的运行速度,还是从生成质量上均显著优于现有方法。

即使在具有挑战性场景上进行大幅度视角运动控制。 NeoVerse 依然能在保持精确相机可控性的同时实现更好的生成质量。

较大的相机运动下的渲染图像容易产生包括飞边像素和扭曲等现象。上图展示了 NeoVerse 单目退化模拟的必要性。如果没有在模拟出的退化样本上进行训练,生成模型往往会过于信任重建渲染中的几何伪影,导致出现「鬼影」效果或模糊输出。通过结合退化模拟,生成模型能够学会抑制这些伪影,并在遮挡或扭曲区域生成逼真的细节。
在大规模视频训练的支持下,NeoVerse 不仅能实现高精度的 4D 重建与精准漫游,更能跨越影视制作、具身智能与自动驾驶等多个领域,支持多视角生成、视频编辑等丰富下游应用。

子弹时间


从图像到世界:重建 + 生成的迭代闭环
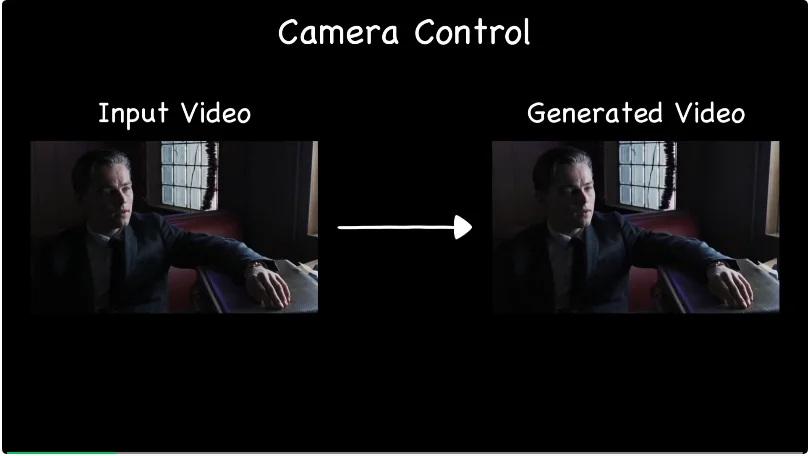
多样化相机控制

视频编辑
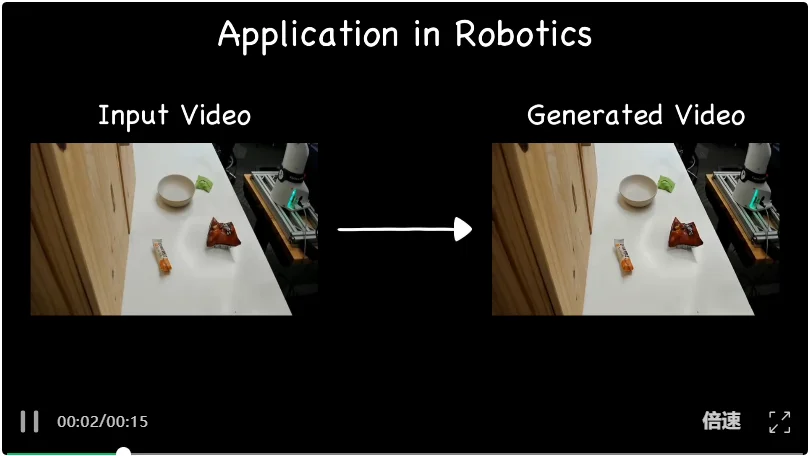
具身场景应用
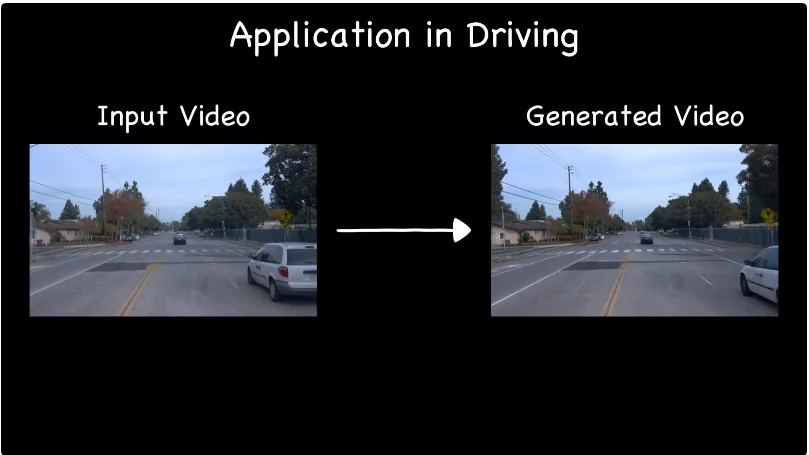
驾驶场景应用

驾驶场景前视相机到多视角相机扩展
NeoVerse 的出现,标志着 4D 空间智能从「实验室精雕细琢」向「大规模数据驱动」的范式转移。它通过攻克核心的扩展性(Scalability)瓶颈,构建了一套能够无缝适配互联网单目视频的训练管线。这种对海量开放场景数据的深度挖掘,不仅让 NeoVerse 在泛化能力上实现了质的飞跃,更使其成为了支撑自动驾驶、具身智能及内容创作等多元领域的通用 4D 世界模型底座。
文章来自于“新智元”,作者 “桃子 好困”。



