# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。
当大部分大模型还在依靠显式空间 (Explicit Space) 或者说语言空间 (Verbal Space) 完成时,一场底层的范式革命已经悄然发生:大模型的核心计算和操作,正在从人类可读的离散符号空间,转向机器原生的连续潜在空间 (Latent Space) 。
这种转变是由显式空间计算的结构性局限性驱动的,包括语言冗余、离散化瓶颈、序列效率低下和语义损失等问题。越来越多的研究指出,许多关键的内部过程在 Latent Space 中执行比在人类可读的词元中执行更为自然且有效。然而,现有文献在机制、能力等方面仍然分散,缺乏对潜在空间的定义、分类和研究的统一视角,这阻碍了该领域的进一步发展和进步。

基于此,来自新加坡国立大学、复旦大学、清华大学、浙江大学等国内外顶级学术机构系统性地梳理了大模型潜空间研究的重磅综述《The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook》,尝试通过 “基础 — 演进 — 机制 — 能力 — 展望” 五大核心视角,构建起清晰的研究框架,为社区和后续的研究者提供了潜在空间的全景视角。

综述首先指出,当前针对潜在空间的综述研究仍存在明显局限:一方面,现有综述要么仅聚焦潜在推理 (Latent Reasoning) 这一细分分支展开探讨,要么仅将潜在空间作为附属小节简略阐述,未形成系统性的研究梳理;另一方面,多数综述对潜在空间的技术实现仅开展碎片化、不完整的分类,其分类框架已难以适配当前日益丰富的技术范式与多元化的应用场景。
基于此,该综述首先提出了五大核心问题:
