# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。
近日,来自上海人工智能实验室、中科大、北大、清华等机构的研究者联合发布了 UniPercept。这是首个统一了 美学(Aesthetics)、质量(Quality)、结构与纹理(Structure & Texture) 三个维度的感知级图像理解框架。

🌐 项目主页:https://thunderbolt215.github.io/Unipercept-project/
💻 代码仓库:https://github.com/thunderbolt215/UniPercept
📝 论文地址:https://arxiv.org/abs/2512.21675
📊 模型权重:https://huggingface.co/collections/Thunderbolt215215/unipercept
🎨 相关工作 (ArtiMuse):https://github.com/thunderbolt215/ArtiMuse
当前,多模态大语言模型在目标检测、图像描述和视觉推理等语义级任务中表现卓越。然而,人类视觉感知不仅限于物体识别,还包括对构图美感、画质损伤、材质纹理以及结构规律性的细腻捕捉。
语义级理解关注的是「场景中有哪些实体」,而感知级理解则需要评估精细的、低层级的视觉外观,例如美学和谐度、降质严重程度或表面肌理。这些属性往往是微妙且主观的,对内容创作、图像增强及生成模型对齐至关重要。
为了填补这一空白,研究团队提出了 UniPercept。该工作建立了层次化的感知属性定义系统,构建了大规模基准测试集 UniPercept-Bench,并开发了一个通过领域自适应预训练和任务对齐强化学习训练的强基准模型。此外,研究团队还给出了 UniPercept 的下游应用实例,包括作为生成模型的奖励模型(Reward Model),以及作为生成模型评估的指标(Metrics)等。
