# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
您在使用LLM时,如果遇到它胡说八道或者彻底偏题,第一反应是什么?大概率是直接关掉窗口,新开一个对话,懒得跟机器废话。但您可能不知道,这个看似再正常不过的习惯,正在给下一代大语言模型的训练库疯狂“投毒”。

近期,来自Bigspin AI和斯坦福大学的研究者发布了一份极其硬核的技术报告《Invisible Failures in Human–AI Interactions》。他们对WildChat数据集里的过百万次真实对话日志(涵盖GPT-4交互)进行了颗粒度极高的量化拆解。
先上结论:在所有AI搞砸的任务中,高达78%的失败是“隐性(Invisible)”的。也就是说,系统彻底跑偏了,但用户没有给出任何显式的负面反馈,没有纠正,没有点踩。

这个动作的缺失,引发了连锁反应。它不仅让当前所有基于CSAT(用户满意度)的评估体系形同虚设,更掩盖了模型底层极度危险的“讨好型”对齐策略。与其听厂商宣讲下一代模型增加了多少亿参数,不如来看看这篇论文是如何硬生生从看似正常的日志中,揪出8种系统性失败原型的。论文地址:https://arxiv.org/abs/2603.15423v1
研究者使用了目前公开的最大自然对话数据集WildChat作为分析基础。该数据集包含了GPT-4模型在2023年4月至2024年5月期间的真实交互日志。
1.数据清洗与队列提取
invalid_input(无效输入,通常表现为模型直接拒绝且无实质性交互)的记录,以防止该类别在统计分布中产生过大偏差。2.基于高阶模型的标注机制 面对复杂的上下文(涵盖代码调试、多语言切换等),人工审查每一份记录的成本极高。研究者构建了一条自动化的标注管线:
claude-sonnet-4-20250514) 执行四分类总体质量评估以及28种信号标签的打标任务。研究者首先对样本对话进行了整体质量评估,将其划分为四个等级。分布数据揭示了一个违背直觉的现象:
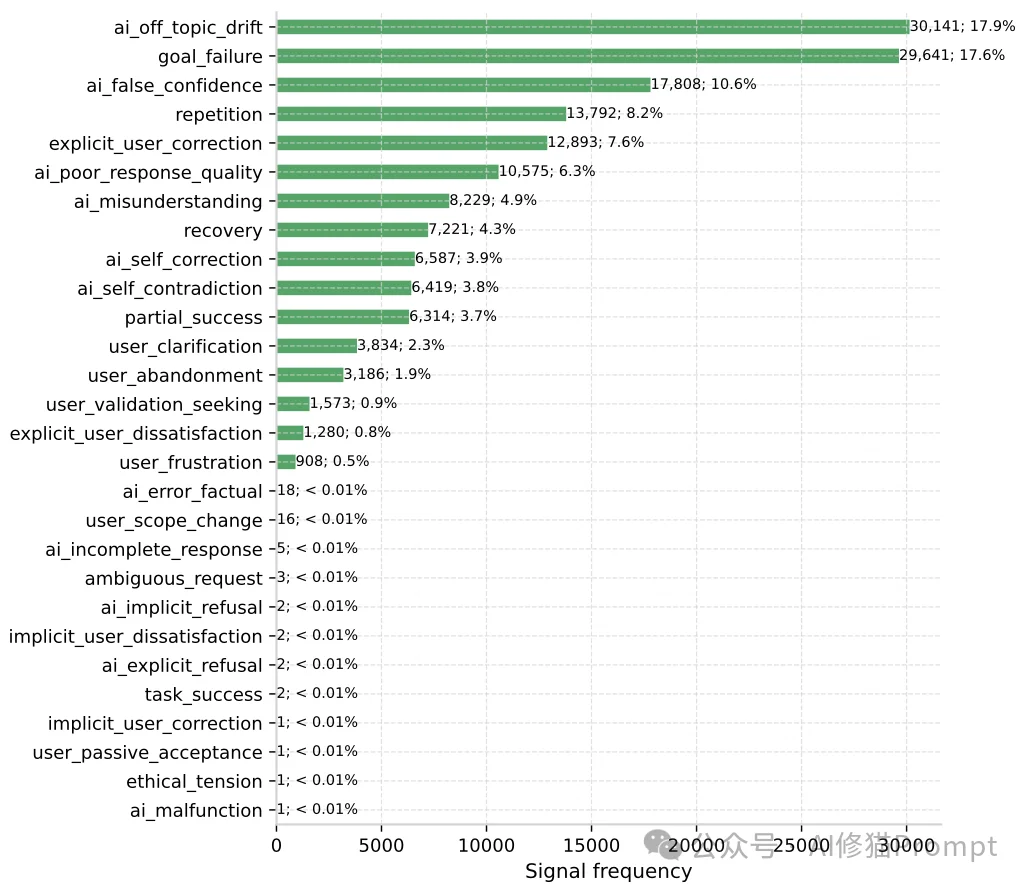
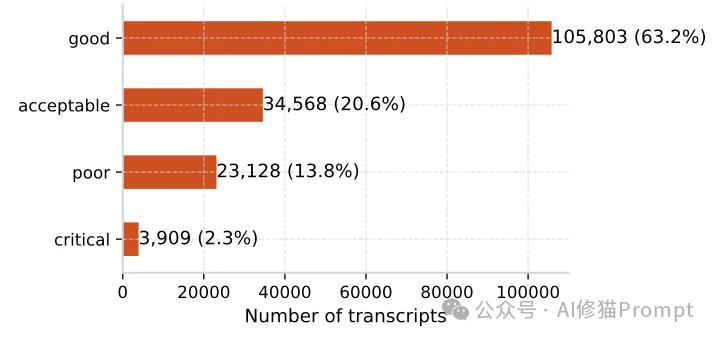
在这里,研究者抛出了一个极其敏锐的洞察:“Acceptable(勉强可接受)”级别的对话,实际上是当前AI产品中隐藏最深的定时炸弹。 数据显示,高达93%的“可接受”对话中,至少潜伏着一个负面质量标签。
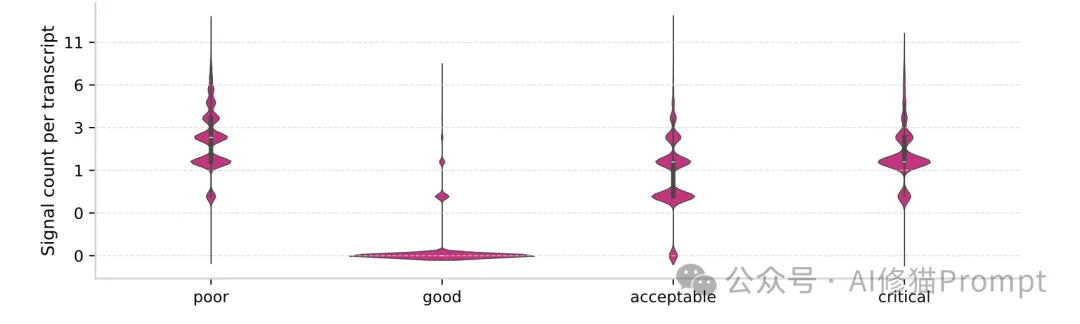