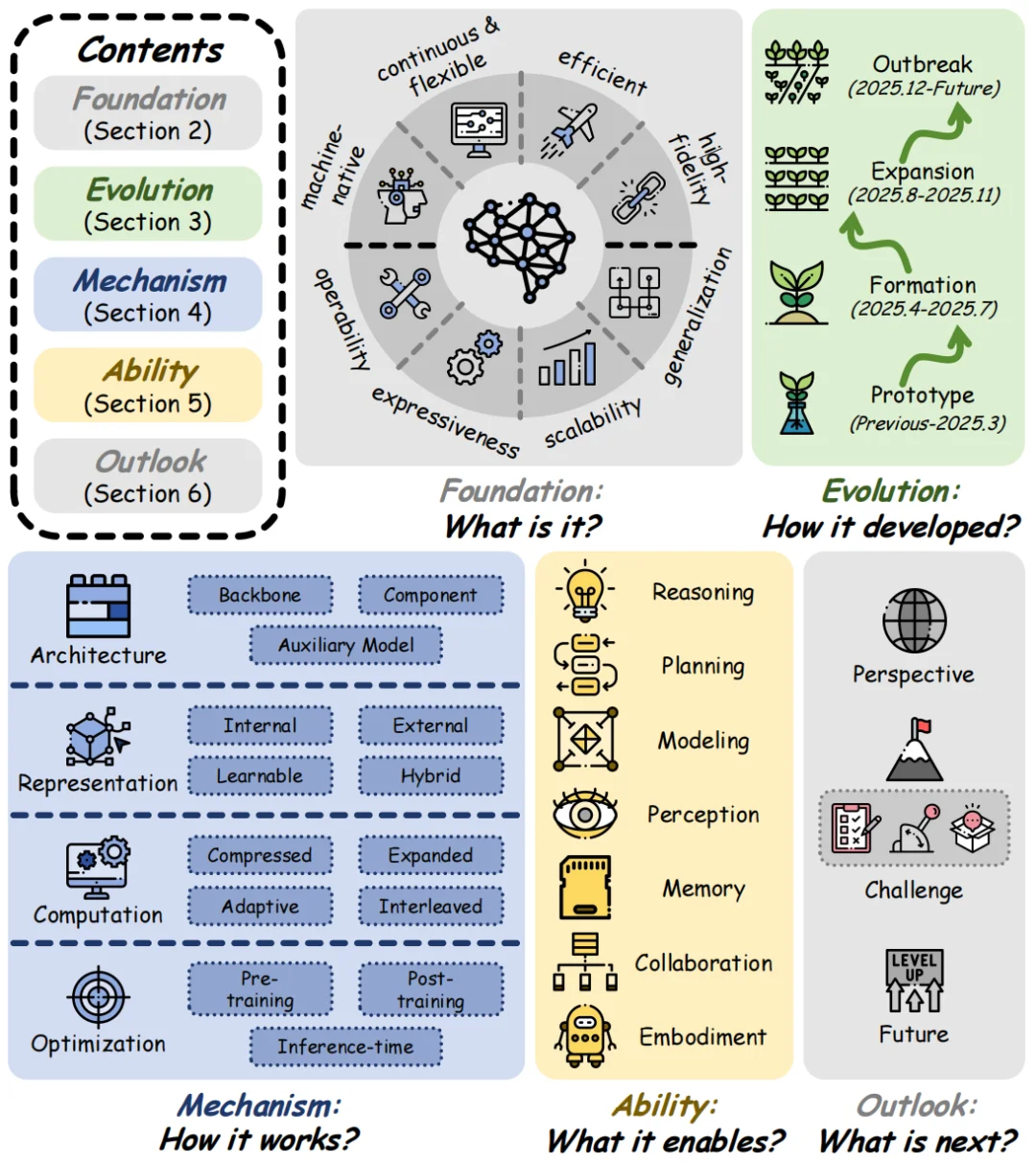
概念:
大模型的潜在空间,是模型内部通过学习形成的连续非离散的表征空间:在其中编码、处理文字背后的语义、语法、上下文关联等没有直接用文字 (token) 显式表达的隐含信息;这个空间还能拓展为统一的空间,用来处理多模态信息。
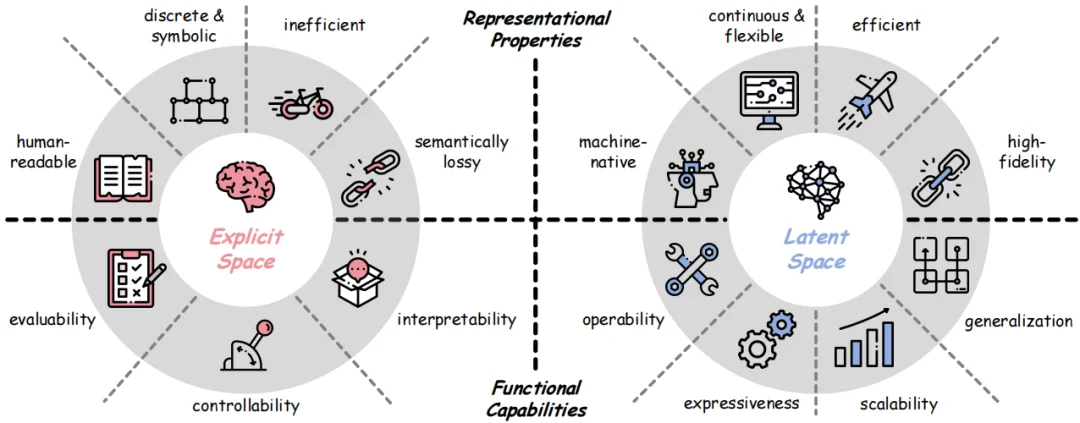
与显式空间的区别:
综述从两个角度进行对比,四大表征属性 (Representational Properties) :
四大功能能力 (Functional Capabilities) :
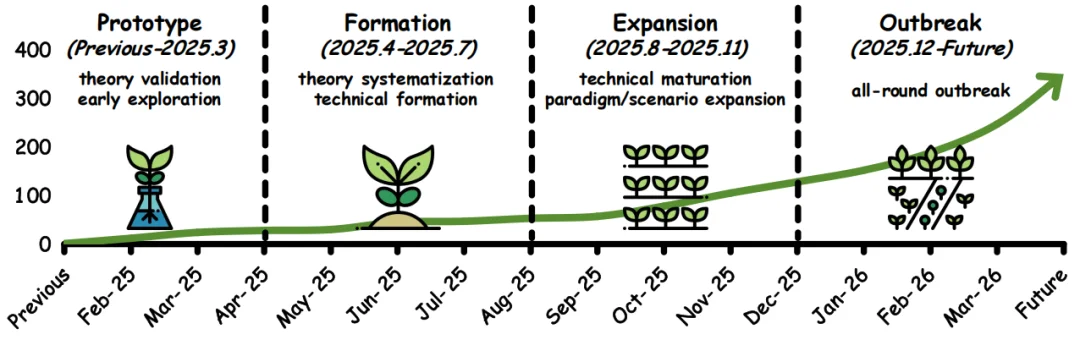
大模型潜在空间的研究发展,随大语言模型能力提升分为四个递进阶段,整体从 “验证想法” 逐步走向 “成熟落地、全面爆发”:
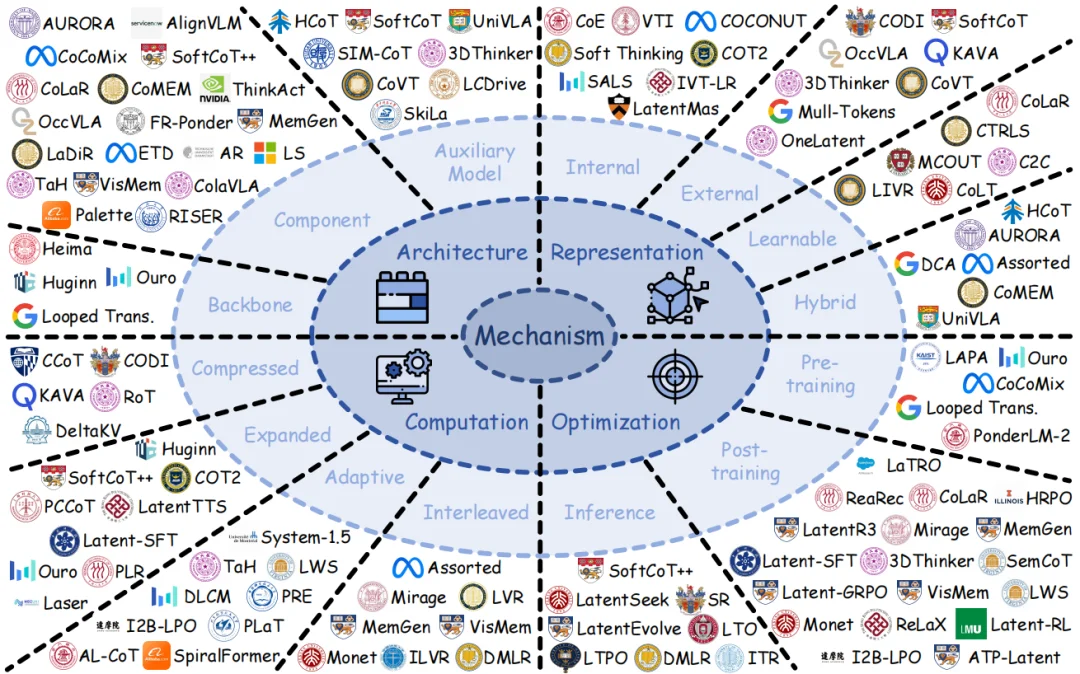
潜空间的机制 (Mechanism) 是大模型将潜空间从理论概念落地为实际功能的底层技术框架,它围绕架构、表征、计算、优化四个相互协同的核心维度,完整拆解了潜空间在大模型中的全流程运作逻辑,分别解决潜空间如何嵌入模型结构、以何种形式承载信息、怎样开展信息运算、如何通过调优提升效果四大关键问题,是连接潜空间基础定义与实际能力的核心技术纽带,也是大模型实现潜空间高效运作、发挥各类进阶能力的底层技术支撑。
架构 (Architecture):