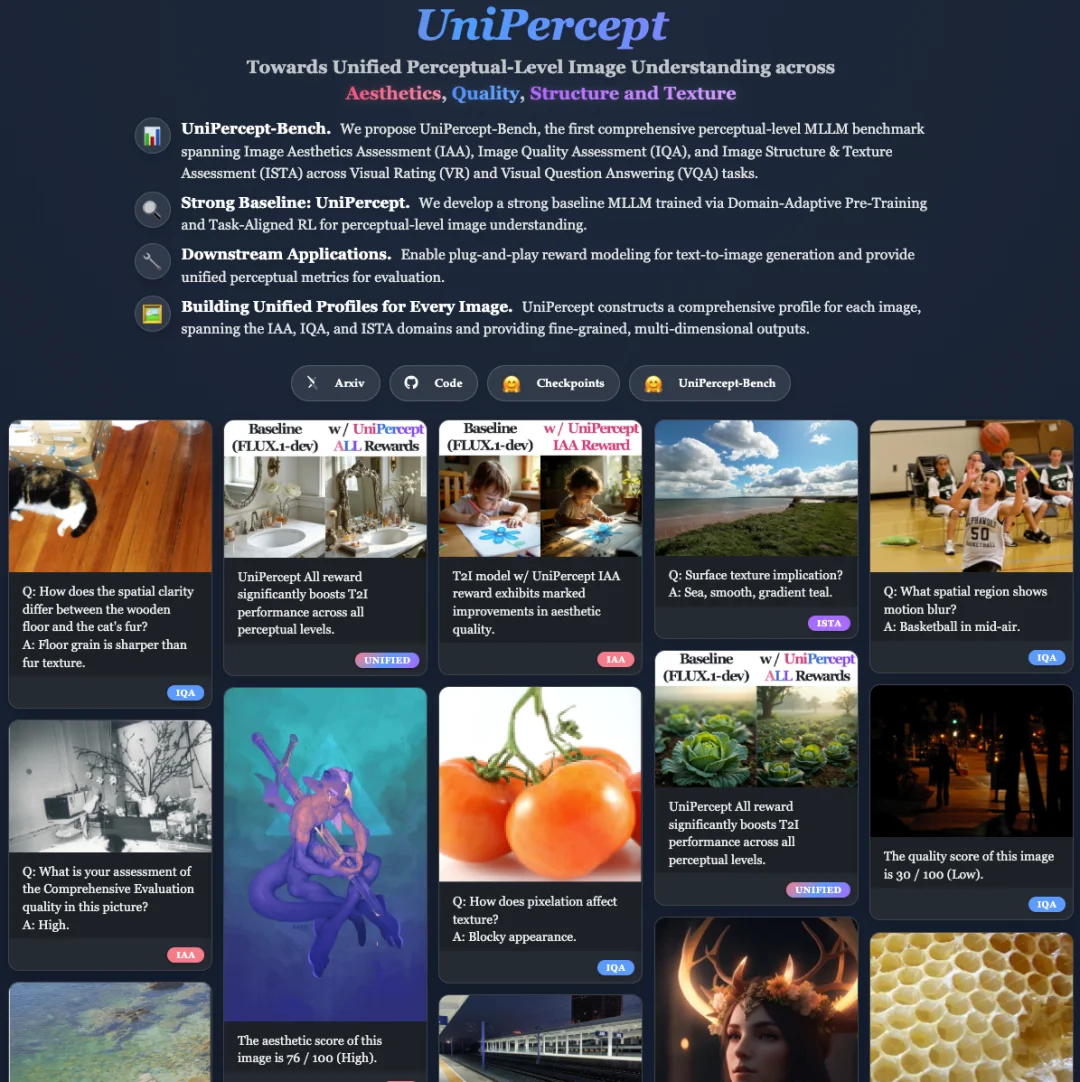
UniPercept 将感知级图像理解拆解为三个核心领域,构建了「领域 - 类别 - 准则」的三级层次结构,旨在全面覆盖人类对图像的视觉评价维度。
核心评估维度
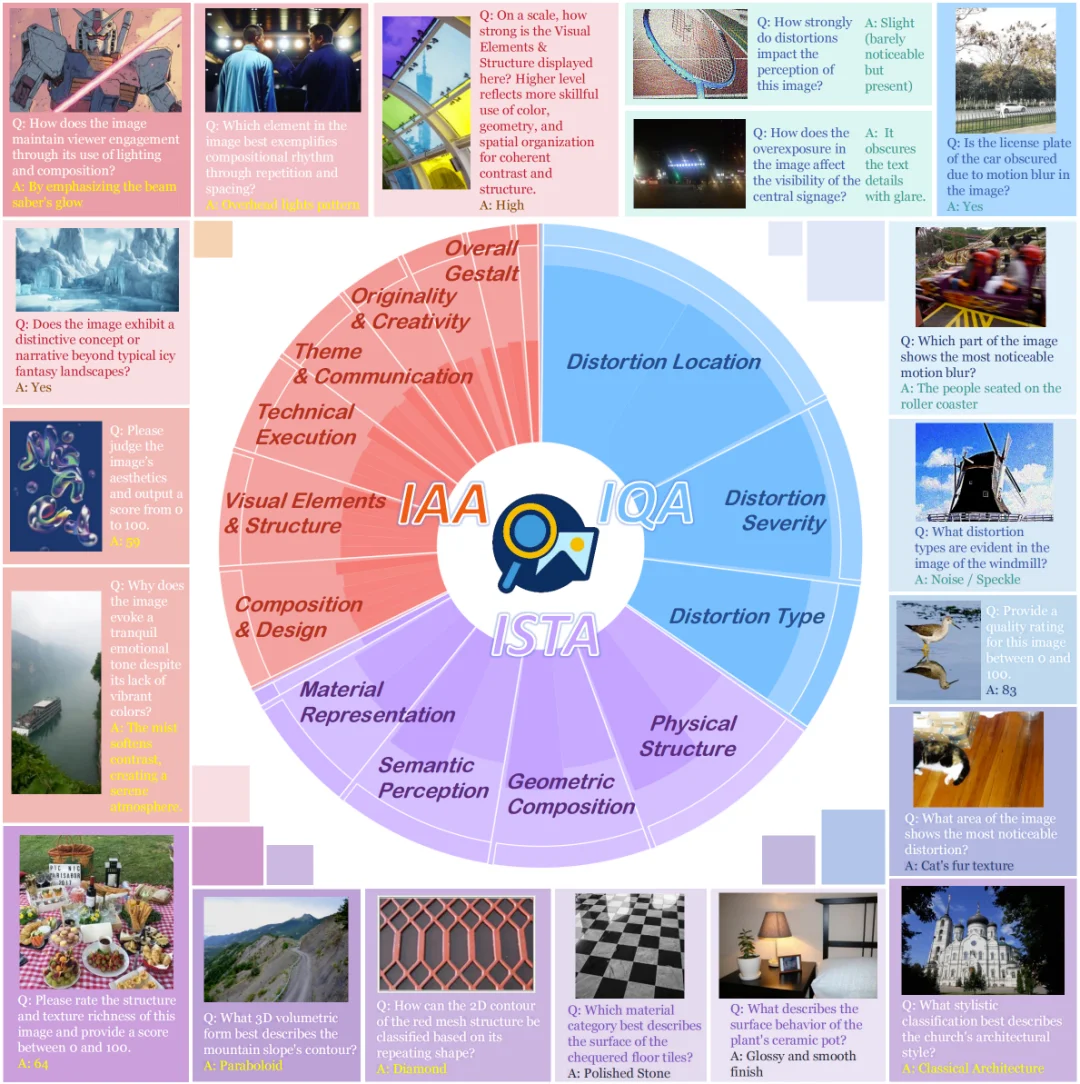
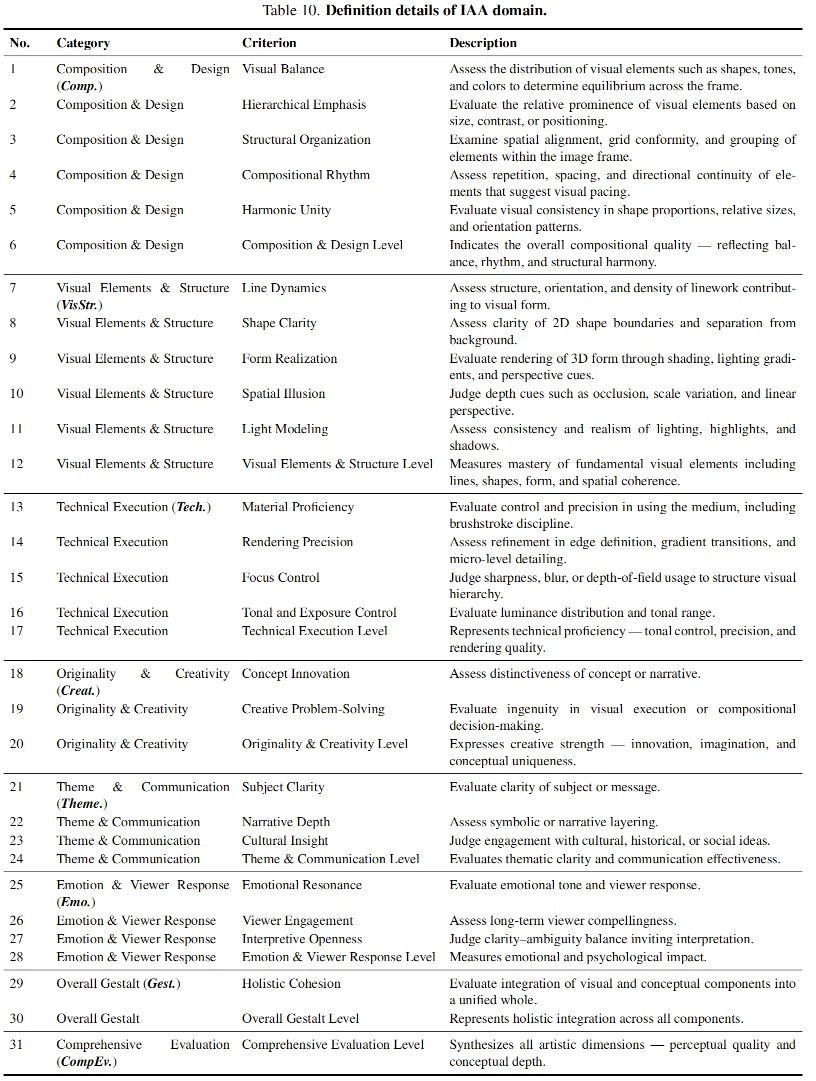
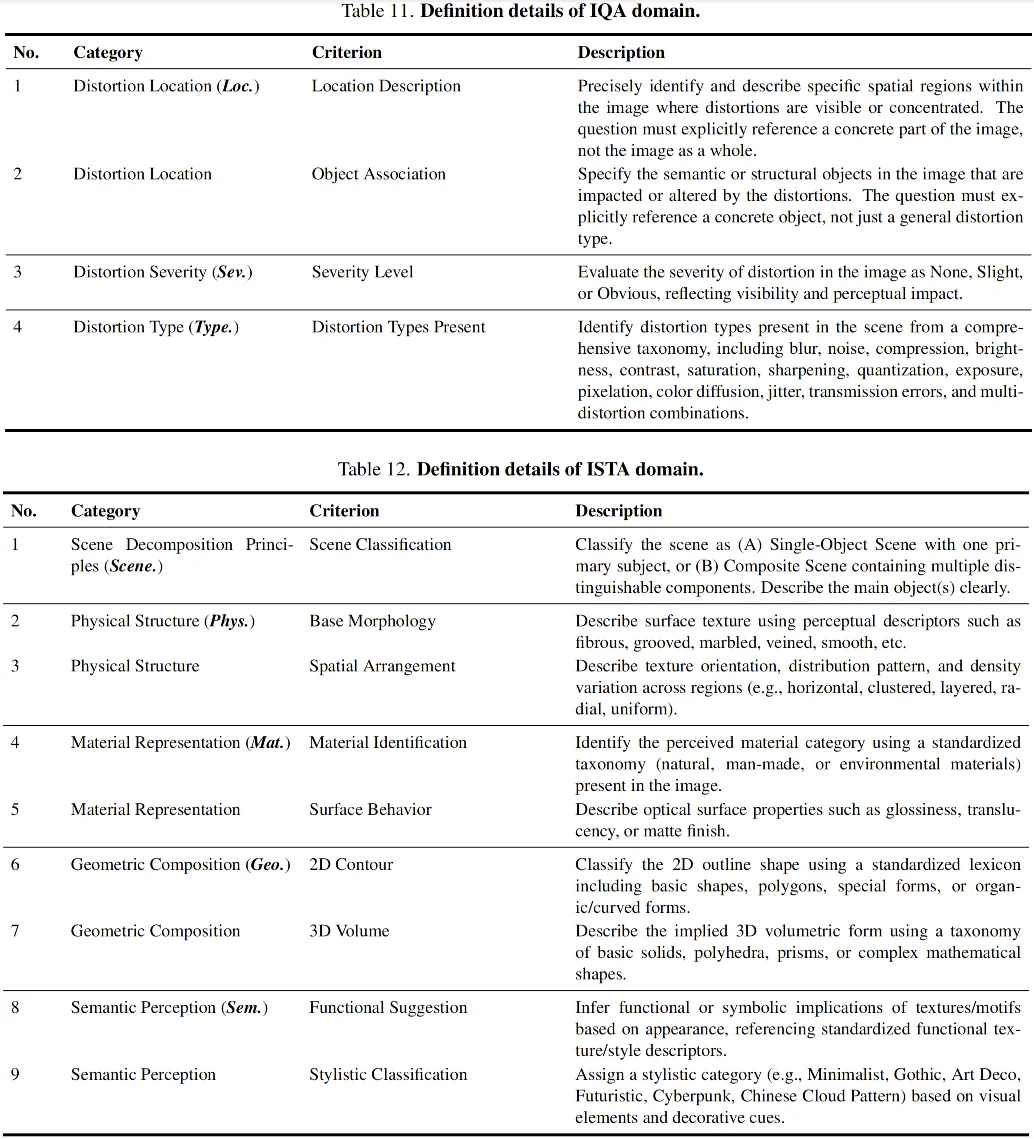
UniPercept-Bench 的定义体系分为三级细分,包含 3 个领域、17 个类别和 44 个细分准则,给出了专家级的细致定义体系,其精细程度远远超过此前的图像评估 Benchmark。
