# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型开发者常面临一个两难选择:要速度,还是省显存?
通常情况下,想要跑得快,显存会爆;想省点显存,计算效率又会被频繁的同步和流水线气泡大幅拖垮。原生的 torch.compile 虽然好用,但在面对复杂的跨层优化和 FSDP 显存管理时,依然力不从心。
为了彻底解决这一痛点,Sand.ai 今天正式开源 MagiCompiler —— 一款基于 torch.compile 深度优化的即插即用、训推一体编译框架。
MagiCompiler 彻底突破了传统局部编译的界限,实现了推理期整图捕获与训练期 FSDP-Aware 整层编译。
更重要的是,研发团队创新提出 Compiler as Manager 理念 —— 将编译器从单纯的 “算子优化器” 进阶为全局管理器。它全面接管了计算调度与显存的生命周期,以系统级的底层解法,破解算力与显存墙难题。
1. 打破编译边界:整图与整层编译
传统编译常因复杂的 Python 逻辑频繁触发 Graph Break。研发团队彻底改变了这一点:
2. 内存魔术:启发式重计算(Heuristic Recompute)
在训练大模型时,开发者通常需要手动插入 torch.utils.checkpoint 来控制显存,既繁琐又难以最优。MagiCompiler 引入了智能感知图分割器:
3. 榨干带宽:JIT 极致 Offload 调度
针对显存瓶颈,研发团队实现了一套极其优雅的权衡调度引擎:
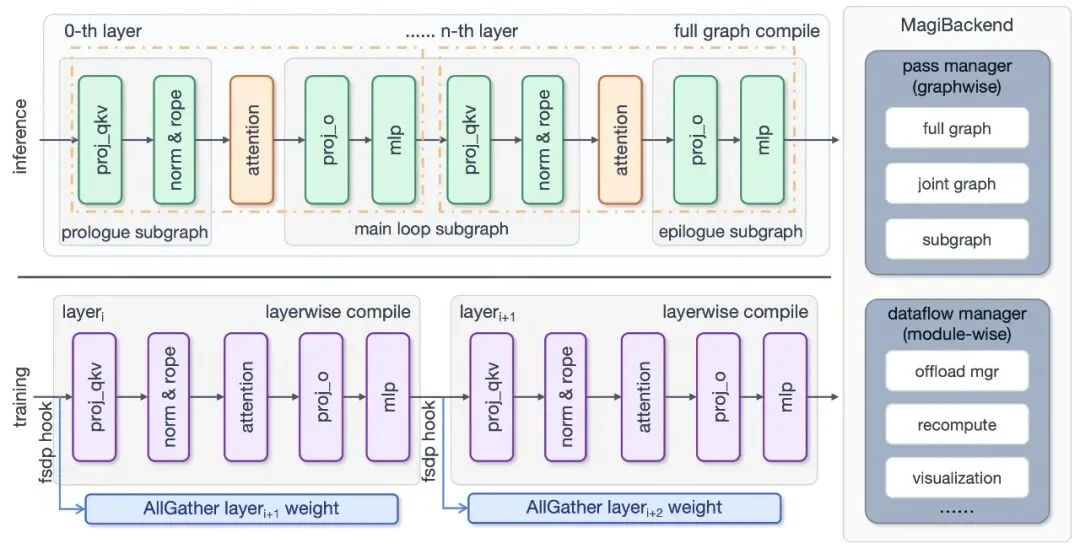
MagiCompiler Overview
凭借底层的全局调度,MagiCompiler 交出了亮眼的答卷:
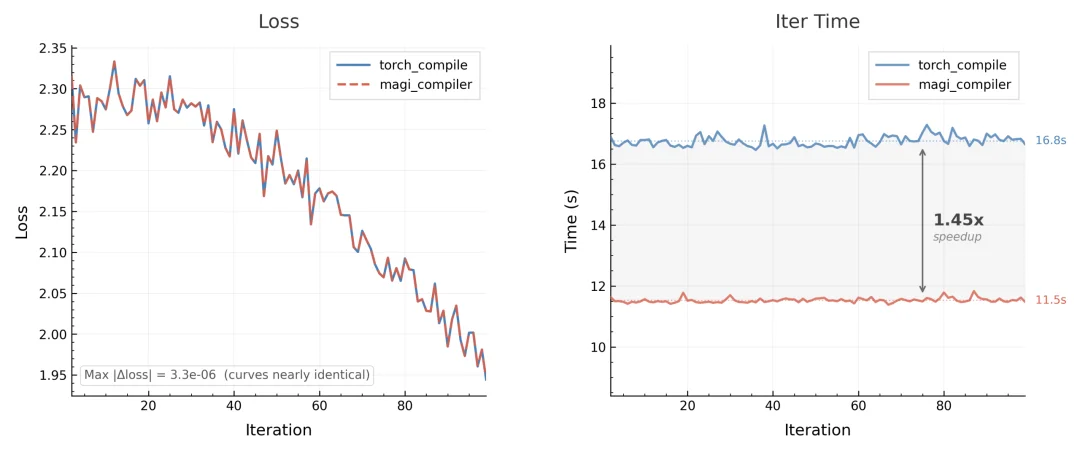
