# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
具身智能,正在进入一个新的叙事阶段。
一个越来越清晰的现实正在浮现:只靠真机遥操作数据,未必能把机器人真正送进大规模场景。
原因不难理解。数据贵,采得慢,节拍还往往不够真实。实验室里能跑通的 demo,到了工厂、仓储和零售现场,常常会被速度、成本和稳定性重新审视。真正决定下一阶段竞争的,已经不只是 “谁能做出一个演示”,而是谁能先把真实世界里的人类操作经验,规模化地转成机器人可学习、可迭代、可部署的能力。
4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?
表面看,这是一场新品发布;但更深一层看,它更像一次方法论发布:当具身智能没有互联网式的数据红利时,下一步到底该靠什么继续往前走。

当真机数据不再够用
具身智能为什么转向 “人类数据”
先看这次到底发布了什么。
模型侧,是 Psi-R2 和 Psi-W0。数据侧,是总规模近 10 万小时的人类操作数据,以及首批开源的 1000 小时数据。这 1000 小时数据,被作为当前行业最大开源的人类手部操作全模态数据集之一来推出。
更具体地看,这套体系中包含 5417 小时真机数据,来自灵初自研的 MobiDex 数采平台;人类数据则达到 95472 小时,覆盖多场景、多任务、多物体。这也是少数明确把近 10 万小时量级人类数据系统性用于机器人预训练的模型方案。
为什么是 “人类数据”?
因为具身智能和大语言模型、自动驾驶不一样。它没有互联网式的海量现成数据,也很难在商业运行中自然沉淀出足够规模的高质量训练样本。数据从哪里来,已经成了这个行业最核心的问题之一。
而人类每天都在真实环境里,用双手完成高频、连续、精细的操作。这些数据天然贴近机器人未来要面对的工作世界。它们发生在真实任务中,带着真实节拍,也带着真实的操作细节。从落地角度看,这类数据的价值远不只是 “多了一种数据源” 那么简单。
但 Human Data 并不是采得多就够了。
它最大的难点,首先是 embodiment gap,也就是人手和机械手在运动学、动力学上的天然差异。其次是精度问题。很多人类操作数据来自第一视角视频,轨迹恢复往往只有厘米级精度;一旦进入手机装配这类亚毫米级任务,这种误差就会被迅速放大。
为了解决这个问题,灵初自研了外骨骼触觉手套和高精度感知硬件,把人手 3D 轨迹采集推到更高精度。另一部分裸手数据,精度没那么高,但规模更大,主要负责提供泛化能力。
换句话说,灵初并不是简单把 “人类数据” 当作替代真机数据的便宜选项,而是在试图建立一套分层的数据结构:高精度数据负责上限,大规模数据负责泛化,两者一起为机器人训练提供新的底座。
一套系统
比单个模型更关键
更有意思的是,灵初最后并没有走一条特别 “花哨” 的对齐路线。
