# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

从电商团队到视觉设计师,如今任何人都能在几分钟内生成数百张可投入生产的图片。几年前,这样的产量需要数千名摄影师、工作室和制作人员。长期以来支配电商及其他数字领域的成本结构已经发生了转变。传统的内容生产壁垒正在消散,这要归功于生成式媒体(Generative Media)基础设施的发展。
生成式技术突破带来的首要影响,是用户和开发者创造潜力的大幅拓展。娱乐应用率先推动了生成式媒体的采用,但到 2025 年,生产应用(如电商、广告、创意工作室)推动了规模化发展[1],到年底有 88% 的组织在至少一项业务职能中部署了 AI[2]。
Jeffrey Katzenberg 阐述了这一根本性变革:这是人类有史以来前所未有的故事讲述的民主化。
这一转变源于生成式技术的快速进步——模型达到了曾经只有专业制作团队才能实现的质量、可控性和可靠性水平。
fal.ai 是一个专注于生成式媒体的 AI 平台,曾获 a16z 等知名机构投资,主要为开发者、企业和应用提供图像、视频、音频、3D 等多模态 AI 模型的高速推理 API 和基础设施服务。
他们最近推出了一份报告,考察了生成式技术和趋势在 2025 年如何加速发展。这些洞察大量引用了从各类组织和个人用户中收集的调查数据[4]。我们收录了在十月份生成式媒体大会上发言的行业领袖的精彩观点,以及涵盖生成式技术变化格局的最具影响力的市场研究。生成式媒体正在改变我们讲述故事、建立商业和与用户互动的方式。
这标志着数字时代新篇章的开始。以下为全文精校翻译。
注:感谢特工宇宙战略顾问 @庄明浩 老师推荐。
2025 年,视频生成模型产出的内容已能通过普通观察者的视觉图灵测试[5]。2025 年,图像、视频和音频生成的技术能力均取得了巨大进步,不同模态达到了相似的发展阶段。图像编辑能力重振了一个看似在衰退的品类。对所有行业和模态而言,基础设施优化充分降低了延迟,使更多实时应用成为可能。
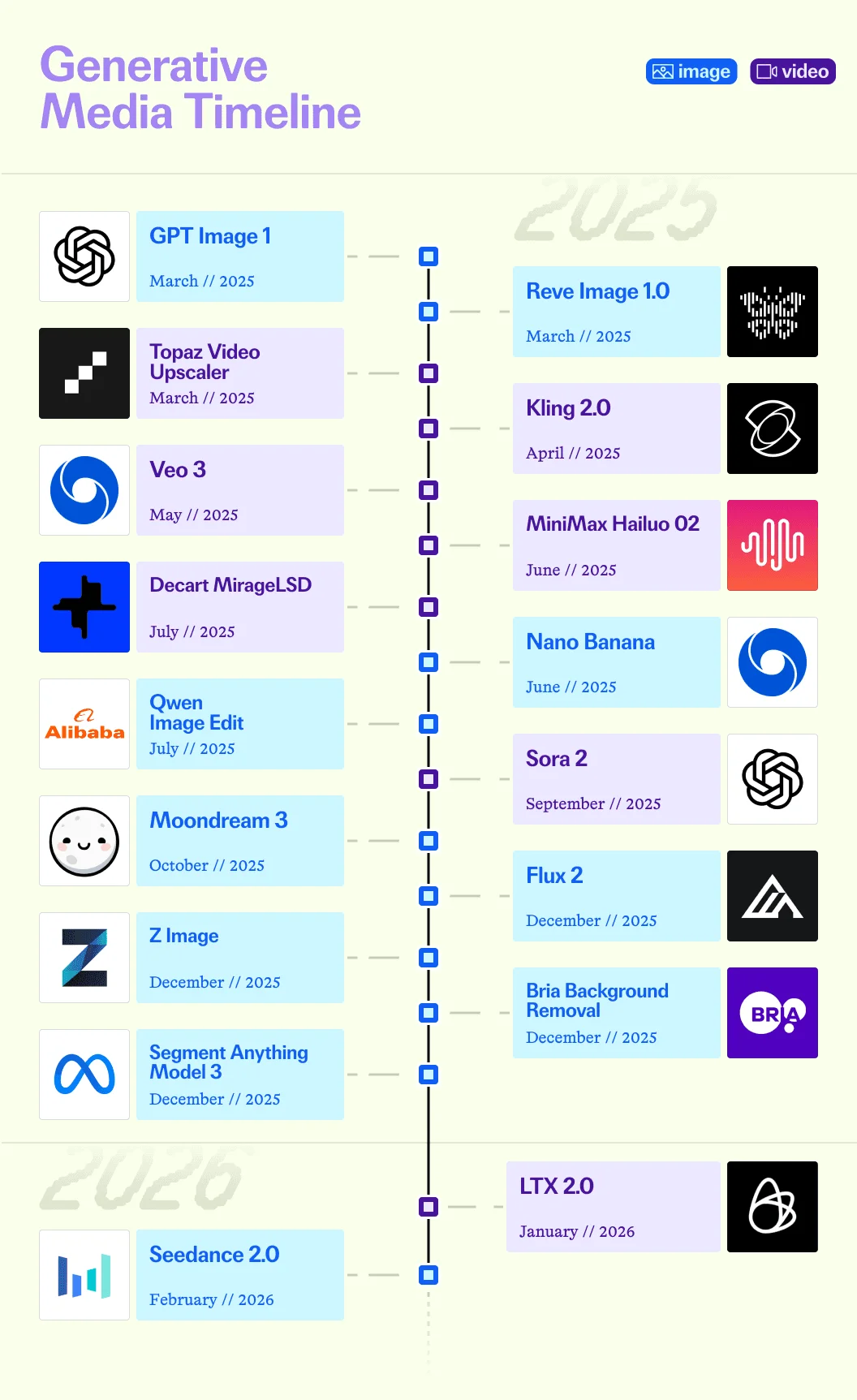
虽然个别发布定义了关键拐点,但 2025 年更宏大的故事是规模化。模型发布不再是孤立的突破,而是在各模态持续涌现,推动每个创意媒介的扩展:

2025 年,图像生成从实验性工作流转变为生产管线。Black Forest Labs 发布了 Flux.1 Dev,具有出色的提示词遵循能力、文本渲染精度和人体姿态保真度。该模型建立了竞争对手数月追赶的基准。OpenAI 的 GPT Image 1 为新一代用户创造了一个文化时刻——该模型的吉卜力工作室美学在社交平台上获得了数十亿次观看。

