# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌发布首个原生全模态 Embedding 模型 Gemini Embedding 2!它将文本、图、音视频及 PDF 无损融于统一向量空间,实现跨越五大模态的直接检索。这极大降低了架构成本,赋予了 AI 真正连贯的「记忆」,是重塑 AI 基建的里程碑。
如果说 ChatGPT 等生成式 AI 大模型是 AI 用来表达的「嘴」,那么 Embedding(嵌入)模型就是负责理解与检索的「记忆神经」。
长期以来,这条记忆神经处于割裂状态。
昨天,Gemini API 上线首个多模态 Embedding 模型预览版 gemini-embedding-2-preview。
作为首个原生全模态 Embedding 模型,它将文本、图像、音视频乃至 PDF 文档,悉数融合进了一个统一的向量空间。
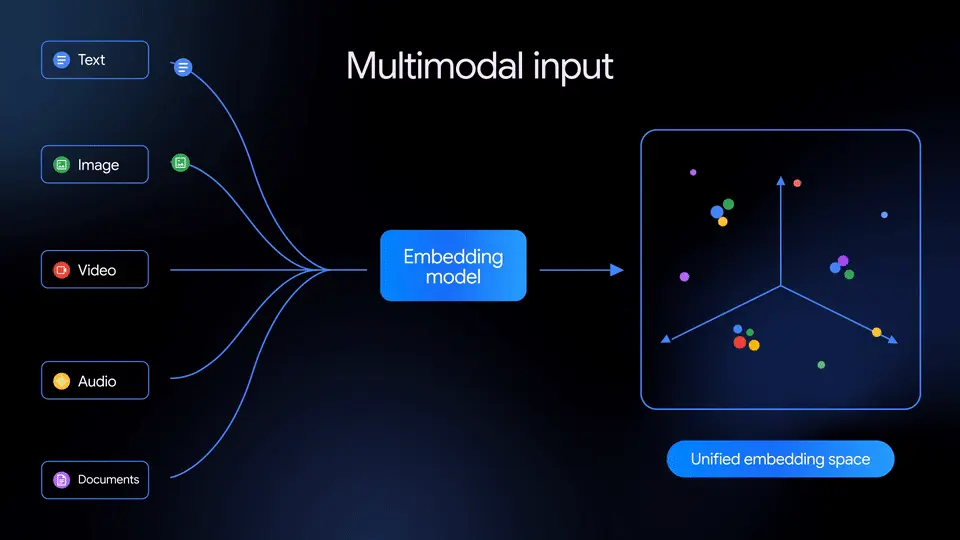
要真正理解这项技术的战略分量,我们需要看清过去 AI 检索系统面临的「数据巴别塔」困境。
以往,视觉模态、音频模态和文本处理模态仿佛说着截然不同的语言,每次调度全局信息都需要极其繁琐的翻译对齐。
Gemini Embedding 2 的出现,等同于在数据世界推行了一门通用语,其核心突破体现在以下几个维度。
斩断转录节点,消除信息损耗黑洞
「原生」二字的含金量在于拒绝任何形式的妥协与翻译。
早期让 AI 「听懂」播客,必须外挂语音识别模型先转成纯文本,导致说话人略带反讽的语调、背景里刺耳的警笛声等「冗余信息」瞬间灰飞烟灭。
如今,模型直接「生吞」 MP3 音轨的波形与高分辨率图片的原始像素,那些只可意会不可言传的感官细节,终于在数学空间里找到了精确的坐标。
打通统一坐标系,解锁跨物种搜索
当五大数据类型被压缩进同一个高维向量空间,数据的边界被彻底消解。
开发者能够轻易实现极其复杂的跨模态检索:
抛入一段发动机异响的录音,系统会瞬间从海量的 PDF 维修手册中精准定位到故障部件的图纸;
上传一张极具后现代风格的建筑照片,系统能直接召回配乐风格极其相似的影视片段。
检索完全进化成了纯粹的「语义和意图共振」。
架构大简化,工程复杂度断崖式下跌
过去拼凑一个多模态检索应用,工程师简直要经历一场噩梦。
维护多个独立模型、花重金购买隔离的向量数据库、再编写极度复杂的重排算法试图强行对齐各类得分,这种草台班子式的架构不仅延迟极高,且极易崩溃。
现在,这堆乱如麻的基建被浓缩成一次简单的 API 调用,一套模型足以打穿整个业务流。
已经提前尝鲜的 Agent 创业者们,也毫不吝啬自己对这个全模态新模型的赞美。

为 Agent 拼上完整的记忆拼图
Agent 往往容易显得迟钝,根本原因就在于其「记忆」是割裂的。
Agent 看完带有大量数据图表的研报后,往往只记住了文字,图表部分则被抛弃。
原生全模态 Embedding 赋予了 AI 一种连贯的底层认知模式,让机器终于能像人类一样,将听到的风声、看到的画面和读过的段落,无缝融合成一段完整的记忆。
「五合一」引擎与降本魔法
新模型不仅包揽了五大数据类型,更拥有极宽的吞吐边界!
