# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
PS:先提前预告下,这个项目解决不了不赚钱的问题,但能帮助减少冲动交易,解决信息搜集、分析效率低问题。当然,也有同事吐槽,这是个韭菜RL,大家有选择地参考与批判一下就好。
一边上班一边炒股,估计是不少人的常态。
但最近的波动行情里,实在要被盯盘这件事搞疯了。
一方面,开会盯盘挺不礼貌的;另一方面,每次决策背后,需要刷新闻、扒研报、看盘面,一套流程下来,每周至少要耗费十几个小时在搜集信息上,效率实在太低。
而我自己呢,也的确算不上什么交易高手。不盯盘则已,一盯盘就容易冲动交易,一周雷霆出手七八回。经常是,别人贪婪我更贪,别人恐慌我跟跑。

往往一年下来,学费没少交,时间没少花,钱也没少亏。
所以,就想着结合最近爆火的Openclaw,以及公司的Milvus数据库做个产品。
这里我没有让AI帮我做决策,更没有让它碰交易本身(风险太大了),主要就是让AI按照我的要求搜集信息、做市场分析、盯盘、打捞我的历史交易数据,然后推送在飞书。
从而解决信息搜集效率低,盲区大;以及冲动交易多,复盘成本高、开会不好盯盘的痛点。

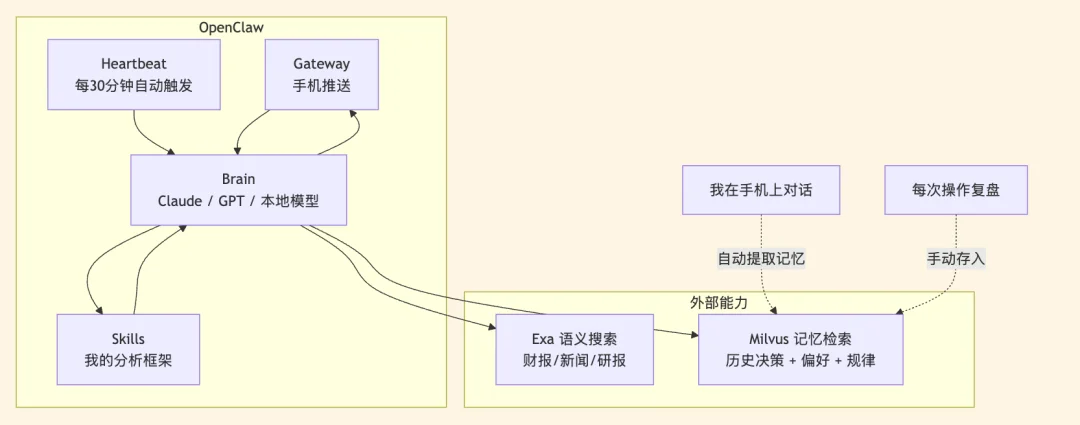
这个agent整体架构不算复杂,主要三个模块,每月成本共计 20 美元左右:
OpenClaw作为决策中枢大脑(10美金)
Exa用于联网做高质量的信息检索(10美金)
Milvus存历史交易信息用于复盘(本地部署、免费)。
以下是整体搭建指南。
投资的第一步就是搞信息,我之前试过硬刷财经 App,但里面会有大量的不相关信息,淹没了我真正关心的内容;也试过写爬虫,但财经网站反爬机制天天更新,维护成本太高。至于一些专业的数据分析软件,API成本太高了,对普通投资者不适用。
所以最后我用了 Exa,它是专门给 AI Agent 设计的互联网搜索(WebSearch) API,跟普通搜索引擎比,它对AI的适配性高了很多,还引入了额外的语义搜索。

比如我想知道 “英伟达 2026 年 Q4 财报超预期为啥股价跌了”,它直接就能理解,还能每分钟刷新索引,自动过滤那些 SEO 垃圾营销文,搜美股的时候再也不用在一堆没用的内容里扒拉了。
当然,更重要的是,Exa 有免费额度,每月 1000 次搜索,初期试用完全够,后续按使用频率续费就行,成本也低。
以下是我的核心的调用代码,如有需要,改改参数,先装包pip install exa-py,再把 api-key 换成自己的就行:
from exa_py import Exa
exa = Exa(api_key="your-api-key")
# Semantic search — describe what you want in plain language
result = exa.search(
"Why did NVIDIA stock drop despite strong Q4 2026 earnings",
type="neural", # semantic search, not keyword
num_results=10,
start_published_date="2026-02-25", # only search for latest information
contents={
"text": {"max_characters": 3000}, # get full article text
"highlights": {"num_sentences": 3}, # key sentences
"summary": {"query": "What caused the stock drop?"} # AI summary
}
)
for r in result.results:
print(f"[{r.published_date}] {r.title}")
print(f" Summary: {r.summary}")
print(f" URL: {r.url}\n")
这里比较值得注意的是 contents 这个参数,它不只能返回链接,还能直接把文章正文抽出来、提取关键句、生成摘要,免去了一篇篇点开看的时间浪费。
另外,在这里分享几个我用的比较多的搜索模式。
第一个是,按类型过滤。比如我只想看彭博、路透这些权威来源的财报分析,不想看营销号的二手信息,加一个 category 就行:
# Only financial reports from trusted sources
earnings = exa.search(
"NVIDIA Q4 2026 earnings analysis",
category="financial report",
num_results=5,
include_domains=["reuters.com", "bloomberg.com", "wsj.com"],
contents={"highlights": True}
)
第二个是相似文章检索。看到一篇不错的分析,想找更多类似观点的文章,用 find_similar,给它一个URL,它会找到内容相似的其他文章:
# "Show me more analysis like this one"
similar = exa.find_similar(
url="https://fortune.com/2026/02/25/nvidia-nvda-earnings-q4-results",
