# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

相信大家都能感觉到,进入2月以来,“上下文工程”、“Vibe Coding”的热度已经让位给了一个新名词:"harness engineering"。
而将这一名字带火的,正是OpenAI Frontier团队的核心工程师Ryan Lopopolo。
他最近发表了一篇长文,成为了热门话题,堪称“harness 工程”的定义之作。

在这篇文章中,Ryan揭示了新成立的OpenAI Frontier团队已经成为OpenAI最大的Codex用户。整个团队最开始只有3个人,历经5个月的极端实验,最后可以运行着100万行代码的代码库,其中零行是人类编写的代码。
同时,更让"黑暗工厂"粉丝们着迷的是,整个代码库在合并之前,完全没有人类审查代码。
那么,OpenAI Frontier团队究竟是如何通过"Harness工程"实现的0手工代码的呢?
就在昨天,Ryan终于出来深度爆料OpenAI这个神秘项目了!
在昨天最新一期的Latent Space播客访谈中,Ryan表示,实现这个“幽灵库”Symphony的核心秘诀,就在于:当AI失败时,不要上来就想着改进提示词,而是问:缺少什么能力、上下文或结构?
因此,最后的结果就是,这个“幽灵库”本身不包含任何实际代码,但却提供了让AI agent自主生成100万行代码所需的所有上下文、规范和工作流。这种思维转变让他们将开发速度提升了10倍,甚至团队都可以不再审查代码,AI写完就可以直接合并了。
当然,播客中还详细讨论了这个幽灵库的七层架构设计。感兴趣的朋友可以向下翻看。这里不再赘述。值得关注的是,Ryan个人对MCP持悲观态度:它已经死了!
因为它会强制往上下文里注入大量 token,还会影响自动压缩(autocompaction),甚至 agent 可能忘记怎么用这些工具。
此外,Ryan作为OpenAI最新成立的团队的核心工程师,还给出了不少对于未来软件严谨的判断。
首先,Ryan认为,未来的软件必须首先对Agent可读。“如果软件充满了隐性上下文,Agent 就无法有效工作。”
那怎么判断这种可读性呢?
Ryan透露到,为了追求极致的内循环速度,Ryan的团队强行实施了“一分钟构建纪律”。如果构建时间超过一分钟,他们就会介入重构,以确保 Agent 的反馈回路足够短。在这种模式下,代码变得高度模块化、可观测且“token 高效”。
而这也意味着,原有的软件开发范式中的许多环节和名词都发生变化。比如,Ryan指出,开源软件的依赖可能会消失。因为在他看来,几千行代码的中低等复杂度软件,已经完全可以让AI来重写,被模型内化。
再比如,我们原来定义的软件BUG也会重新定义。Agent 时代之下,“BUG就是agent编写的、由于某个尚未写下来的非功能性需求而不一致的代码。"
再比如,传统的MVC模式也重新发生了定义,AI 原生版本是 Model-View-Claw——Claw 就是 harness。
其次,值得一提的是,OpenAI这种“AI 原生”的开发过程也充满着“幽默感”。
Ryan爆料,“幽默是AGI的一部分。”他们甚至会教Agent理解公司文化,包括生成梗图、和Slack互动等等。在他们看来,幽默感是智能的重要测试指标,而最新的5.4模型在“玩梗”方面,已经表现得很惊人了。
另一个相信大家跟小编一样好奇的是,OpenAI这个新团队Frontier究竟想干嘛?OpenAI这是要往toB赛道上重仓了吗?
Ryan也很坦诚地将这个团队的“阳谋”分享了出来。Ryan表示,Frontier最终的愿景是:帮助企业安全、大规模地部署 Agent。而这个产品本质是一个“分发Spec”的系统,既能介入企业IM、又能集成安全工具、又能接入工作流工具。
Ryan还透露,Codex应用的周活跃用户已经突破了200万,并正在以每周25% 的速度增长。这一数字,也能看出OpenAI想要在ToB赛道上转变为一个真正赋能全球企业的AI原生平台的野心。
此外,主持人还观察到了OpenAI的一个重要扩张信号:"去旧金山中心化"。Ryan对此解释到,OpenAI的确正在扩张到西雅图、纽约、伦敦。"我认识有人因为不想搬去旧金山而拒绝了OpenAI的工作,"Ryan调侃到,"现在他们别无选择了。"
而Ryan自己也正是是西雅图办公室的首批工程招聘之一,那里有"madmen风格的办公室氛围",而贝尔维尤的新办公室则是"非常绿,金色装置,非常太平洋西北"。
很明显,这个新设立的西雅图贝尔维尤办公室正成为OpenAI这一toB愿景的重要支点。
另外,还值得一提的是,现在Ryan表示自己对于目前这种“harness工程”已经上瘾了。他承认自己已经喂Agent喂到不可自拔了,甚至在飞机上半扣上笔记本电脑写代码。
"很难停止戳机器,因为它让我想喂它。这种持续反馈循环,看着AI自主工作、不断生成代码,似乎有一种特殊的吸引力。”
Ryan甚至给出了一个惊人的数字:团队每天使用10亿个token(约合2000-3000美元)。他说,如果你不这样做,就是"疏忽"。吝啬token,就是吝啬效率。
篇幅关系,这里不再一一展开了,整体感受,又是一场阿尔法含量超标的分享。
以下是小编梳理的精彩观点。
主持人:
好,现在进入正题。我们现在在录音棚里,和来自 OpenAI 的 Ryan Lopopolo 一起。欢迎你。谢谢你来旧金山,也谢谢你抽时间参与我们节目。你写了一篇关于 harness engineering 的爆款文章,很可能会成为这个新兴领域的定义性作品。
Ryan Lopopolo:谢谢,这件事其实挺有意思的——在某种程度上感觉我们定义了这个领域的讨论方式。
主持人:我们先补充一点背景信息。这是你第一次上播客,对吧?那能不能讲讲你的背景?你在哪个团队?大概做什么?
Ryan Lopopolo:我在 OpenAI 的 Frontier 团队,主要做前沿产品探索和新产品开发。Frontier 是一个企业平台,核心是让 agent 能在企业中安全、大规模地部署,并具备良好的治理能力。我和团队的职责是,探索如何把模型打包成产品,并以解决方案的形式卖给企业客户。
主持人:我补充一下你的履历:Snowflake、Stripe、Citadel,对吧?
