# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一款 “反直觉” 的产品,往往最能折射一个产业的真实需求。
3 月 25 日,硅心科技(aiXcoder)发布了一款专为「代码变更应用」场景设计的高性能、轻量级模型 aiX-apply-4B。
基准测试结果显示,在 20 多种主流编程语言及 Markdown 等多类型文件格式的测试中,aiX-apply-4B 的平均准确率达到 93.8%,超越 Qwen3-4B 基座模型 62.6% 的准确度,甚至高于千亿级大模型 DeepSeek-V3.2。同一任务场景下,aiX-apply 模型算力成本约为 DeepSeek-V3.2 的 5%,推理速度则提升 15 倍,仅需一张消费级显卡即可在企业部署。
同一代码变更应用任务场景下,对比 aiX-apply 模型与 DeepSeek-V3.2 推理速度
当全行业还在卷参数、卷通用能力时,这家北大系 AI Coding 赛道创企早已将目光投向了更深水区的问题 —— 在企业研发算力有限的背景下,AI 到底该如何赋能智能化软件开发?
为什么是 4B 小模型?
因为企业的算力 “就这么多”
随着 OpenClaw 等智能体框架的普及,企业 AI 应用正从单次模型调用走向多智能体协作。一个复杂任务的完成往往需要 10 到 50 次模型调用,并发场景下的 Token 消耗更是达到传统模式的数倍甚至数十倍。
这一变化直接加剧了企业的算力压力。尤其对于金融、通信、能源、航天等关键领域企业来说,私有化部署的算力 “就这么多” 且极其宝贵 —— 每一次额外的模型调用,都在消耗本就紧张的算力资源,推高延迟的同时挤占并发能力。当多智能体协作成为常态,如何控制算力成本成为企业面临的核心挑战之一。
公有云 “烧” Token 的模式无法满足企业数据安全需求,私有化部署千亿级、万亿级大模型成本高昂且容易导致算力空转浪费。如何将有限算力实现最优配置,让每一份算力都能落到最需要的研发场景中去,是行业亟待解决的核心问题。
