# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
我们在很多地方都看到了一个词,叫「压缩即智能」
第一次碰到这个词的时候,很多人会愣一下。压缩?压缩怎么就智能了?zip 文件很智能吗?后来读到刘慈欣的《诗云》,突然就通了
故事的背景是,一个技术远超人类的外星神级文明来到地球。人类在它面前毫无还手之力,科技、军事、能源,全面碾压
但有一个人类诗人对它说:你写不出超越李白的诗
这个文明不服。它决定用自己的方式解决这个问题:穷举。把所有汉字的所有可能排列组合,全部生成出来,存进一团围绕恒星运行的巨大存储结构里。刘慈欣管它叫「诗云」

从数学的角度,这朵云里一定包含了超越李白的作品。所有可能的汉字排列都在里面,当然也包括最好的那几首
但这个文明做完之后,沉默了。因为它找不到那些诗。拥有一切可能的诗句,却没有办法判断哪些是好的
一个图书馆把世界上所有的书都收齐了。这不叫智能。一个人读完之后,用三页纸写清楚这些书的共同规律。这叫智能,区别在于:丢掉了什么
穷举不产生智能。压缩才产生智能
那压缩和智能之间的关系,到底是文学直觉,还是有数学支撑?
有。而且这条线索比大多数人想象的要长
1948 年,Claude Shannon 发表「A Mathematical Theory of Communication」,定义了信息熵:一条消息的信息量,等于编码它所需的最小比特数
最小。这两个字是整个信息论的地基
你能用 10 个 bit 无损表达原本需要 100 个 bit 的信息,说明你找到了 90% 的冗余结构。你理解了它
1960 年代,Solomonoff、Kolmogorov 和 Chaitin 从三个不同国家独立提出了算法信息论。Kolmogorov 复杂度:一个对象的复杂度 = 生成它的最短程序长度
最短的程序,能还原全部的信息

