# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。
模型没变。变的是模型外面的那一层。
Akshay Pachaar 刚发了一篇非常扎实的长文,把 Anthropic、OpenAI、LangChain、CrewAI 这些头部玩家正在构建的智能体基础设施做了一次完整的解剖。这层基础设施有了一个正式的名字:Agent Harness(智能体线束)。
一句话总结:你的智能体表现差,大概率不是模型的问题,是 Harness 的问题。你搭了一个 chatbot、接了几个工具、跑通了 demo,然后试着做一个生产级的产品——结果模型忘了三步之前做过什么,工具调用悄无声息地失败,上下文窗口里塞满了垃圾。这不是模型笨。是包裹模型的那层基础设施没到位。
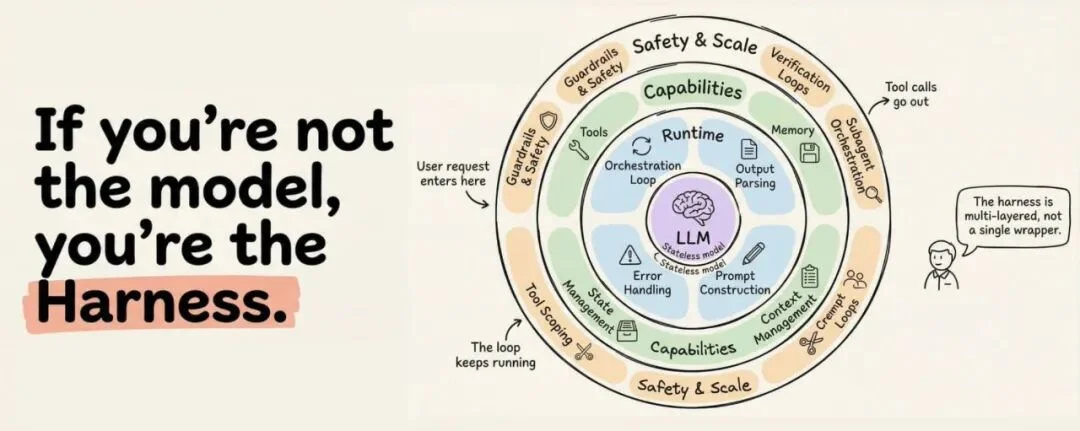
原文标题图:「如果你不是模型,你就是 Harness」——多层同心圆展示了 Harness 的完整架构
这个概念在 2026 年初被正式命名,但思路早就有了。Harness 指的是包裹在大模型外面的全部软件基础设施:编排循环、工具调用、记忆系统、上下文管理、状态持久化、错误处理、安全护栏。Anthropic 的 Claude Code 文档直说:SDK 就是「驱动 Claude Code 的 Agent Harness」。OpenAI 的 Codex 团队用的是同样的说法。
这个定义非常重要,因为它意味着 Harness 不是「一层薄封装」,而是一个完整的软件系统——可能比你的业务逻辑还复杂。LangChain 的 Vivek Trivedy 有一句我很喜欢的话:
如果你不是模型,你就是 Harness。
区分一下容易搞混的概念。「智能体」是涌现行为——有目标、会用工具、能自我纠正的那个你看到的东西。Harness 是产生这种行为的机器。当有人说「我做了一个智能体」,他们实际做的是:搭了一个 Harness,然后把它指向一个模型。