Ryan Lopopolo:对,基本都是同一类客户。
主持人:但我一开始其实没想到你是这个背景。我看你 Twitter 的时候,感觉完全相反——全是那种“全力以赴 AI coding”的风格,比如把电脑绑在 Waymo 上之类的内容。然后再看你的履历,就发现你在传统企业环境里也非常“正经”。是一个很有意思的组合。
Ryan Lopopolo:哈哈,做一个“AI 最大化主义者”其实挺有趣的。如果你要活成这种人设,那 OpenAI 是最适合的地方。而且内部没有速率限制,我可以像你说的那样“全力冲刺”。
主持人:所以你是在 Frontier 团队里的一个“特种小组”。
Ryan Lopopolo:对,我们被给予了一定的自由空间去尝试,这也是为什么我一开始设定了一个比较极端的约束:完全不自己写代码。我的想法是,如果我们要构建可以部署到企业里的 agent,那它们就应该能完成我能做的所有事情。在过去 6到8个月里使用这些 coding 模型和 harness,我确实觉得模型能力已经足够,harness 也足够成熟,在能力上几乎和我是同构的。所以我从“不写代码”这个约束出发,逼自己必须通过 agent 来完成工作。
主持人:简单说一下背景,这其实就是你那篇文章的核心内容:你们花了5个月开发一个内部工具,自己写的代码是0行,但最终代码库超过100万行,而且你说效率比人工快了10倍。
Ryan Lopopolo:对,这基本就是当时的思路。一开始我们用的是很早期的 Codex CLI 和 Codeex mini 模型,那时候模型能力比现在弱很多。但这反而是个好约束。当你让模型帮你实现一个功能,它却拼不起来的时候,这种挫败感非常真实。于是我们形成了一个方法论:当模型做不了的时候,就把任务拆开,构建更小的模块,然后再组合成大的目标。说实话,最开始的一个半月效率非常低,大概是我手写代码的10倍慢。但正是因为付出了这个成本,我们最终构建出了一个“装配线”,让 agent 能完成整套开发流程,效率超过任何一个工程师。
后来我们经历了 GPT-5.1、5.2、5.3、5.4 等多个模型版本,每一代模型的行为方式都不同,我们也不得不调整代码库来适配模型的变化。比如一个很有意思的点是:在 5.2 时,Codex harness 还没有后台 shell,所以我们可以依赖阻塞脚本来执行长任务。但到了 5.3,有了后台 shell,模型反而变得更不“耐心”,不愿意等待阻塞任务。所以我们不得不重构整个构建系统,把构建时间压缩到1分钟以内。在一个多人协作、有各种意见的代码库里,这几乎是不可能的。但因为我们的唯一目标是让 agent 高效运行,我们在一周内从 Makefile 切换到 Bazel,再到 Turbo,再到 NX,最终停在 NX,因为构建速度已经足够快。
主持人:你从 Turbo 切到 NX,这很有意思,很多人是反过来的。
Ryan Lopopolo:老实说,我对前端仓库架构经验不多。你可以跟 Josh 聊这个,他才是搭这个系统的人。我认识 NX 团队,也了解 Turbo(来自 Jared Palmer),所以对比很有意思。但我们的核心目标其实很简单:让构建变快。我们的应用是一个 React + Electron 的单体应用,要求构建时间必须控制在1分钟以内。
主持人:我对“后台 shell”其实不太熟。
Ryan Lopopolo:简单说,就是 Codex 可以在后台启动任务,然后继续做其他事情,比如一边跑构建,一边审查代码。这可以提高整体时间效率。
主持人:那为什么一定是1分钟,而不是5分钟?
Ryan Lopopolo:我们希望内部循环(inner loop)尽可能快,1分钟只是一个好记的目标,而且我们能做到。如果超过这个时间,我们就把它当作信号:说明需要停下来,把任务拆分,优化构建图,再让 agent 继续工作。
主持人:听起来像一种“棘轮机制”,你在强制构建时间纪律,否则它就会不断膨胀。
Ryan Lopopolo:没错。传统平台团队的做法是:允许构建时间慢慢变长,直到不可接受,再花几周时间优化。但现在 token 很便宜,模型又高度并行,我们可以持续“修剪”系统,保持这些不变量。这让代码库更加稳定、可控,也让我们在开发过程中可以依赖更多确定性。
主持人:你在文章里提到,人类反而成了瓶颈。一开始你们团队只有三个人。你们产出了接近百万行代码、1500个 PR,这背后的思路是什么?
代码本身某种程度上是“可丢弃”的,但你们又做了大量 review。你在文章里提到,要把一切都“prompt 化”,凡是 agent 看不到的东西基本都是垃圾,不应该存在。所以整体来说,你们是怎么构建这个系统的?以及在人类成为瓶颈之后,人类还如何参与,比如 PR review 这一层是怎么做的?
Ryan Lopopolo:其实我们已经不太依赖“人类做代码评审”这件事了。现在大多数的人类评审发生在 merge 之后。甚至说,merge 本身也谈不上是评审,更像是一种让自己“安心”的仪式。从根本上讲,模型是可以无限并行的,只要我愿意投入 GPU 和 token,它就可以无限扩展产能。
唯一真正稀缺的资源,是团队中人类的同步注意力。一天就那么多小时,我们要吃饭,也想睡觉,虽然很难停下来不去“逗这台机器”,因为你会忍不住想继续喂它。
所以你必须退一步,用系统思维去看:agent 在哪里犯错?我时间花在哪?如何以后不再花这些时间?然后把这些经验沉淀为自动化,等于你解决了 SDLC 的一部分问题。
一开始,我们不得不非常仔细地看代码,因为 agent 还没有足够好的“构建模块”,无法生成模块化、可拆解、可靠、可观测的系统,更不用说还能产出一个真正能工作的前端。为了避免整天坐在终端前、一次只能处理一两个问题,我们投入大量精力去提升模型的“可观测性”,也就是你在文章里看到的那张图。
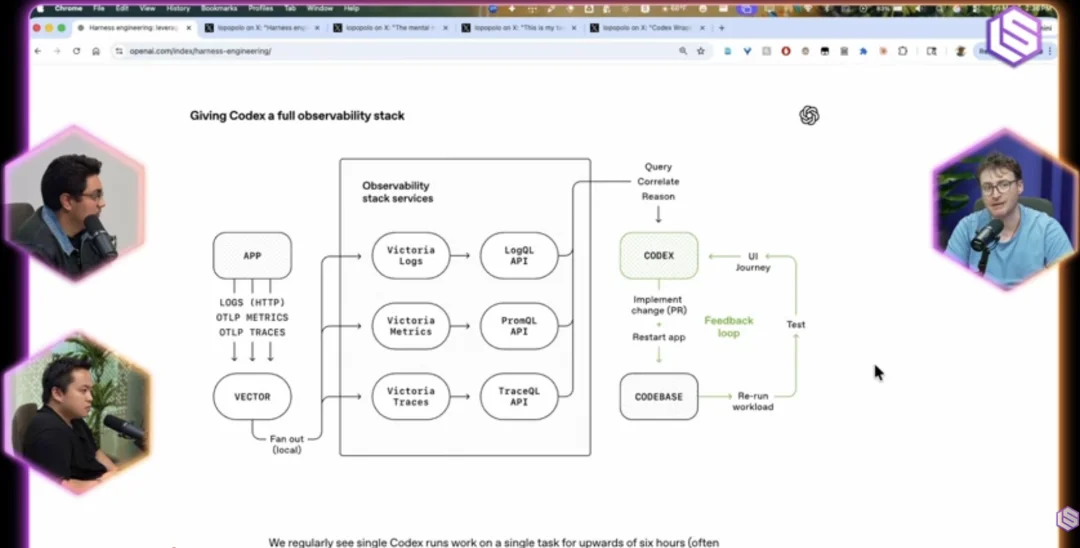
主持人:我们来讲讲这个 tracing 系统,是先有 trace 还是先有应用?
