# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着RL后训练逐步延伸至全模态与Agentic场景,多模数据异构、系统稳定性和角色耦合等方面的问题日益凸显。

为此,小红书AI平台团队刚刚开源了Relax——一个为全模态数据、Agentic工作流和大规模异步训练协同设计的现代RL训练引擎!
实测全异步Off-Policy模式相比共卡On-Policy吞吐提升76%,相比veRL的全异步实现提升20%!
RL后训练正在经历两个根本性变化:模型走向全模态(图文音视频一起训,甚至带有音频或图片视频输出),训练走向Agentic(多轮推理、工具调用、复杂环境交互)。
这两个趋势叠加,把现有RL训练框架逼进了三重困境——而且这三个问题不是各自独立的,它们环环相扣,必须一起解决。
困境一:数据异构。高质量的图片和音视频原始数据传输体积大、CPU预处理开销高、编码后token爆炸,multi-modal encoder无法和已有并行策略高效协同——在小红书内极其丰富的多模场景下,需要一款定制优化的框架。
困境二:系统脆弱。多模态下较高的OOM风险叠加上千卡长时训练,硬件故障、NCCL超时随时出现——传统方案缺乏分钟级故障恢复和单角色弹性伸缩能力。
困境三:角色耦合。Colocate方案下各角色共享GPU只能串行执行,Trainer干等最慢的Rollout完成;现有全异步方案虽然把Rollout和Train拆到不同组,但缺少细粒度的流水线调度。
这三个困境形成了一条因果链:
多模态让系统更低效且脆弱→催生服务化隔离和全异步架构→催生数据总线→总线的字段存储天然兼容多模态→三个问题一条因果链,完成闭环。
Relax用一套协同设计(co-design)把多模态原生、服务化容错、全异步流水线一并解决。