Black Forest Labs 推出了 Flux Kontext,这是首个专用图像编辑模型,实现了角色一致性、风格迁移和近实时速度的局部编辑。Qwen Image Edit 作为首批支持 LoRA 功能的开源图像编辑模型之一,让没有企业级计算预算的开发者也能进行微调。
Google DeepMind 的 Nano Banana (v1) 证明了无技术能力的用户也能通过自然语言生成生产级质量的内容。字节跳动的 Seedream 4.0 在保持同等输出质量的同时,以更低的计算成本实现了更快的生成速度。
最受欢迎的模型(按日均请求量):
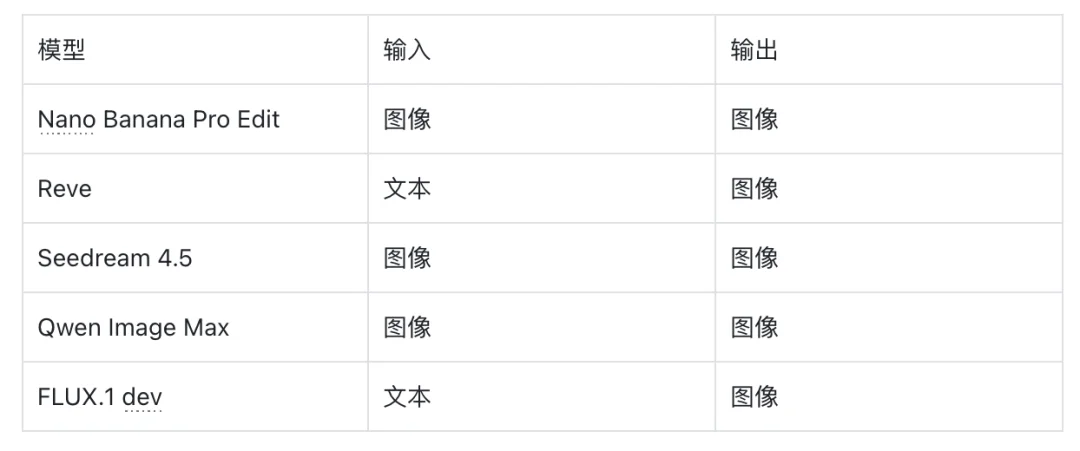
十个月内八次重大视频生成发布带来了快速的竞争迭代。性能领先地位多次易手,各公司以企业软件领域罕见的速度推出产品。Google DeepMind 于 2024 年 12 月发布了 Veo 2,以物理准确的视频确立了质量基准。该模型的物理模拟准确建模了重力、水流动力学和物体交互,为生产就绪的视频生成设定了质量标杆。
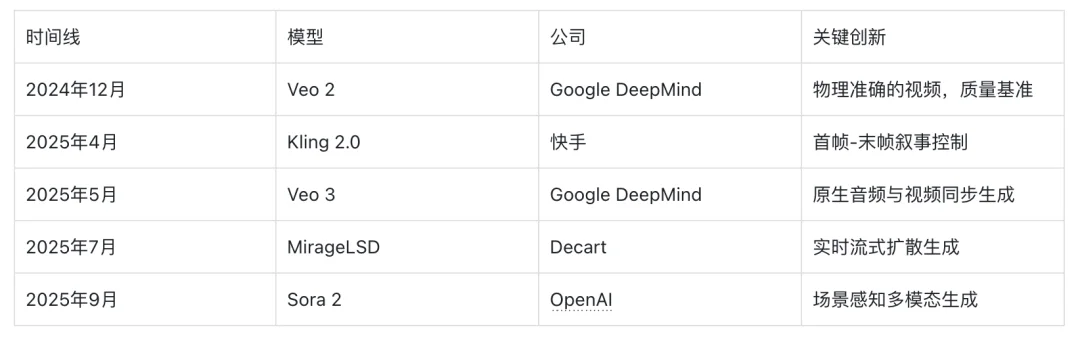
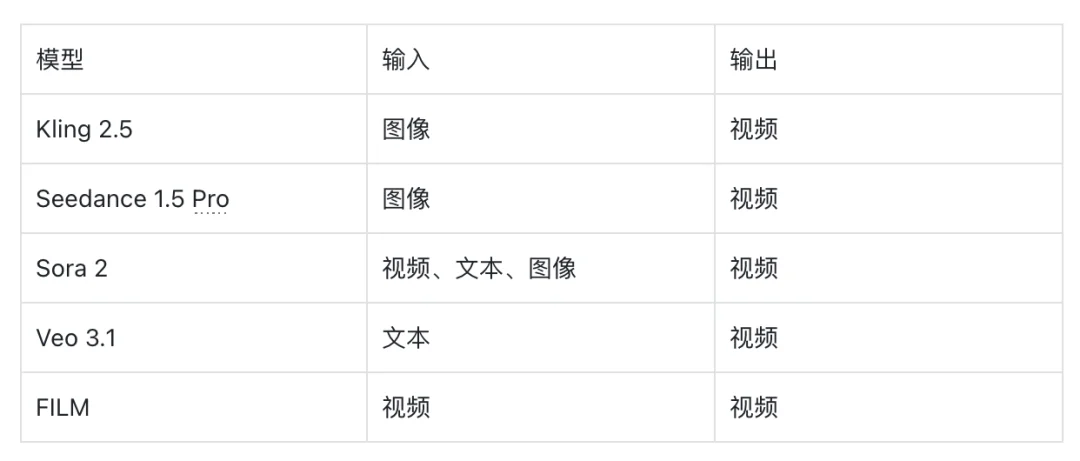
2025 年 2 月的 PixVerse v4 将触达范围扩展到技术用户以外,展示了精密的视频生成可以覆盖主流创作者。2025 年 4 月的 Kling 2.0 引入了首帧-末帧功能,让创作者对生成的序列拥有精确的叙事控制,并允许一致的角色描绘。
2025 年 5 月的 Veo 3 为社交媒体和内容频道启用了快速周转工作流。该模型将速度、质量与原生音频生成相结合,让内容创作者能在数小时而非数天内完成生成、迭代和发布。2025 年夏季竞争加剧。MiniMax 的 Hailuo 02 和字节跳动的 Seedance 1.0 均于 2025 年 6 月推出,证明多种技术路线可以同时达到顶级性能。
2025 年 7 月,Decart 的 MirageLSD 通过实时流式扩散逐帧生成视频。这一方法开辟了批处理模型无法解决的直播和互动娱乐应用。2025 年 9 月的 Sora 2 在单一输出中结合了原生音频和出色的多镜头生成,无需手动编辑即可实现连贯的场景转换。
2025 年每 4-6 周就有重大发布,性能提升扩展了娱乐、营销和教育领域的可行用例。
最受欢迎的模型(按日均请求量):