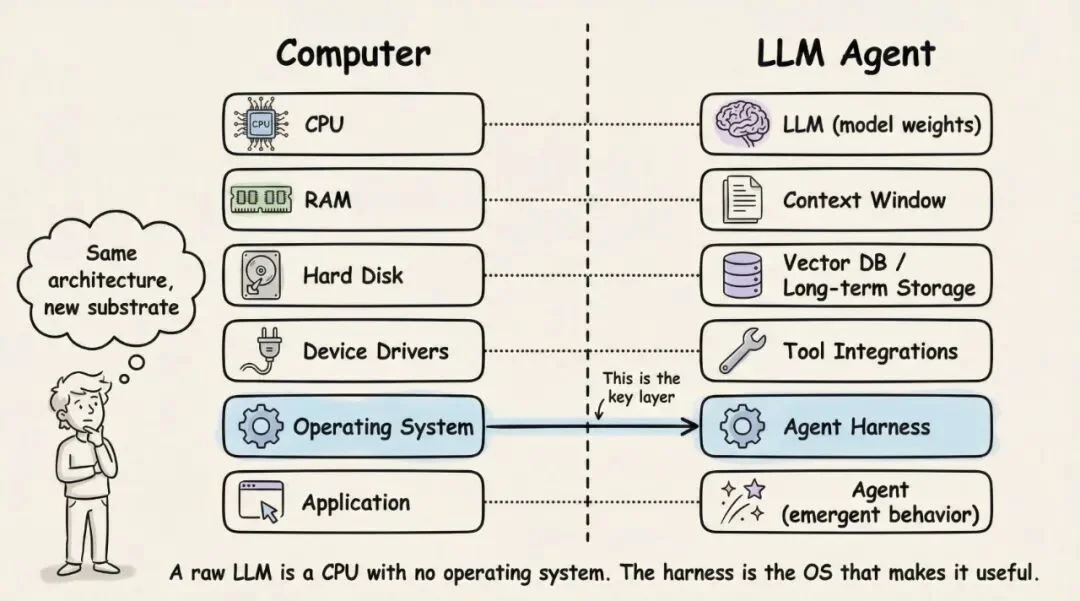
冯·诺依曼架构的 AI 版本:CPU=模型权重,RAM=上下文窗口,操作系统=Harness
Beren Millidge 在 2023 年的论文里用了一个精确的类比:裸模型就是一颗没有操作系统的 CPU——没有 RAM、没有硬盘、没有 I/O。上下文窗口是内存(快但小),外部数据库是磁盘(大但慢),工具集成是设备驱动,而 Harness 就是操作系统。他的原话是:「我们重新发明了冯·诺依曼架构。」
围绕模型的工程有三个同心层次:
提示工程——设计模型接收到的指令。上下文工程——管理模型看到什么、什么时候看到。Harness 工程——包含前两者,加上整个应用基础设施:工具编排、状态持久化、错误恢复、验证循环、安全执行、生命周期管理。
Harness 不是提示词的封装。它是让自主智能体行为成为可能的完整系统。很多人把「做智能体」等同于「写好提示词」,这就像把「做操作系统」等同于「写好启动脚本」——只碰到了冰山一角。
综合 Anthropic、OpenAI、LangChain 和开发者社区的实践,一个生产级的 Harness 有12 个独立组件。我挑几个最关键的展开说。
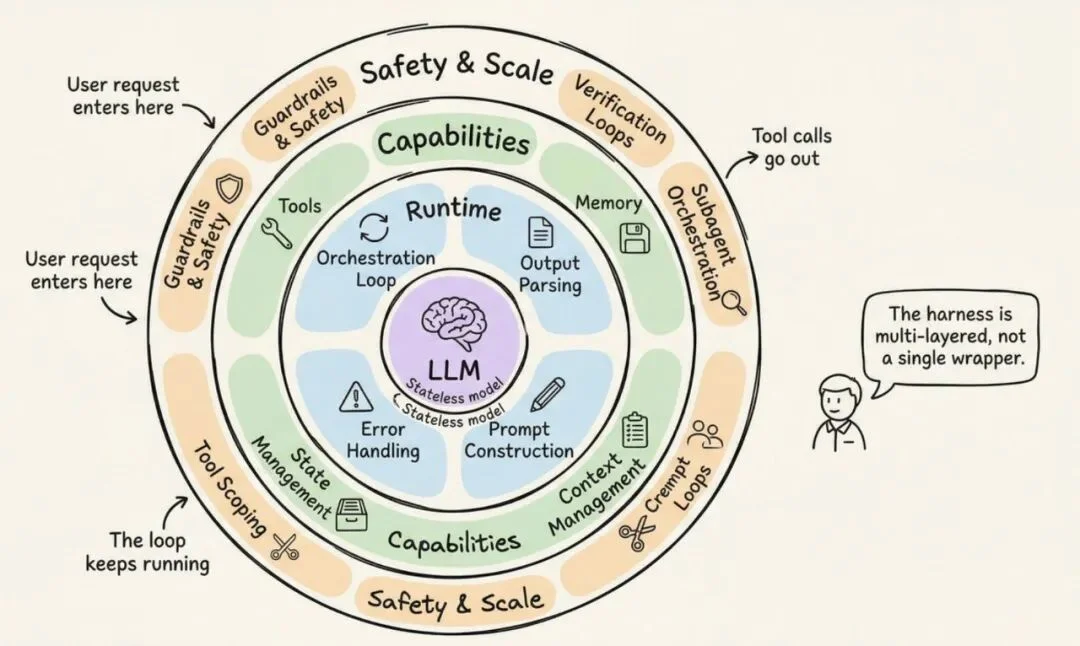
Harness 的 12 个组件:分为运行时、能力层、安全与规模三圈
编排循环是心跳。它执行 Thought-Action-Observation 循环(也叫 ReAct 循环):组装提示 → 调用模型 → 解析输出 → 执行工具调用 → 把结果喂回去 → 重复直到完成。机械上看就是一个 while 循环。Anthropic 自己都说他们的运行时是一个「傻循环」——所有智能都在模型里,Harness 只管理轮次。
但这个「傻循环」管理的东西一点都不傻。