num_results=10,
start_published_date="2026-02-20",
contents={"text": {"max_characters": 2000}}
)
第三个是深度搜索。碰到复杂问题,比如中东局势对半导体供应链的影响,普通搜索结果太散,用 type="deep" 让它综合多方面信息,还能按你要的结构返回摘要:
# Complex question — needs multi-source synthesis
deep_result = exa.search(
"How will Middle East tensions affect global tech supply chain and semiconductor stocks",
type="deep",
num_results=8,
contents={
"summary": {
"query": "Extract: 1) supply chain risk 2) stock impact 3) timeline"
}
}
)
第四个是实时新闻监控。限定下发布时间,就能只搜当天的美股新闻:
# Breaking news only — today' iss date 2026-03-05
breaking = exa.search(
"US stock market breaking news today",
category="news",
num_results=20,
start_published_date="2026-03-05",
contents={"highlights": {"num_sentences": 2}}
)
我做了十几个搜索模板,覆盖了日常关注的所有方向:美联储政策、科技股财报、中东局势对油价的影响、宏观流动性指标变化……每天早上自动跑一遍,结果就能推到我手机上。
以前可能每天找全这些信息需要耗费一两个小时,现在早上起床看5分钟摘要,就已经能浏览完所有重要信息。
除了光知道外面发生了什么之外,普通投资者最需要的,是避免记吃不记打。
比如什么时候追高为Meta的元宇宙梦想买过单,什么时候卖飞了因为openclaw爆发的苹果。
历史教训很多,但一个礼拜出手七八回之后,就经常忘了自己都怎么亏过钱。所以,我把自己之前做对了什么、做错了什么、有什么偏好和盲区,全部存在了Milvus向量数据库里。
(当然,也有同事说,这是个韭菜RL,但多复盘多总结总归是没错的)
不过这里值得多提一嘴的是,一定要区分长期记忆、短期记忆、狭义知识库。
比如,我的选股偏好,投资理念,这些是长期记忆,需要每次喂给模型;具体操作方式是把以前和Agent的对话、经验总结存下来,让AI知道我是谁、我做过什么、我容易犯什么错。(这里最好直接MD格式存储,透明化的展示到底学了什么、记了什么)
那些亏钱小操作,则应该归属知识库的范畴,在遇到类似的情况的时候,再被检索出来,用来提醒。
产品文档、研报、FAQ 这类参考材料,是客观外部知识,所以也属于狭义知识库概念在需要的时候被唤起。
我自己搭的这套系统,主要做的是前两个,研报、招股书这些,都可以公开检索到,没必要放在数据库中。
具体选型上,我选了Milvus Lite ,可以本地部署,不用搭服务器就能直接跑。然后把自己需要的专属信息,分了三个库存储,建库代码贴在这里了,维度 1536 是和OpenAI的embedding模型匹配的,直接用就行:
from pymilvus import MilvusClient, DataType
from openai import OpenAI
milvus = MilvusClient("./my_investment_brain.db")
llm = OpenAI()
def embed(text: str) -> list[float]:
return llm.embeddings.create(
input=text, model="text-embedding-3-small"
).data[0].embedding
# Collection 1: past decisions and lessons
# Every trade I make, I write a short review afterward
milvus.create_collection(
"decisions",
dimension=1536,
auto_id=True
)
# Collection 2: my preferences and biases
# Things like "I tend to hold tech stocks too long"
milvus.create_collection(
"preferences",
dimension=1536,
auto_id=True
)
# Collection 3: market patterns I've observed
# "When VIX > 30 and Fed is dovish, buy the dip usually works"
milvus.create_collection(
"patterns",
dimension=1536,
auto_id=True
)
建库之后,另一个比较棘手的问题是,怎么让AI知道什么该记住,或者什么时候该检索了。