2025 年,音频成为最具生产就绪性的生成式媒体类别之一。ElevenLabs Turbo v2.5 是使用最广泛的低延迟文本转语音系统之一(约 250-300 毫秒),而 MiniMax Speech-02(2025 年 5 月)在 32 种语言中实现了 99% 的人声相似度。正如一位生成式语音用户所说:“低于 300 毫秒是语音 AI 的基本门槛。超过这个值,体验就会崩塌。”[6]
开源替代方案扩大了可及性。Apache 2.0 许可的 Kokoro TTS 以 8200 万参数实现了生产级质量。Nari Labs 的 Dia 1.6B TTS 提供了超逼真的对话合成。
ElevenLabs 的 Eleven Music(2025 年 8 月)是首个完全基于授权数据训练的主要 AI 音乐模型,建立了选择性参与机制和艺术家 50/50 分成。Suno 通过高质量、基于提示词的歌曲生成推动了快速的消费者采用。Mirelo SFX v1.5(2025 年 10 月)等模型能从视频自动创建同步的音效和音乐。
最受欢迎的文本转语音模型:
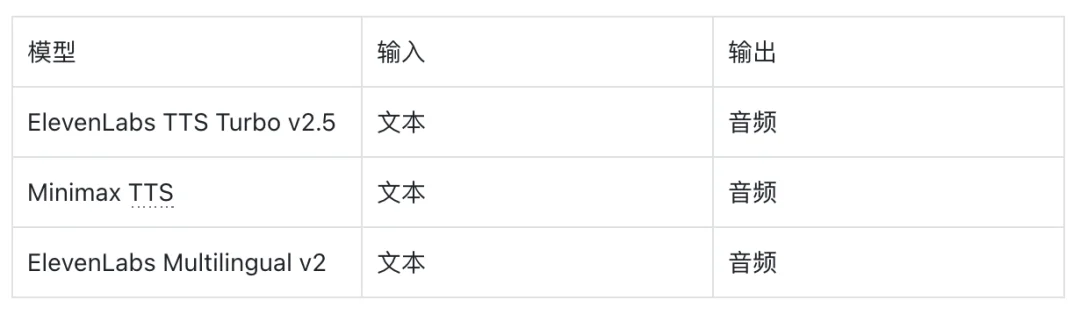
最受欢迎的语音转文本模型:
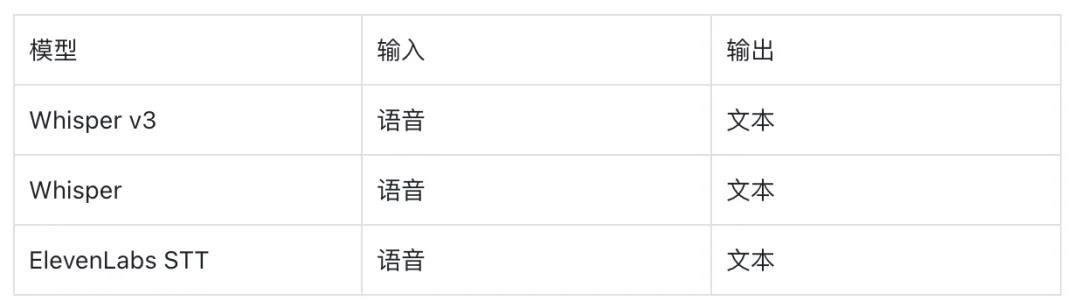
2025 年,3D 生成从实验性输出成熟为生产资产,将建模时间从数周压缩至数分钟。腾讯于 2025 年 1 月发布了混元 3D 2.0。Deemos 于 2025 年 4 月推出了拥有 40 亿参数的 HyperRodin Gen 1.5。Meshy 于 2025 年 7 月推出了第 5 版,10 月推出了 v6 预览版,获得了 Andreessen Horowitz 在其游戏开发者调查中的认可[18]。
Tripo 3.0 于 2025 年 9 月服务了超过 300 万创作者和 700 多家企业[26]。微软最近于 12 月发布的 TRELLIS 2 能在 3 秒内生成高分辨率资产,为实时应用创造了机会。
3D 模型的进一步创新即将到来。生成的网格仍需拓扑清理才能用于动画工作流。几何精度在复杂机械组件上会下降。硬表面建模可能需要大量手动修整。
最受欢迎的 3D 模型:
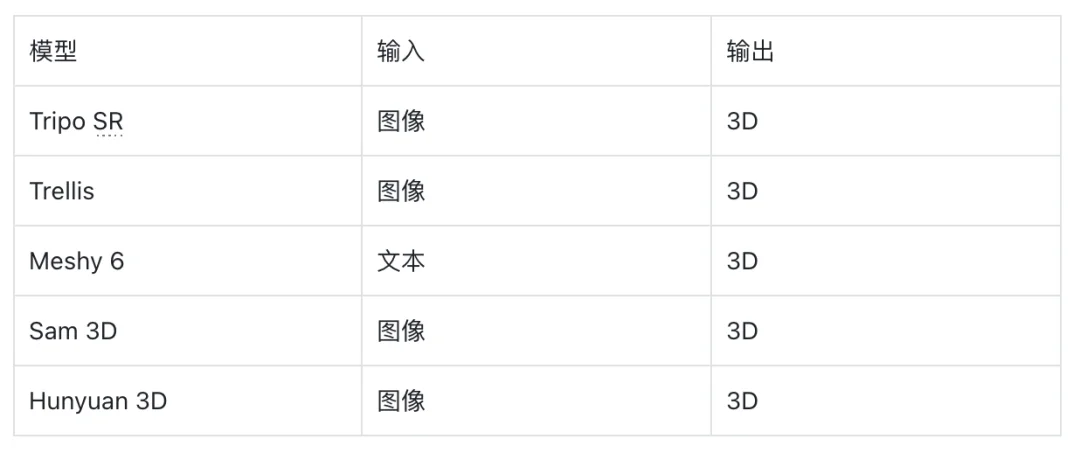
创造力不是机器生成机器的产出。它是那个无法接触到特效实验室的孩子现在能做这些事情。我们在加速人类的创造力。
世界模型同时生成和模拟交互式 3D 环境,所有模态在此汇聚。DeepMind 于 2024 年 12 月宣布了 Genie 2,能从单张图片提示生成可玩的 3D 环境。用户和 AI 智能体使用键盘和鼠标导航,模型在物理一致的空间内模拟动作后果。系统可保持 10-20 秒的一致性,部分环境可持续达一分钟[25]。