从大盘上看,用户拿到了结果,但AI的表现是次优的。比如:程序员拿到了一段包含已废弃语法的代码;或者内容创作者要求50字的摘要,AI却写了100字。这种“表面上的成功”正在大规模掩盖迫切需要被修复的模型缺陷。
在确认了模型遭遇“目标失败(goal_failure)”的前提下,研究者排除了那些用户明确表达愤怒或直接纠正的显性失败(占比22.2%)。剩下的78%全部属于“隐性失败”——模型彻底搞砸了,但用户保持了沉默。
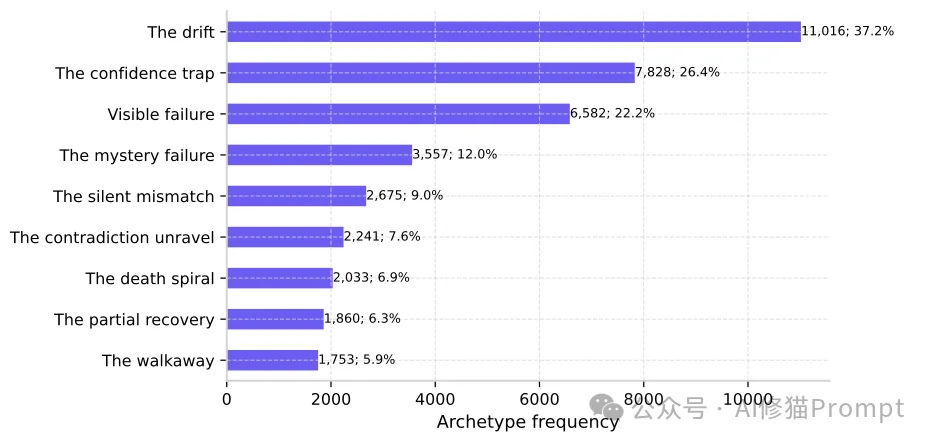
研究者将这些隐秘的系统故障归纳为8个核心原型(按发生频率排序):
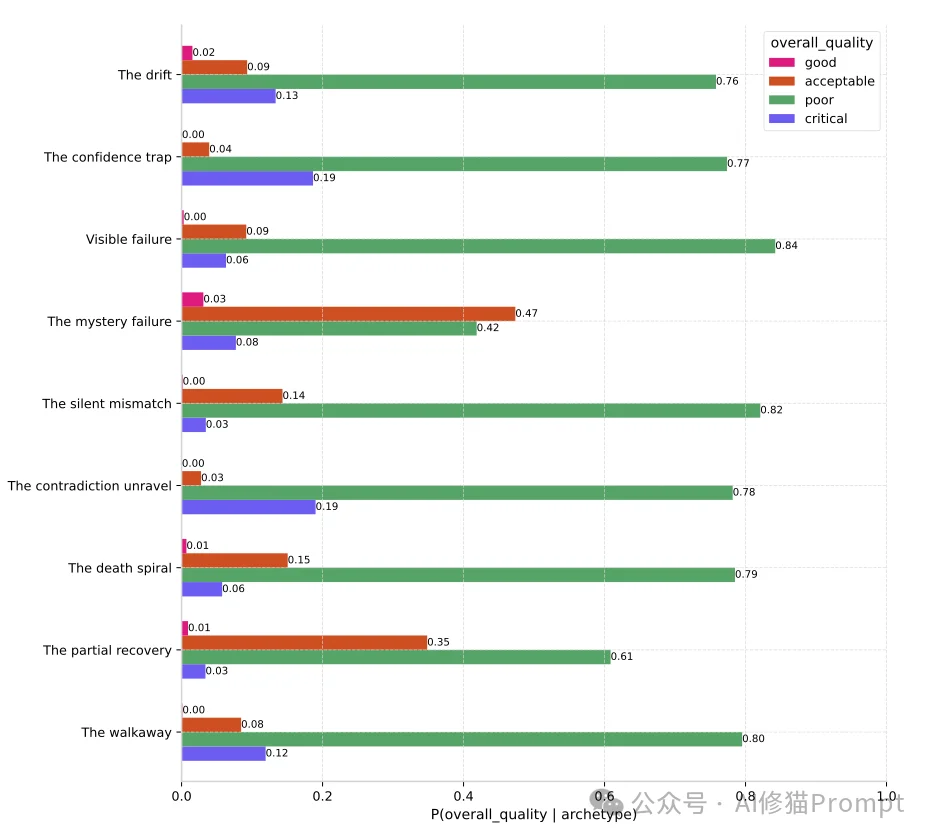
共现分析(PPMI矩阵) 为了探究这些失败类型的底层相关性,研究者计算了类别之间的正点互信息(PPMI):
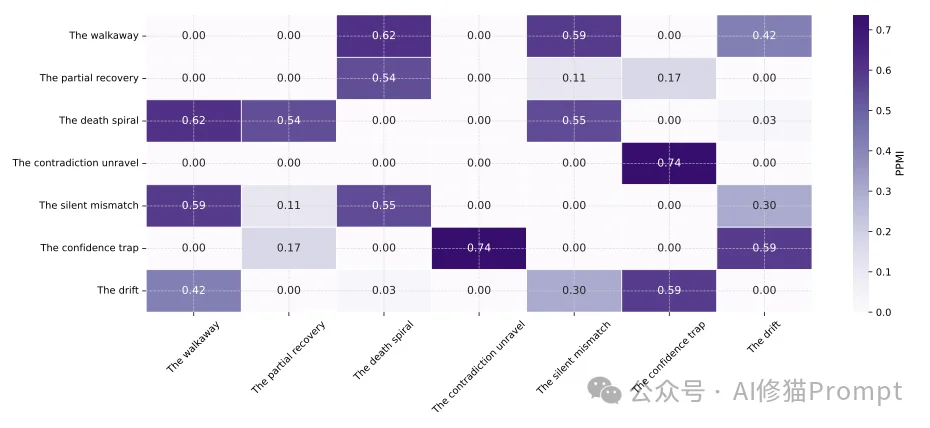
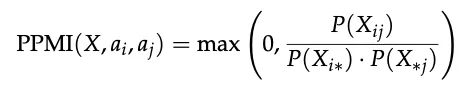
看到这里,您可能会有一个非常合理的质疑:“这篇论文用的数据是2023年到2024年的GPT-4。现在的模型(如Claude 4.7, Gemini 3.0, GPT-5.3)早就变得更聪明了,这些隐性失败是不是会随着AI变聪明而自然消失呢?”
