# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
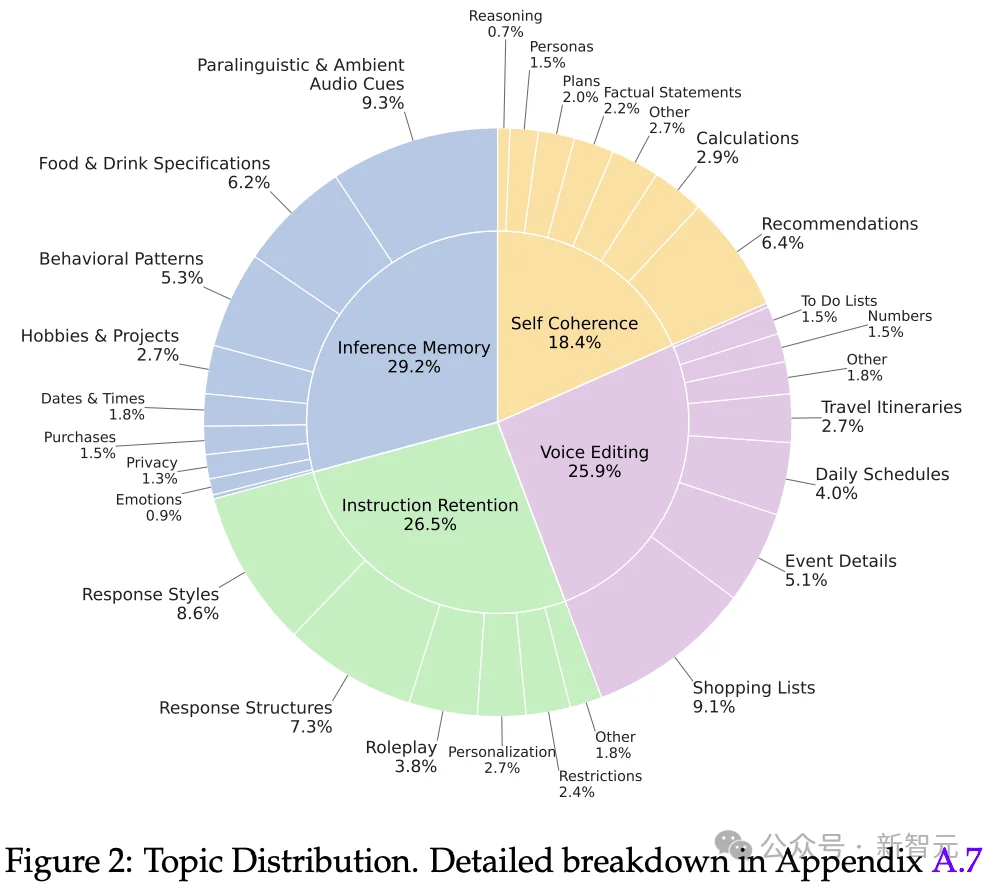
文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半数,而GPT-4o Audio的表现更是令人大跌眼镜。
随着实时语音大模型的普及,人们一度以为AI实时伴侣已经跨越了自然交互的最后一道门槛。
然而,大模型在语音对话中表现出的聪明,很大程度上源于评测手段的滞后。
此前,Scale AI推出的MultiChallenge基准凭借对指令保留、推理记忆和自我一致性的严苛考察,被公认为评估大模型逻辑长性的黄金标准。
但长久以来,该基准一直缺少一个真正的音频原声版本。
最近,Scale AI正式补齐了这块拼图,发布Audio MultiChallenge,不仅刷新了语音交互的新高度,更揭开了行业内一个公开的秘密:
由于缺乏原生音频测试集,模型厂商在发布报告时,往往不得不利用T2S(Text-to-Speech)将文本基准转换为语音进行评测。

论文链接:https://arxiv.org/pdf/2512.14865
这种做法虽然让数据看起来很漂亮,却在无形中给模型加了一层过度美化的滤镜。

利用TTS转换来进行评测,实际上是为模型营造了一个完美的无菌环境。
TTS 生成的语音平滑、规律且高度标准化,彻底过滤掉了人类语言中最重要的特质:日常说话时的各种吞吐、重复、琐碎停顿以及临时改口。
当你对AI说:我想定周一,哦不,是周三的票,等下……还是周二吧。
这种充满了逻辑回溯和口语碎片的自然场景,是目前TTS技术极力避免但在现实生活中无处不在的。
过去,模型穿上了一层由合成语音搭建的语音外壳,本质上是在用文本思维处理洁净信号。
而一旦脱离这个外壳,面对Audio MultiChallenge中47名真实说话者录制的原始音频,模型的逻辑链条便会迅速崩塌。
论文直言不讳地指出:模型在合成语音上的得分显著高于真实人声,这证实了干净的合成音频掩盖了模型在现实世界中的失败模式(Masking real-world failure modes)。