一个简单的问题可能只需要 1-2 个循环。一次复杂的代码重构可能链式调用几十次工具,横跨多个循环。循环的终止条件是分层的:模型产生了不含工具调用的响应、达到最大轮数上限、token 预算耗尽、安全护栏触发、用户中断、或模型返回安全拒绝。每一层都是一道防线。
对于跨越多个上下文窗口的长任务,Anthropic 开发了一种「Ralph 循环」模式:一个初始化智能体搭建环境(初始化脚本、进度文件、功能列表、初始 git 提交),然后后续每个会话的编码智能体读取 git 日志和进度文件来定位自己、选择最高优先级的未完成功能、完成后提交并写摘要。文件系统提供了跨上下文窗口的连续性。
工具系统是智能体的手。工具以 schema(名称、描述、参数类型)的形式注入上下文。Claude Code 提供了六类工具:文件操作、搜索、执行、网络访问、代码分析、子智能体生成。OpenAI 的 SDK 支持函数工具(@function_tool)、托管工具(WebSearch、CodeInterpreter)和 MCP 服务器工具。
记忆在多个时间尺度上运作。短期记忆是单次会话内的对话历史。长期记忆跨会话持久化。各家的实现不同:
Anthropic 用 CLAUDE.md 项目文件和自动生成的 MEMORY.md 文件。LangGraph 用命名空间组织的 JSON 存储。OpenAI 支持基于 SQLite 或 Redis 的 Sessions。
Claude Code 的记忆系统特别值得说。它实现了三层层级结构:一个轻量级索引(每条约 150 字符,永远加载)、按需拉取的详细主题文件、以及只通过搜索访问的原始对话记录。关键设计原则是:智能体把自己的记忆当成「提示」,在行动前先验证。不盲信自己记住的东西。
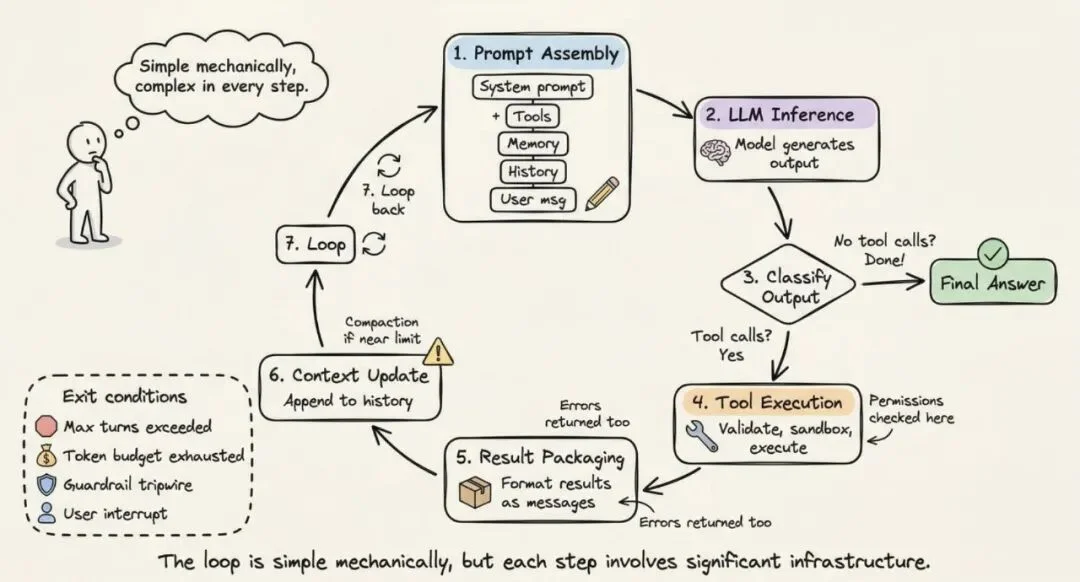
记忆系统的多层结构:短期对话历史、长期文件存储、跨会话持久化