Ryan Lopopolo:一开始只有应用,后面从 vector 到登录、指标、API 这些东西,大概花了我半个下午就搭起来了。我们刻意选择了一些高层、开发效率很高的工具,现在生态已经很好了。比如我们大量使用一个叫 MI 的工具,可以很轻松地把 VictoriaMetrics 这一整套 Go 写的组件拉到本地开发环境里。再加一点 Python glue code 把这些服务跑起来,就可以用了。有个很关键的设计是,我们尽量“反转”整个系统:不是先搭好环境再把 agent 放进去,而是以 agent 作为入口——直接启动 Codex,然后通过 skills 和脚本,让它在需要时自己启动整套开发环境,并配置环境变量,让本地应用指向它自己拉起的服务。
我觉得这正是现在的 reasoning 模型和过去 4.1、4o 时代模型的根本区别。以前的模型不会“思考”,你必须把它们关在一个有明确状态机的盒子里;而现在,我们让模型和 harness 成为整个系统本身,给它足够的选项和上下文,让它自己做决策。
主持人:听起来很多东西都在往“scaffold(脚手架)”方向演进。但有意思的是,有了 reasoning 模型之后,好像反而不需要那么重的 scaffold 了。你们用了像 spec.md、很短的 agent.md 这种结构。
Ryan Lopopolo:对,我们确实定义了一套结构,比如一个总的目录(大概100行),下面是各种“skills”。这种结构的好处是,可以非常低成本地往代码库里注入新内容,同时引导人类和 agent 的行为。
主持人:某种意义上,你们是从零开始“重新发明了 agent skills”。
Ryan Lopopolo:确实如此,因为我们开始的时候这个概念还不存在。我们有一个总的目录文件,然后是各种小的 skills,比如 core beliefs.md、tech debt tracker 等。
其中 tech debt tracker 和 quality score 很有意思,它们本质上是一个极简的 scaffold——一个 markdown 表格,作为 Codex 的钩子。它会去检查我们定义的业务逻辑,评估是否符合既定的 guardrails,然后给自己生成后续任务。在有 Jira 之类系统之前,我们其实只是把这些后续工作记录在 markdown 里,然后可以定时启动一个 agent 去“清债”。
这里有个很关键的洞察:模型“渴望文本”。我们做的很多事情,本质上是在往系统里注入更多文本。比如某次线上报警,是因为缺少 timeout,我可以直接在 Slack 里 @Codex,说“我要加一个 timeout,同时请更新我们的可靠性文档,要求所有网络请求必须有 timeout”。这样我不仅修了一个 bug,还把“什么是好的实践”永久编码进系统里。这个知识会随着上下文传递给后续的 coding agent。
你还可以基于这些文本生成测试,或者驱动 code review agent,从而缩小代码的“可接受空间”。
主持人:但这里有个问题:你以为你在做一个“长期正确”的规则,但其实可能忽略了例外情况,后面还得回滚。
Ryan Lopopolo:确实,模型有时会“过度服从”。所以我们在设计上给它一定的判断空间。比如 quality score 这种工具,不是每次都强制执行,而是由模型自己决定何时调用。
在 prompt 层面,我们也允许 agent“反驳”。一开始我们引入 code review agent 时,流程是:Codex 本地生成代码→推 PR→触发 review agent→它写评论→我们要求 Codex 必须回应这些评论。最初的问题是,写代码的 agent 太“听话”,被 reviewer“带着走”,导致系统不收敛。所以后来我们调整了双方的 prompt:review agent 被要求偏向通过(只提不高于 P2 的问题);而 P0 是会毁掉整个代码库的级别。与此同时,我们也允许写代码的 agent 拒绝或延后处理 review 意见。现实中也是这样——有些 review 只是 FYI,不是要求立刻修复。如果不给这种语境,agent 就会机械地执行所有指令。
主持人:我想确认一个点:这些 agent 可以自动 merge,对吧?这其实很多人不太能接受。而且你列的范围几乎是全栈——产品代码、测试、CI、发布工具、内部工具、文档、review 评论、甚至管理仓库的脚本,全都是 agent 在写。
Ryan Lopopolo:是的,基本上全部都是。而且它们是并行运行的。
主持人:那有没有一个“紧急刹车”?比如团队里谁可以一键停掉一切?
Ryan Lopopolo:因为我们做的是原生应用,而不是基础设施,所以我们没有做持续部署。发布分支的切割还是需要人类参与,而且上线前必须经过人工批准的 smoke test。换句话说,在发布环节还是有人类把关。
主持人:所以你们不是在做那种要求“99.999% 可用性”的基础设施系统。
Ryan Lopopolo:对,是这样的。而且要强调一点:这一切都是在一个“全新仓库”里完成的。这不意味着它可以直接套用到所有生产环境中。
主持人:最开始 onboarding 的一个月基本是在“倒着工作”,你得不断适应系统;但现在你已经非常自动化了。我很好奇:现在人类在 loop 里还占多大比重?还有哪些瓶颈是你希望能继续自动化的?以及你觉得模型能力接下来会怎么发展,进一步替代人类?比如我们刚刚有了 GPT-5.4,这是个非常强的模型。
Ryan Lopopolo:是的,这是第一个把顶级 coding 能力和推理能力融合在一起的模型——既有 Codex 级别的代码能力,也有通用推理能力,还支持 computer use。现在我甚至可以直接让 Codex 写博客了,而之前我还得在 chat 和 coding 之间切换……说不定我都要失业了(笑)。
主持人:你这话让我突然想到,可以用 5.4 做一个完全 AI 驱动的 newsletter。
Ryan Lopopolo:对,这其实就是“闭环”的一个例子。比如你刚提到的 dashboard,我们让 Codex 去写 Grafana dashboard 的 JSON、发布它们、同时响应报警。也就是说,当报警触发时,它知道具体是哪个 dashboard、哪个 alert、对应代码库里的哪一条日志,因为这些信息都被统一汇总了。
主持人:也就是说,它必须“拥有一切”。
Ryan Lopopolo:没错,这一点非常关键。这意味着如果发生了一次没有触发报警的故障,它也可以基于现有的 dashboard、metrics 和日志,找出监控体系的缺口,并一次性修复。就像一个全栈工程师可以从后端一路把功能推到前端一样。
主持人:听起来你们做的大量工作,其实是让软件更符合“模型的写作方式”,而不是“人类的可读性”。也就是从 human-legible 转向 agent-legible。这对更大规模的团队意味着什么?比如在 OpenAI 内部,或者整个软件工程行业——是不是意味着大家都要切换?毕竟这是一个非常激进的变化。
Ryan Lopopolo:我的心态其实是:我已经从具体执行中“抽离”出来了。我不会对代码的细节有太多意见,更像是在管理一个500人的团队——这种情况下,你不可能逐个 PR 深入细节。所以我们用 post-merge review 作为一个类比:我只抽样看一些代码,从中推断团队的问题、瓶颈、哪里需要支持、哪里已经很顺畅,然后调整我的关注重点。
我对“代码具体怎么写”没有太多执念,但我非常关注“系统原语”。比如我们有一个 command-based class,用来封装可复用的业务逻辑,同时自带 tracing、metrics、可观测性。这类原语才是关键——只要代码使用了这些原语,就天然具备杠杆效应。所以重点不是代码结构,而是是否使用了正确的抽象。
主持人:这又回到你文章里的系统思维,比如如何强制架构、如何编码“工程品味”。
Ryan Lopopolo:是的。而且随着模型能力提升,它们也越来越擅长提出抽象,帮助自己解锁问题。这让我可以站得更高,去思考真正阻碍团队交付的是什么。
主持人:你这个项目本质上是一个百万行代码的 Electron 应用,同时还管理自己的服务,有点像 BFF(backend for frontend)。
Ryan Lopopolo:对,我们确实有后端,但部署在云上。而在 Electron 内部,本身就有 main 和 renderer 两个进程,这天然形成了类似 MVC 的结构,我们也用同样严格的方式去做分层。
顺便说个有趣的梗:传统 MVC 是 Model-View-Controller,而我觉得 AI 原生版本是 Model-View-Claw——Claw 就是 harness。
主持人:这个说法挺妙的。
Ryan Lopopolo:我确实觉得 Codex + harness 作为 AI 产品构建方式,还有很大的探索空间。现在模型在 coding 上的进步非常快,每一代都显著提升任务复杂度。如果你能把产品问题“压缩”为代码问题,那么用 Codex harness 去解决就非常自然——它已经帮你完成所有基础设施,你只需要用 prompt 驱动它。
而且这是一种对工程师来说非常“可理解”的能力扩展方式:你只需要把你原本就会写的那些脚本交给模型。
主持人:换句话说,coding agent 不只是写代码,它会“吞噬”所有知识工作。很多人以为非编码任务需要单独的 agent,但其实你是从 coding agent 往上扩展。
Ryan Lopopolo:对,本质上你只需要把任务定义成代码问题,一切都是 coding agent。
主持人:那我再问一个现实问题:像 ticket 系统、PR 这种机制,是不是要被彻底重构?因为 Git 本身对多 agent 是非常不友好的。
Ryan Lopopolo:我们大量使用 worktree,但即便如此,merge conflict 仍然存在。不过模型其实非常擅长解决冲突。而且当我不再同步地盯着终端时,这些冲突对我来说几乎是“可忽略的”。
我们有一个叫 “dollar land” 的 skill,会指导 Codex 完整处理 PR 生命周期:创建 PR、等待人类和 agent review、等待 CI 通过、修复 flaky、处理冲突、重新合并、进入 merge queue,直到进入主分支。这就是“完全委托”的含义。对人类来说,这是一套非常重的流程,但 agent 完全可以处理,我基本只需要把电脑开着。
以前我控制欲很强,但现在我反而觉得:它在很多事情上确实比我做得更好——前提是给它足够的上下文。
主持人:还有什么是你觉得文章里没讲清楚,但大家在讨论的?