李飞飞的 World Labs 于 2025 年 11 月推出了 Marble——首个商业化的世界模型产品。Marble 从文本、图像、视频或全景图生成持久且可下载的 3D 环境。平台输出高斯散点、网格或视频格式的环境,可集成到 Unity、Unreal Engine 和 VR 头显。
世界模型正在将视频生成的时间理解和 3D 建模的空间推理统一到实时交互中。这使得自动驾驶车辆可在模拟城市中训练,游戏开发者可从草图原型化世界。目前系统大多用于原型部署,而非完整的生产发布。
基础模型将在核心指标(分辨率、时间一致性、物理真实感)上继续提升,但随着模型接近基本极限,提升速率可能会放缓。解决局限性将需要超越当前扩散和 Transformer 方法的架构创新。最近的模型发布预示着新方向的可能性:
从第一天使用 Stable Diffusion 开始,我就被生成式媒体深深吸引。每天,我信息流中的 AI 内容质量都在变好。它无处不在。
Flux.2 通过架构改进实现了 3 倍推理加速且质量相当,改变了大规模图像生成的经济性。增强的提示词遵循和改进的文本渲染解决了持续存在的生产部署挑战。
阿里巴巴通义实验室的 Wan 2.6 于 2025 年 12 月 16 日发布,引入了原生音视频同步。该模型可生成 1080p 的 15 秒视频,配有同步对话、音效和背景音乐,同时在多镜头叙事中保持角色一致性。
Kling O1 在视频编辑方面引入创新,支持此前需要手动链接的复杂多步骤指令,减少了复杂视频工作流中的人工干预。
Meta 的 SAM 3D 于 2025 年 11 月 19 日发布,能从单张图像重建具有几何体、纹理和空间布局的 3D 物体。两个变体分别处理日常物品(SAM 3D Objects)和人体姿态估计(SAM 3D Body),在现有方法中取得了较高的胜率。
企业生成式 AI 采用在 2025 年加速,采用率因行业垂直领域和用例而异。个人用户通过新兴消费应用绕过了技术门槛,无需专业知识即可即时访问。组织面临不同的障碍:模型编排复杂性、集成决策和成本管理都制约了部署节奏。企业通过两种途径获取生成式技术,在应用(65%)和 API(62%)之间几乎均分[4],许多企业两者兼用。
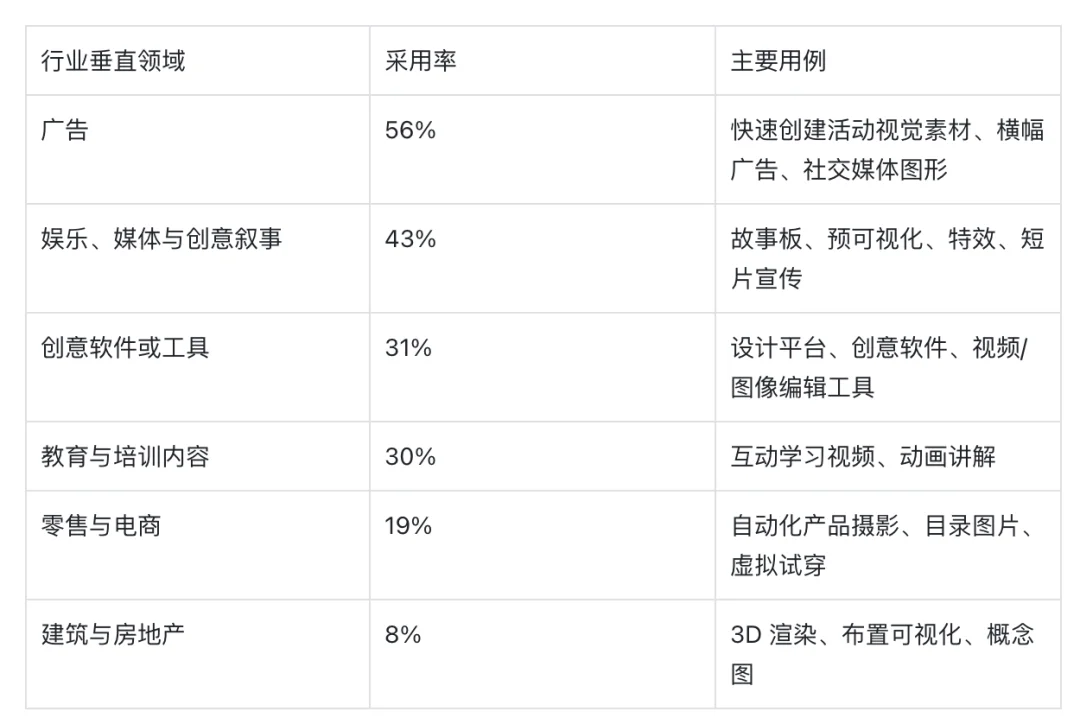
生产部署成熟度因模态而异。31% 的组织仍处于将生成式模型部署到工作流的原型阶段。创意团队倾向于使用生成式应用进行快速迭代而无需编码,而工程组织则优先选择 API 集成以实现程序化控制和工作流自动化。
随着前沿模型访问日益商品化,采用正从早期以娱乐为主的实验向外扩展。广告、电商和创意制作领域的组织正朝着可靠的生产基础设施迈进,一致的性能、可扩展性和成本效率至关重要。