他们尝试过图像修补、关键点辅助 loss、特征空间对齐等做法,想把人类数据尽可能修成更像机器人数据的样子。但最后发现,数据量小的时候这些方法有帮助;数据量一旦上来,它们反而会变成瓶颈。
原因并不复杂。那些方法本质上都在努力模糊人和机器人的差异,但在长程、精细、接触密集的任务里,这种差异恰恰不能被轻易抹平。越是复杂和精细的任务,越需要承认两种 embodiment 的真实不同。强行 “抹平” 之后,模型反而更容易在关键动作上犯错。
所以,灵初最后选了一条更朴素的路:只做必要的输入输出维度对齐,把人类关节通过运动学映射到机器人关节,图像尽量不做处理,直接把原始数据喂给模型。它给这条路线的总结也很直白:raw data in, raw data out。
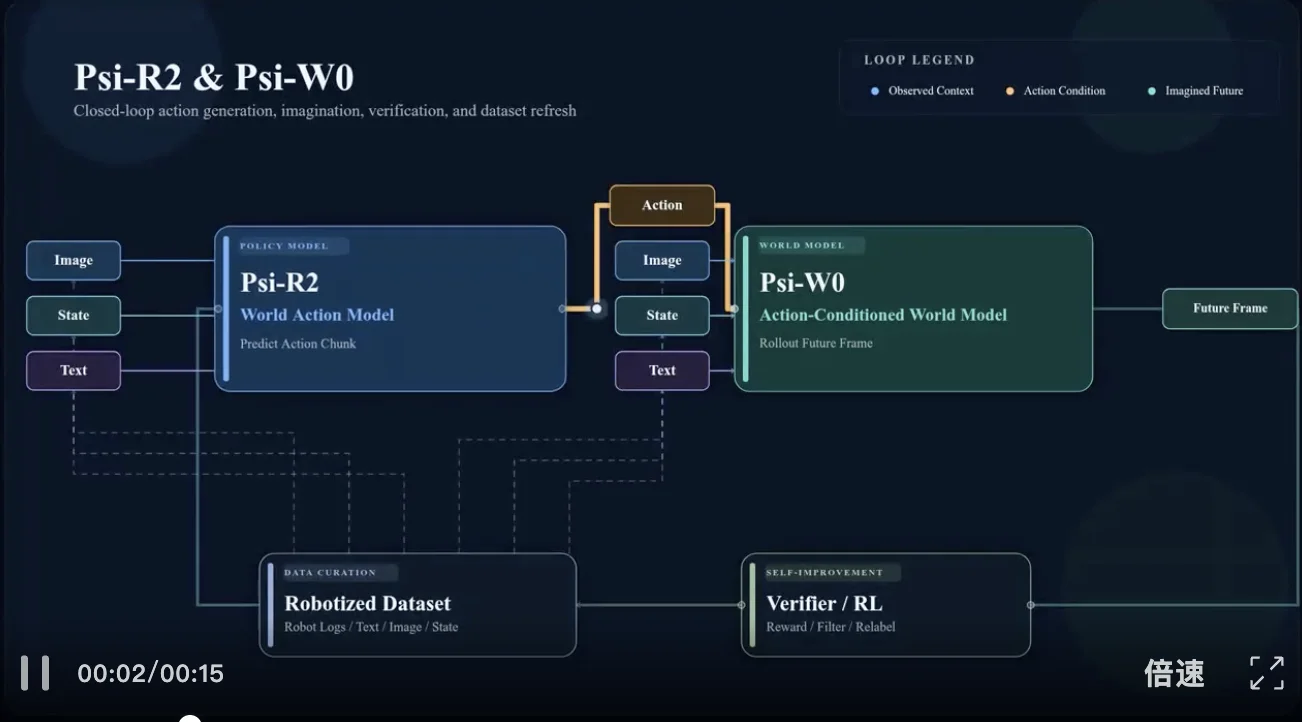
在这套方法里,Psi-R2 负责 “先学会怎么做”。
它的输入是图像和语言,输出同时包括未来视频和机器人动作。也就是说,它不是只学下一步动作,而是在同时学习 “接下来世界会怎样变化”。这套设计建立在预训练视频生成模型之上,目标是把大规模人类数据里的任务知识,尽可能装进策略模型。
在大规模预训练之后,Psi-R2 仅需少于 100 条真机轨迹微调,就能完成手机装配、工业包装、叠纸盒等长程、精细任务。

但只学成功动作,还不够。
因为成功示范只能告诉模型 “应该怎么做”,却不能告诉它 “换一种做法,会在哪一步失败”。而这恰恰是强化学习最需要的信息。
这也是 Psi-W0 的位置。
它接收图像、语言和机器人动作轨迹,去预测未来视频。相比 Psi-R2,Psi-W0 多了一项关键职责:建模失败、建模反事实、建模试错空间。为此,Psi-W0 的训练中额外加入了约 30% 的失败数据。
换句话说,Psi-W0 不只是一个 “会预测” 的模型,它更像一个可以用来评估和打磨策略的训练场。Psi-R2 先从人类数据里学到任务知识,再把轨迹送进 Psi-W0 做 rollout;随后在机器人动力学约束下,通过强化学习做小步修正,把 “人类会做” 的轨迹改造成 “机器人也能做” 的轨迹。好的轨迹回流训练集,坏的轨迹帮助世界模型继续变准,飞轮就这样转起来。
这也是这次发布最值得注意的地方:真正起作用的,不是某一个单点模型,而是 Psi-R2、Psi-W0 与强化学习 的系统协同。
围绕 Human Data,灵初也给出了一组很值得行业参考的判断:对数据分布来说,任务多样性 > 物体多样性 >> 场景多样性;对模态价值来说,精准 3D 位姿 > 触觉 > 2D 图像特征。
翻译成更直白的话就是:背景是不是足够复杂,未必最重要;真正决定模型上限的,是它见过多少任务、碰过多少物体,以及它是否真正理解了接触和操作细节。
也因此,灵初把触觉看成一种跨具身的 “通用语言”。人手和机械手的结构可以不同,但 “碰到了没有”“接触是怎样发生的” 这类物理信号,本质上是相通的。
从论文到现场
落地还要跨过部署关