架构是潜空间在大模型中的结构集成方案,核心解决 “潜空间如何嵌入模型” 的问题,决定了潜计算的底层载体。它不改变模型核心逻辑,而是通过三种方式将潜空间融入结构:直接改造模型主干实现原生潜计算、加装插件模块实现潜功能扩展、借助外部辅助模型提供潜信号支持,最终让模型具备原生的潜空间运算基础,是潜空间落地的结构根基。
表征 (Representation):
表征是潜空间的信息承载形式,核心解决 “潜空间用何种载体处理信息” 的问题,定义了潜信息的表达范式。它依托模型内部激活、外部模块、可学习模块或混合方式生成潜载体,将离散的文本 token 转化为连续高维向量,既能复用模型原生隐状态、也能自定义可学习潜表示,是潜空间实现高保真、高效率信息表达的核心载体。
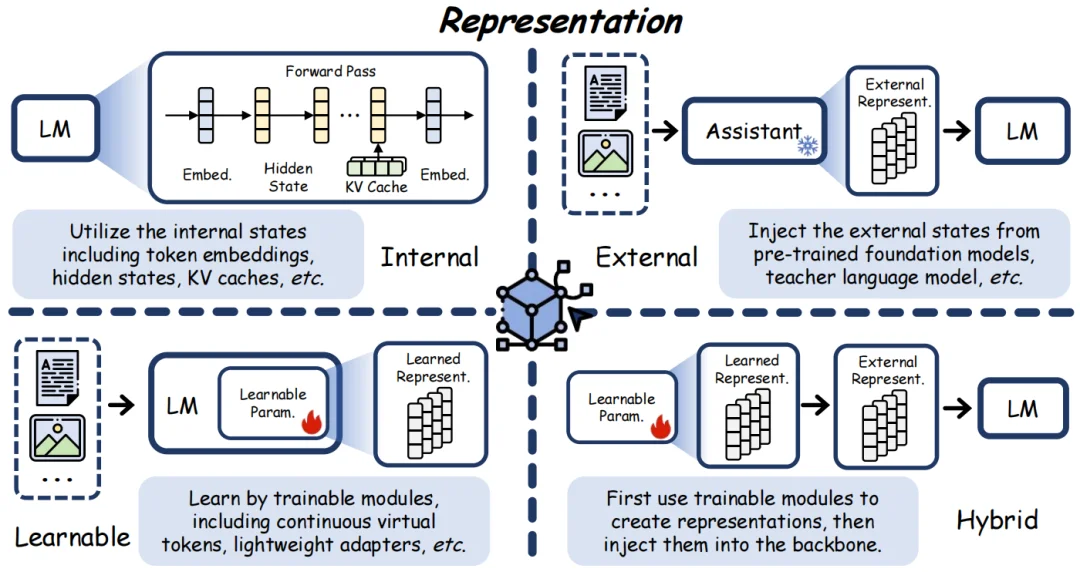
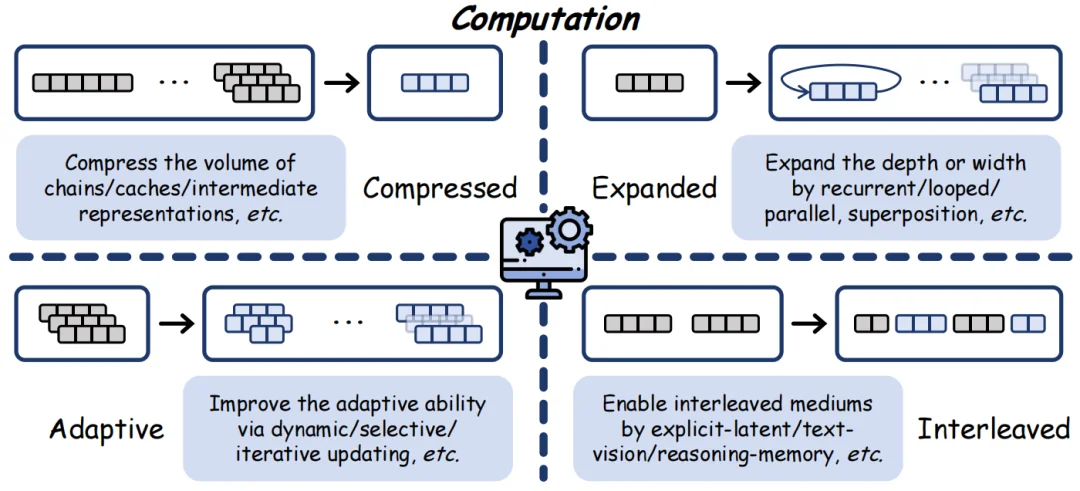
计算 (Computation):
计算是潜空间的信息处理逻辑,核心解决 “潜空间如何运算和处理信息” 的问题,决定了潜计算的效率与能力上限。它通过压缩、扩展、自适应、交叉四种模式处理信息:压缩冗余信息降低算力、扩展算力提升表达、动态分配算力平衡效率、交错信息融合优势,让潜空间摆脱离散 token 的限制,实现灵活、高效、高带宽的内部运算。
优化 (Optimization):
优化是潜空间的效果调优手段,核心解决 “如何优化潜空间运算” 的问题,覆盖模型全生命周期。它在预训练阶段让模型习得潜计算能力、后训练阶段精调潜空间适配任务、推理阶段实时修正潜状态,通过监督学习、蒸馏、强化学习等方式规范潜空间的几何结构与运算逻辑,持续提升潜空间的可靠性、可控性与泛化性。