Ryan Lopopolo:有一点我可能没讲清楚:我们写的文档、测试、review agent,本质上都是在把“非功能性需求”(比如高可用、高质量、可维护性)注入到模型的上下文里。我们要么写成文档,要么通过 lint 报错提示正确做法。整个系统的本质,就是把工程师脑子里“什么是好”的隐性知识,全部显性化,让 agent 可以学习。
所以我们特别关注 agent 的 bug——因为每一个 bug,都意味着有某个“尚未被写下来的规范”。这其实就是系统进化的驱动力。
主持人:所以大家之前误解的点是?
Ryan Lopopolo:其实不是误解,而是有人刚好点出了这一点,我就意识到:对,这才是我真正想表达的核心。
主持人:我明白了,很有意思。有个很有趣的现象是,很多人直接把你那篇文章的链接丢给像 Pi 或 Codex,然后说“把我的仓库变成这样”。相当于实现了一种“完全递归”。而且效果居然很好?
Ryan Lopopolo:是的,效果出奇地好。其实我昨天也用 5.4 试了一下,当时我在外面演讲,没有太多时间,就想着:能不能直接基于这篇文章快速搭一个类似的 scaffold(注:模版、脚手架)?我先这么做了一版,然后又拿了一个小的 side project,完全没有写代码,就是随便用语音 TTS 拼出来的那种非生产级项目,然后问:如果要把它完全自动化成这种体系,该怎么改?这个过程特别有价值,因为它不仅能帮你改代码,更像是在“分析”你的系统。你把所有代码、上下文和文章一起喂给它,它会一步步带你理解问题和改进方向。
主持人:我还想提一个点:你们董事会主席 Bret Taylor 也回应了你的文章。他说软件依赖可能会消失,未来可以直接“内嵌”(vendored)。你怎么看?
Ryan Lopopolo:我基本同意。但现实是,你现在还是要为 Datadog、Temporal 这些服务付费。以当前模型能力来看,我们可以“内化”的依赖大概在低到中等复杂度之间。
主持人:“中等复杂度”具体指什么?
Ryan Lopopolo:大概是几千行代码的依赖,我们可以在一个下午内轻松重写一份。而且有个关键点是:你其实不需要它全部的功能。通过内化依赖,你可以把通用逻辑全部剥离,只保留自己真正需要的部分。
主持人:我一直在说,这是“插件的终结”。
Ryan Lopopolo:确实。因为开源项目为了通用性,会引入大量冗余和复杂性。但如果你自己实现,只需要最小集。
还有一个很实际的好处:当我们在仓库里部署 Codex 安全审查时,它可以直接修改这些“内化”的依赖,而不需要走传统流程——提 PR、等上游发布、再拉下来、再处理兼容性。这整个流程的摩擦成本会低很多。在 token 很便宜的前提下,代码本身也变得“便宜”了。
主持人:但反对意见也很明显,比如大规模测试和安全性。像 Linux、MySQL 这种系统,依赖“众包审查”才能保证质量。如果你自己重写一遍,很可能会重复别人犯过的错误。
Ryan Lopopolo:没错。一旦你内化依赖,你就回到了“从零开始”的状态,必须重新建立对代码质量的信心。
主持人:回到你最开始说的:整个系统,包括内部工具,都是 Codex 写的,对吧?甚至连可视化工具也是?
Ryan Lopopolo:对,我现在做 AI 相关的内部工具,基本都是 prompt 出来的。前几天我给别人展示,他们问我花了多久,我说——我其实没花时间(笑)。
有个很有意思的例子:我们把应用部署给第一批内部用户后,遇到性能问题,于是让他们导出 trace(一个 tar 包),交给值班工程师。他用 Codex 做了一个非常漂亮的本地工具(Next.js 应用),可以拖拽这个文件并可视化整个 trace,做得非常好,花了一个下午。但后来我们意识到,这其实完全没必要——你可以直接把 tar 包丢给 Codex,让它分析,几分钟就能得到结果。
所以,从“人类可读性”出发去优化调试流程,其实是错误的。这让人类不必要地参与进来,而 agent 本可以直接完成。
主持人:这确实需要对抗直觉——过去我们习惯的做法,在这里反而是低效的。
Ryan Lopopolo:是的。比如传统上你会部署 Jaeger 去看 trace,但现在你甚至不需要看 trace,因为你也不会亲自去修代码。
主持人:所以核心是:你需要一整套“自洽的系统栈”,并让 agent 完全掌控。
Ryan Lopopolo:对,这一点非常关键。而且我们之后也会分享更多这方面的内容。
主持人:我们稍后会聊到 Symphony。你们现在是用“spec”的方式来分发软件,有人把这叫做“幽灵库(ghost libraries)”,这个说法挺酷。
Ryan Lopopolo:是的,这种方式让软件分发成本大幅降低。你只需要定义一个 spec,让 coding agent 能根据这个 spec 在本地重建系统。
流程也很有意思:我们把原有仓库的 scaffold 抽出来,新建一个仓库,然后让 Codex 基于原仓库生成 spec;接着让它启动一个新的 Codex 实例去实现这个 spec;再启动另一个 Codex 去对比实现和原始代码,并不断优化 spec,让两者越来越一致。这个过程会不断循环,直到 spec 可以高保真复现整个系统。
主持人:而且这个过程中,你基本没有引入人类偏见。
Ryan Lopopolo:对。人类写 spec 时,往往会带入自己的想法,比如“我觉得应该这么做”,但其实 agent 自己可以找到更优解。
我最近也在想一个问题:agent 能不能写出一个“自己无法实现”的 spec?也就是说,它能否想象出超出自身能力的系统?
我觉得这可以用一个二维坐标来看:问题是“简单/复杂”和“已有/全新”。对于“复杂+全新”的问题,还是需要人类;但其他象限,其实已经可以被解决了。
这意味着,人类可以把时间用在最有价值的地方——那些真正未知的领域,或者需要深度重构的系统设计。
主持人:这其实是在把人类推向更高层的抽象。
Ryan Lopopolo:没错,这也是我希望做的事情。
主持人:那我们来正式聊聊 Symphony。你们选了 Elixir,很有意思。
Ryan Lopopolo:对,但其实 Elixir 只是模型选择的一个结果。它选择 Elixir,是因为它的进程模型(比如 supervision、GenServer)非常适合我们这种任务编排方式。我们本质上是在为每个任务启动一个小型“守护进程”,并驱动它完成。
这意味着模型可以“免费”获得很多能力,比如并发、恢复等。我自己还专门去补了一下 Elixir 和 BEAM 的知识。虽然大多数人不需要这么高的并发规模,但它确实提供了一种很好的思维模型。
主持人:那 Symphony 是怎么诞生的?