这让我想到一个现实中的类比。人类工程师调试问题的时候,也不会完全依赖记忆——他们会打开之前的笔记、翻 git log、看看上次怎么处理的。好的智能体也应该这样。「我记得这件事」和「让我确认一下这件事」之间,差的是可靠性。
这是很多智能体悄无声息失败的地方。核心问题叫上下文腐烂:当关键内容落在上下文窗口的中间位置时,模型性能下降超过 30%(Chroma 研究数据,斯坦福的「Lost in the Middle」论文佐证)。即使百万 token 窗口也会随着上下文增长而出现指令遵循能力退化。
生产环境的应对策略包括:
压缩——接近上下文上限时总结对话历史。Claude Code 会保留架构决策和未解决的 bug,丢弃冗余的工具输出。观察遮蔽——JetBrains 的 Junie 隐藏旧的工具输出结果,但保留工具调用记录可见。按需检索——只维护轻量标识符,动态加载数据。Claude Code 用 grep、glob 等搜索工具而不是把整个文件加载进来。子智能体委派——每个子智能体可以大量探索,但只返回 1000-2000 token 的精炼摘要。
上下文管理策略:压缩、遮蔽、按需检索、子智能体委派四条路径
Anthropic 的上下文工程指南把目标说得很清楚:找到最小的高信号 token 集合,最大化期望输出的可能性。ACON 研究展示了 26-54% 的 token 缩减,同时保持 95%+ 的准确率——通过优先保留推理轨迹而非原始工具输出。
有一个简单的数学:一个 10 步流程,如果每步成功率是 99%,端到端成功率只有约 90.4%。错误的复合效应极其残酷。
LangGraph 把错误分成四种:瞬态错误(退避重试)、模型可恢复错误(把错误当 ToolMessage 返回,让模型自己调整)、用户可修复错误(中断等人介入)、意外错误(上报调试)。Anthropic 在工具处理器内部捕获失败并作为错误结果返回,保持循环不断运行。Stripe 的生产 Harness 把重试上限设为 2 次。