MagiCompiler v.s. baseline
在单机 NVIDIA H100 上,面对主流视频生成模型,MagiCompiler 比目前的领跑方案(如 LightX2V)还要快 9%~26%。
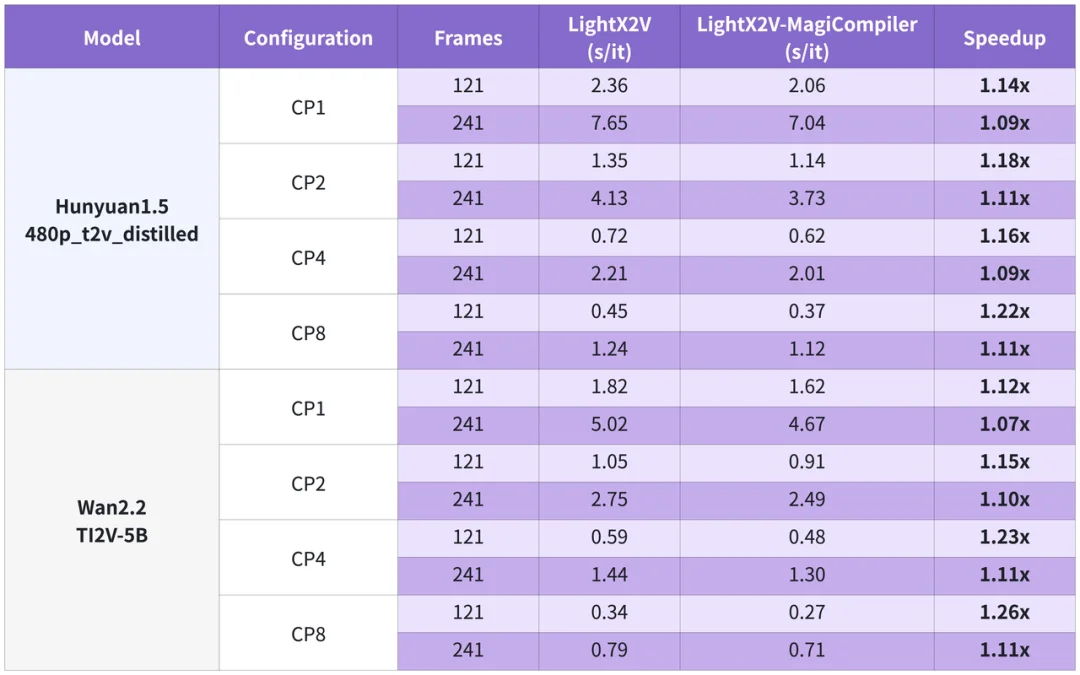
H100 性能测评
即便在显存有限的 5090 上,通过 JIT Offload 调度,MagiCompiler 也让 daVinci-MagiHuman 这种超大模型跑出了近乎实时的速度。
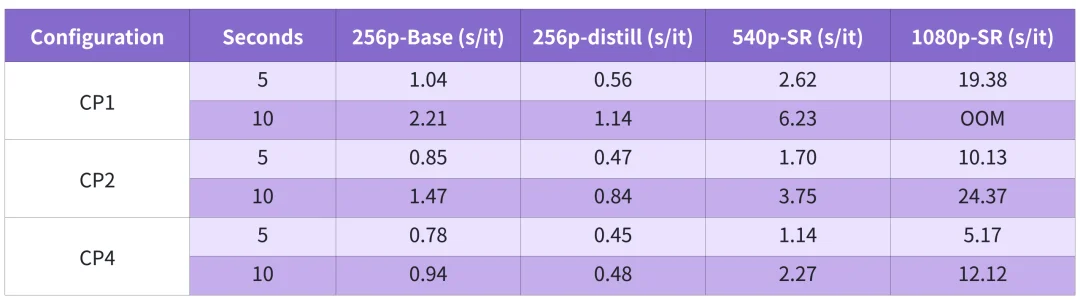
5090 daVinci-MagiHuman 性能指标
强悍的底层性能并不意味着复杂的接入成本。秉持对开发者友好的设计理念,MagiCompiler 只需两个装饰器即可完成接入。
无需修改模型源码,magi_compile 一键装饰 TransformerBlock:

对于 FlashAttention 或 MoE 等定制化算子,轻松注册并无缝融入重计算策略:

此外,我们内置了强大的自省工具链:开启环境变量,所有隐式的编译产物(反编译字节码、Kernel 代码、Guard 条件等)均会被持久化为人类可读的 Python 文件与图表,让编译器 Debug 变得简单直观。
MagiCompiler 正在打破传统编译器的边界。它不仅让我们看到了 torch.compile 迈向全局调度的巨大潜力,更为大模型与多模态架构的规模化落地提供了基础设施。
目前,MagiCompiler 已全面开源。Sand.ai 将持续降低大模型底层的开发门槛,为 AI 社区持续做出贡献。
了解更多信息,欢迎访问 Sand.ai 官网:https://sand.ai
文章来自于“机器之心”,作者 “机器之心”。