生成式媒体投资回报的实现速度快于新型企业软件技术的预期[4]。但细节显示,投资回报仍然分化:实现强劲 ROI 的组织专注于具有明确指标的特定高价值用例,而追求广泛实验的组织则报告了令人失望的回报[9]。
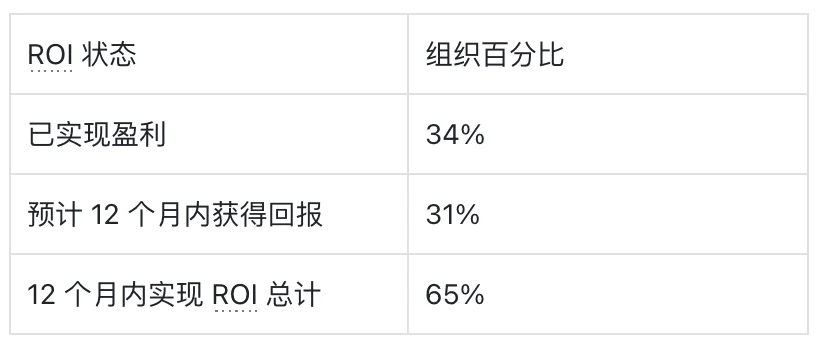
报告可衡量 ROI 的组织聚焦于三个类别:效率提升、成本降低和收入扩展。74% 的公司报告其计划达到或超过了 ROI 预期[9]。对于创意营销平台 Pimento,成果是通过消除冷启动延迟而非最大化质量来实现的——因为营销人员需要快速测试数十种变体,然后再提高精细度和保真度。部署将生成时间缩短了 80%,功能发布速度翻倍[21]。
游戏工作室需要速度而非托管控制,因为竞争优势来自于比竞争对手更早提供最新功能。数字创意平台 Layer 基于这一洞察,使精简团队能在 24 小时内向工作室发布新模型[22]。
实现生成式规模化的组织进行了超越新技术部署的结构性变革。43% 重新设计了工作流和生产管线,33% 投资于员工培训和技能提升,30% 为媒体生成基础设施分配了专项预算[4]。
营销组织的生成式 AI 采用率达 75%,高于 2024 年的 61%。然而,80% 表示在不到一半的工作中使用了 AI。法律顾虑主导了犹豫情绪:94% 将知识产权归属和责任视为实施挑战[10]。与现有创意工作流(如通过 Adobe Creative Suite、DAM 系统或活动平台)的集成比预期更具挑战性。
实现规模化的代理公司将生成式媒体用于内容变体和 A/B 测试,而非主要资产创建。72% 的营销人员认为 GenAI 是 2025 年下半年最重要的趋势[11],但仅有 30% 在整个活动生命周期中实现了完全集成[12]。这一差距表明了紧迫的基础设施需求:活动规模的程序化生成、品牌一致性保障,以及某些行业合规所需的审计追踪。
电商平台展现了较高的采用率,产品图像生成成为核心基础设施能力。Matt Koenig 阐述了区分电商与其他垂直领域的关键约束:
模型的创造力绝对不能干扰产品保真度。图像和视频必须忠实呈现每一个产品。
电影和电视制作在主要运营工作流中展现了谨慎乐观的采用态度。大型工作室将不到 3% 的制作预算分配给生成式 AI,同时将 7% 的运营支出转向用于合同管理、许可和规划的 AI 赋能工具[13]。独立工作室遵循不同的模式:自 2022 年以来已有 65 家以上以 AI 为核心的电影工作室成立[15],在整个制作管线中使用生成式 AI。