这让我想起分布式系统的一个老原则:不要假设任何一次调用会成功。区别在于,传统分布式系统的错误是确定性的(超时、网络断开),而智能体的错误是概率性的——模型可能给出语法正确但语义错误的结果。这更难捕捉,也更需要验证循环。
OpenAI 的安全护栏设计也值得一提。它分三层:输入护栏(在第一个智能体上运行)、输出护栏(在最终输出上运行)、工具护栏(在每次工具调用时运行)。还有一个「绊线」机制——一旦触发立即停止智能体。Anthropic 则在架构上把权限执行和模型推理分离:模型决定尝试什么,工具系统决定允许什么。Claude Code 独立控制约 40 个离散的工具能力,经过三个阶段:项目加载时建立信任、每次工具调用前权限检查、高风险操作需要用户明确确认。
这是把玩具 demo 和生产级智能体区分开来的关键。Anthropic 推荐三种验证方式:规则验证(测试、代码检查工具、类型检查器)、视觉验证(通过 Playwright 截屏验证 UI 任务)、模型即裁判(单独的子智能体来评估输出质量)。
Claude Code 的子智能体编排也很有代表性。它支持三种执行模式:Fork(父上下文的完整复制)、Teammate(独立终端窗格,通过文件邮箱通信)、Worktree(自己的 git 工作树,每个智能体一个隔离分支)。OpenAI 的 SDK 支持「智能体即工具」(专家处理有边界的子任务)和「交接」(专家接管全部控制)。LangGraph 则把子智能体实现为嵌套状态图。
Claude Code 的创造者 Boris Cherny 说过:
给模型一种验证自己工作的方式,可以将质量提升 2 到 3 倍。
2 到 3 倍。不是 10% 的边际改善。是翻倍。
脚手架隐喻:Harness 是临时基础设施,模型变强后脚手架可以拆除——但目前还拆不得
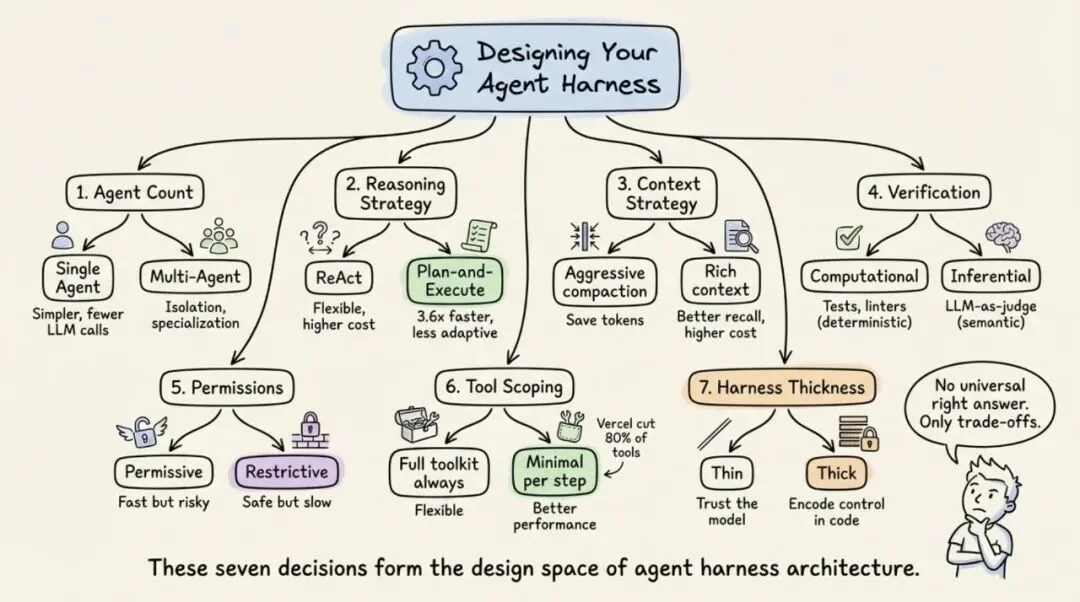
每个 Harness 架构师都要面对七个关键选择。我挑几个最有争议的说:
