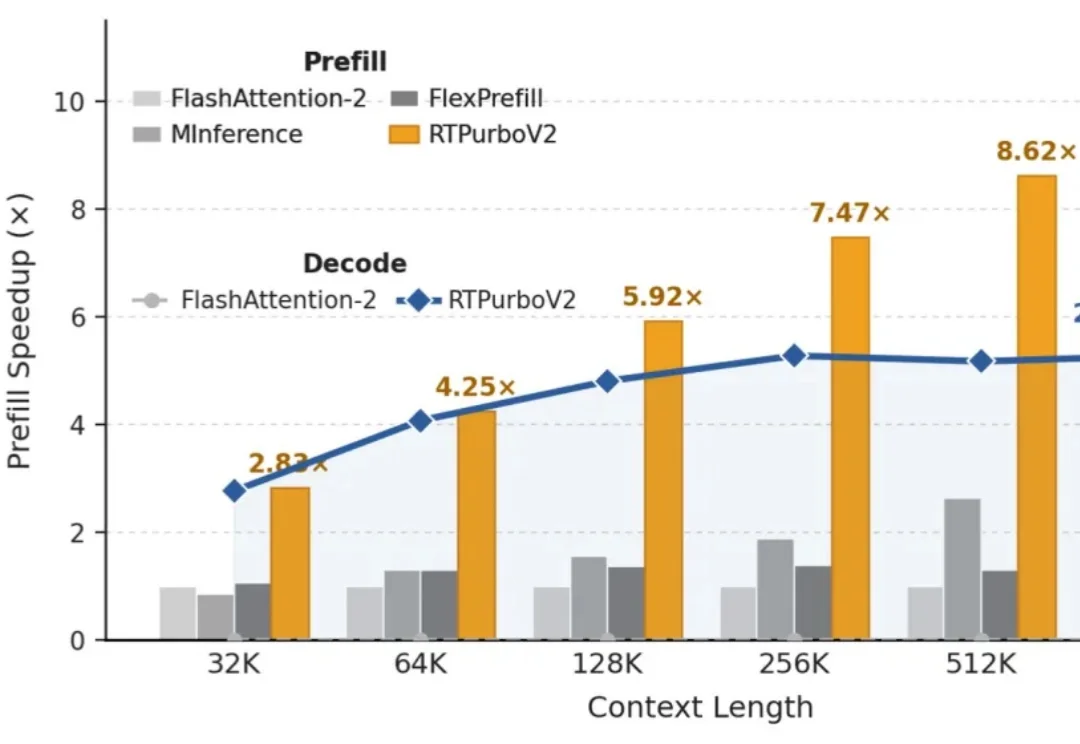
阿里RTPurboV2:原生Transformer再次崛起,百步训练实现10倍稀疏注意
阿里RTPurboV2:原生Transformer再次崛起,百步训练实现10倍稀疏注意“Full Attention 正在被遗忘”
来自主题: AI技术研报
7676 点击 2026-06-08 15:08
 搜索
搜索
“Full Attention 正在被遗忘”

2026年5月30日,半导体研究机构SemiAnalysis发布深度报告《AI Dark Output: The Visible Cost of Invisible Output》,提出了一个“暗产出”的概念,判断AI正在大规模创造真实经济价值,但这些价值在GDP、价格指数和就业统计中几乎无迹可寻,规模“可能不亚于工业革命”。

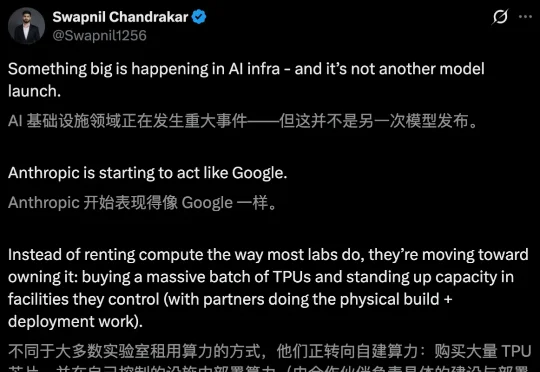
谷歌豪掷400亿美元加注Anthropic,自家Gemini正面对垒的「敌人」。当Claude年化收入一年暴涨30倍冲到300亿,当算力成为AI下半场唯一硬通货,与其用Gemini硬刚,不如把对手变成TPU最大买家。

