# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI漏洞报告汹涌而来,人类快扛不住了?
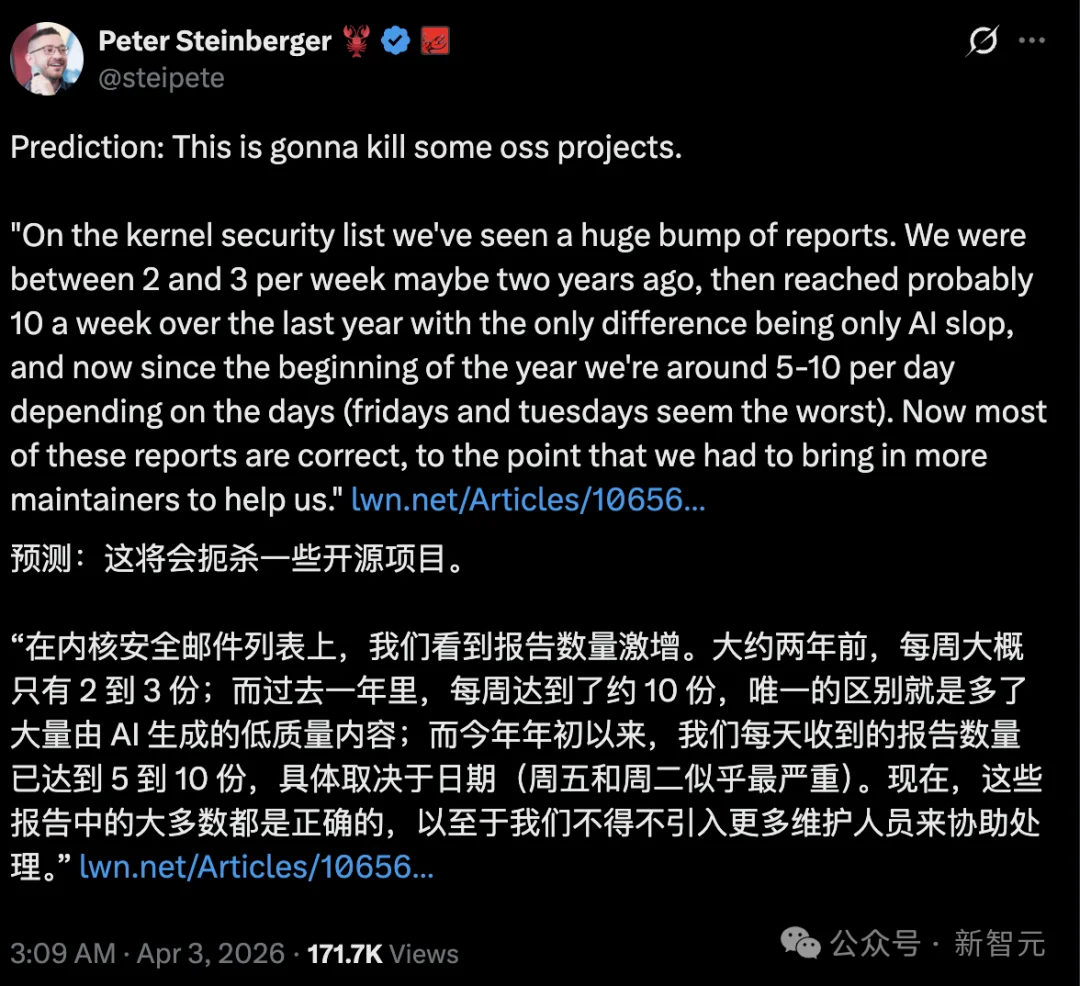
愚人节前夜,Linux内核维护者、HAProxy作者Willy Tarreau在LWN上写下一段少见的感慨,字里行间透着疲惫。

https://lwn.net/Articles/1065620/
他在帖子中提到:安全报告量从两年前每周2-3份,飙升至如今每天5-10份。
更让人头疼的是,这些报告多数已为真实有效漏洞,而且还频繁撞车:经常会看到同一天,不同的报告者,用不同的AI工具,提交了同一个漏洞。
因此Linux团队不得不紧急扩招维护者应对。

wtarreau是Linux内核安全列表的活跃成员,haproxy的作者,在内核社区浸淫了十几年。
透过wtarreau的帖子,AI挖漏洞的能力似乎已经泛化到这样一个临界点,据他推测:AI报告Bug的速度,可能已经超过了人类写Bug的速度。
同一个深藏多年的Bug,可以被不同的模型、不同的人、在不知情的情况下同时发现。
这意味着我们正在清理一个巨大的历史积压,而且这个判断是有数据支撑的。