单智能体 vs 多智能体。Anthropic 和 OpenAI 的建议一致:先把单智能体做到极致。多智能体系统会增加额外的大模型调用开销(路由)和上下文丢失(交接)。只有当工具过载超过约 10 个重叠工具,或者任务领域确实互不相干时,才应该拆分。很多团队一上来就搞「多智能体协作」,其实是在用架构的复杂度掩盖单智能体能力的不足。先让一个智能体真正好用,再考虑分裂。
工具范围策略。这一条反直觉:工具越多,表现往往越差。Vercel 把 v0 的 80% 的工具都砍掉了,结果反而更好。Claude Code 通过延迟加载实现了 95% 的上下文缩减。原则是:只暴露当前步骤需要的最小工具集。
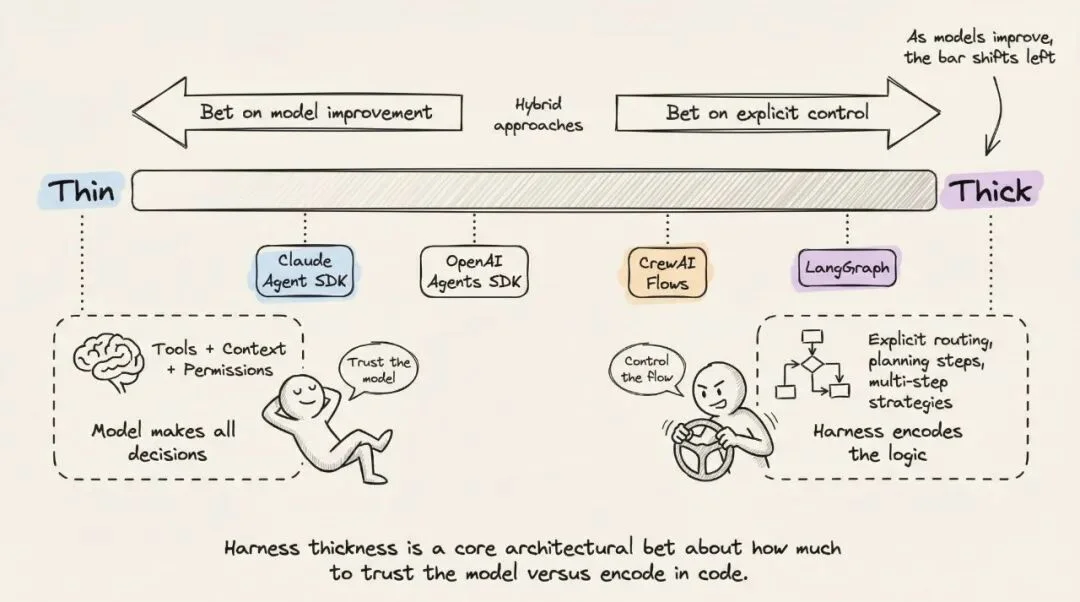
Harness 厚度。多少逻辑放在 Harness 里,多少留给模型?Anthropic 押注薄 Harness + 模型改进——他们会定期从 Claude Code 的 Harness 里删除规划步骤,因为新版模型已经内化了这个能力。图结构框架(如 LangGraph)则押注显式控制。
Harness 架构师面对的七个关键设计抉择
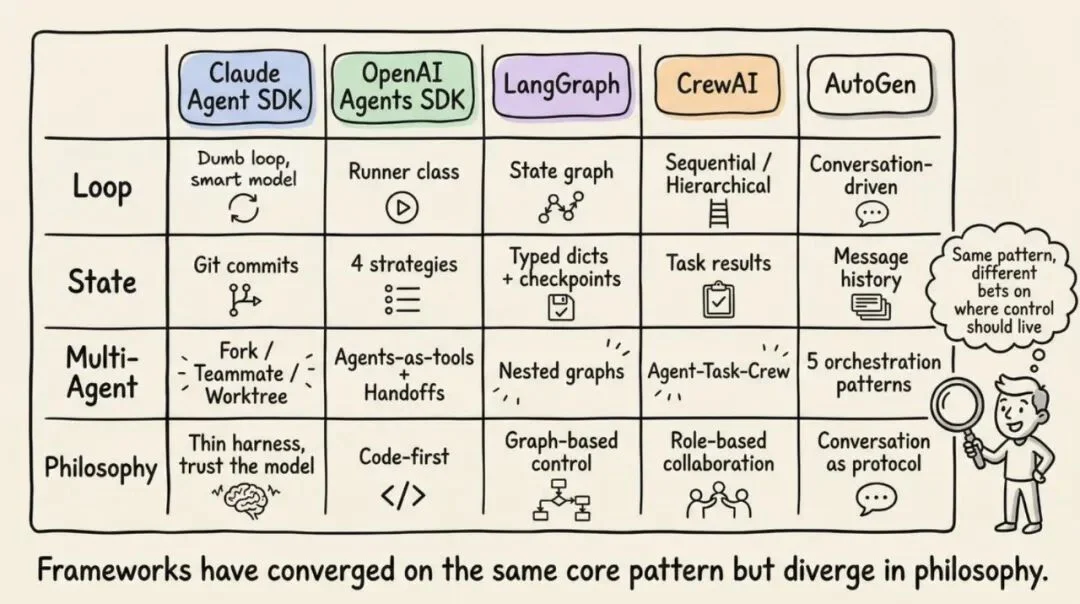
Akshay 把四大框架的实现方式做了横向对比,我整理了一张表:

四大框架如何实现 Harness:从「傻循环」到「显式状态图」,设计哲学截然不同
有意思的是 Codex 团队说的一句话:「Codex 模型在 Codex 的界面上感觉比在通用聊天窗口好用。」因为模型是和这个特定的 Harness 一起后训练的。换一个 Harness,性能就会下降。这暗示了一个深层趋势——模型和 Harness 正在共同进化。
