# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

图文原创:亲爱的数据
AI已经是一个彻底围绕Token的生意了,
或者说,Token经济学就是推理经济学,
我认为,今时今日的AI,
连这种基础设施层的东西(比如网络),
都和业务理念融为一体了,
这真是一个大趋势。
而TPN本身就是这个趋势的产物。
TPN架构的全称是:
Token Performance Network。
怎么描述我的感受呢?
一个网络架构用业务术语—
Token来命名自己,
这在以前是不可想象的。
只能说,阿里云的TPN,
是一个现象级的事件。
TPN 的命名本身就很有意思,
网络团队不再说"我的带宽是多少",
开始说"我的Token产能是多少"。
文章开头那么只能解释这么多了,
赶紧上车吧。
为什么大神Jeff Dean在GTC 2026上,
会强调这样一句话?
『Agent一旦开始长时间自主运行,
超低时延的推理就会变得关键。』
这里有个技术术语,
超低时延是Ultra-low-latency inference。
这话啥意思?
作为写了AI 基础设施九年的人,
我恨不得,
把Jeff Dean大神说的每一句技术评价,
都尽可能的理解了。

你问一个问题,模型想了想,总要花点时间。
只要别太磨蹭,都能接受。
现在换成Agent,
则是另一个游戏规则。
Agent一旦长时间自己跑起来,
每一步的"思考速度"就变得生死攸关。
比如,一个任务可能跑200轮。
中间都是它自己玩,
每一轮都有延迟,
直接叠加成总时间,
反正时间总是越加越长。
如果每一轮推理需要2秒,
200轮就是400秒。
7分钟光花在"思考"上。
真是太棒了,
这时候人类老板就会说,
你能不能干?
不能干有的是智能体能干。
再看"超低时延(ultra-low-latency)" 这个词。
为什么他用这个词,
不是"低延迟就行",而是"必须超低延迟"。
我赞成使劲卷AI,
以免来卷我。
看看英伟达的Bill哥(BillDally)怎么回应的,
Bill哥说,大部分延迟实际上来自通信。
Bill哥还说,"推理不是刚刚开始变得重要。
推理现在就是核心任务。
数据中心里90%的机器都花在推理上了。
反正在AI市场上,
英伟达公司高管说啥都有几份道理。
你就凑合听一听,
观察和独立判断更重要。
比如,你看,英伟达的Groq 3 LPU芯片,
是专门为其中一个阶段(Decode)设计的,
而不是AI生产的全阶段。
于是,市场上有了"为特定推理阶段定制的芯片"。
所以,这个趋势不只发生在网络层,
其实整个AI全栈都在经历同样的融合。
为什么2026年突然冒出一个TPN?
因为游戏规则变了。
2022到2025年,行业的核心焦虑是:
"模型能不能训出来"。
所以以前(HPN)的哲学是,
"不惜代价把性能拉满",
现在(TPN)的哲学是,
"在保住Token产(性)能的前提下,
把成本压下来"。
所以TPN不是HPN的升级版,
是另一个物种。
TPN是网络层的证据,
Groq LPU是芯片层的证据,
KV-Cache分层存储是存储层的证据。
整个AI Infra软件栈,
收敛成"一切为Token服务"。
这真是一场深刻的变化。
你不细看,确实会错过。
再看组织团队的KPI变化,
长久以来,
网络团队的KPI是带宽、时延、丢包率。
推理业务团队的KPI是三个新指标,
TPOT,是Token之间延迟
Goodput,有效Token吞吐
Cost per Token,每个Token成本。
在下一节会展开。
我看到,新指标把所有人的目标都统一了。
老掉牙的故事是,
两拨人目标不同,开不同的会,各干各的。
但是,有一天坐下来一起开会的时候,
发现一个问题:
网络团队说:"我们把交换机升级了,
带宽翻倍了"。
推理业务团队说:"用户还是觉得慢"。
两边看着对方,陷入沉默中。
这肯定是不行。
阿里云已经回应这种变化了,
TPN就是直接证据,
网络团队不再说"我的带宽是多少",
而是开始说:"我的Token产能是多少"。
网络的度量单位从比特变成了Token。
这不是换个名词的问题,
是新故事的逻辑全部重写了,
逻辑包括优化目标、架构设计、资源调度。
以前网络优化一条链路,
不需要知道上面跑的是什么业务。
现在网络必须知道,
这条链路搬的是KV-Cache吗?
这是在推理prefill,还是在推理decoding?
回到讨论的主线,
为什么要看新指标
?