所有媒体公司 68% 的采用率[14]反映的是在预可视化、自动编辑和后期制作特效增强方面的部署,而非主要内容创作。尽管如此,媒体公司的 AI 支出预计将在 2024-2029 年间以 37.2% 的复合年增长率增长,从 26 亿美元增至 125 亿美元,表明尽管当前制作预算保守,但投资仍在持续。
不同的生成式采用率强调了老牌工作室在优化运营成本,而新进入者则在依靠新能力重构制作经济性来竞争。Katzenberg 在生成式媒体大会上强调了深层的制度性约束:
最伟大的创新不会发生在传统企业内部。它们就是无法放下过去、面向未来创新。
游戏工作室展现了强劲的采用态势,68% 积极将 AI 融入工作流[17]。游戏领域生成式媒体的增长来自于与传统资产时间线不兼容的快速迭代需求,以及专注于更可预测生成的技术基础设施。40% 的工作室实现了超过 20% 的生产力提升,25% 实现了超过 20% 的成本节约[18]。
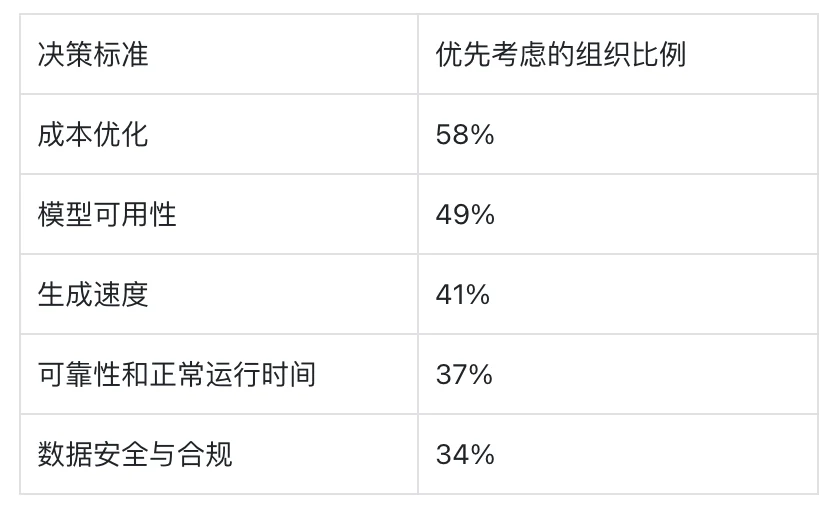
用例涵盖从概念艺术加速到纹理生成、NPC 对话变体、动画中间帧和 AI 增强的程序化关卡生成。基础设施选择强调生成速度(41%)和可靠性(37%),而非最高质量[4]。这一偏好解释了游戏对生成式媒体 API 的显著采用:程序化控制使得与开发管线的集成成为可能。
游戏的基础设施需求不同于其他垂直领域:动态内容的实时生成、资产库的批处理,以及游戏引擎集成。对能够快速部署模型并随不可预测的玩家负载扩展的基础设施需求旺盛。Burkay Gur 描绘了生成式游戏的未来:
文本到游戏将是文本到视频的延续;本质上是让视频输出变得可交互。我们离这一目标并不遥远。这是世界模型的绝佳用例。
视频与交互性的融合代表了从内容创作到世界模拟的根本性转变。文本到游戏的能力将使动态的、AI 生成的游戏环境能够实时响应玩家行为,将游戏从预先编写的体验转变为涌现式叙事。
教育行业代表了生成式媒体最大的未开发机遇之一,结合了巨大的市场规模与历史上有限的技术采用。Sonya Huang 阐述了这一潜力:
我对教育用例最感兴奋。教育是一个如此重要的市场,却从未有过那么多有说服力的商业案例。挑战在于大规模创建对学习者最理想的高质量内容的瓶颈。
传统教育内容生产面临 Huang 指出的同样限制——大规模创建高质量、个性化内容在经济上一直是不可承受的。Gorkem Yurtseven 对生成式 AI 在教育领域的前景有同样强烈的预测:
教育市场目前在视频生成方面几乎未被触及。那里有巨大的潜力,只是在等待质量和可预测性的提升来开辟新的用例。
当前的局限性——特别是一致性和可控性——制约了教育部署。教育内容要求事实准确性、文化敏感性和跨多周课程序列的课程连贯性。随着这些能力的成熟,教育可能成为最大的生成式媒体市场之一,驱动力是大规模个性化学习的需求。