正是在这样的行业背景下,aiXcoder 推出更适合企业私有化部署的 aiX-apply-4B 轻量级模型,服务于代码变更应用场景。这一场景的核心挑战在于,需要将模型生成的不规整、碎片化的代码片段,精准、无损地应用到原始文件中,同时严格保持缩进、空白符、上下文的一致性,不牵动其他代码、避免引入新问题。
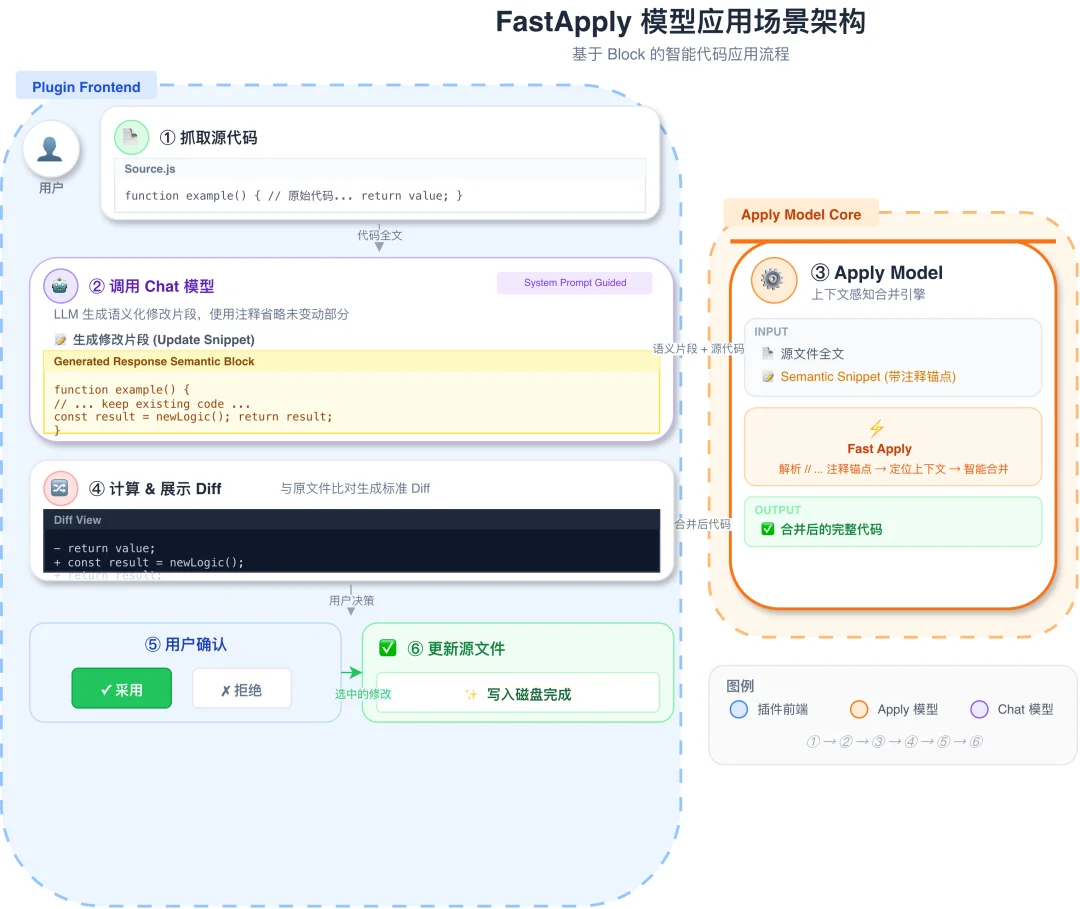
aiX-apply-4B 模型架构
据了解,为了贴合真实企业研发应用场景,确保模型应用效果,aiXcoder 团队采用了一系列创新训练方法:
一是高质量专属数据集构建。aiX-apply 模型的训练数据源自真实企业级场景下的代码提交记录。在此基础上,引入一致性审计机制,剔除包含模糊上下文或无法推导出修改逻辑的冗余信息,确保 “代码片段” 与 “变更结果” 之间存在绝对确定的因果关系。这意味着模型在训练阶段接触到的都是 “逻辑闭环” 的高质量数据,使其能够精准建立从修改意图到代码应用位置的深度映射。
二是训练与评测一体化闭环设计。aiX-apply 模型是基于高性能强化学习框架不断生成代码修改内容,并结合规则化奖励机制进行评测 —— 系统会实时判定修改是否正确、是否越界,再把结果反馈给模型。通过端到端闭环训练,让模型在 “生成 - 反馈 - 修正” 的在线强化学习中持续对齐工程约束,始终在指定区域精准操作,杜绝因 “幻觉” 而导致的非必要代码改动,显著提升代码应用的准确性与可靠性。
三是严格的工程化约束。为适配代码变更应用这一垂直工程场景,aiX-apply 模型设定了两项核心工程约束。首先是非副作用约束,模型仅修改指定改动区域,区域外内容严禁变动;然后是安全失败策略,当代码上下文锚点不唯一、无法准确定位时,模型直接输出空结果,不做猜测性修改,避免污染代码库。双重约束保证了代码合并过程高度可控、结果可预期。
在统一的测试方法与多维度评估体系下,这个 4B 参数小模型在代码变更应用这一场景中实现了超越千亿级大模型的表现:
在准确率方面,测试结果显示,在覆盖 20 余种编程语言及文件类型的 1600 余条测试集上,aiX-apply 表现优于同量级模型 Qwen3-4B(准确率 62.6%),更与参数规模相差一百多倍的 DeepSeek-V3.2(准确率 92.5%)比肩。
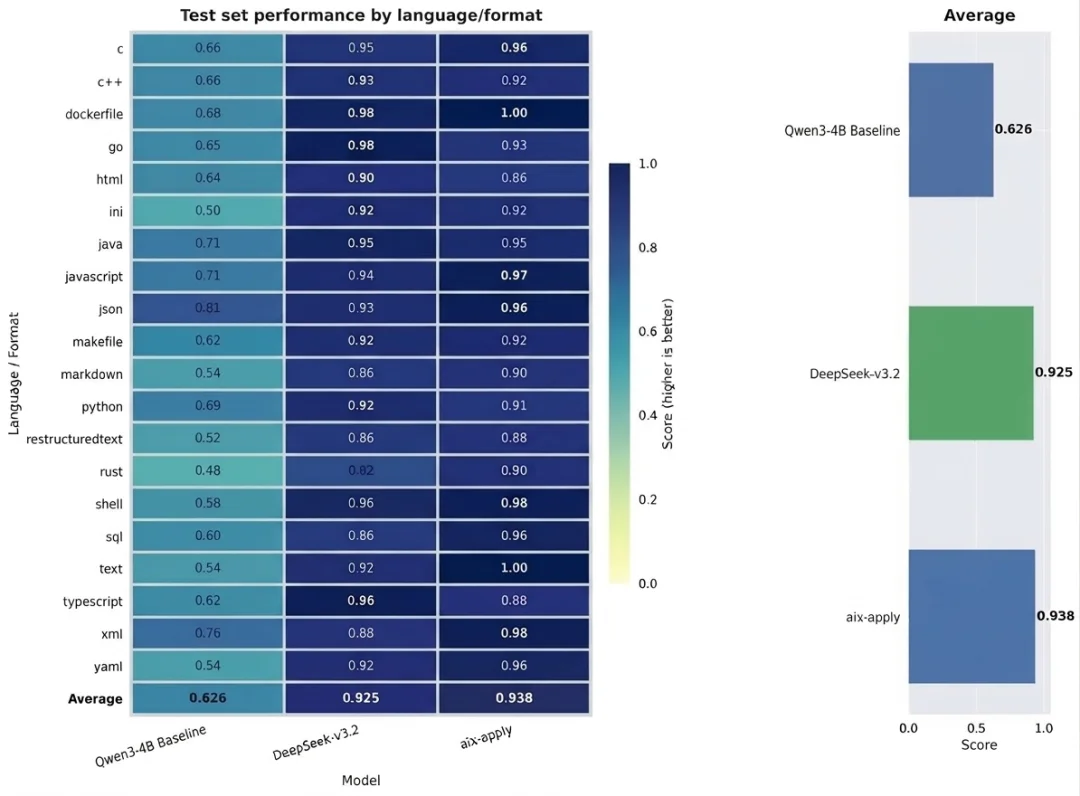