在具体定义上,它实现了从领域到准则的精密解构:例如从美学(IAA)领域,到「构图与设计(Composition & Design)」类别,深入到对「视觉平衡(Visual Balance)」这一微观准则的量化;或从场景解析(ISTA)领域,到「几何构成(Geometric Composition)」类别,细化到对「3D 体积(3D Volume)」隐含信息的提取。这种三级联动的体系,确保了模型能够从宏观的「整体感知」跨越到微观的「渲染精度」进行全方位、多维度的专家级评估。
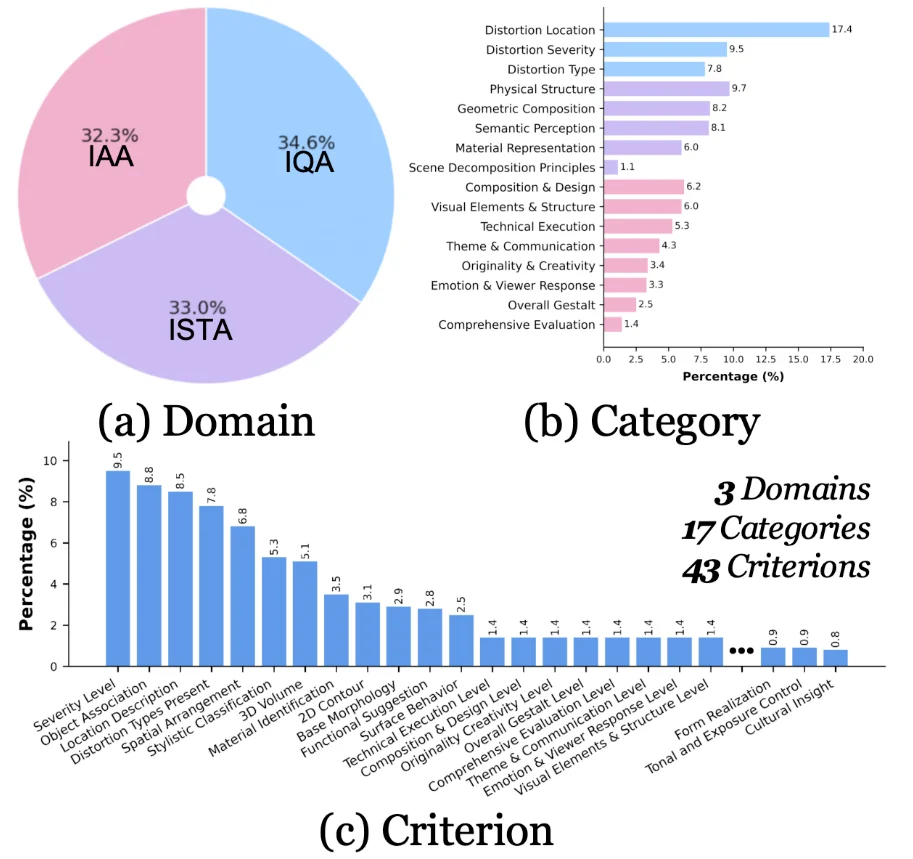
该基准支持 视觉评分(Visual Rating, VR) 和 视觉问答(Visual Question Answering, VQA) 两种互补的任务形式。

为了确保数据质量,研究团队设计了三阶段自动化流水线:
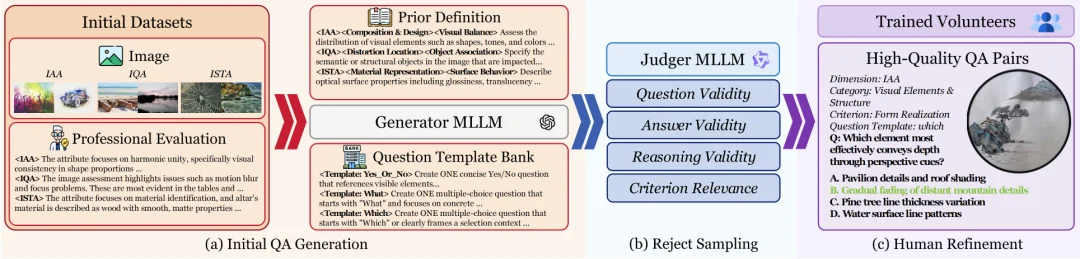
