# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。
当前音频生成领域面临的一大挑战是模型碎片化:文本生成音效、视频配音、音乐生成分别依赖不同的专用模型,任务间的知识无法共享,泛化能力受限。
香港科技大学郭毅可院士团队最新提出的AudioX则将这些能力统一到一个模型中。
具体来说,AudioX基于Diffusion Transformer(DiT)架构,并提出了轻量级的多模态自适应融合(MAF)模块,支持文本、视频、图像、音频等多种模态的灵活组合输入,可以完成包括文本生成音效(T2A)、文本生成音乐(T2M)、视频配音(V2A)、视频配乐(V2M)、音频修复(Audio Inpainting)、音乐续写(Music Completion)在内的多种任务。
在AudioCaps、MusicCaps、V2M-bench等多个权威基准上,AudioX在多个任务上达到了SOTA。

论文链接:https://arxiv.org/pdf/2503.10522
项目主页:https://zeyuet.github.io/AudioX/
开源链接:https://huggingface.co/collections/HKUSTAudio/audiox
更值得关注的是AudioX在细粒度可控生成上的表现。在团队自建的T2A-bench以及AudioTime两个指令跟随基准上,AudioX在所有评测维度上全面领先现有方法,展现出卓越的可控生成能力。
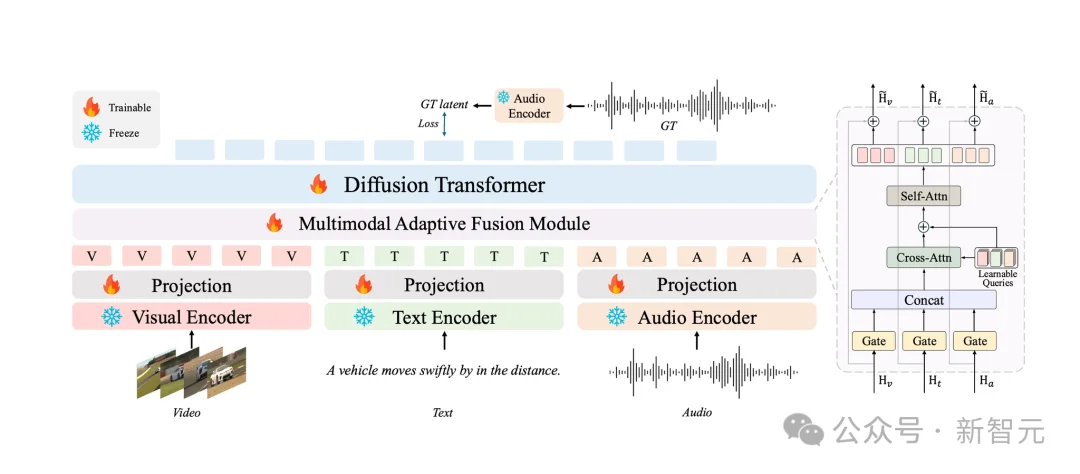
AudioX框架图
目前AudioX项目已开源,包括代码、模型权重和数据集。项目在GitHub上已获得超过1.2k Star,并一度登顶Hugging Face音频生成模型排行榜。
文字 → 音效(T2A):输入一段文字描述,AudioX即可生成对应的音效,并支持对声音事件的类别、数量、时序和时间戳的精准控制。

Thunder and rain during a sad piano solo

Footsteps followed by rapid gunshots and people speaking.

A toilet flush occurs from 1.616 to 4.458 seconds, followed by a rumble between 6.044 and 10 seconds.

A machine gun fires twice, followed by a period of silence, then the sound of waves and surf.
文字 → 音乐(T2M):给出音乐风格、乐器等文字描述,生成对应风格的音乐。

Instrumental jazz piece with piano, guitar, drums, and bass.

An orchestral music piece for a fantasy world

Playful 8-bit chiptune music for a retro platformer game

Punk rock track with electric guitar, bass, drums, aggressive and melodic.
视频 → 音效(V2A):输入一段视频,自动生成与画面内容匹配的音效。