如果说前面解决的是 “技术上行不行”,那商业化真正关心的,始终是 “这条路值不值得走”。
答案很明确:值得,而且必须走。
原因很简单。实验室里,动作慢一点、路径绕一点,很多 demo 依然可以做出来;但到了工厂、仓储和零售现场,节拍、成本和稳定性会重新定义一切。真实作业里,一个动作多一步、一拍慢一点,最后都会落到良率和成本上。
从这个角度看,最有价值的数据,往往不是实验室里的遥操作演示,而是一线工人的真实作业数据。
一方面,人类数据采集可以更便宜,其成本被压到了传统真机遥操作方案的十分之一以下。另一方面,它的节拍更真实,更贴近业务现场的 SOP 和速度要求。
工程侧的进展,则让这件事离落地又近了一步。
通过 DiT Caching、Torch Compile、量化等优化,单次推理时间已从 2.2 秒压到 100 毫秒以内。对于连续、灵巧、顺滑的操作来说,这已经不是 “优化得不错”,而是能不能真正进场部署的一道门槛。
外部基准,也给了这套方法一个注脚。
截至发稿,公开榜单页面显示,在 MolmoSpaces Combined 榜单、且不使用 MolmoBot Data 的分组中,Psi-R2 以 46.4 的 Oracle Success Rate 排名第一,并覆盖 4 个任务。
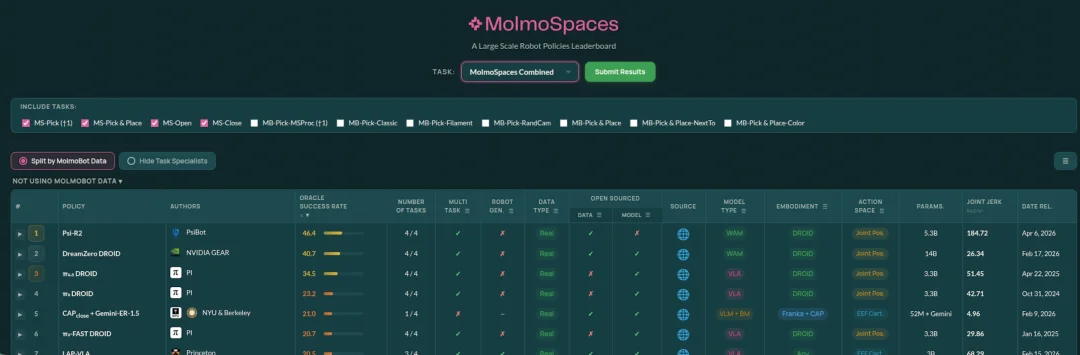
MolmoSpace 由美国艾伦人工智能研究所(AllenAI)发起,是全球具身智能领域权威基准评测平台,NVIDIA、PI 等全球顶尖团队均参与本次评测。灵初 Psi-R2 在评测中超越 PI、DreamZero 等国际知名模型,表现显著优于其他基线模型,成功率大幅领先同类 VLA 产品,充分体现出企业自主研发路线的先进性与竞争力。
这个细节的价值,不只是 “上榜”。更重要的是,它说明这套方法,正在进入一个公开、可比较的评价环境里接受检验。
把这些信息放在一起看,这次发布的重点并不只是 “又发了一个模型”,也不只是 “又开源了一批数据”。
它更像是在对外释放一个判断:
第一,具身智能的瓶颈是数据,而人类数据不是旁路,而是主线。
第二,真正能把人类经验转成机器人能力的,不是单个模型,而是 Psi-R2、Psi-W0 和强化学习共同构成的系统。
第三,所有技术问题的终点都不是论文,而是落地:节拍、成本、推理速度、数据飞轮能不能真正转起来,才是最后的检验标准。
如果这套路线最终走通,这次开源的意义,就不只是 “放出一个模型,开放一批数据”。

它更像是在告诉行业:具身智能真正的分水岭,也许已经不再是谁先做出更惊艳的 demo,而是谁能先把 Human Data、世界模型和强化学习 连成一条持续运转的增长曲线。
从这个意义上说,这次想发布的,也许不只是一个新产品。
而是一个新阶段。
文章来自于微信公众号 "机器之心",作者 "机器之心"



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