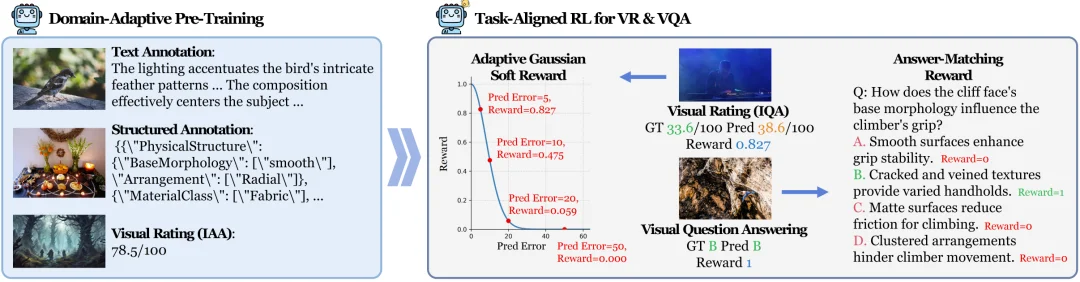
为了使模型具备真正的感知能力,研究者采用两阶段框架对基础多模态模型进行持续演进。
领域自适应预训练(Domain-Adaptive Pre-Training)
研究团队整合了约 80 万个样本的大规模语料库,涵盖文本描述、结构化标注和数值评分。通过这一阶段,模型习得了跨领域的底层视觉特征,为其后续的精准判断打下了相应的感知基础。
任务对齐强化学习(Task-Aligned RL for VR & VQA)
这是提升模型感知一致性的关键。研究者采用了 GRPO 算法进行策略优化,并针对感知任务设计了特定的奖励函数:
这种软奖励机制提供了更平滑的梯度,避免了传统阈值奖励导致的优化不连续性。此外,模型引入了评分 Token 策略,直接从预测概率分布中导出数值,大幅缓解了模型生成数字时的幻觉倾向。