2025 年,基础设施质量成为开发速度的决定性因素。成功扩展生成式 AI 部署的组织优先考虑优化的服务基础设施,而非模型选择。在游戏领域,工作室需要将资源集中在核心业务能力上,而非 GPU 管理[22]。
尽管持续报告积极的 ROI,在实现大规模生产部署方面挑战依然存在。基础设施提供商在速度和可靠性方面差异很大,冷启动中断了用户流程[21]。
采用模式揭示了团队在图像和视频工作负载中整合基础设施的方式,以及哪些提供商在生产环境中受到信任。以下数据显示了受调查组织如何在 API 提供商之间分配图像和视频生成工作负载:
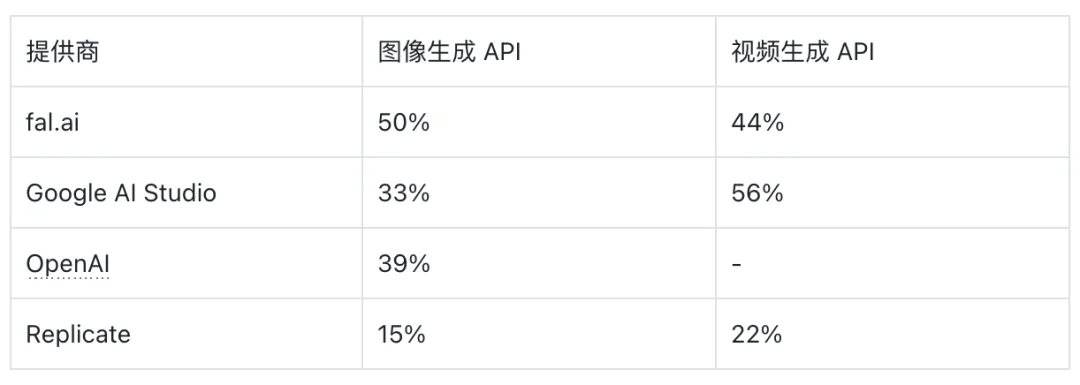
这些技术选择会随时间复合。每天处理数百万请求的产品通过在内核和网络层的持续优化建立竞争优势,而非季度功能冲刺。基础设施合作伙伴的响应能力与原始性能同样重要;信任和协作进行测试与基准评测的意愿成为关键选择因素[21]。
企业生产部署使用的模型中位数为 14 个[24]。认为单一全能模型能处理所有生成式任务的信念被证明是不正确的。生产部署表明,针对特定任务的优化在专门应用中始终优于通用方法。
人们预测了能生成每种类型令牌的全能模型,但越来越清楚的是,你需要针对特定输出进行优化。最好的超分辨率模型只做超分辨率;所有这些专门任务都需要有自己权重的专用模型。
这种增殖创造了企业组织难以管理的复杂性。简化模型选择、测试、切换和跨多提供商性能监控的工具存在重大机遇。
某些企业用例越来越倾向于在生产部署中使用开源模型而非封闭 API。开源的透明性使企业团队能够审计模型行为、确保数据隔离,并在本地部署而不受供应商锁定。Jennifer Li 在生成式媒体大会上分享了见解:
如果我们有一个开源模型,代码可用,模型可用,他们可以测试,可以使用……自托管的进入门槛比封闭模型低得多。
无论是否自托管,组织都需要在推理优化、多租户效率和地理分布方面具备卓越能力。随着基础模型更加商品化,基础设施决策将决定生成式部署的速度和成功。
2026 年及以后的生成式媒体发展轨迹已很清晰。三大主题将主导:
1. 多模态进步(如世界模型)
2. 基础设施优化
3. 创意工具的民主化
专业知识将变为编排而非执行。品味变得稀缺,而能力变得充裕。随着技术能力更加商品化,根本价值主张发生转变。“重要的是讲故事。”[19]
Katzenberg 描述的创意民主化将以新形式展现。个人创业者将生成与大型制作公司无异的视觉内容。成功将生成式技术融入产品的组织将在编排、部署可靠性和领域特定优化方面展开竞争。
持久的竞争护城河将属于那些懂得如何最佳部署生成式媒体的团队——在生成专业媒体比以往任何时候都更容易的今天。
参考文献:
