# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大语言模型 Agent 开始在对话、问答与复杂交互环境中长期运行,“记忆该如何设计” 正在成为一个绕不开的核心问题。

来自 UIUC、清华大学与微软研究院的研究团队,近日提出了一种面向 LLM Agent 的任务无关记忆模块 PlugMem。该工作试图回答一个在 Agent 研究中反复出现、却始终没有统一答案的问题:
Agent 的长期记忆,究竟该 “存什么”,才能真正帮助它在不同任务中做出更好的决策?
在当前主流设计中,大多数 Agent 的记忆仍停留在 “存经历、再检索” 的范式:
要么把对话、轨迹、网页观察等原始内容直接存下来,要么在此基础上做简单压缩或检索增强(如 RAG、GraphRAG)。
问题在于,这类方法在任务切换时往往失效:
一个在长对话中表现良好的记忆机制,放到 Web Agent 或多跳问答中,几乎无法直接复用。
作者在论文中给出了一个极具代表性的隐含例子:
但当 Agent 面临一个新任务时(比如推荐菜谱,或在陌生电商页面购物):
真正对决策有帮助的,其实只是两类高度抽象的信息:
但这些信息,往往并不存在于任何一条原始记忆中,而是分散在大量经历里。
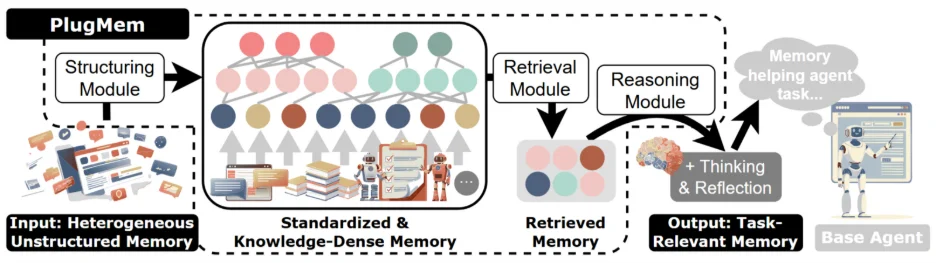
基于这一观察,PlugMem 提出了一种与主流 Agent 记忆设计明显不同的思路:
记忆的基本单位,不应是 “文本” 或 “轨迹”,而应是 “可决策的知识”。
具体来说,系统将 Agent 的长期记忆明确拆分为三类:
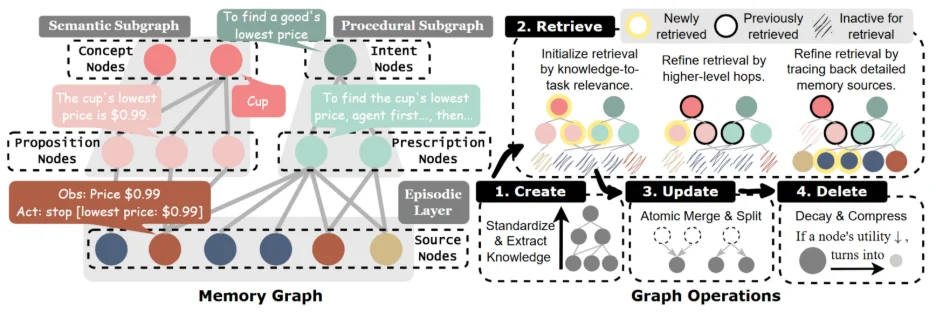
与 GraphRAG 等方法不同,PlugMem 构建的并不是 “实体图” 或 “文本图”, 而是一个以命题(proposition)和处方(prescription)为节点的知识中心记忆图。
换句话说,Agent 检索的不是 “我曾经做过什么”,而是 “我已经学会了什么”。
论文中一个很有说服力的点在于:
PlugMem 在 不做任何任务特化修改 的情况下,被直接用于三类差异极大的任务:
在每种任务中,系统会动态判断当前更需要哪一类记忆:
而检索与推理始终围绕知识级节点展开,而不是原始文本。
PlugMem 的实验设计,围绕三个明确的问题展开。这三个问题,分别对应 Agent 记忆系统中最关键、也最容易被混用的三个层面:通用性、因果结构,以及可迁移性。
第一个问题关注的是 PlugMem 的适用范围。
作者将同一个 PlugMem 实现,直接用于三类结构差异极大的任务:
这些任务对记忆的需求并不相同:
有的依赖对过往事实的回忆,有的依赖知识之间的关联,有的则依赖对行动策略的复用。
实验结果显示,在三类任务中,PlugMem 都能够在提升任务表现的同时,显著降低 Agent 侧所消耗的记忆 token 数量。这表明,将记忆表示为知识级单元,有助于在不同任务中稳定提升单位记忆的决策价值。
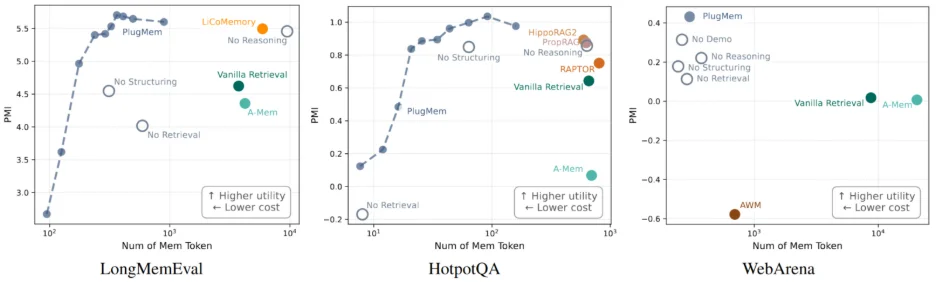