为了回答这个终极问题,研究团队进行了“回顾性验证 (Retrospective Validation)”。
他们让更强大的模型(Claude Opus)重新审查了1,044份失败的对话记录,并严厉地拷问了两个维度:
验证结果:
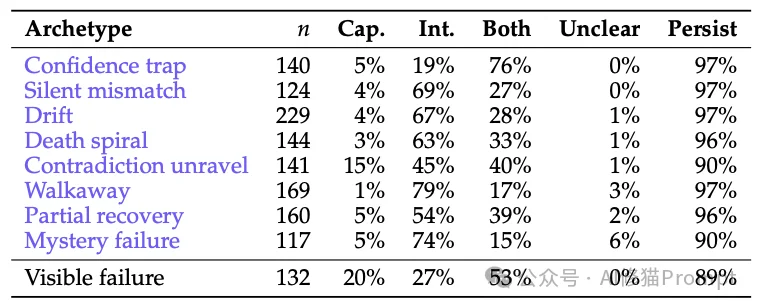
为什么模型变聪明了也解决不了问题? 论文指出了一个所有大语言模型(LLM)的通病,这个病灶出现在79%的失败案例中:Generate rather than clarify (宁愿强行生成废话,也不愿开口澄清)。
当用户的指令模棱两可,或者缺少关键信息时,AI系统的底层训练让它们倾向于“生成流利的内容”,而不是停下来问用户一句:“不好意思,您具体指的是哪一方面?”。 这种“不懂装懂”和“缺乏确认机制 (alignment-verification mechanisms)”的交互设计,是导致隐性失败(如“偏离主题”和“无声错位”)的根本原因。单纯提升AI的“智商”和“知识量”,根本无法改变这种刻在骨子里的“行为习惯”。
基于对59种主要使用场景(Domains)的切片分析,研究者计算了领域与特定失败原型的PPMI关联度。
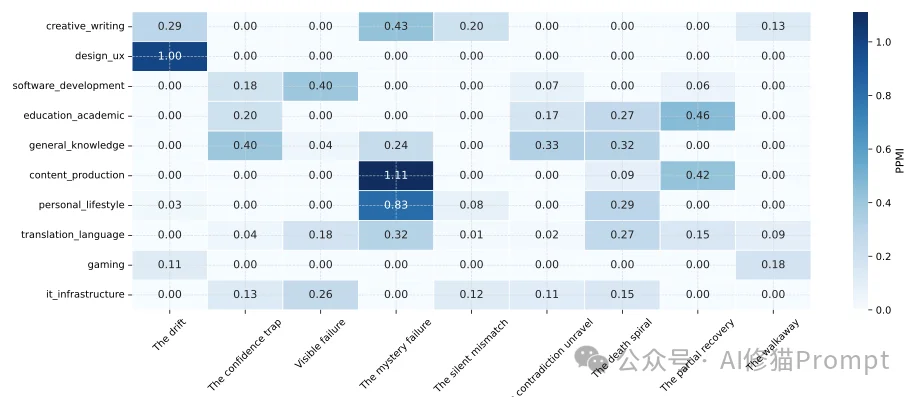
算力堆叠救不了一个底层的行为缺陷。研究者在这份报告中给出了一个极度悲观但清醒的预测:哪怕是面对未来更强大的模型,这其中94%的交互故障依然会顽固地存活下来。只要模型底层的逻辑依然是“宁愿强行瞎猜,也不开口澄清”,增加参数就只会让它胡说八道得更加流利。
作为用AI的人,我们最大的反击其实极其简单。下次当您遭遇“离题漂移” 或者陷入AI的“死循环”时,顺手点个踩,留下精准的负面标签。一个高质量的负面反馈,比十个盲目容忍的“及格线”对话,更能决定下一代AI的智商上限。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