Ryan Lopopolo:去年12月底的时候,我们每个工程师每天大概能做 3.5 个 PR。到了1月初,随着 5.2 模型上线,在没有额外优化的情况下,这个数字直接提升到了每人每天 5到10 个 PR。
Ryan Lopopolo:我不知道你们有没有类似的感受,但这种频繁切换上下文其实非常消耗精力。一天结束的时候,我基本已经被榨干了。所以问题又回来了:人类的时间花在哪里?其实就是在不同的终端窗口(T-Mux pane)之间来回切换,去推动 agent 前进。
所以我们又做了一件事:想办法把人从这个 loop 里移除。这就引出了 Symphony——本质上是一次非常“疯狂”的冲刺,目标就是让人不需要一直坐在终端前。我们尝试了很多方案,比如 dev box、自动拉起 agent 等等。理想状态其实很简单:我每天打开电脑两次,点个“yes / no”,然后去海边躺着。
这种模式带来的一个变化是:我对“延迟”不再敏感,也不再执着于代码本身。我几乎没有参与代码的“创作过程”,所以如果生成的东西是垃圾,我可以毫不犹豫地扔掉。在 Symphony 里有一个“rework”状态:当 PR 被提交并交给人类审核时,这个审核应该非常轻量——要么能 merge,要么不能。如果不能,就打回 rework,然后 Elixir 服务会直接删除整个 worktree 和 PR,从头再来。
这时候关键的问题是:为什么它是垃圾?agent 做错了什么?先修正这些问题,再重新推进任务。
主持人:为什么这些能力没有在 Codex App里?
Ryan Lopopolo:我们的团队其实一直在“跑在产品前面”,尽可能 AI-first 地探索。很多我们做的东西,后来都会进入正式产品。比如 Codex App、skills、自动化能力等等,我们都深度参与过。但我们的优势在于:不被产品节奏束缚,可以快速试错,然后再沉淀出可规模化的方案。
这种方式很有趣,但也很混乱。我经常完全不知道代码库当前的真实状态,因为我不在 loop 里。
举个例子:有一次团队把 Playwright 直接接进 Electron 应用,通过 MCP 来驱动。我其实对 MCP 挺悲观的,因为它会强制往上下文里注入大量 token,还会影响自动压缩(autocompaction),甚至 agent 可能忘记怎么用这些工具。而实际上,我真正需要的 Playwright 调用可能就三种。
后来有人直接写了一个本地 daemon,封装 Playwright,再暴露一个极简 CLI。我完全不知道这件事发生过,因为对我来说,我只是运行 Codex,然后它变得更强了。
所以在人类层面,我们必须花大量时间做同步信息共享。我们每天的 standup 要开45分钟,因为需要把当前系统状态“广播”出去。
主持人:这对单人+多 agent 还好,但多人与多 agent 的组合,会变得非常复杂。
Ryan Lopopolo:没错,这也是为什么我们在代码架构上采用了“10000人规模”的设计。
主持人:这个“10000人规模”是什么意思?
Ryan Lopopolo:我们的仓库大概拆成了500个 npm package。对于一个7人团队来说,这种架构是严重“过度设计”的。但如果你把每个人看成10到50个 agent,那这个产能规模就合理了。这时候,深度拆分、模块隔离、接口边界就变得非常重要。
主持人:你们用 Linear 做 issue 管理?
Ryan Lopopolo:对,我们也大量用 Slack。比如一些低复杂度的修复任务,我们会直接在 Slack 里触发 Codex 去处理,同时把知识同步进代码库。
说实话,我最大的一个想法是:OpenAI 应该做一个“Slack”。因为如果 AI 要真正做“有经济价值的工作”,它必须能和人类自然协作,而这就需要新的协作工具。
主持人:现在 Codex 已经从模型 → CLI → App,可以并行跑多个 agent,但团队协作还是缺失的。你觉得未来工具会怎么演进?是每个团队做自己的一套,还是会有通用方案?
Ryan Lopopolo:现在还没有一个通用答案。但我有一个倾向:尽量让“代码结构”和“流程结构”保持一致。因为代码本身就是上下文,就是 prompt。如果不同模块结构完全不同,agent 就需要频繁切换上下文,效率会下降。
同样的逻辑也适用于 skills。我们整个代码库只有6个 skills。如果某个开发流程没有被覆盖,我们的第一反应不是新增 skill,而是把它整合进已有的 skill 里。这样做的好处是:改变 agent 行为的成本,比改变人类行为更低。
主持人:你们会让 agent 改变自己的行为吗?比如自我优化?
Ryan Lopopolo:会的。我们有一套“skill 蒸馏”机制。比如你可以让 Codex 回顾自己的 session log,然后问它:我该如何更好地使用你?需要哪些新的 skills?这其实就是一种“自我反思”。
但更重要的是,我们把这些数据汇总起来:团队所有人的 session、PR 评论、失败构建,全部收集到一起,然后每天跑 agent 去分析:我们整体可以怎么做得更好?再把这些改进反馈回代码库。
换句话说,每个人的经验都会自动变成团队的能力。
PR 评论、构建失败,其实都是信号——说明 agent 在某个时刻缺少了上下文。我们的工作,就是把这些缺失的信息补回系统里。
主持人:我其实也在做类似的事情。每次用 AI 工具做完任务,我都会问:下次我可以做得更好吗?这其实就是一种元编程式的反思。
Ryan Lopopolo:没错,本质上你可以把 Symphony 看成一个多层级的“反思系统”。有点像“第零层”。所以这六个层级分别是:策略(policy)、配置(configuration)、协调(coordination)、执行(execution)、集成(integration)、可观测性(observability)。
我们已经聊过其中几个了,但第零层更像是在问:我们现在的工作方式运转得好吗?能不能改进?比如我能不能修改我自己的 workflow.md 之类的东西?我也不确定。
主持人:对,当然可以。
Ryan Lopopolo:而且这个系统甚至可以自己创建工单,因为我们给了它完整权限。是的,让它给自己创建一个“创建工单”的工单。你甚至可以在工单里写上,它需要跟进哪些后续工作。自我修改。
所以,不要把 agent 关在盒子里。要给它在自己领域内的完全访问权限。
主持人:你刚说“不要把 agent 放进盒子里”,我脑子里的第一反应其实是:还是应该把它放进盒子里。只是这个盒子要给它提供一切所需。
Ryan Lopopolo:对,context 和工具。
主持人:没错。但我们作为开发者,习惯调用各种外部系统。而在这里,你会用像 Prometheus 这样的开源工具,本地运行,这样就能形成完整闭环,对吧?
Ryan Lopopolo:对。我认为你应该尽量减少对云的依赖。同时也要认真思考 agent 能访问什么,对吧?它能看到什么?这些信息会不会被重新喂回循环?最基础的一点,比如你让它看到自己的调用链(call traces),它就可以判断自己哪里出错了。但问题是,你有没有把这些再反馈回去?所以在最基本层面,你需要清楚看到输入和输出——agent 能不能访问这些输出?