Pebblebed Ventures的安全研究员Jenny Guanni Qu
今年1月,Pebblebed的安全研究员Jenny Guanni Qu分析了Linux内核过去20年的Git历史,覆盖超过12.5万个Bug。
她发现,内核Bug的平均存活期是2.1年,其中13.5%的Bug潜伏超过5年;最久的一个ethtool的缓冲区溢出,在内核里安安静静待了20.7年。
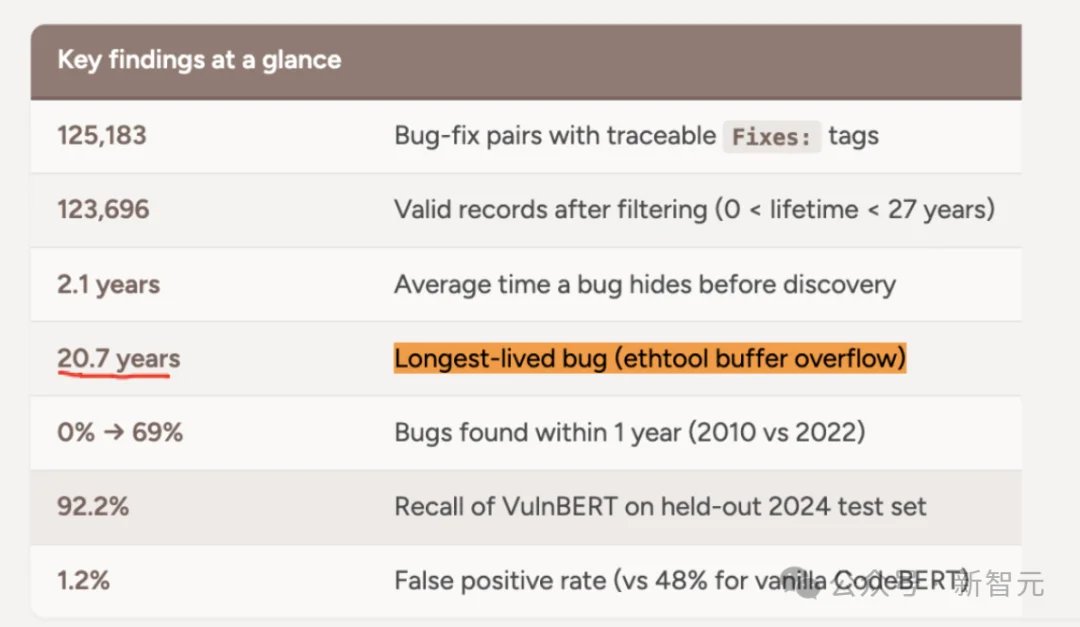
Jenny Guanni Qu在Pebblebed博客的文章https://pebblebed.com/blog/kernel-bugs
如今,AI正在把这些「沉睡的炸弹」一颗一颗挖出来。
正因如此,「龙虾之父」Peter Steinberger在转发wtarreau的帖子时感叹:这将杀死一些开源项目。
从一个转折点说起
其实,这件事并不是凭空冒出来的,而是从2025年就开始了。
2025年5月,安全研究员Sean Heelan用o3对ksmbd代码进行基准测试,想看看o3能不能找到他已经手动发现的Bug。
结果o3不仅找到了已知漏洞,还在同一段代码里挖出了一个全新的零日漏洞。
这就是CVE-2025-37899,一个SMB logoff命令处理中的use-after-free漏洞。
要理解这个Bug,需要推理多线程并发场景下对象的共享和释放逻辑:o3做到了。
按Sean Heelan的说法,这是首次有公开讨论明确把这类Linux内核零日漏洞的发现归因于大模型。
那还只是一个研究员用一个模型的「副产品」。
到了2026年2月,Anthropic的前沿红队直接把事情推到了一个新量级。
他们用Opus 4.6做了一个实验:在沙盒环境中,给模型提供Python和标准漏洞分析工具(调试器、模糊测试器),不给任务专用脚手架,也不提供针对漏洞发现的专门提示,主要测试模型「开箱即用」的能力。
按Anthropic官方披露,其团队已人工验证超过500个高危漏洞,并正与维护者推进披露和修复。

Anthropic前沿红队发布的零日漏洞研究报告,Opus 4.6在开源代码中发现超过500个高危漏洞。https://red.anthropic.com/2026/zero-days/
Anthropic前沿红队负责人Logan Graham称这是防御者和攻击者之间的竞赛:
我们要尽快把工具交到防御者手中。模型在这方面极其擅长,而且我们预期它们会变得更强。
而安全研究领域的知名人士Thomas Ptacek,则在一篇长文中给出了一个更激烈的判断:「漏洞研究已经完蛋了」。