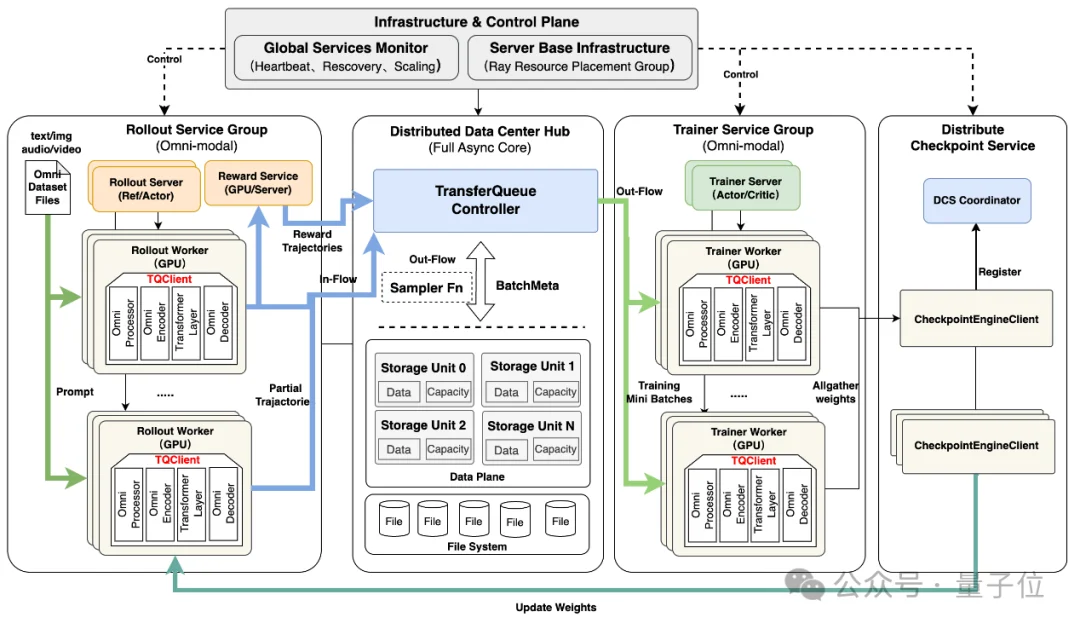
传统方案把Rollout和Train绑在一起。Relax的做法很暴力——直接拆成两个独立服务。
Rollout服务:专门做推理生成,用SGLang引擎
Train服务:专门做梯度更新,用Megatron后端
两个服务通过TransferQueue数据总线连接。Rollout生成的数据往里写,Train从里面读,互不阻塞。这带来一个直接的好处:Rollout的推理时间大部分被掩盖!Train不用等Rollout完事再开工,而是上一批数据训着,下一批数据就已经在生成了。
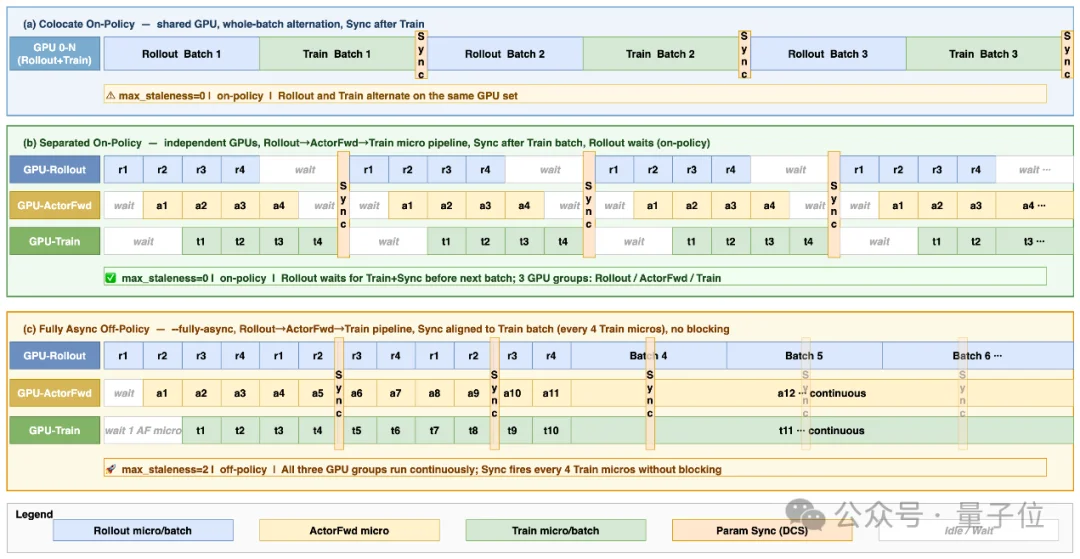
光把Rollout和Train拆开还不够。传统方案——包括现有的全异步框架——还有一个致命缺陷:全局batch同步。
Relax把粒度从全局batch推进到了micro batch级别的流水线,例如:
效果?长尾样本再也拖不死整个step。单条慢样本只影响它所在的micro batch,其他micro batch正常流转;对于超时仍未完成的样本,Relax还支持partial rollout——已生成的部分直接回收利用,不白等也不白扔。整条RL训练链路从粗粒度的“Rollout完了再Train”变成了细粒度的多阶段流水线。
Relax不是一个铁板一块的单体程序。它把RL训练的每个角色——Actor、Ref、Rollout、Reward——拆成独立的Ray Serve服务。
每个服务有自己的进程空间、故障域和资源配额。它们之间不直接引用,全部通过TransferQueue数据总线通信。
说白了——Ref挂了,Actor照样训。一个Rollout实例OOM了,其他Rollout正常工作。
传统方案呢?一个节点出问题,整个任务重启,进度全丢!