这里我写了个简单的 “记忆提取器”,每次跟 AI 聊完天自动运行,不管是我说 “这轮 AI 行情像 2000 年互联网泡沫”,还是复盘某次交易的错误,系统都会自动把这些有价值的洞察,决策记录、个人偏好、市场规律、经验教训提取出来,分门别类存进Milvus,还会自动查重,避免存重复(相似度超过0.92)的内容,核心代码如下,挂在对话结束后就行,不用改太多:
import json
def extract_and_store_memories(conversation: list[dict]) -> int:
"""
After each chat session, extract personal insights
and store them in Milvus automatically.
"""
# Ask LLM to extract structured memories from conversation
extraction_prompt = """
Analyze this conversation and extract any personal investment insights.
Look for:
1. DECISIONS: specific buy/sell actions and reasoning
2. PREFERENCES: risk tolerance, sector biases, holding patterns
3. PATTERNS: market observations, correlations the user noticed
4. LESSONS: things the user learned or mistakes they reflected on
Return a JSON array. Each item has:
- "type": one of "decision", "preference", "pattern", "lesson"
- "content": the insight in 2-3 sentences
- "confidence": how explicitly the user stated this (high/medium/low)
Only extract what the user clearly expressed. Do not infer or guess.
If nothing relevant, return an empty array.
"""
response = llm.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": extraction_prompt},
*conversation
],
response_format={"type": "json_object"}
)
memories = json.loads(response.choices[0].message.content)
stored = 0
for mem in memories.get("items", []):
if mem["confidence"] == "low":
continue # skip uncertain inferences
collection = {
"decision": "decisions",
"lesson": "decisions",
"preference": "preferences",
"pattern": "patterns"
}.get(mem["type"], "decisions")
# Check for duplicates — don't store the same insight twice
existing = milvus.search(
collection,
data=[embed(mem["content"])],
limit=1,
output_fields=["text"]
)
if existing[0] and existing[0][0]["distance"] > 0.92:
continue # too similar to existing memory, skip
milvus.insert(collection, [{
"vector": embed(mem["content"]),
"text": mem["content"],
"type": mem["type"],
"source": "chat_extraction",
"date": "2026-03-05"
}])
stored += 1
return stored
这样做的好处是,我和AI聊天的时候根本不用刻意记笔记。聊完了,系统就会自动把有价值的东西存下来。时间一长,它对我的了解会越来越深。
到了下次想要冲动交易的时候,我就先做一下检索,写个检索函数,把当前市场场景输进去,就能调出对应的历史经验(至于是要强化自己的经验,还是把历史操作作为反面案例反思,大家根据自己实力量力而行)。
def recall_my_experience(situation: str) -> dict:
"""
Given a current market situation, retrieve my relevant
past experiences, preferences, and observed patterns.