它可以在很多方面自我改进。本质上,这些都是文本,对吧?我的工作就是想办法把文本从一个 agent 流转到另一个 agent。有意思的是,在这波 AI 浪潮刚开始的时候,Andre 就说过:“英语是最火的新编程语言。”现在真的成真了。
很多软件本来是为人设计的,有 GUI。但现在我们看到的是 CLI 的演化:几乎所有工具都有 CLI,而且 agent 用得很好。
接下来关键在于:我们会不会有更好的视觉能力?更好的小型沙盒?但就目前来说,这种方式非常有效。模型很喜欢用工具,喜欢读文本,所以直接给它一个 CLI,让它自由发挥,这几乎适用于一切。
Ryan Lopopolo:对。我们也在把一些非文本的东西转成这种形式,以提升模型表现。比如我们希望 agent 能“看到” UI,但它并不是像人一样视觉感知。它不会看到一个红色方框,而是看到“红色方框按钮”这样的语义,它是在潜在空间里理解这些。
所以如果我们真的想让它理解布局,有时候反而是把图像栅格化成 ASCII,再喂给它更容易。而且其实可以两种方式同时用,进一步优化模型对操作对象的理解。
主持人:要不要再聊几个层级?有没有你特别感兴趣的?
Ryan Lopopolo:我觉得“协调层”(coordination layer)特别难做好。
主持人:那就聊这个。
Ryan Lopopolo:这也是 Temporal 的核心所在。这里的关键在于,当我们把 spec 转成 Elixir 实现时,模型可以“走捷径”。因为它有一套原语,可以在一个具备原生进程监督(process supervision)的运行时中使用。我觉得这是一个很优雅的方式,把 spec 映射到实现上。
就像你做全栈 Web 开发时,会更倾向用 TypeScript 仓库,因为前后端可以共享类型,从而降低复杂度。这有点像当年的 GraphQL。
而且这里没有人类参与,所以我个人会不会写 Elixir,并不会影响我们是否选用最合适的工具,这一点其实挺疯狂的。
主持人:很有意思。我在想,不同语言在这种范式下会不会表现不一样?可能有些更慢,有些更容易出 bug,比如需要偶尔重启服务器。
Ryan Lopopolo:有可能。我觉得可观测性层已经比较成熟了。集成层的话……MCP 已经“死了”。但整体来看,这是一套很有意思的层级体系,可以上下穿梭。它给在系统中工作的开发者提供了一种共通语言。
策略层也很酷。你不需要写很多代码去保证系统必须等 CI 通过,它其实就是你的“机构知识”。你只需要给它 GitHub CLI,再加一句“CI 必须通过”,就够了。
主持人:那你觉得 CLI 的维护者需要为 agent 做特别优化吗?
Ryan Lopopolo:其实不用。比如 GitHub CLI,当初设计时肯定没想到今天这种用法,但它已经很好用了。
CLI 的优势在于“token 高效”,而且很容易进一步优化。比如你去看 Buildkite 或 Jenkins 的日志,通常是一大堆输出。为了方便人类开发者,你的 Dev Productivity 团队往往会写代码,从日志中提取关键异常,放到页面顶部。
CLI 也应该类似这样设计。比如你不需要告诉 agent 每个文件都已经格式化了,它只关心“是否已格式化”。这样它就可以决定是否执行写操作。
类似地,我们在用 PNPM 的分布式脚本时,输出会非常多,但其实大部分只是测试日志。我们最后写了一层封装,把无关信息压掉,只保留失败部分。
主持人:对,可以把错误流单独 pipe 出来。
Ryan Lopopolo:对,不过这就有点太工程细节了。我以前也维护过 CLI,这块我很有共鸣。
主持人:还有什么要补充的吗?
Ryan Lopopolo:这份 spec 很长,也有很多强假设。但我觉得重点是:你可以拿它来用,同时也要改造成适合你自己的。
本质上,软件在能适应部署环境时才更灵活。所以像 Linear、GitHub 这些虽然写进 spec,但不是必须的。你完全可以换成 Jira 或 Bitbucket。
关键在于,它把一些核心东西定义得很清楚,比如 ID 格式、agent 的循环机制。这样你可以很快跑起来一个完整系统,然后再逐步演化。
我们从没打算让它成为一个不能修改的静态规范,它更像一个蓝图,让你先跑起来,再慢慢优化。而且这里面很多其实就是 prompt,只是一个非常长的 prompt。本质上 agent 很擅长遵循指令,所以你就给它足够清晰的指令,这样结果的可靠性会提高。
就像我们用 Symphony 一样,我们不希望人类去盯着 agent 工作。所以我们会非常严格地定义成功标准,这样部署成功率会更高,也减少支持工单。
主持人:这又回到“可丢弃性”这个点。以前跑一个 Codex 任务可能要两小时,你会一直盯着,怕它走偏。但现在你可以直接并行跑四个。
Ryan Lopopolo:对,我最喜欢 Codex App 的就是这个——直接 4 倍并行。没问题,总有一个是对的,甚至可能更好。
别过度思考。我最早的例子其实是 deep research。刚发布的时候,我问了一个关于 LLM 的问题,它却以为是法律问题,花了一个小时写了一份完全跑偏的报告。当时我想“我得盯着这个东西”,但其实不对——你不应该盯着它。你应该把系统设计成自动走在正确路径上,而不是自己在那里 babysit。你用 deep research 得到一个糟糕结果,其实你已经意识到需要微调 prompt 了,对吧?这就是你反馈回系统的“护栏”,进一步对齐 agent 的执行。这些思路在这里也是一样的。
主持人:
顺便问一句,Symphony 的客户反馈怎么样?
Ryan Lopopolo:我觉得目前还没有真正意义上的“客户”,因为这是一个我们内部使用的东西。只要你满意,你就是客户。
主持人:那外部怎么看?
Ryan Lopopolo:大家对这种以低成本分发软件和想法的方式非常兴奋。对我们这些用户来说,生产力又提升了 5 倍。这说明这里有一种“可持续的模式”:把人从循环中移除,同时建立对输出结果的信任。
比如这里展示的视频,其实就是我们期望 coding agent 在创建 PR 时附带的内容。这是构建信任的一部分。从根本上说,这个系统最有意思的地方在于,它让 agent 更像一个“与你协作的队友”。我不会盯着你一周内处理的每一个工单,也不会想要你在 Cursor 或 Claude Code 里的完整屏幕录制。我只希望你用你认为合适的方式证明代码是可靠的、可以合并的,并把整个过程压缩成一个我作为 reviewer 能理解的结果。
这点其实很自然。而且你可以做到这一点,因为像 Codex 这样的系统真的很强。
主持人:对,像 FFmpeg 这种就是“神级 CLI 工具”。
Ryan Lopopolo:对,简直像瑞士军刀一样。我以前常说,FFmpeg 的每一个 flag 都可以变成一个微型 SaaS。你给它套个 UI、做成服务,那些不会用 FFmpeg 的人就会愿意付钱。
我们刚开始做这些实验时,有一种很强烈的“未来感”:屏幕上不断弹出窗口,文件自动出现在桌面上,系统在控制你的电脑,而且是在做真正有生产力的事情。我基本只是在旁边保证它别休眠,偶尔动一下鼠标。
主持人:很多上班族其实也这么干,会买个“鼠标自动移动器”。
Ryan Lopopolo:没错。
主持人:我想问一个问题:既然现在这些东西这么强,可以异步丢一堆 agent 去跑,那你怎么看 Spark 这种模型(注:轻量版的 Codex 模型)?比如 5.3 Spark,它更适合快速小修改,比如改一行代码、换个颜色。我不想开 IDE,但可以让它帮我做这些。但问题是,我是不是还是瓶颈?为什么不干脆也把这些交给系统自动处理?