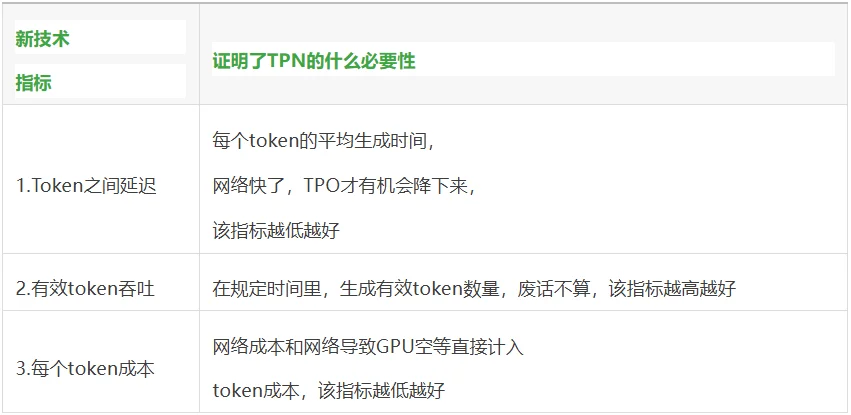
第一,TPOT(Token之间延迟),
第二,Goodput(有效Token吞吐),
第三,Cost per Token(每个Token成本)
旧阵营要迈往新阵营,就是靠指标来导向。
这些指标并不是以前完全没有,
而是重要性今非昔比。
第一个指标:TPOT,是Token之间延迟。
一个Agent跑一个任务,
烧1000个Token,
每个Token之间隔一小段时间,
这就是TPOT。
TPOT长,任务就慢;
TPOT短,任务就快。
就这么简单。
原来跑完要一小时,TPOT压缩一半,半小时干完。
怎么搞呢?
其中一个关键就是KV-Cache搬得快。
PD分离之后,这些东西不在一起了,
要通过网络从另一台机器搬过来。
搬得慢,就等着。
第二个指标Goodput,
是有效Token吞吐。
"有效"这个词确实有两层含义,不能混在一起。
第1层:基础设施层面的"有效"
这个"有效"关注的是,
"Token 吐得够不够快、够不够稳"。
跟网络强相关,网络抖动一次,
Goodput就低一分。
第2层:业务层面的"有效"
你说的是另一个维度,
生成出来的Token 是不是用户真正需要的。
『喂妖妖零吗?
这个AI动不动给我1000个字的废话。
我要取消订阅』。
对于Agent来说,100个Agent 里面,
有15个跑得慢,
但要100个Agent全部跑完才能下一步,
这也拖慢了业务,
Goodput 对网络的要求不是『平均快』,
是『每一次都快』。
第三个指标Cost per Token,
就是每个Token成本。
和钱有关好理解,
就是直播间里的主播说的,把价格打下来。
就一句话:同样的电费、同样的卡,
能多吐几个Token,
每个Token就便宜几分钱。
GPU上电就烧钱,
不管它在算Token还是在等数据,
电表都在转。
所以Cost per Token的关键,
不是GPU贵不贵,
是GPU闲不闲。
单位产能高,成本就越低。
同样的时间下,总产能上不去,
单位产能不可能高。
三个指标的属性是啥?
1.TPOT(Token之间延迟)
是体验指标,度量用户感受。
2.Goodput(有效Token吞吐)是效率指标,
体验达标前提下的最大承载量。
3.Cost per Token是经济指标,商业可行性。
终极优化目标:
在Cost per Token最低的前提下,
最大化有效Token的吞吐(Goodput)。
旧思路是:
假设网络性能强了,用户体验就好了。
新思路是:
先定义用户需要什么体感,
反推网络需要做到什么。
比如,文本的TPOT小于50ms,
语音的TPOT小于10ms。
旧思路下网络团队可以自己猛猛优化。
新思路下必须跟推理业务坐在一起。
即便是以前老指标都上了新台阶,
并不代表推理业务部门,
也就是推理集群使用者的用户体验,
我们现在要和他们一起共同制定指标。
网络很牛逼,使用者无体感。
思路彻底转向关注于『体感』,
先做到体感优,再此基础上降低成本。
结论很清楚了,这是一个Token为中心的世界。
网络的技术考量都融进去了。
按这个趋势,
AI基础设施团队应该长这样:
不再有孤岛似的,
"网络团队""存储团队""计算团队"。
取而代之的是"Token生产团队"
你看,顺着我的逻辑,
是不是觉得阿里这次组织架构调整,
是如此的顺理成章。
这是一个在AI浪潮下激流勇进的团队。
26年3月16日,
阿里巴巴正式成立ATH事业群,
目标:创造Token(通义模型训练),
输送Token(MaaS模型推理),
应用Token(千问+悟空+创新),
AI的基础设施是阿里云与平头哥。
文章来自于"亲爱的数据",作者 "亲爱的数据"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