100 bits → 10 bits:找到冗余,就是理解
2006 年,Marcus Hutter 发起了一个 50 万欧元的竞赛:谁能更好地压缩维基百科的前 1GB,谁就更智能。他说,智能是一个模糊的概念,但文件大小是硬数字
Ilya Sutskever 说过,通过压缩实现无监督学习,是创立 OpenAI 的两个 founding ideas 之一
DeepMind 的论文「Language Modeling Is Compression」证明了语言建模和数据压缩在数学上等价。训练一个语言模型,就是在训练一个压缩器
从 Shannon 到 Kolmogorov 到 Hutter 到 Ilya,几十年,所有人到了同一个地方:
最小化描述长度,最大化预测能力
这就是「压缩即智能」的数学含义
不止数学。回头看整个科学史,「压缩即智能」一直在场
第谷花了二十多年记录天文观测数据,手稿好几米高。开普勒压缩成了三条定律
然后牛顿来了。F = ma 加上万有引力公式,两行字,把前面所有东西全部装进去了
麦克斯韦用四个方程压缩了整个电磁学。爱因斯坦用五个符号 E=mc² 压缩了质量和能量的关系
科学的进步史,就是压缩率的提升史
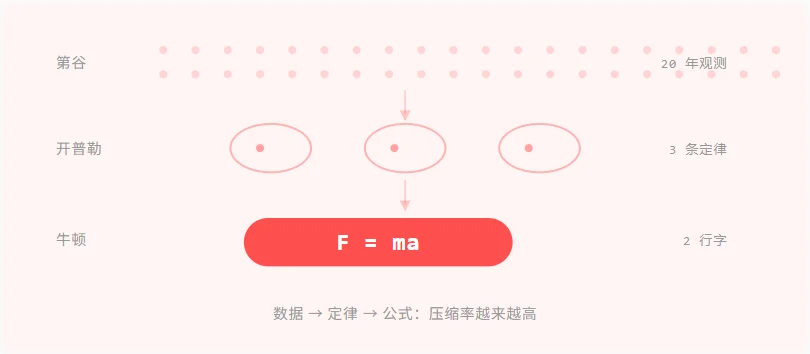
20 年观测 → 3 条定律 → 2 行字
每一次重大突破,都是用更少的符号解释更多的现象
物理学最底层的原理叫最小作用量原理。光走最短路径。物体沿作用量最小的轨迹运动。宇宙在每一个尺度上都偏好最经济的方案
压缩,即智能
说到数学结构,这里有一段有意思的历史
1928 年,冯·诺依曼证明了博弈论的基石定理:在零和博弈中,存在一个最优策略,使得最大可能损失被最小化
这个定理叫 Minimax 定理
找到所有最坏情况(max loss),然后在里面选最好的(min)。反过来也成立,在所有保守策略中找收益最高的(max min)
后来这个框架到处都是。Nash 均衡、Alpha-Beta 剪枝、对抗训练,都建立在它上面
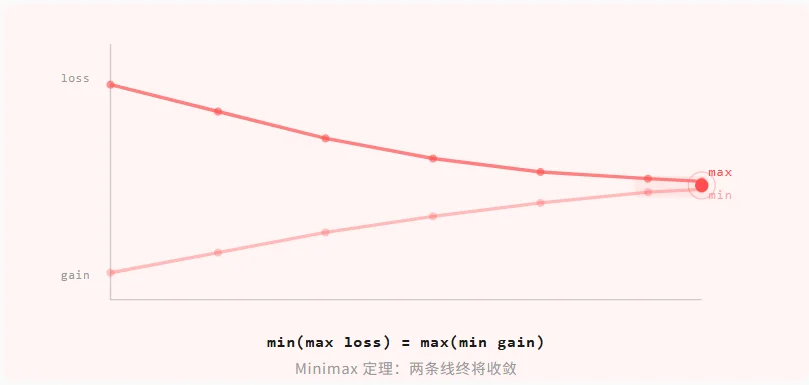
两条线终将收敛:这就是 Minimax
还有一件事比较有意思,可以把前面说的「压缩即智能」放进数学框架里看
Kolmogorov 复杂度:最短的程序,还原全部信息
min 描述长度,max 保真度
Shannon 最优编码:最少的比特数,无损传输全部信息
min 码长,max 保真
训练语言模型:找一组参数,使得在任何未知数据上的预测误差尽可能小
min loss,max generalization
这三个问题的数学结构是一样的。都是 Minimax
冯·诺依曼在 1928 年就把这个结构命名好了。只是当时没人在讨论 AI
「压缩即智能」在生物学里也有对应
人类婴儿出生时,大脑有大约 100 万亿 个突触连接。到成年,减少到 50 万亿
少了一半。这个过程叫突触修剪。大脑主动丢弃低效连接,保留最有用的路径。大脑在对自己做压缩
自闭症谱系的一种理论认为,部分患者的突触修剪不够充分。连接太多,信号互相干扰,无法提取清晰的模式
连接太多和信息太多,是同一类问题。诗云的困境,在生物学里也存在
人脑每秒接收大约 1100 万 bits 的感官信息,意识只能处理大约 50 bits。99.9995% 被丢弃了
意识,大概就是一个极其挑剔的压缩器
它的工作就是决定丢掉哪些信息
最后回到诗云,算一笔账
假设汉字 5000 个,一首七言绝句 28 个字。所有可能的排列组合是 5000²⁸,大约 10¹⁰³
可观测宇宙中的原子总数大约 10⁸⁰。诗云里的「诗」比宇宙里的原子还多
好诗大概率不超过几百万首。占比 10⁶ / 10¹⁰³ = 10⁻⁹⁷
随机抽样找好诗,在宇宙的整个生命周期里,一首都找不到
穷举的失败在于搜索空间太大。什么都不压缩,好的东西就被淹没了
而李白不在 10¹⁰³ 的空间里搜索。他对语言、情感、韵律、意象有一套高度压缩的理解,可以直接跳到好诗的邻域
他的脑子里装的是一个压缩过的生成模型

李白不穷举。他知道往哪里跳
大语言模型也是一回事。GPT 的参数量远小于训练数据量,但它能生成从没见过的合理文本。因为它压缩了数据背后的结构
外星文明输给了李白。它的算力够了。它不会压缩
「压缩即智能」这个词表达得不好。两个抽象概念中间一个「即」字,没有信息论背景的人很难直觉理解
但它说的事情很简单。用最少的符号解释最多的现象,用最短的程序还原全部信息,用最少的参数做最好的预测。换句话说:Mini 这个 Max
我建议以后别说「压缩即智能」了,说:MiniMax
以上内容,是认真的
文章来自于“赛博禅心”,作者 “金色传说大聪明”。