1. Generative Media Conference (October 24, 2025). Zhang Yongliang presentation.
2. McKinsey & Company (2025). The state of AI in 2025. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
3. Generative Media Conference (October 24, 2025). Jeffrey Katzenberg keynote.
4. Artificial Analysis & fal (2025). State of Generative Media Survey Report 2025. https://artificialanalysis.ai/media/survey-2025#use-of-models
5. Variety (2025). Video Generation Model Evaluation in 2025. https://variety.com/vip/video-generation-model-evaluation-in-2025-veo-2-sora-pika-ray2-1236276435/
6. fal (2025). PlayAI and fal Customer Case Study. https://fal.ai/customer-case/playai-and-fal
7. Tochilkin, D., et al. (2024). TripoSR: Fast 3D Object Reconstruction from a Single Image. arXiv:2403.02151. https://arxiv.org/abs/2403.02151
8. SNS Insider (2025). AI-Generated 3D Asset Market Report 2024-2032. https://www.snsinsider.com/reports/ai-generated-3d-asset-market-7835
9. Deloitte (2024). State of Generative AI in the Enterprise 2024. https://www2.deloitte.com/us/en/what-we-do/capabilities/applied-artificial-intelligence/content/state-of-generative-ai-in-enterprise.html
10. 4As & Forrester (2025). The State of Generative AI Inside US Marketing Agencies. https://www.aaaa.org/resource/the-state-of-generative-ai-inside-us-marketing-agencies-2025/
11. Mediaocean (2025). 2025 H2 Market Report. https://www.mediaocean.com/press-releases/07/16/2025/h2-market-report-release
12. IAB (2025). State of Data 2025. https://www.iab.com/insights/2025-state-of-data-report/
13. Deloitte (2025). Technology, Media & Telecom Predictions 2025. https://www2.deloitte.com/us/en/insights/industry/technology/technology-media-and-telecom-predictions.html
14. ResearchAndMarkets (2025). AI in Film and TV Strategic Intelligence Report. https://www.researchandmarkets.com/reports/6189727/strategic-intelligence-artificial-intelligence
15. Indiewire (2025), Brian Welk. https://www.indiewire.com/news/business/ai-studios-launched-since-2022-1235103261/
16. Generative Media Conference (October 24, 2025). Jeffrey Katzenberg keynote.
17. Aream & Co. (2025). The State of AI in Gaming Survey. https://areamandco.com/insights/state-of-ai-in-gaming/
18. a16z Games (2024). State of AI in Gaming. https://gamedevreports.substack.com/p/a16z-games-use-of-ai-in-gaming-in
19. Training Data Podcast (2025). Gorkem Yurtseven, Burkay Gur, Batuhan T. and Sonya Huang. https://www.youtube.com/watch?v=s_IIjGamN3Y
20. Generative Media Conference (October 24, 2025). Matt Koenig presentation.
21. fal (2025). How Pimento Brings AI-Powered Performance to Marketers with fal. https://fal.ai/customer-case/pimento-and-fal
22. fal (2025). How Layer Accelerated Gaming Innovation with fal. https://fal.ai/customer-case/layer-and-fal
23. Generative Media Conference (October 24, 2025). Jennifer Li (a16z).
24. Generative Media Conference (October 24, 2025). Gorkem Yurtseven keynote.
25. Google DeepMind Blog (2024). https://deepmind.google/blog/genie-2-a-large-scale-foundation-world-model/
26. Business Wire (2025). https://www.businesswire.com/news/home/20250820723593/en/Tripo-the-Frontrunner-of-3D-AI-Boom-Supercharges-New-Era-in-Content-Creation-with-3.0-Upgrade
27. Generative Media Conference (October 24, 2025). Steve Jang presentation.
28. Generative Media Conference (October 24, 2025). Justine Moore presentation.
文章来自于微信公众号 "特工宇宙",作者 "特工宇宙"



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