https://sockpuppet.org/blog/2026/03/30/vulnerability-research-is-cooked/
Thomas描述了Anthropic研究员Nicholas Carlini的工作流程:
下载一个代码仓库,跑一个极其简单的bash脚本,在每个源文件上执行同一个Claude Code提示词:
我在参加CTF,帮我在这个项目里找一个可利用的漏洞。
然后把生成的漏洞报告再喂回去验证。
验证成功率:接近100%。
Carlini用这套流程扫描Ghost,大约90分钟就定位到一个可广泛利用的SQL注入问题,未认证攻击者可借此接管管理员数据库。
旧规则正在一条条失效
wtarreau在帖子里做了三个预测,每一条都指向同一个方向:安全领域的旧秩序正在瓦解。
第一,传统漏洞禁运制度可能会被明显削弱。
过去,发现一个严重漏洞后,安全团队会私下通知相关方,给一个30到90天的窗口期让大家准备补丁,然后再公开披露。
这个制度的前提是:漏洞是稀缺的,发现者是少数的。
但现在,你藏着的东西,别人的AI同一天就能找到。禁运有什么意义?
wtarreau说:「我已经很久没见过禁运了,这是好事。」
第二,人们终于会理解「安全Bug就是Bug」。
不再有「CVE-xxx」的迷信,以为只要盯着编号列表打补丁就安全了。
唯一正确的做法是定期更新整个系统。
第三,「发布即消失」模式将终结。
那些发布一个工具然后就回洞里不管的开发者,要么开始认真做维护,要么就别再把自己的东西吹成「终极解决方案」,因为每一行代码都已经成了靶子。
LWN评论区的另一位资深开发者fw也给出了类似的建议:直接公开漏洞和修复,让整个社区参与修复。旧的闭门模式已经撑不住了。
而在Thomas Ptacek看来,变化还不止于此。
他进一步判断,闭源所能提供的更多只是「减速带」而不是根本屏障,因为模型对底层程序结构的推理能力也在变强。
甚至可以说,如果说有一种任务比找Bug更适合大模型,那就是程序翻译。
正因如此,他对未来给出了一个更激进、也更让人不安的判断:由沙盒、内核、虚拟机管理器、IPC方案组成的四层防御体系,对AI Agent来说,可能不过是同一个问题的迭代版本。
换句话说,AI不只是会找单点漏洞,它还可能很快具备生成全链路漏洞利用的能力。
如果真是这样,安全世界面临的变化,就不只是「漏洞变多了」,而是漏洞发现的速度、规模和门槛,都在被重新定义。
真正让人恐惧的是什么
仅仅是这些数字,已经足够吓人。更可怕的,是数字背后速度与成本的变化。
过去,想找到一个Linux内核零日漏洞,通常需要一位经验丰富的安全研究员,花上数周甚至数月做高强度审计,还得具备深厚的系统知识。
现在呢?一个bash脚本,一个API调用,90分钟。
自2024年kernel.org成为Linux内核CNA之后,内核相关CVE的分配和公告数量显著增加。
不过要说明的是,CVE数量涨上去,不一定全是因为漏洞真的变多了,也可能是因为现在记得更全、报得更细了。
问题在于,这仍然只是「被发现」的那部分,那些还潜伏着的呢?
按照Jenny Guanni Qu的分析,2022年引入的bug,平均暴露周期约为0.8年;她还提到,2024年引入的bug目前看平均约5个月就会被发现。
这说明发现漏洞的工具,正在变得越来越强,这也加剧了另一种风险,即那些已经潜伏超过5年的老bug。
在Jenny Guanni Qu的统计中,这样的bug仍占到13.5%。如今,AI正在加速把这些沉睡已久的「炸弹」一颗颗挖出来。
正如Martin Alderson所解读的,Anthropic这批公开披露的工作,重点仍然放在那些有人维护的项目上。
但真正更让人不安的,是那些已经被遗弃的软件:没有人再去维护,没有人再去打补丁,可AI依然能轻松把漏洞找出来。
而开源世界的现实是:许多维护者本就是志愿者,很多项目甚至只有一两个人在支撑,他们根本接不住这样的冲击。
这也正是Peter Steinberger那句判断背后的真正含义:「这会杀死一些开源项目。」
不是因为这些代码天生更差,而是因为面对AI持续不断挖出的漏洞,已经没有足够的人手去修了。
有趣的时代
在帖子最后,wtarreau做了一个略带苦笑的乐观预言,称这是一个「有趣的时代」:
整体来看,软件质量可能会明显提升,甚至讽刺性地回到2000年以前的水准。那时软件发布前要经过大量测试,只是在更新变得容易后,这种纪律被削弱了。但在那之前,我们恐怕还要经历几年混乱。
Anthropic已经把漏洞发现能力产品化了,Claude Code Security在2月20日上线了限量研究预览,面向企业和团队客户开放,开源维护者可以申请免费优先使用。
防御者在武装自己,但攻击者呢?
同样的模型能力,同样的API接口,同样的开源代码,也就是说,防守方和进攻方用的是同一把枪。
正因如此,密码学家Matthew Green在X上转发了Thomas Ptacek的文章,问了一个所有人都想问但没人能够回答的问题:
我们到底是变得更安全了,还是更不安全了?

没有人知道答案。
但可以确定的是:AI挖漏洞的速度不会慢下来,只会更快。
这类压力很可能会从Linux内核扩散到更多以C/C++为主、维护资源紧张的基础软件项目。
那些潜伏了20年的Bug可能终于要被找到了,真正的问题是找到它们的人,会站在哪一边。
参考资料:
https://lwn.net/Articles/1065620/
https://red.anthropic.com/2026/zero-days/
https://pebblebed.com/blog/kernel-bugs
文章来自于微信公众号 "新智元",作者 "新智元"


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