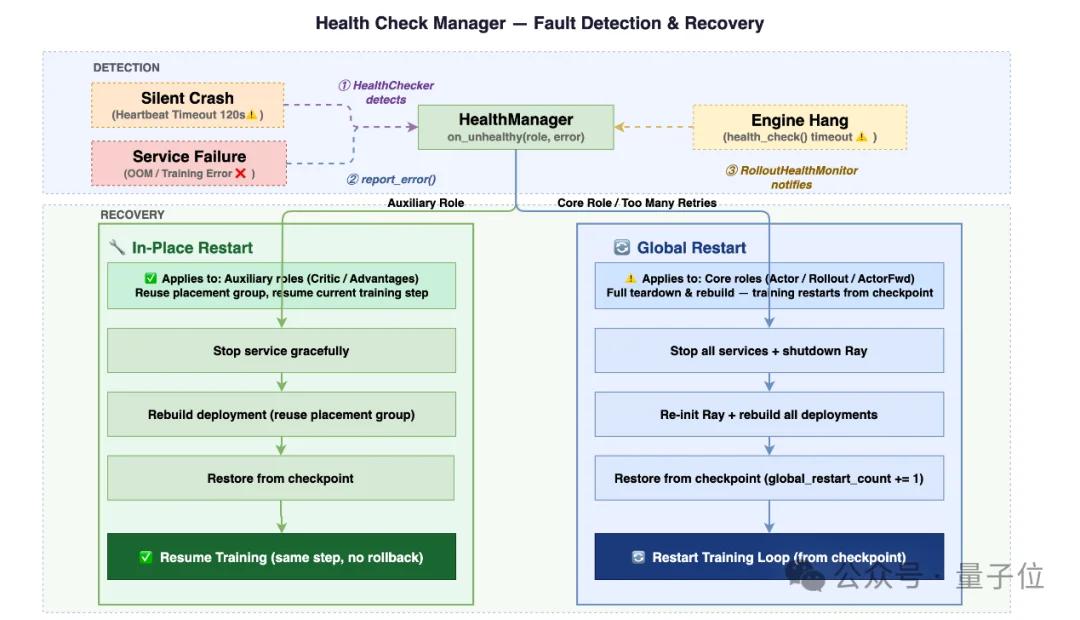
Relax有一套完整的健康监控体系:通过主动上报和心跳超时两条路并行,并根据角色重要性分级处理:
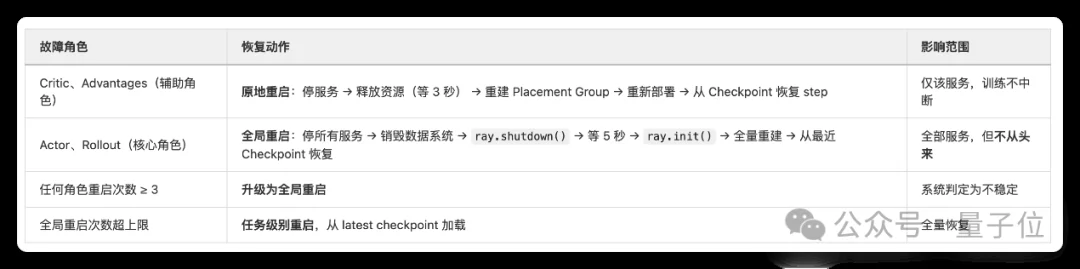
简单来说——能局部修就局部修,必须全局重启也从最近的checkpoint恢复,而不是从头再来。
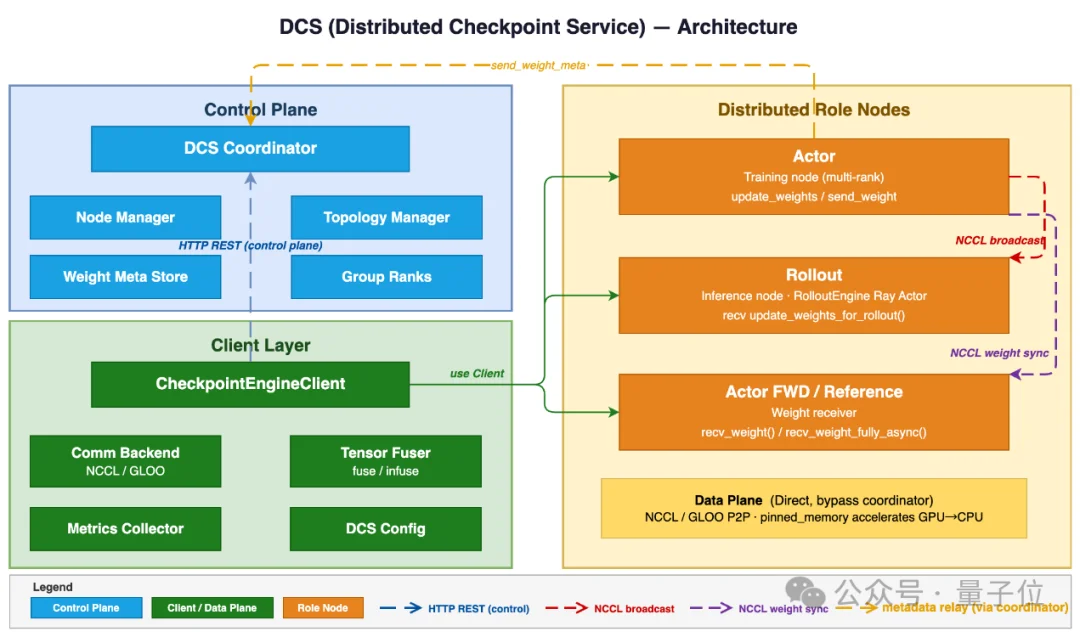
恢复快不快,核心取决于权重能不能快速到位。Relax专门为此搞了一个独立服务——DCS,它不是简单的“训完了存一下”,而是一个带拓扑感知的分布式权重传输系统。
DCS自动发现TP/PP拓扑、构建跨异构并行的rank映射,集群内走NCCL GPU通信(最低延迟),跨集群走TCP,对弹性扩缩,甚至是联邦集群下的弹性扩缩足够友好。
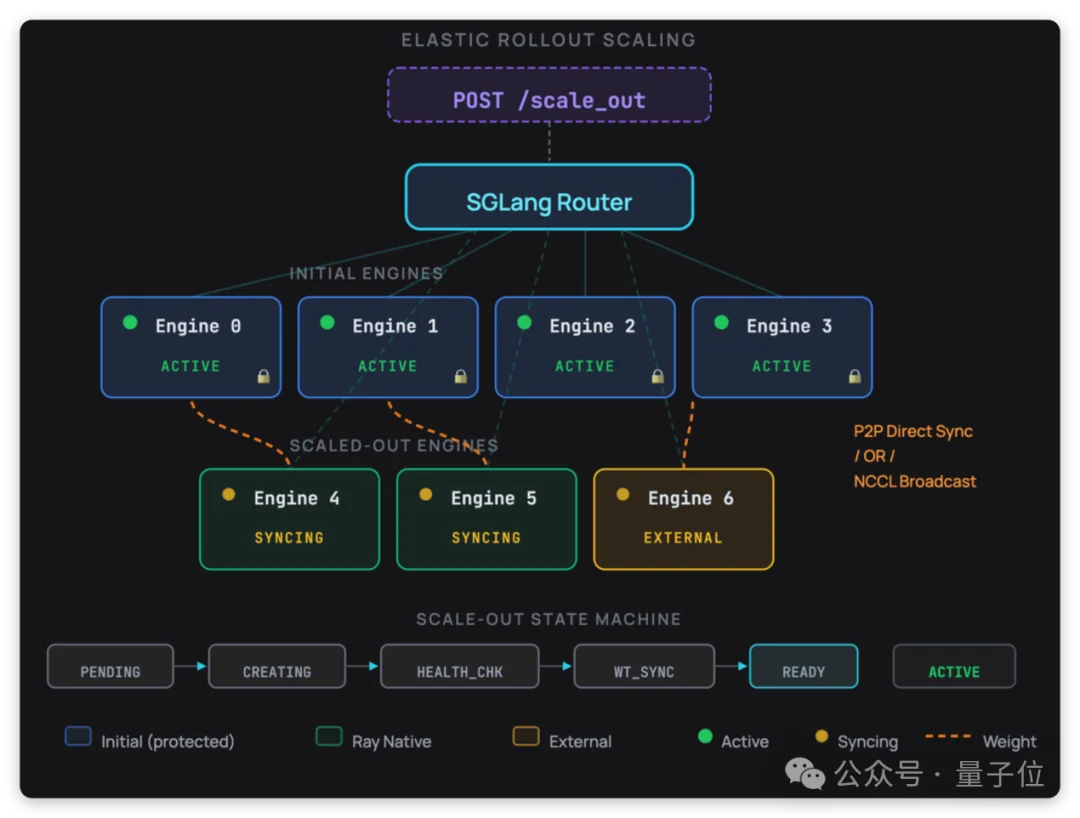
Relax支持训练过程中动态扩缩Rollout实例,提供Ray原生(集群内增减副本)和外部引擎(接入外部集群)两种模式。