Ryan Lopopolo:Spark 确实是完全不同的一类模型。它架构不同,不支持复杂推理,但速度极快。说实话,我还没完全摸清怎么用它。我一开始是拿它做高推理模型的任务,结果它在真正写代码之前就消耗掉了大量上下文。
顺便说一下,像 5.4 这种百万 token 上下文,对于 agent 非常关键。你能在压缩上下文之前运行更久,token 越多,效果越好。
至于 Spark,我觉得你的直觉是对的:它很适合快速原型、探索想法、更新文档。对我们来说,它在把反馈转化成 lint(比如 ESLint 规则)方面非常好用,因为我们已经有成熟的基础设施。这类任务它做得很好,可以快速 unblock,也适合做一些“自愈式”的代码维护。
主持人:那你们其实是在把模型推到极限。那现在的模型还有什么做不好的?
Ryan Lopopolo:它们还做不到从“全新产品想法”直接一步到位生成一个可用原型(zero-to-one)。这是我目前花最多时间“干预”的地方:把一个完全没有现有界面的想法,转化成一个可操作的产品。
另外一个难点是“复杂重构”。虽然每次模型更新都有进步,但最复杂的重构任务仍然需要我频繁介入。我甚至需要为此构建额外工具,去拆解单体系统。
不过我预计这些都会持续改善。短短一个月内,我们已经从只能做低复杂度任务,进展到可以处理“大规模 + 低复杂度”的任务。这就是为什么你不应该低估模型——它会不断扩展到更高复杂度的空间。
所以正确的策略不是“对抗模型能力”,而是“围绕它设计系统”,让它去处理越来越复杂的部分,而你逐渐退到更高层的问题。
主持人:听起来任务类型本身也不一样。比如 Codex 很擅长理解已有代码库,但像 Lovable、Bolt、Replit 这些公司,解决的是从 0 到 1 的 scaffold 问题——从想法直接变产品。
Ryan Lopopolo:对,而且这两类问题是不同的。模型在这方面也在发生“阶跃式”进步。但它和现在的软件工程 agent 还是不一样。
我常说,模型在能力上其实和我“同构”(isomorphic),唯一的区别是:我需要想办法把我脑子里的东西,转成模型可以理解的上下文。而在这些“白纸项目”(white space project)上,其实我自己也不擅长。
所以在 agent 执行过程中,我经常是走到一半才意识到缺了什么,这也是为什么我需要同步交互。但如果有更好的 harness 或 scaffold,能够引导我、收敛可能性空间,比如强约束框架、提供模板,这些都可以帮助模型获得更多“非功能性需求”的上下文,从而避免结果发散。
主持人:最后聊聊 Frontier 吧。
Ryan Lopopolo:可以,但这里我恐怕不能详细展开蓝图。Frontier 是我们希望推动企业 AI 转型的平台,从大公司到小公司都适用。核心目标是:让企业可以轻松部署那些“高可观测、安全、可控、可识别”的 agent。
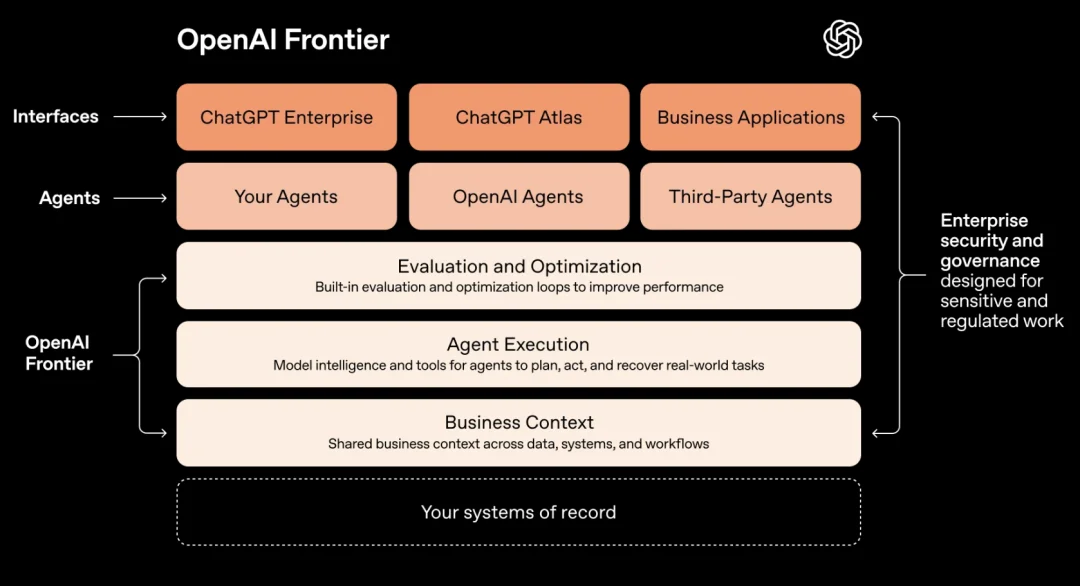
它需要能接入企业内部的 IM 系统,集成安全工具,连接工作流工具。本质上,你是在“分发 spec”。我们预计这里会有一些 harness 组件,Agent SDK 是核心,它可以让创业团队和企业开发者都拥有一个“开箱即用”的执行环境,能充分利用模型能力,比如 shell 工具、Codex 式执行环境、文件附件、容器等等。
我们的目标是把这些能力做到足够好,同时让它们可以安全地组合在一起。比如说,像 GPT OSS 的 safeguard 模型,有一点很酷:它自带了和“安全规范”对接的能力。而安全规范往往是企业定制的。
我们有责任帮这些公司,让他们能够给企业里的 agent 加上控制,防止数据外泄(exfiltration),而且是按照他们自己的关注点来控制,比如识别公司内部代号之类的。所以关键在于:既要提供足够的“钩子”(hooks)让平台可定制,同时默认情况下又要尽可能“开箱即用”。这就是我们在探索的空间。
主持人:对,这其实是像 Snowflake、Brex、Stripe 这类公司刚需的东西。
我想回到你们的 demo 视频,那其实很好地展示了一个“大规模 agent 管理”的场景。比如你给用户一个控制面板,在运行多个 agent 的时候,可以下钻到单个实例,看它具体在做什么。当然可以。但问题是:这个产品的用户是谁?是 CEO、CTO、还是 CIO?
Ryan Lopopolo:我个人的看法是,这个产品服务的“购买者”是一类人,但“用户”是两类人。第一类是实际在用这些 agent 提升生产力的员工,他们接触的是 agent 出现的界面、可用的连接器等等。
而像这种控制面板,更多是给 IT、GRC(治理/风险/合规)、AI 创新办公室、安全团队这些人用的,也就是公司里负责把 agent 安全部署到员工工作环境中的那批人,同时还要确保符合监管要求和客户合规承诺。
所以这更像是一个“冰山结构”,员工看到的是水面上的部分,底下还有一整层体系。
主持人:对,相当于 UI 的每一层都对应 agent 抽象的不同层级。
Ryan Lopopolo:没错。而且能够深入到单个 agent 的执行轨迹(trajectory)层级,非常关键——不仅对安全来说重要,对那些负责开发“技能”的人也很重要。
我们之前还发布过一个内部数据 agent,用了很多 Frontier 的能力,让 agent 能理解我们的数据本体(data ontology),知道数据仓库里到底有什么。
主持人:类似语义层(semantic layer)?我之前稍微接触过这个领域,说实话,人类自己都很难统一定义,比如“收入到底怎么算”。“什么算活跃用户”?公司里可能五个数据科学家,每个人定义都不一样。甚至还有内部政治,比如市场说“这部分是我贡献的”,销售说“这是我的”,加起来超过 100%。
Ryan Lopopolo:对,完全是这样。
主持人:而且在初创公司里,什么都算 ARR(笑)。这确实很有意思。
Ryan Lopopolo:对。我们其实写过这方面的博客。
主持人:那大家可以去看看。总之,“数据作为反馈层”很关键。你必须先把这个问题解决,才能闭环产品的反馈机制。
Ryan Lopopolo:没错。agent 要理解业务,必须知道收入是什么、用户分层是什么、产品线是什么。就像我们之前说的 harness 代码库里,有一个 core_beliefs.md,里面写了团队是谁、产品是什么、目标客户是谁、试点客户是谁、未来 12 个月的愿景是什么——这些都是构建软件时的重要上下文。
主持人:那这些也要喂给 agent?