Audio MultiChallenge延续了原版的严苛逻辑,并针对音频特性新增了致命的一击,从指令保留、推理记忆、自我一致性以及核心的Voice Editing(语音编辑) 四个轴向对模型进行综合考核。
根据论文公布的排行榜,目前全球顶尖模型的音频原生能力普遍处于及格线以下:
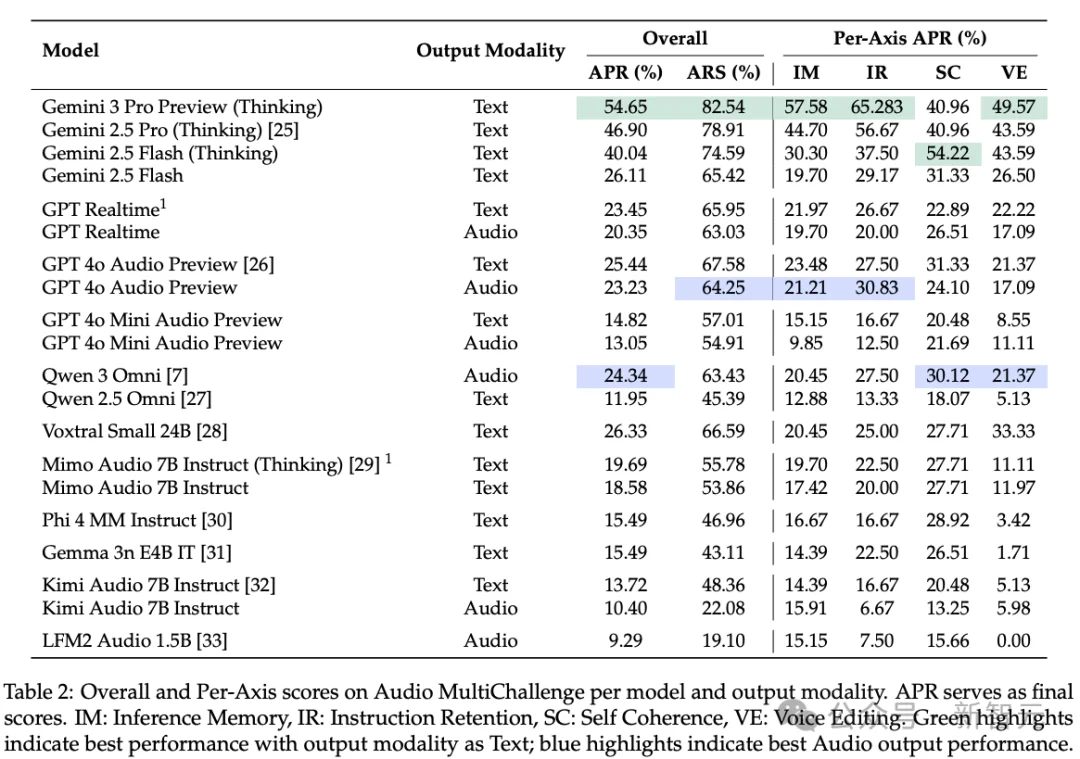
实验数据揭露了一个惊人的落差:Gemini 3 Pro Preview凭借其推理架构在逻辑深度上维持了领先;而GPT-4o Audio Preview在面对真实人类语音时,表现出的鲁棒性远低于预期,通过率甚至只有Gemini的一半左右。
论文通过详细的错误分析,精准捕捉到了模型在音频模态下的三个软肋,这些结论直接指出了大模型在语音交互中的底层Gap:
语音编辑是逻辑黑洞:这是本次基准新增的维度。当用户在说话过程中中途改口或逻辑回溯时,大多数模型会死板地执行听到的第一个指令。该维度的平均通过率仅为17.99%,这意味着模型在听觉上无法有效处理信息的撤回与覆盖。
时长驱动的崩溃:模型表现随着音频总时长增加而稳步恶化。数据显示,当对话累计音频超过8分钟时,模型的自我一致性得分会骤降至 13% 左右。这意味着目前的语音模型在处理长程语音上下文时,状态追踪能力极其薄弱。
音频线索的感知缺失:当任务要求模型识别非语义信号(如背景的环境声、说话人的语气情绪)来辅助推理时,模型表现比纯语义任务下降了 36.5%。这说明模型依然把语音当成脱水的文字在读,而没能真正听懂声音背后的物理世界。
Audio MultiChallenge的发布证明了语音绝不仅是文本的简单投射,包含着实时状态跟踪、情绪理解以及复杂的口语特质处理。
Scale AI的这一记重锤敲醒了业界:如果我们不能撕掉那层精美的语音外壳,解决模型对自然语音中不完美特征的感知断层,那么AGI驱动的自由交互,将永远停留在听懂单词却不懂逻辑的初级阶段。
参考资料:
https://arxiv.org/pdf/2512.14865
文章来自于“新智元”,作者 “LRST”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