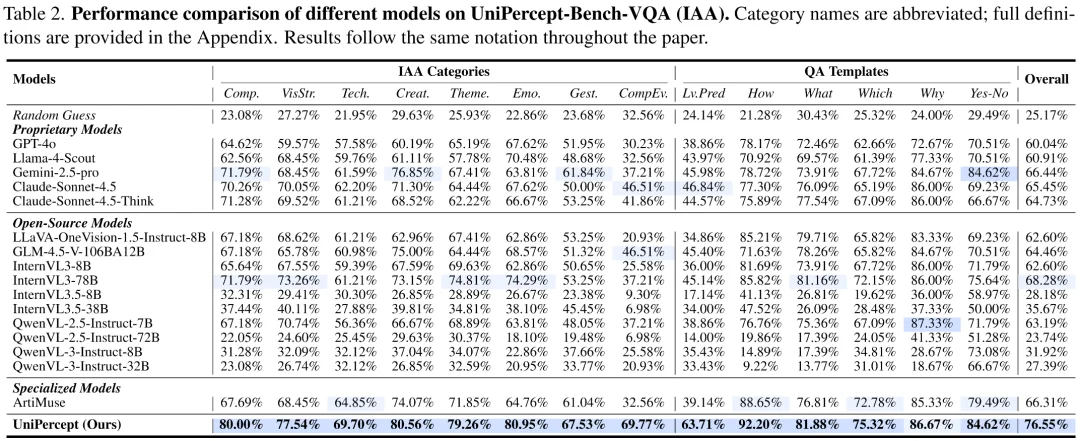
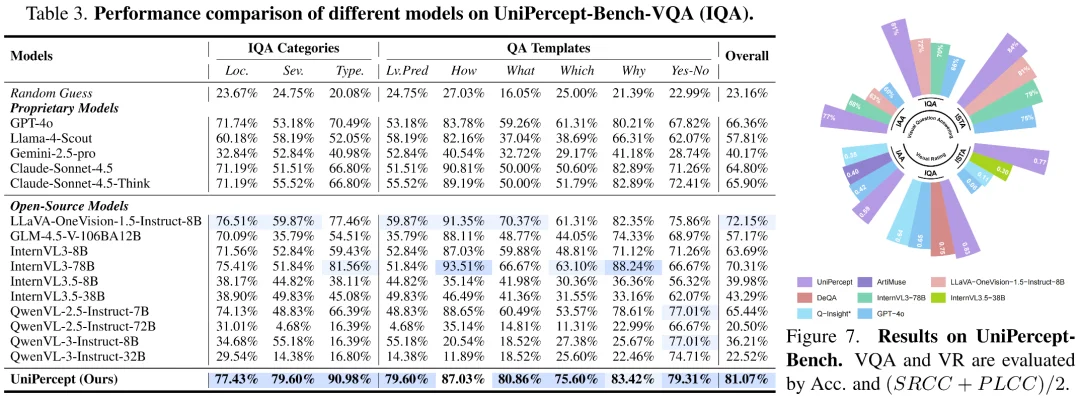
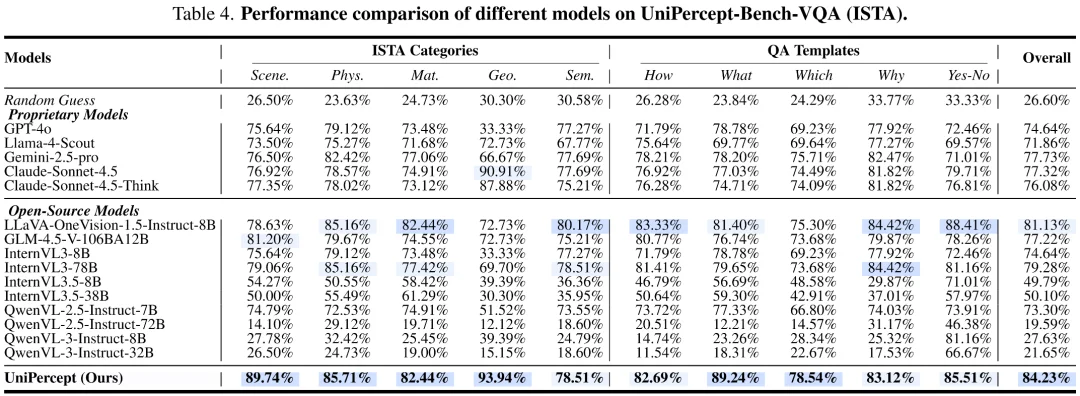
研究团队在 UniPercept-Bench 上评估了包括商用闭源模型系列、领先开源系列以及针对美学和质量优化的专用模型在内的 18 个模型,UniPercept 在其中取得了显著优秀的表现。
视觉评分(VR)表现
在持续分数的回归任务中,大多数通用模型在没有针对性训练的情况下表现较差。相比之下,UniPercept 在所有三个领域(美学、质量、结构)中均取得了最高的斯皮尔曼相关系数(SRCC)和皮尔逊相关系数(PLCC)。尤其是在 ISTA 领域,UniPercept 填补了现有模型对细节纹理判断的空白。
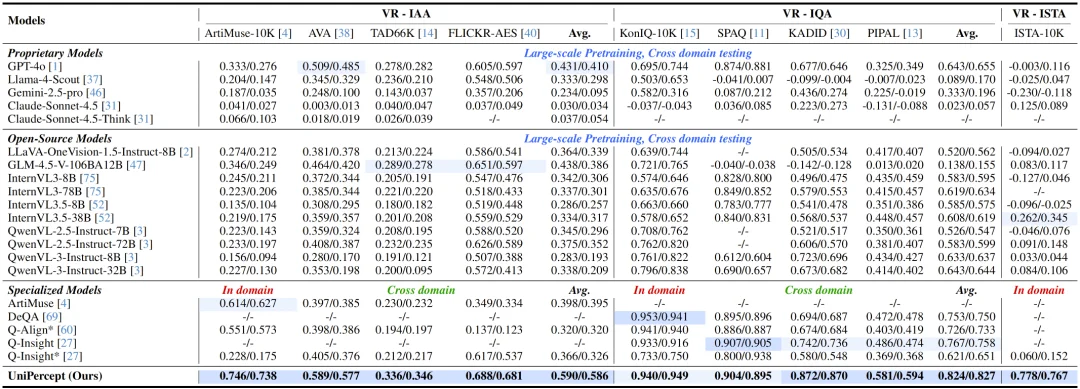