强如谷歌,算力也不够了。
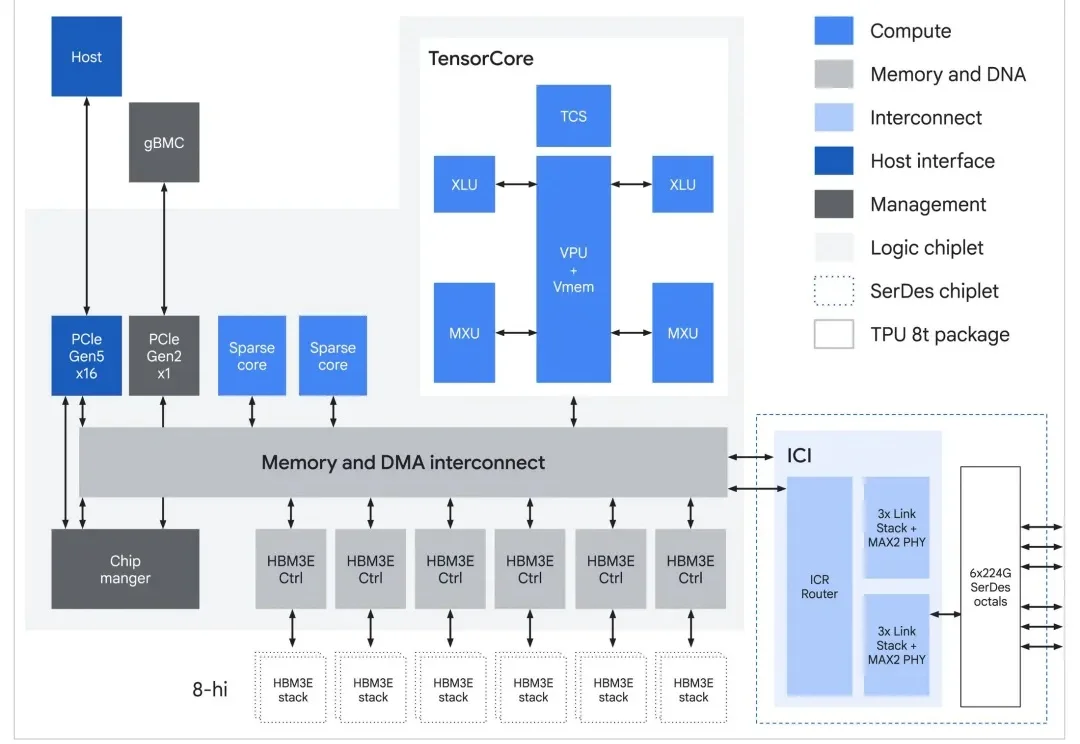
今天,谷歌在 Cloud Next '26 峰会上发布了其第八代 TPU 架构(TPU 8t 与 TPU 8i),TPU 8t 主攻训练,TPU 8i 主攻推理,将在 2026 年晚些时候上市。第八代 TPU 采用申请制,Google Cloud 用户如需使用,需要在官网提交登记需求。

AI已经是一个彻底围绕Token的生意了, 或者说,Token经济学就是推理经济学, 我认为,今时今日的AI, 连这种基础设施层的东西(比如网络), 都和业务理念融为一体了, 这真是一个大趋势。
刚刚,Anthropic年收入首超OpenAI!同时就在今天,一份与谷歌、博通最新合作,将在2027年上线3.5 GW全新TPU集群。这批史诗级的算力,预计从2027年开始陆续上线。
在他们看来,真正的胜负手不在于单点技能拉满,而在于能否在同一颗芯片里,把“训练级吞吐”和“推理级低延迟”同时做好——尤其是在长上下文、Agent循环这些更复杂的真实工作流中。

Meta腾出CoWoS排产「让路」,加上台积电的积极扩产,2026年谷歌把TPU的「算力水龙头」拧到最大,预期产能飙升至430万颗,猛攻英伟达CUDA护城河。
2026年开局,Anthropic未发一弹已占先机!谷歌首席工程师Jaana Dogan连发多帖,高度赞扬Claude Opus 4.5——没有图像/音频模型、巨大的上下文,仅有一款专注编码的Claude,Anthropic依旧是OpenAI谷歌最有力竞争者。