"""
query_vec = embed(situation)
# Search all three collections in parallel
past_decisions = milvus.search(
"decisions", data=[query_vec], limit=3,
output_fields=["text", "date", "tag"]
)
my_preferences = milvus.search(
"preferences", data=[query_vec], limit=2,
output_fields=["text", "type"]
)
my_patterns = milvus.search(
"patterns", data=[query_vec], limit=2,
output_fields=["text"]
)
return {
"past_decisions": [h["entity"] for h in past_decisions[0]],
"preferences": [h["entity"] for h in my_preferences[0]],
"patterns": [h["entity"] for h in my_patterns[0]]
}
# When Agent analyzes current tech selloff:
context = recall_my_experience(
"tech stocks dropping 3-4% due to Middle East tensions, March 2026"
)
# context now contains:
# - My 2024-10 lesson about not panic-selling during ME crisis
# - My preference: "I tend to overweight geopolitical risk"
# - My pattern: "tech selloffs from geopolitics recover in 1-3 weeks"
信息有了,记忆有了,最后还缺一个东西:分析逻辑。
如果只是把新闻和记忆丢给AI说帮我分析一下,大概率它会给你一篇四平八稳的通用分析,什么角度都提一嘴,什么结论都不敢下。这种东西对决策没用。
所以,我需要的是它按照我的标准来分析。哪些指标我看重,哪些情况我认为是危险信号,什么时候该保守什么时候该激进。这些规则每个人不一样,得自己定义。
OpenClaw的Skills机制刚好干这个事。你可以在Agent的工作目录下放一个markdown文件,把遇到什么情况该怎么做写清楚。Agent收到相关消息的时候会自动调用它。
这是我写的财报后操作判断 Skill,大家可以根据自己的实际需求自行修改:
---
name: post-earnings-eval
description: >
Evaluate whether to buy, hold, or sell after an earnings report.
Trigger when discussing any stock's post-earnings price action,
or when a watchlist stock reports earnings.
---
## Post-Earnings Evaluation Framework
When analyzing a stock after earnings release:
### Step 1: Get the facts
Use Exa to search for:
- Actual vs expected: revenue, EPS, forward guidance
- Analyst reactions from top-tier sources
- Options market implied move vs actual move
### Step 2: Check my history
Use Milvus recall to find:
- Have I traded this stock after earnings before?
- What did I get right or wrong last time?
- Do I have a known bias about this sector?
### Step 3: Apply my rules
- If revenue beat > 5% AND guidance raised → lean BUY
- If stock drops > 5% on a beat → likely sentiment/macro driven
- Check: is the drop about THIS company or the whole market?
- Check my history: did I overreact to similar drops before?
- If P/E > 2x sector average after beat → caution, priced for perfection
### Step 4: Output format
Signal: BUY / HOLD / SELL / WAIT
Confidence: High / Medium / Low
Reasoning: 3 bullets max
Past mistake reminder: what I got wrong in similar situations
IMPORTANT: Always surface my past mistakes. I have a tendency to
let fear override data. If my Milvus history shows I regretted
selling after a dip, say so explicitly.