视觉问答(VQA)表现
实验显示,即使是目前最顶尖的商业模型在处理精细感知问题时也显得吃力:
UniPercept 展示了作为生成模型优化信号的巨大潜力。研究者将其作为奖励模型,整合进文生图模型的微调流水线中。UniPercept 主要从以下三个方面对生成模型进行优化:
不同奖励信号有着不同的优化侧重点,当三个维度的奖励信号协同作用时,生成的图像在视觉吸引力和技术保真度上均达到最优。
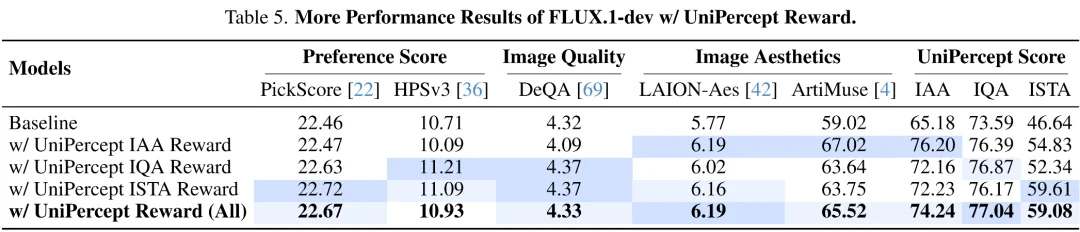

此外,UniPercept 天然可以作为从美学、质量、纹理与结构三方面对于图像进行评估的 评估指标(Metrics),可以准确反映不同模型输出图像的各方面表现。
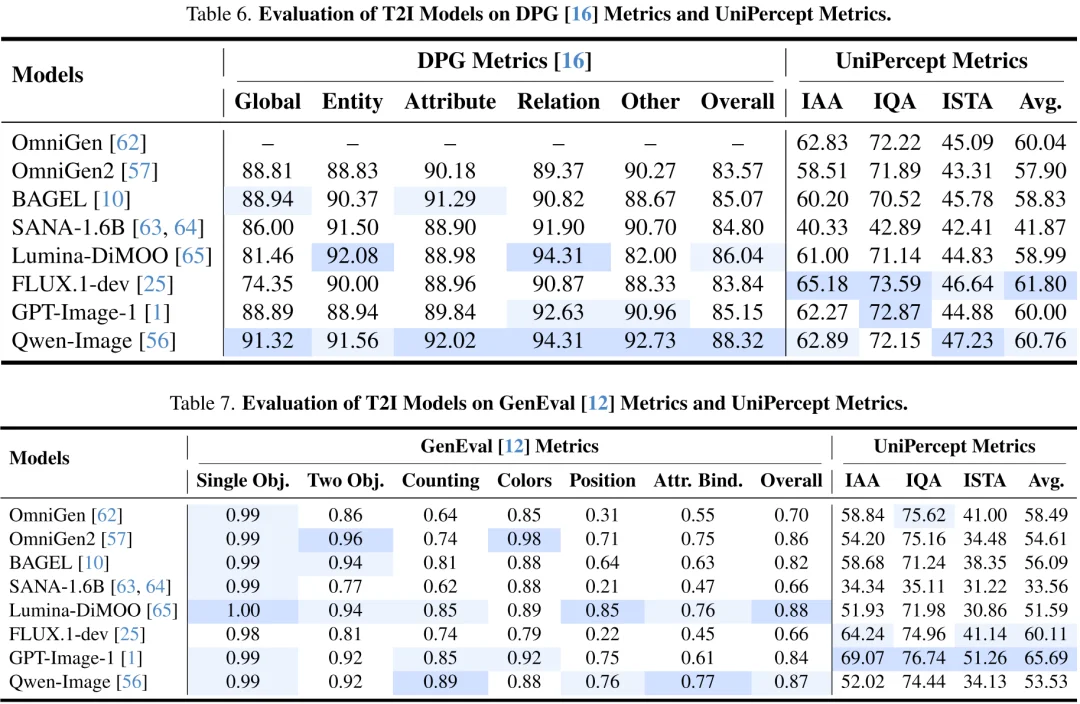
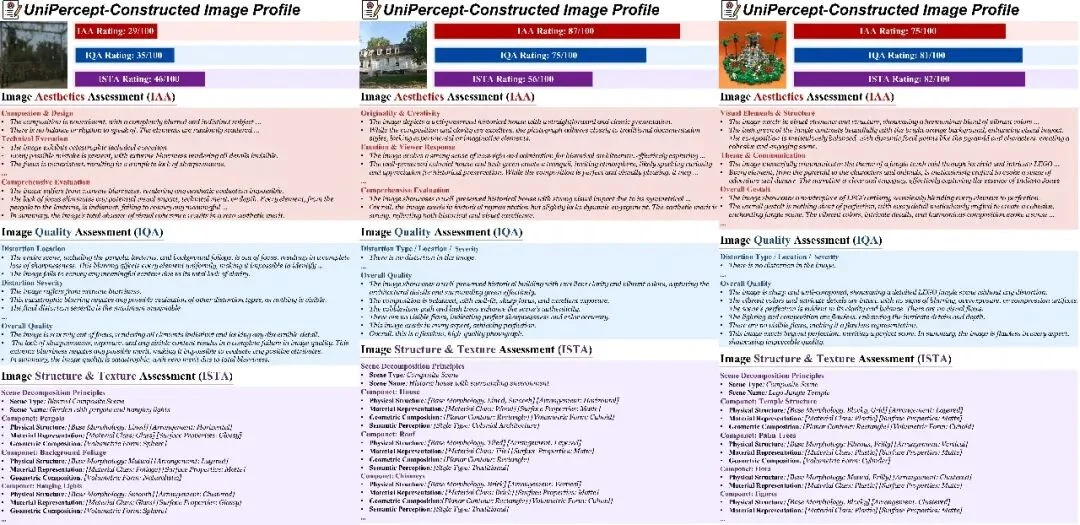
UniPercept 还能为图像生成全方位的「感知档案」,不仅给出评分,还能从美学、质量、纹理与结构三个方面针对构图、执行精度、损伤位置等具体维度给出详细的文字解析与结构化输出。
UniPercept 的提出,是多模态大模型的研究重心正在从单纯的语义识别,向更具挑战性的「感知图像」转化的重要一环。通过建立统一的评价基准、高效的数据生产线以及新颖的任务对齐学习策略,UniPercept 为未来的视觉内容评价与可控生成提供了一个强大的底座。它不仅是研究感知的有力工具,更是构建「感知闭环」系统的重要一步。
随着感知级理解能力的不断提升,人工智能将能够像人类艺术家一样,不仅能看懂画面中的故事,更能体会并创造出具备极致美感与精湛质感的视觉作品。
文章来自于“机器之心”,作者 “操铄、李佳阳”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