在秀肌肉的同时,谷歌也替企业算好了一笔经济账。
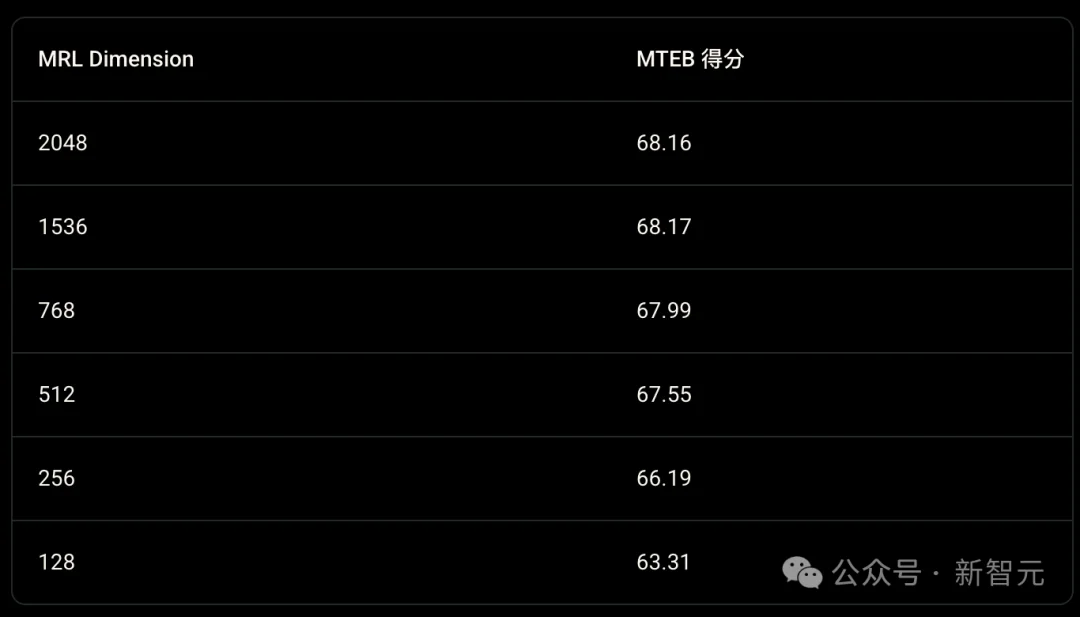
Gemini Embedding 2 沿用了巧妙的「俄罗斯套娃」表示学习技术(MRL)。
这项技术允许开发者像拆解套娃一样,根据自身的存储预算灵活「折叠」向量的体积。
在默认的 3072 维满血状态下,模型自然能提供极致的检索基准。
https://ai.google.dev/gemini-api/docs/embeddings?hl=zh-cn
但真正让人惊艳的是它向下压缩时的韧性:当维度被对半砍到 1536 维时,其 MTEB 多语言性能得分依然坚挺在 68.17 分,甚至出现了一个反直觉的现象——这个分数比 2048 维还要略高一丝。
即便你把预算压缩到极致,将向量体积暴减 75% 降至 768 维,其跑分也仅仅微跌了 0.18 分(67.99 分)。
这意味着,开发团队完全可以在几乎不牺牲核心检索质量的前提下,大幅度削减存储与计算开销,用极高的性价比撬动顶级的多模态能力。
环顾四周,这条赛道的火药味从未如此浓烈。
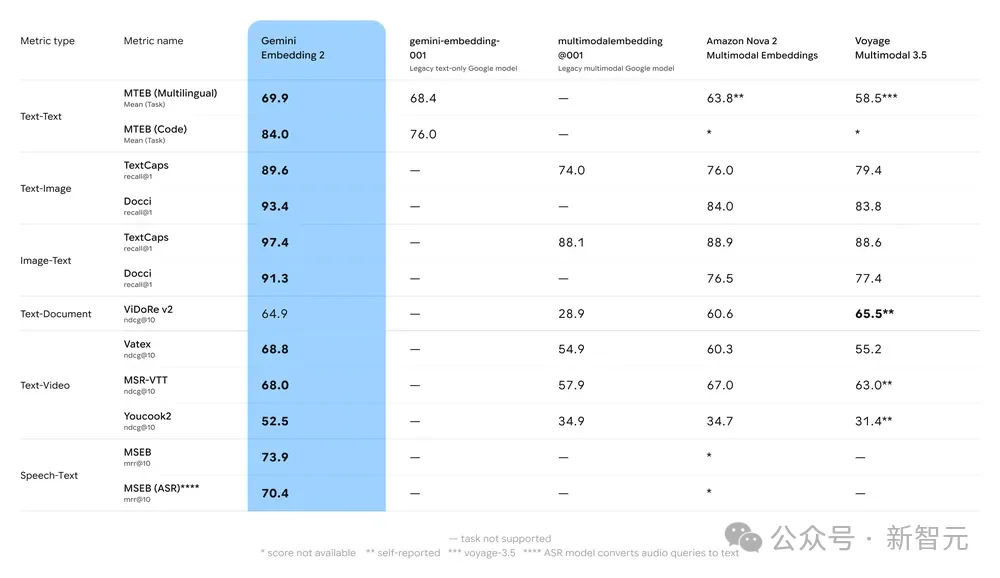
OpenAI 的 text-embedding-3 依然死死守在纯文本阵地,视觉方面全靠旧版模型支撑;
老牌玩家 Cohere 的 Embed v4 遗漏了音视频两块关键拼图;
开源阵营中最能打的 Jina v4 拿下了图文与 PDF,同样对声音和动态影像无能为力。
Gemini Embedding 2 恰好填补了市场空白,成为当下唯一覆盖五大模态的商用级全能选手,实现了全模态 SOTA!
对于准备尝鲜的工程团队而言,有几个现实的「坑」必须提前规避:
当孤立的数据孤岛被彻底贯通,庞杂的现实世界才得以在代码的深海中投下清晰的倒影。
最深远的智能革命,往往藏在那些不动声色的基础设施里,悄然将万物重塑为同一种语言。
现在,可以通过 Gemini API 或 Vertex AI 开始使用 Gemini Embedding 2 模型,参考调用方式如下:
from google import genai
from google.genai import types
# For Vertex AI:
# PROJECT_ID='<add_here>'
# client = genai.Client(vertexai=True, project=PROJECT_ID, location='us-central1')
client = genai.Client()
with open("example.png", "rb") as f:
image_bytes = f.read()
with open("sample.mp3", "rb") as f:
audio_bytes = f.read()
# Embed text, image, and audio
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"What is the meaning of life?",
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png",
),
types.Part.from_bytes(
data=audio_bytes,
mime_type="audio/mpeg",
),
],
)
print(result.embeddings)
参考资料:
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embed
文章来自于“新智元”,作者 “艾伦”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