潜在空间作为大模型机器原生的连续表征载体,突破了传统离散文本 token 的表达局限与计算瓶颈,不再局限于单一的文本推理,而是从能力 (Ability) 上全面解锁了覆盖推理、规划、建模、感知、记忆、协作、具身的七大核心智能能力,让模型在逻辑思考、多步决策、多模态理解、知识存储、智能体协同与实体交互等全场景中,实现效率、表达力与泛化性的全方位升级。
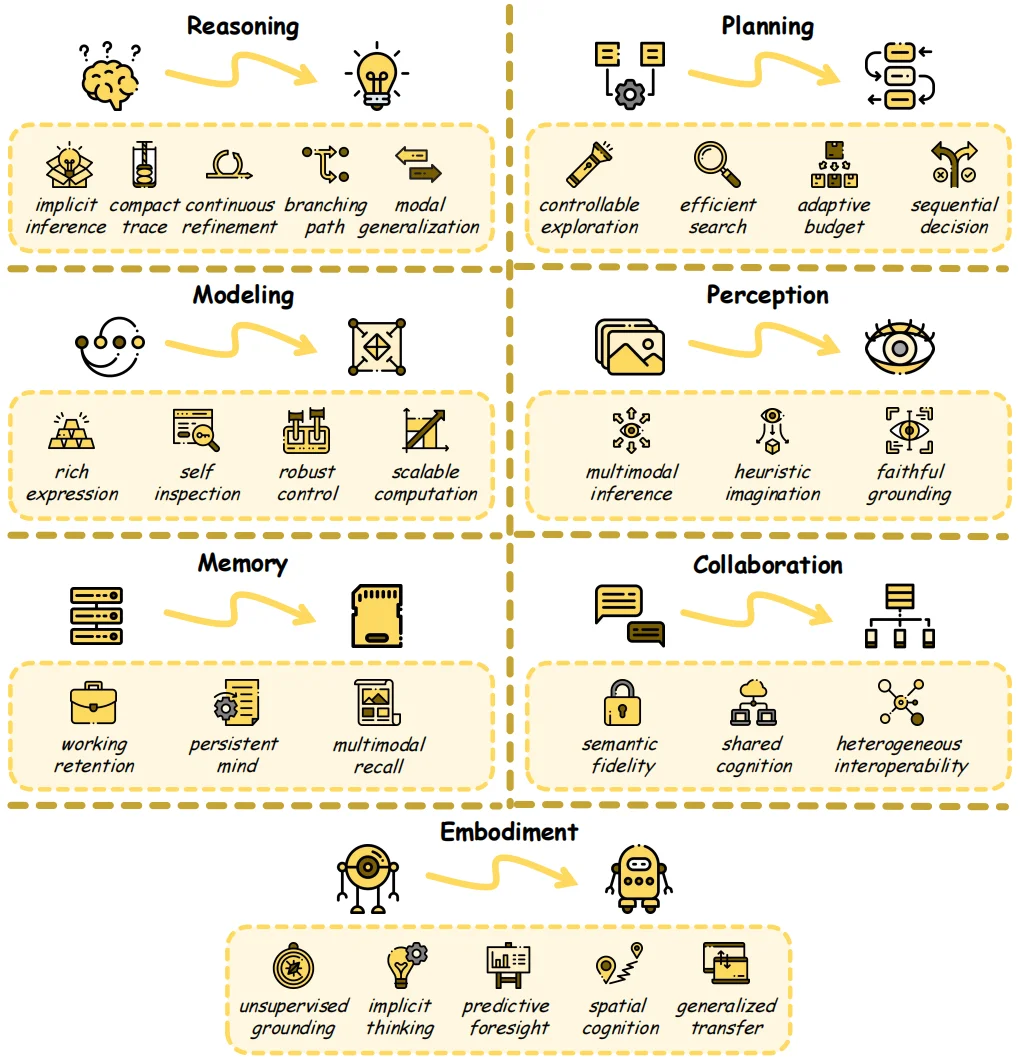
推理能力 (Reasoning):
潜在空间推理是指大型模型能够通过内部连续的表征,而非通过逐个词元的显式语言表达,来进行逻辑演绎、关系计算和结论生成。从显式 CoT 推理到潜在推理的转变代表着一种根本性的范式转变:模型不再需要用自然语言表达每一个中间步骤,而是学习在一个连续的高维潜在流形中思考。
这种范式在推理的能力方面具有显著优势,该综述将其归纳为六种能力:无需完全语言表达的隐式推理 (Implicit Inference)、将长链压缩成紧凑状态的紧凑轨迹 (Compact Trace)、以潜在形式维持和修正思维的连续迭代 (Continuous Refinement)、跨多个候选路径的分支路径 (Branching Path),以及超越纯文本设置的模态泛化 (Modal Generalization)。
规划能力 (Planning):
规划关注的是在解空间中寻找最优轨迹,其中潜在流形的连续性和可微性允许基于梯度的策略优化和迭代轨迹改进。
与侧重于在给定上下文中进行逻辑推理的推理不同,规划强调计算的前瞻性组织,确定资源的分配位置、探索解空间的方式以及何时终止搜索。
基于潜在空间的方法从四个方面优化了潜在规划:对内部解路径的可控探索 (Controllable Exploration)、在潜在流形中导航的高效搜索 (Efficient Search)、根据难度匹配计算资源的自适应算力 (Adaptive Budget),以及在下游交互式任务中的顺序决策 (Sequential Decision)。