基准测试对比
在推理效率方面,aiXcoder 引入自适应投机采样技术,极大压缩了端到端延迟。企业级生产环境实测显示,aiX-apply-4B 推理速度每秒可达 2000 tokens,在单张 RTX 4090 消费级显卡上即可高效运行;而对比模型 DeepSeek-V3.2 则需要八卡 H200 高端集群部署。综合不同的硬件部署成本与推理速度综合对比,aiX-apply-4B 仅用 DeepSeek-V3.2 约 5% 的算力成本,实现了 15 倍的效率提升。
在泛化能力方面,aiX-apply 模型展现出了媲美 DeepSeek V3.2 的准确性和稳定性。无论是面对超长代码文件的精确编辑,还是在训练数据中占比极低甚至未显式出现的编程语言场景下,aiX-apply 模型都保持了良好的范式泛化能力,充分验证了其在真实企业级开发环境中的实用价值。
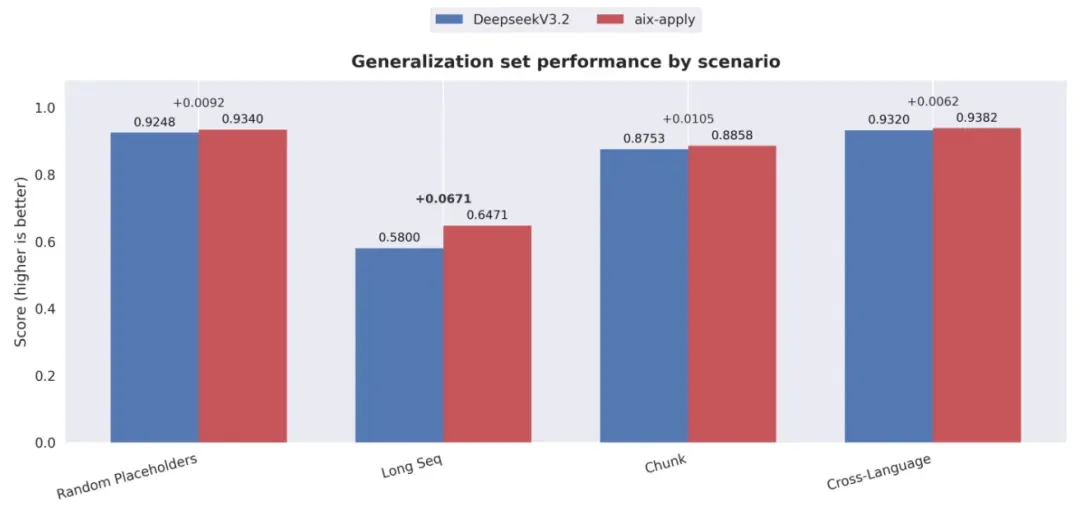
泛化性能力测试对比
“大模型 + 小模型” 协同,最大化释放有限算力价值
事实上,aiX-apply-4B 模型并不是 aiXcoder 发布的针对研发场景定义的第一款小模型,早在 2024 年 aiXcoder 团队就已推出参数量为 7B 的代码补全小模型,能够精准预测开发者意图,专为开发者日常编码的高频场景设计。
据介绍,基于 “场景定义模型” 这一理念,aiXcoder 已构建起覆盖多个研发关键环节的小模型矩阵,并创新提出 “大模型 + 小模型” 协同架构,让 “通才” 大模型与 “专才” 小模型各司其职、优势互补:通用大模型聚焦复杂意图理解、代码逻辑分析、修改方案制定等需要深度推理的工作,发挥其智能优势;而垂直场景小模型则承接高频工程任务,以轻量化特性实现快速、精准执行。
这种架构设计可以让企业的有限算力得到分层利用:小模型支持专项场景任务的高效完成,节约出更多算力用于大模型的复杂推理。由此,避免了高端算力的浪费,充分释放企业有限算力价值。
文章来自于微信公众号 "机器之心",作者 "机器之心"



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