每个新实例依次经过PENDING→CREATING→HEALTH_CHECKING→WEIGHT_SYNCING→READY→ACTIVE六个阶段,每一步都有超时和回滚,任何一步失败自动清理资源。缩容同样不粗暴——先停止接新请求、排空在途任务、等待权重更新完成,再逐步下线。Relax还内置了基于KV Cache利用率、排队深度、TTFT等指标的自动伸缩器。
Processor Pool。多模态processor(图片resize、视频抽帧、音频重采样)是CPU密集型操作,单线程跑会被GIL卡死。Relax用ProcessPoolExecutor把processor放到独立进程,共享内存零拷贝传输,配合asyncio实现processor、media encoding、Rollout请求三阶段流水线——CPU预处理完全藏在GPU推理延迟背后。
ViT原生HF+TP维度数据并行。通过Megatron Bridge保持ViT的HF原生实现,在TP维度上复制到所有rank,各rank独立encode不同的pixel_values切片后AllReduce合并。ViT参数只占1-5%,冗余开销可忽略,省掉格式转换的工程负担和精度风险。
异步通信。Relax基于TransferQueue的async_put / async_get,让数据读写与GPU计算完全重叠,配合micro batch流水线实现端到端的细粒度异步。
服务化架构带来的另一个好处——Agentic场景天然适配。
自定义Rollout:Agent要调工具、查数据库、跑沙箱?写成可插拔服务,挂上去就行。
多轮状态管理:服务化架构下,多轮交互的状态管理就是服务间的消息传递。
灵活的Reward:Rule-based、LLM-as-Judge(GenRM)、自定义函数,按需组合。
实验环境:NVIDIA H800 80GB GPU集群,NVLink/InfiniBand互联。

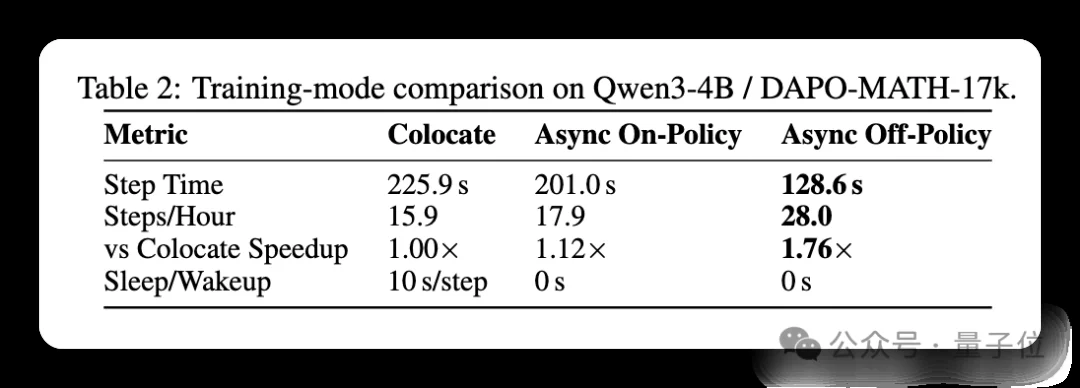
在Qwen3-4B+DAPO-MATH-17k+16×H800的配置下,全异步Off-Policy模式相对Colocate方案吞吐提升76%,相比VeRL的全异步实现提速20%(28.7 vs. 23.9 steps/hour),即使是分离异步下的On-Policy,也可提速12%。
加速来自三层叠加:
1. 流式micro batch调度:不等慢样本,生成一组处理一组,即使是async的on-policy也能拿到提速收益!