这一结果为后续分析提供了基础前提:记忆的组织方式,会系统性地影响其在不同任务中的有效性。
在进一步分析之前,作者引入了一个统一的评估视角,用于衡量记忆系统在不同任务中的性价比。
具体而言,论文将记忆的作用表述为:在给定状态下,记忆对 Agent 正确决策概率所带来的信息增益,并将这一增益归一化到所使用的记忆 token 数量上。由此得到的 “信息密度” 指标,使得不同任务、不同记忆设计可以在同一尺度下进行比较。
这一评估框架,为后续的消融分析和跨任务比较提供了统一坐标系。
第二个问题关注的是 PlugMem 内部各组件的作用分工。
作者通过系统性的消融实验,分别移除结构化模块、检索模块和推理模块,观察性能与记忆消耗的变化。实验结果呈现出清晰的分工关系:
当检索被移除后,记忆几乎无法在决策中发挥作用。
在缺少结构化的情况下,系统更容易检索到冗余、粒度不合适的原始信息,从而限制性能提升空间。
移除推理模块后,性能变化相对有限,但记忆 token 消耗显著增加,表明其主要作用在于压缩与整合。
这组实验明确区分了三个常被混为一谈的概念:
检索让记忆 “可达”,结构化让记忆 “可用”,推理让记忆 “省着用”。
第三个问题关注的是记忆的可迁移性。
在 WebArena 中,作者将任务划分为 online 与 offline 两个阶段:
Agent 只允许在 online 阶段写入记忆,而 offline 阶段则在基本冻结记忆的情况下进行评估。
这一设置刻意避免了通过重复试错积累熟练度的可能性,重点考察已有记忆是否能够支持新任务中的决策。
实验结果表明,即使在 offline 阶段,PlugMem 仍能显著提升任务成功率,尤其是在涉及多站点组合操作的任务中。这表明系统中存储的程序性与语义知识,能够被新的 Agent 实例直接复用,而不依赖于具体的交互轨迹。
通过这三组问题,实验逐步澄清了 PlugMem 所刻画的 Agent 记忆形态:
在这一意义上,PlugMem 的实验不仅验证了方法本身,也为理解 Agent 长期记忆的设计与评估提供了一组清晰的分析视角。
总体来看,PlugMem 从记忆的基本单位、组织方式与评估视角三个层面,系统性地重审了 Agent 长期记忆这一问题。通过将经历抽象为可复用的语义与程序性知识,并在多类任务中进行统一评估,作者展示了一种更接近 “经验继承” 而非 “历史回放” 的 Agent 记忆形态。这一思路,也为后续构建可迁移、可积累经验的通用 Agent 提供了新的设计基线。
作者简介:
杨可,清华大学本科、UIUC计算机三年级博士生,主要研究AI agents、语言模型、信息检索与算法审计。本项目由其承担领导与主要写作工作,为排序第一作者,并与陈子曦、何宣、蒋积泽共同作为共同第一作者。该成果由UIUC、清华大学与微软研究院合作完成,并接受Michel Galley、汪成龙博士建议,得到高剑峰、韩家炜、翟成祥教授指导。
文章来自于“机器之心”,作者 “杨可”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