建模能力 (Modeling):
建模涵盖了对大型语言模型中潜在表征进行刻画、检查和塑造的能力。推理和规划关注的是模型在潜在空间中计算的内容,而建模则侧重于潜在表征如何帮助我们理解和控制计算本身。
该综述将这一维度构建为四种能力的提升:用于编码复杂计算的丰富表达 (Rich Expression)、使内部状态可分析的自我检视 (Self Inspection)、针对风险或不稳定行为的鲁棒控制 (Robust Control),以及通过潜在递归扩展容量的可扩展计算 (Scalable Computation)。
感知能力 (Perception):
潜在空间感知旨在解决视觉语言模型的理解、表示和处理连续、高保真潜在空间中的视觉信息的根本挑战。当前的视觉语言模型仍然面临一个关键瓶颈:将丰富的视觉内容转换为离散的文本标记不可避免地会丢失空间结构、精细细节和关系几何信息。潜在感知通过保留离散标记化必然会破坏的密集空间结构信息来克服这一限制,使模型能够像人类感知一样,以丰富而微妙的方式对视觉内容进行推理。
潜在空间赋予了感知三个逐渐深入的高级能力:基于内部视觉表征的多模态推理 (Multimodal Inference)、用于生成式操作和三维理解的启发式想象 (Heuristic Imagination),以及通过表征层面的干预来提高输出保真度的忠实定位 (Faithful Grounding)。
记忆能力 (Memory):