2. 资源分离:log-prob和reference log-prob在独立GPU上计算,计算量完全被掩盖。
3. 无sleep/wakeup开销:独立集群部署,不再需要卸载/重载模型参数(4B模型省10秒,35B模型可能省50-80秒)。
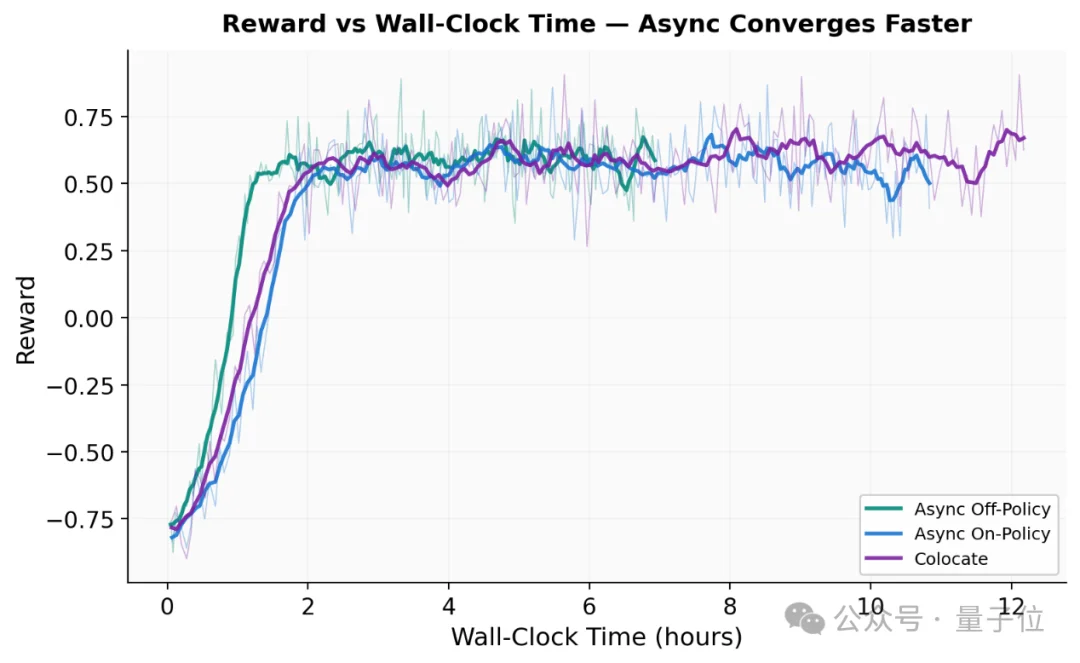
最关键的问题:跑这么快,效果打折了吗?
按wall-clock time看,三种模式最终收敛到相同reward水平,但Async Off-Policy达到同等reward的wall-clock时间比Colocate缩短43%。更快收敛,效果不掉。
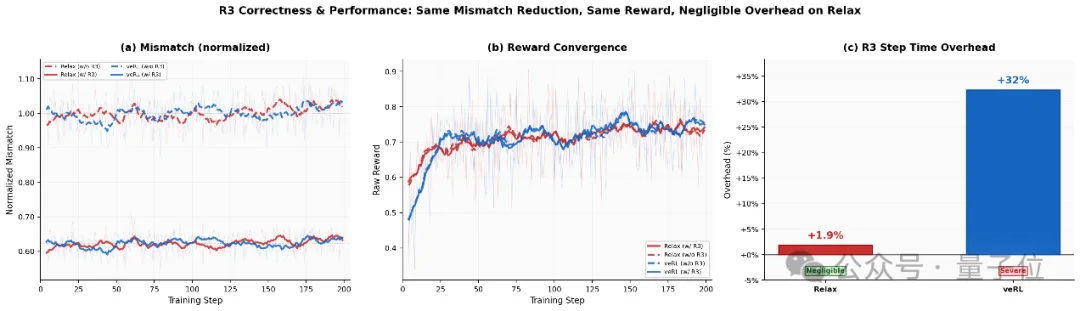
MoE模型在RL训练中有个隐蔽的坑:Rollout和Training阶段的expert路由可能不一致,导致log probs mismatch从而加重off-policy。
Relax的R3(Rollout Routing Replay)在Rollout时记录路由决策,Training时原样回放:
Mismatch降低约38%,Relax额外开销仅+1.9%,veRL为+32%。
为什么差这么多?因为Relax的异步pipeline天然吸收了R3的开销——序列化路径重写+异步device-to-host传输,R3完全跑在关键路径之外。
当RL训练从纯文本单轮走向全模态Agentic,数据异构、系统脆弱、角色耦合三重困境不再是可以分别解决的独立问题。Relax的回答是一套协同设计:全模态原生pipeline解决数据异构,服务化隔离+DCS快速恢复解决系统脆弱,micro batch级全异步流水线解决资源利用率——三者因果闭环,缺一不可。
Relax的落地有赖于开源社区的支持,研究团队希望在此致谢:
感谢Slime和SGLang团队在Ray+Megatron+SGLang结合用于RL训练方面的基础性工作,Relax正是在此基础架构之上构建的。感谢NVIDIA Megatron Bridge团队开发的开源checkpoint转换框架,Relax将其扩展以支持全模态模型。感谢华为昇腾TransferQueue团队开发的开源异步数据总线,它是Relax分布式架构的数据面核心。
GitHub:
https://github.com/redai-infra/Relax
License:
Apache 2.0
文章来自于微信公众号 "量子位",作者 "量子位"



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