写完之后,把这段内容丢到 OpenClaw 工作目录的 skills/ 文件夹下就行。以后每次我跟 Agent 聊到某只股票的财报表现,它就会自动按这个框架来分析。
最后那行是关键,「我有被恐惧驱动的倾向,如果历史记录显示我曾后悔过在下跌时卖出,请明确告诉我」。一个给自己量身定做的纠偏机制。
类似的skill还有很多,我会针对情绪面、宏观面、资金面全都写一个简单的分析skill,然后把Binance 的K线、推特的kol言论也做一个搜集总结。
此外,我还把自己喜欢的投资大师的风格,写成了skill,模拟类似的情况,他们会怎么决策,作为我自己的决策参考之一。目前市场上已经有很多公开的巴菲特模拟skills、桥水风格模拟skill是,大家可以直接按需写入。
此外,需要注意一点,我们比较关注RSI、MACD这些指标,千万别交给AI去算,直接无脑调用,或者自己写函数,大模型在这方面经常会出现bug。
当然,做完以上这些还不够,如果所有操作都得我手动触发,那跟自己刷新闻也没啥区别。
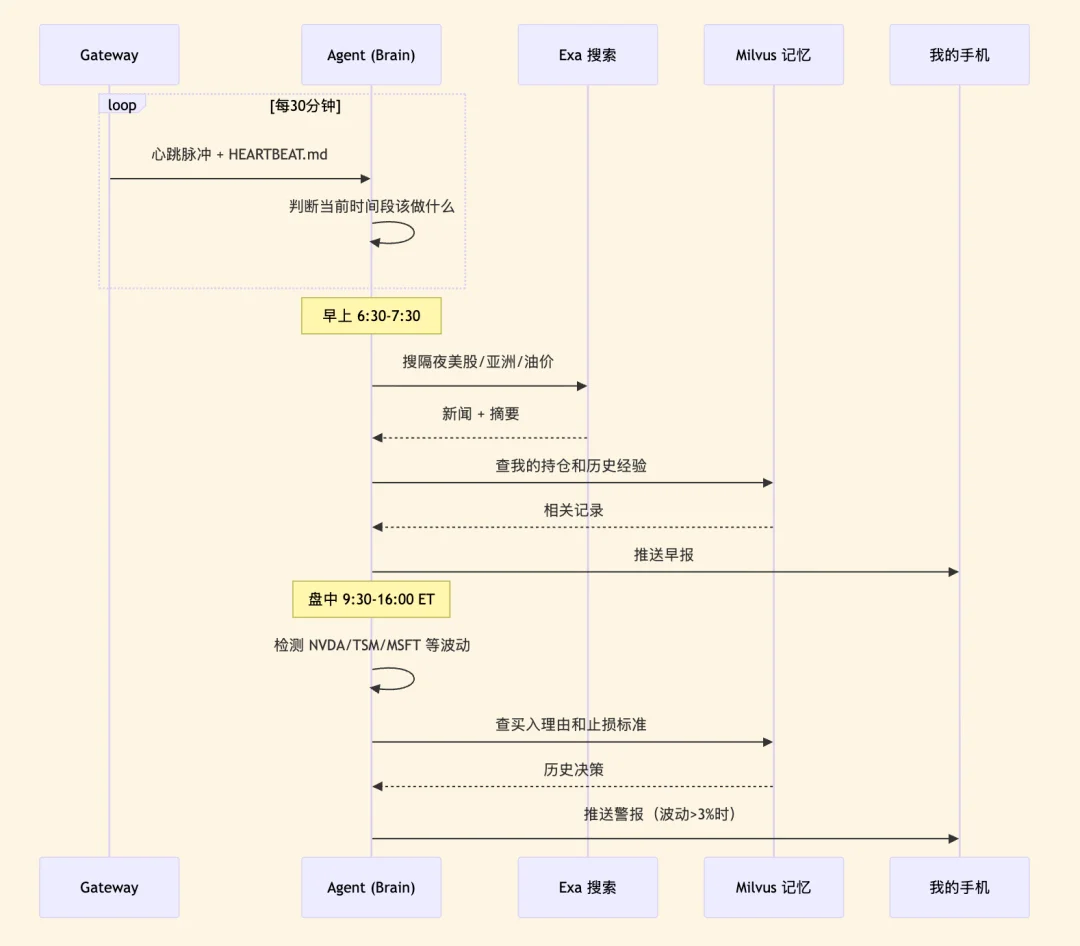
所以,这里我重点使用了OpenClaw 的Heartbeat 机制。Gateway 会每隔 N 分钟(默认30分钟)会自动触发一次,然后Agent会 根据你写的HEARTBEAT.md来决定什么时候该做什么,最后把结果直接推到手机上。
同样的,这里你也不用写定时任务代码,只需要写一个 markdown 文件:
# HEARTBEAT.md — runs every 30 minutes automatically
## Morning brief (6:30-7:30 AM only)
- Use Exa to search overnight US market news, Asian markets, oil prices
- Search Milvus for my current positions and relevant past experiences
- Generate a personalized morning brief (under 500 words)
- Flag anything related to my past mistakes or current holdings
- End with 1-3 action items
- Send the brief to my phone
## Price alerts (during US market hours 9:30 AM - 4:00 PM ET)
- Check price changes for: NVDA, TSM, MSFT, AAPL, GOOGL
- If any stock moved more than 3% since last check:
- Search Milvus for: why I hold this stock, my exit criteria
- Generate alert with context and recommendation
- Send alert to my phone
## End of day summary (after 4:30 PM ET on weekdays)
- Summarize today's market action for my watchlist
- Compare actual moves with my morning expectations
- Note any new patterns worth remembering
目前整个系统流程跑起来是这样的:
每日固定早报,每天早上7点左右自动执行。用 Exa 搜隔夜全球市场动态,从 Milvus 里捞出我的持仓情况和相关历史经验,喂给大模型生成一份定制化的简报,推送到手机上,告诉我隔夜发生了什么、跟我的持仓有没有关系。然后我趁着刷牙和开车时间,整体听一遍。
盘中警报,美股交易时间每30分钟巡检一次。如果关注的股票波动超过3%,立刻推一条消息,附带你当初为什么买的、现在是不是到了你设定的止损止盈点。
周度周报复盘。作为一个价值投资者,为了避免被市场情绪干扰,有时候我会刻意不盯盘,然后让Agent 生成周报,周末花半小时看一下就好。
之前每周完成以上动作,需要至少花十几个小时,现在能压缩到两小时左右,完全不影响上班。而且整体的信息覆盖变得更全面、质量更高。
配合上历史操作复盘,我整体的冲动交易的次数少了很多,摩擦成本随之大大降低。
而整体成本,也只有一开始说的10美金大模型成本,和10美金Exa成本,还有一点电脑开机的电费。
回想一下,要是一年前要搭同样的东西,得自己写一堆胶水代码,定时任务、消息推送、记忆管理全得从零来。
现在用 OpenClaw ,只要给它一套规则、一个记忆库、一个时间表,它就能自己去跑,跑完了把结果推给你,整个过程,被极大地简化了。
不过搭这个框架,我也还是花了两个周末,时间主要是用来梳理自己的判断标准,写skill了。
所以,本质上,这不算一个可以帮你赚钱的工具,只是把过去需要费大功夫做的信息搜集、历史数据回顾,变得更简单、更自动化了。
但换个思路,如果把这个框架换一套 Skill 和数据源,就可以从盯盘agent,编程盯论文、盯竞品、盯舆情、盯供应链的agent。
欢迎大家做更多的尝试与探索,在评论区与我们多多分享,工程师会24小时为您答疑解惑。

张晨
Zilliz Algorithm Engineer
文章来自于“Zilliz”,作者 “张晨”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