记忆已成为大模型的必要补充,无状态架构需要外部机制来跨推理步骤保留知识。然而,基于标记的记忆也存在自身的瓶颈:将累积的上下文表示为离散序列会增加提示长度,降低检索保真度,并阻碍自适应记忆巩固所需的基于梯度的优化。潜在记忆通过将持久知识编码为连续向量来解决这一问题,从而实现紧凑的跨上下文保留,并具有更高的保真度和适应性。
在记忆层面,潜在空间的三种扩展能力有力地支撑了其成为记忆的媒介:用于缓存干预的工作记忆留存 (Working Retention)、用于自我演化知识存储的持久记忆演化 (Persistent Mind),以及跨视觉和具身模态的多模态记忆调取 (Multimodal Recall)。
协作能力 (Collaboration):
传统上,多智能体系统中的集体智能是通过自然语言来传递的。然而,语言本身就是一个固有的瓶颈:将内部表征压缩成离散的词元会丢失语义细微差别,增加通信延迟,并破坏联合优化所需的梯度路径。潜在协作通过使智能体能够交换连续表征来解决这些限制,从而保留更丰富的内部状态并支持更具表现力的集体协作形式。
潜在空间协作组织成三个递增的能力:用于通过潜在通道实现智能体间的无损状态传输的语义保真 (Semantic Fidelity),用于识别和演化跨智能体的共享思维结构的共享认知 (Shared Cognition),以及用于将协作扩展到不同的模型族和模态的异构互通 (Heterogeneous Interoperability)。
具身能力 (Embodiment):
具身智能体面临着一种数据瓶颈,这是任何纯粹语言领域都无法比拟的:物理多样性的每一次增加,例如新的硬件形态、视角和任务环境,都会使现有的标记演示失效,并迫使用户进行平台特定的重新训练,而这种模式无法直接迁移。潜在表征可以同时消除这些失效模式,使行为语义能够从未标记的视频中涌现,并使空间先验信息能够直接提炼成策略骨架,而无需额外的工具或重新标注。