以下视频来源于AI人工智能影像



训练统一模型的另一个关键瓶颈在于数据:现有的音频数据集要么规模有限,要么只提供粗粒度标注(如简短描述或类别标签),缺乏对事件类别、数量、时间戳、时序关系等多维度的结构化标注。
为此,团队设计了一套两阶段数据标注流水线,构建了大规模高质量数据集IF-caps(Instruction-Following Captions)。
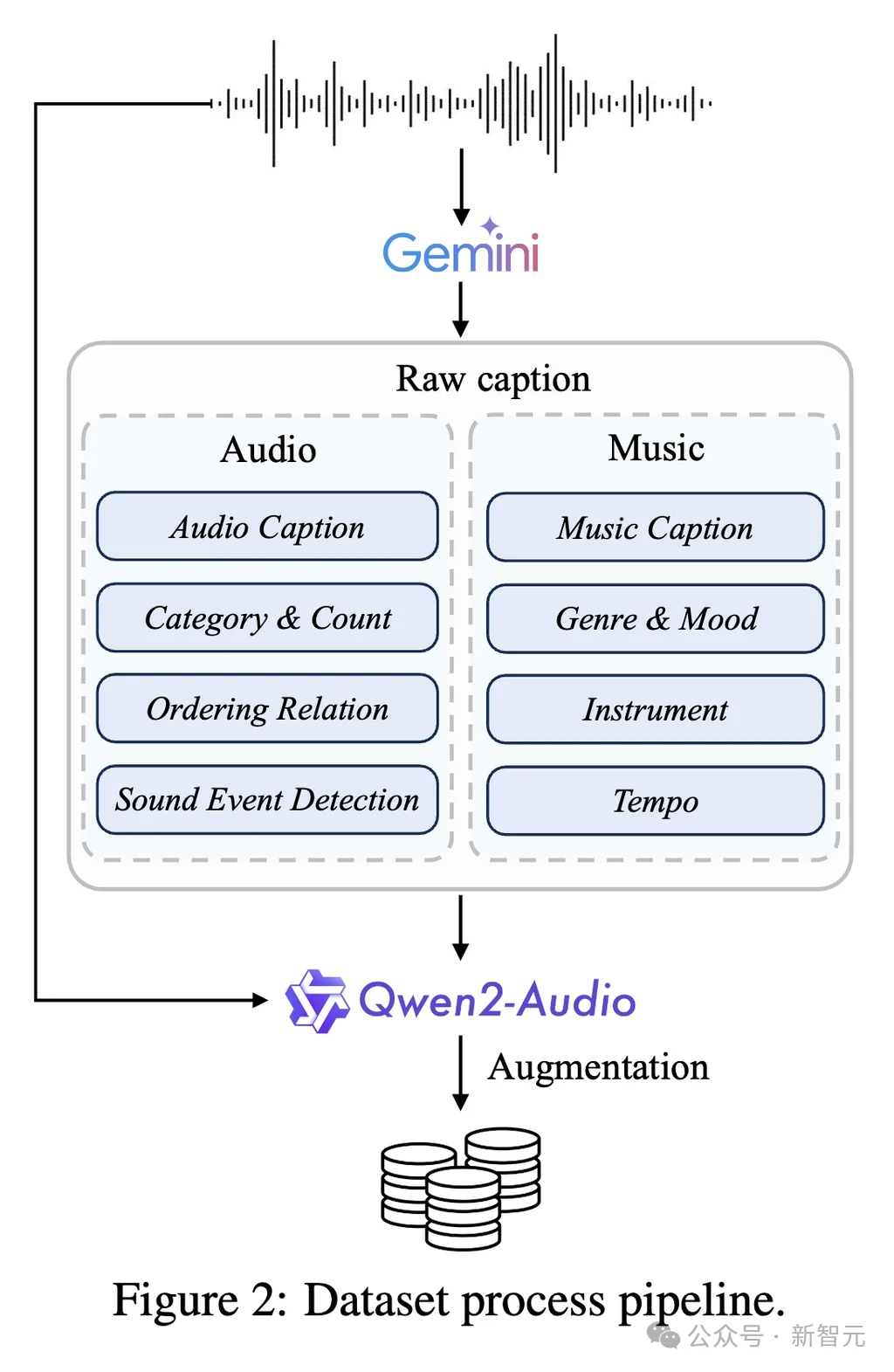
数据处理流水线图
第一阶段:使用Gemini 2.5 Pro对每段10秒视频-音频片段的音频轨道进行精细化分析,生成一套全面的结构化标注。对于音效数据,标注包括全局描述、声音事件分类与计数、事件时间戳(SED)、事件时序关系等;对于音乐数据,则包括曲风、情绪、乐器、节奏等属性。
第二阶段:考虑到标注成本和数据多样性,团队利用开源的Qwen2-Audio模型,基于第一阶段的结构化标注进行大规模数据增强。通过改写原始描述、基于类别与计数生成新描述、基于时间戳生成新描述、基于时序关系生成新描述等多种角度,为同一段音频生成语义一致但风格多样的文本描述,大幅提升了训练数据的多样性和模型对不同用户输入的鲁棒性。
最终,IF-caps包含约130万条音效数据和570万条音乐数据,总计超过700万样本。

在消融实验中,团队发现了一个重要且有趣的现象——跨模态正则化效应(Cross-modal Regularization Effect)。
直觉上,提升文本标注的质量应当主要改善文本到音频(T2A)的性能。然而实验结果表明,更高质量的文本监督信号不仅显著提升了T2A任务的表现,还同步带动了视频到音频(V2A)等其他任务的性能提升。
这个发现说明:在统一训练框架下,高质量的文本数据充当了一种隐式正则化信号,增强了模型共享的多模态表示空间。文本数据提供的精细语义结构(事件类别、数量、时序等)帮助模型建立了更好的内部表征,而这些表征对所有条件模态(包括视频)都是共享的,从而带动了整体性能的提升。
这一发现对未来的多模态生成研究具有重要的启示意义:高质量的文本数据不仅仅是一种输入条件,更是构建强大、鲁棒的多模态模型的有效策略。
田泽越:第一作者,现为香港科技大学(HKUST)跨学科学院三年级博士生,师从郭毅可教授。其主要研究方向为多模态音频音乐生成。
郭毅可:通讯作者,中国工程院外籍院士,现任香港科技大学首席副校长、计算机科学及工程学系讲座教授。
雪巍:通讯作者,香港科技大学艺术与机器创造力学部、新兴跨学科领域学部助理教授,其主要研究方向为智能语音、音频以及音乐的感知与生成。
参考资料:
https://arxiv.org/pdf/2503.10522
文章来自于“新智元”,作者 “LRST”。