还有一个很重要的观察。LangChain 从 AgentExecutor 进化到 LangGraph,是因为 AgentExecutor 在 v0.2 被弃用了——原因是难以扩展、不支持多智能体。LangChain 的 Deep Agents 明确使用了「Agent Harness」这个术语:内置工具、规划(write_todos 工具)、文件系统做上下文管理、子智能体生成、持久化记忆。这说明行业正在趋向统一的 Harness 概念,尽管实现路径不同。
AutoGen(正在演变为 Microsoft Agent Framework)则开创了对话驱动的编排。它的三层架构(Core、AgentChat、Extensions)支持五种编排模式:顺序、并发(扇出/扇入)、群聊、交接和 Magentic(管理者智能体维护动态任务台账协调专家)。五种模式覆盖了几乎所有的多智能体协作场景。
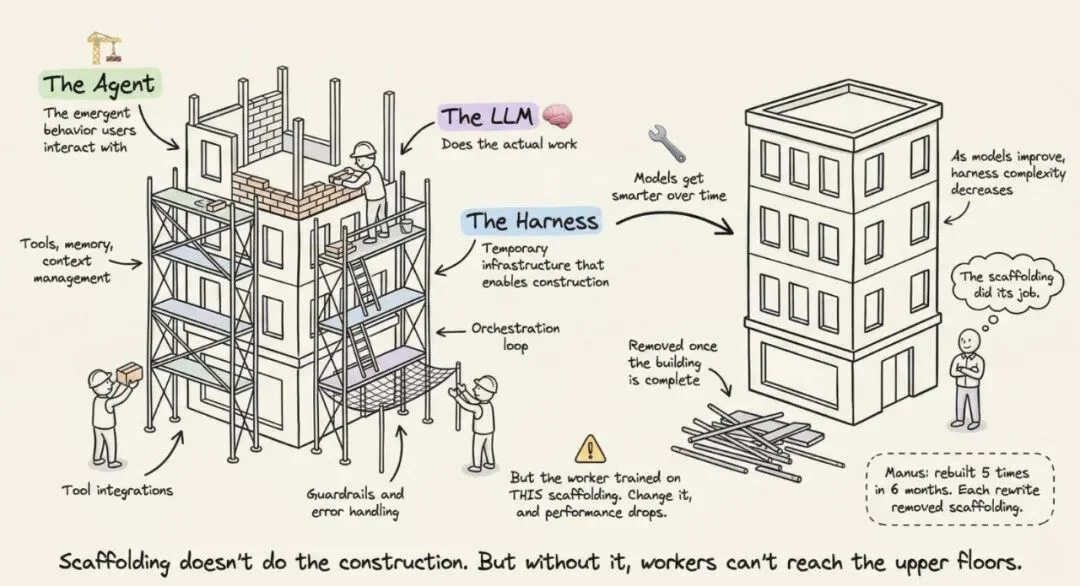
文章里有一个特别精妙的隐喻:Harness 就像建筑工地的脚手架。脚手架不做施工——但没有它,工人够不到高楼层。关键洞察是:脚手架在建筑完工后会被拆除。
这在智能体领域的意思是:随着模型变强,Harness 的复杂度应该降低。Manus 在六个月内重建了五次,每次重写都在删减复杂度——复杂的工具定义变成了通用 shell 执行,「管理智能体」变成了简单的结构化交接。这个节奏本身就说明问题:不是「设计一次,用十年」,而是「模型每升级一代,Harness 就要瘦身一轮」。
这里存在一个「共同进化原则」:模型现在是带着特定 Harness 做后训练的。Claude Code 的模型学会了使用它训练时的特定 Harness。更换工具实现可能会降低性能,因为这种紧密耦合。这对开发者来说意味着什么?选择 Harness 就是选择了生态。
Harness 设计的「未来验证测试」:如果换上更强的模型后,性能自动提升而不需要增加 Harness 复杂度——那你的设计就是好的。