潜在空间在具身领域的潜力可以归纳为五种递进的能力:用于从无标签视频中导出可迁移的动作表示无需具身化特定标签的无监督落地 (Unsupervised Grounding),用于将多步骤规划内化为连续的潜在计算而无需显式生成思维链的内隐思考 (Implicit Thinking),用于模拟未来状态以生成密集的训练信号并指导实时决策的预测前瞻 (Predictive Foresight),用于从 2D 观察重建 3D/4D 几何结构的空间认知 (Spatial Cognition),以及用于通过共享的与身体无关的基质来连接异构硬件形态的泛化迁移 (Generalized Transfer)。
核心定位:
潜空间是大模型的原生核心计算空间,并非附属功能,已从文本推理拓展到多模态、记忆、协作、具身智能等全场景,是下一代通用 AI 的核心范式。
现存挑战:
潜空间存在三大短板:难评估(中间计算过程不可见,无法验证推理合理性)、难控制(无法精准操控内部连续表征)、难解释(高维向量无直观语义,模型行为不可追溯)。
未来方向:
综上,该综述系统性填补了大模型潜在空间研究的碎片化空白,以 “基础 — 演进 — 机制 — 能力 — 展望” 五大视角构建完整研究框架,清晰剖析了潜空间从概念验证到全面爆发的演进路径与底层逻辑。作为大模型从显式符号向机器原生连续表征跨越的核心范式,潜空间已解锁多维度智能能力,虽仍面临挑战,但仍然具有极大潜力,该综述为后续研究奠定坚实基础。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