Ryan Lopopolo:对。
主持人:而且这些东西是动态变化的吧?不是一个静态 spec。
Ryan Lopopolo:对,它是会不断迭代的。
还有一个可能更“炸脑”的点是:我们甚至给 agent 做了“技能”,让它学会生成深度油炸(deep fried)梗图,还有 Slack 里的 reaction 文化。因为通过 Slack + ChatGPT + Codex,我可以让 agent 代我发消息。
幽默其实是 AGI 的一部分。
主持人:那它好笑吗?
Ryan Lopopolo:挺不错的。幽默其实是很难的能力,因为你要在很少的字里压缩大量上下文。这也是为什么 5.4 这种模型对我们提升很大——在“玩梗”这件事上。
主持人:明白了,结论是:5.4 能让我们更会玩梗(笑)。
你们可以试试让 Codex 回顾你们的 agent 记录,然后吐槽你们。
Ryan Lopopolo:哈哈,可以试试。
主持人:回到最后一个问题:我觉得你们做的这套东西,其实是所有公司都应该采用的模式,不管是不是用你们的产品。我看到的第一反应就是:每家公司都需要这个。
Ryan Lopopolo:对。
主持人:虽然听起来有点“无聊”,比如安全、合规这些,但如果你真的要在大规模上管理 agent,这些是必需的。你们这个 dashboard,很像我最初理解的 Temporal:一个面板,能看到公司所有长时间运行的流程。
Ryan Lopopolo:对,就是这样。不过它会高度定制化,每家公司关注点不同。但我觉得未来一定会有很多公司专门做这一层服务。
主持人:我现在完全是 Frontier 的“信徒”了(笑)。之前是先看到 Frontier,再看到 harness 和 Symphony,最后才意识到:原来这是你们交付这套能力的方式。
Ryan Lopopolo:对。我们把一系列“构建模块”组装成这些 agent,而这些模块本身也是产品的一部分。比如你可以控制 agent 的行为、在模型失控时撤销权限等等,这些都通过 Frontier 提供。
公司里会有很多不同角色,他们都能在这个平台上看到自己需要的信息,从而推动 agent 的大规模落地。
主持人:这让我想起 OpenAI 之前提到的“AGI 五个阶段”,其中一个阶段是“AI 组织”。这基本就是那个方向了。
Ryan Lopopolo:是的。比如我们团队现在就在做一件事:收集 Codex 的 agent 执行轨迹,然后进行提炼,形成团队级知识库,再反馈回代码库。但这不一定要绑定在 Codex 上,我希望 ChatGPT 也能学会我们的“梗文化”、产品逻辑和工作方式。这样我去问它时,它就有完整上下文。
我对 Frontier 能实现这一点非常兴奋。
主持人:模型团队看到你们这样用,会有什么反馈?你们有大量使用数据和轨迹。
Ryan Lopopolo:确实存在一个核心张力:我们到底是应该继续加强 harness(系统工程层),还是把这些能力直接训练进模型,让模型默认就会做这些事情。
对。我觉得我们现在这种工作方式的“成功”,意味着模型会逐渐形成更好的“品味”(taste),因为我们可以为它指明方向。而且我们构建的这些东西,并不会降低 agent 的性能——本质上它们只是让 agent 去跑测试,而“跑测试”本来就是写可靠软件的一部分。
如果我们是围绕 Codex 额外搭一整套 ROS 式的 scaffold,去强行限制它的输出,那这种额外的 harness 很可能最后会被废弃。但如果我们能把这些护栏直接构建在 Codex 原生输出之上,也就是代码本身,那就没有摩擦,一方面不影响模型持续进化,另一方面这本身也是良好的工程实践。这才是关键。
主持人:我之前也和一些研究科学家讨论过类似问题,比如强化学习里的 on-policy 和 off-policy。你的意思其实是:应该构建一个 on-policy 的 harness,也就是在模型本身分布内做增强,而不是搞一个偏离分布的外部系统?
Ryan Lopopolo:没错。
主持人:很有意思。还有什么我们没聊到,但你觉得值得补充的吗?
Ryan Lopopolo:我一直很兴奋能受益于 Codex 团队的持续“高强度迭代”。他们的核心工程文化就是“疯狂发版本”(ship relentlessly),而且他们真的做到了。从 5.3 到 Spark,再到 5.4,感觉几乎是在一个月内完成的,这个速度非常惊人。
主持人:对,一个月前还是 5.3,昨天就已经 5.4 了。那接下来是不是每个月都来个 5.5?
Ryan Lopopolo:哈哈,这种事我不好说,但预测市场的人可能会很激动。
主持人:不过很有意思的一点是,这也和增长同步——他们说已经有 200 万用户了。但某种程度上,你甚至不再只关心 Codex 本身了,而是更大的图景:coding 只是入口,真正的目标是整个“知识工作”。
Ryan Lopopolo:没错,这才是核心方向。这也是我们团队在努力支持的事情——让 self-hosted harness 跑起来。接下来就是:真正去“做事”。
主持人:还有什么想对大家说的吗?你在西雅图,对吧?
Ryan Lopopolo:对,我们在 Bellevue 有新办公室,录制前一天刚刚开业。环境很好,我们很高兴能在华盛顿州参与建设未来。
我想说的是,在 Frontier 这块,为企业客户提供服务还有大量工作要做,我们正在招聘。如果你还没试过 Codex App,建议去下载试试。我们刚刚突破了 200 万周活用户,而且每周增长 25%,速度非常快。欢迎加入我们。
主持人:我有个观察:OpenAI 以前是一个非常“旧金山中心化”的公司。很多人因为不想搬去旧金山而放弃加入。但现在你们开始在伦敦、西雅图扩张,这会不会改变公司文化?
Ryan Lopopolo:我算是西雅图办公室最早的一批工程师之一,所以对我来说这很自然。这也是我一直在推动的方向,而且发展得很好。我们在那里已经建立了稳定的产品线,同时也有大量从 0 到 1 的创新项目。
这其实就是我们做“应用 AI”的核心方式:快速冲刺、不断探索,看模型在哪些场景下能真正落地。
另外我们在纽约也有办公室,而且工程团队规模也不小。
主持人:明白,这基本就是我的“AI 朝圣地图”:哪里招工程师我就去哪。
Ryan Lopopolo:纽约办公室也很不错,是以前 REI 的办公楼。但纽约的空间毕竟有限,很难像西雅图那样有大规模办公室。西雅图这边有点像《广告狂人》(Mad Men)那种风格,很漂亮;Bellevue 新办公室则是绿色基调、金属装饰,很有太平洋西北的感觉。
主持人:确实,有些人就是喜欢纽约的氛围。
Ryan Lopopolo:对。我们的办公环境团队做得非常好,能在这里工作是很幸运的。
主持人:好的,非常感谢你今天的分享,内容很扎实,而且你们确实在“疯狂推进”。
Ryan Lopopolo:很高兴交流,祝周五愉快。
主持人:周五愉快。
文章来自于"51CTO技术栈",作者 "云昭"。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