我自己这段时间也在密集使用各种智能体编程工具,体感和这篇文章的结论完全一致。模型能力已经够用了——Claude Opus、GPT-4.1、Gemini Pro,在模型层面差距越来越小。真正拉开体验差距的,就是 Harness。同一个模型,放在不同的 Harness 里,表现可以天差地别。
几个关键启示:
1. Harness 才是产品。两个用相同模型的产品,可以因为 Harness 设计不同而表现天差地别。TerminalBench 的数据很说明问题:仅靠 Harness 优化就能跳 20+ 名。对于做 AI 产品的团队来说,把 80% 的精力放在 Harness 上可能比换模型更有效。
2. 少即是多。Vercel 砍掉 80% 工具反而更好。Manus 每次重建都在删减。这和软件工程的直觉一致——最好的代码是你不需要写的代码。最好的 Harness 是让模型自己解决问题的 Harness。
3. 模型和 Harness 在共同进化。Claude 的模型是和 Claude Code 的 Harness 一起训练的。换 Harness 等于换了模型的运行环境。这意味着未来的竞争不只是模型之战,也不只是应用之战,而是「模型 + Harness」组合的系统之战。
原文最后一句说得好:下次你的智能体失败了,别怪模型。看看 Harness。
我补一句:如果你做的 AI 产品还在比谁调的模型更贵更强,方向可能已经偏了。真正的差距在模型外面。
行业正在走向更薄的 Harness。但 Harness 本身不会消失。即使最强的模型也需要有东西来管理它的上下文窗口、执行它的工具调用、持久化它的状态、验证它的工作。这些不是「暂时需要」的功能,而是智能体系统的结构性需求。就像操作系统不会因为 CPU 变快而消失一样。
相关链接:
• 原文:https://x.com/akshay_pachaar/status/2041146899319971922
文章来自于"深思SenseAI",作者 "深思SenseAI"。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
