# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当 AI 智能体不再只是「一次性工具」,而是能够持续学习、自我进化的「数字伙伴『数字同事』,会发生什么?自进化智能体应该采取怎样的设计原则?
全球首个基于「上下文信息密度最大化」设计原则的自进化智能体系统 ——GenericAgent(GA),正式发布其技术报告。
报告显示,GA 能在保持任务准确率前提下,比同类竞争对手节省近 10 倍 Token。报告深度解读了 GA 的核心设计理念,介绍了自进化智能体的评测基准,并给出了评测数据,全面剖析 GA 的自进化能力以及智能体设计的可靠思路!
整个报告长达 47 页,今天大家可以一睹为快!

GenericAgent(GA)是复旦大学知识工场实验室旗下 A3 实验室(Advantage AI Agent 实验室,与深圳夸夸菁领科技有限公司合作)构建的一个通用型、自进化 LLM 智能体系统。
GA 是下一代自组织、自学习、自进化的通用智能体的代表之一,是一个拥有「生命感」,能够在用户使用调教下快速学习与成长的数字生命。GA 技术的商业应用版是 DinTal Claw,旨在将这一自进化架构深度应用于政企场景,打造低成本、高效率、安全可控的「数智员工」实战标杆。
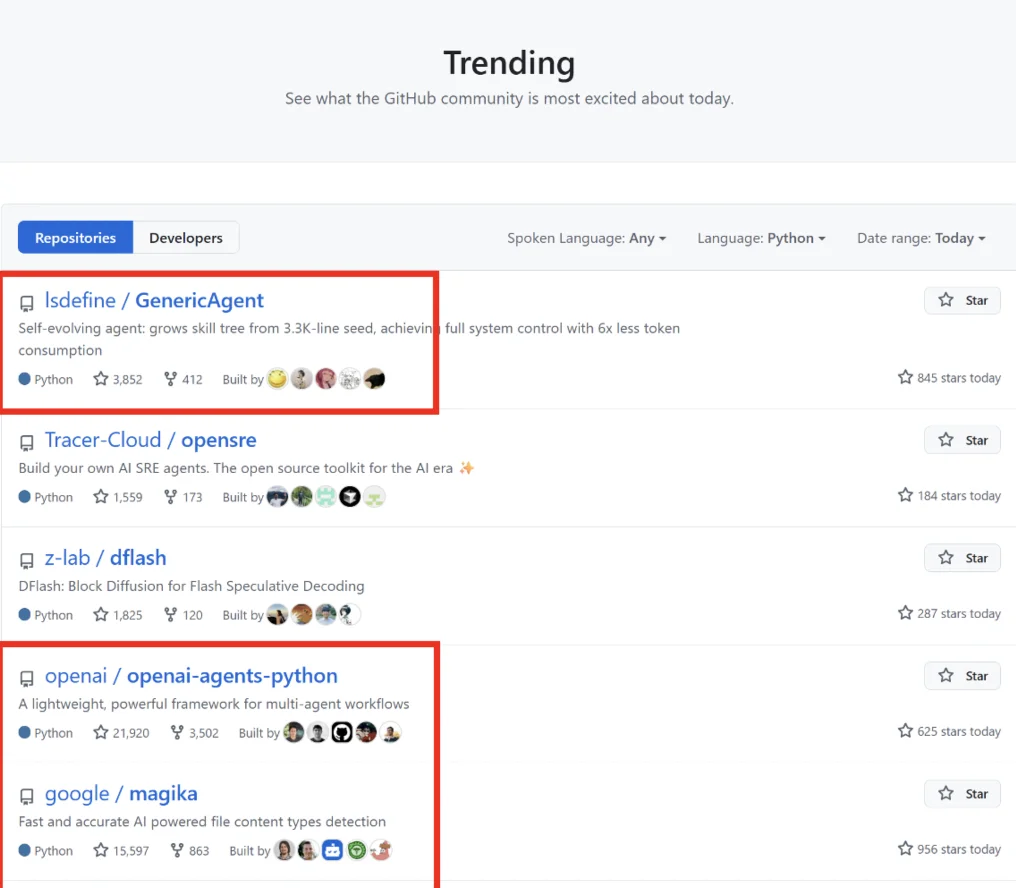
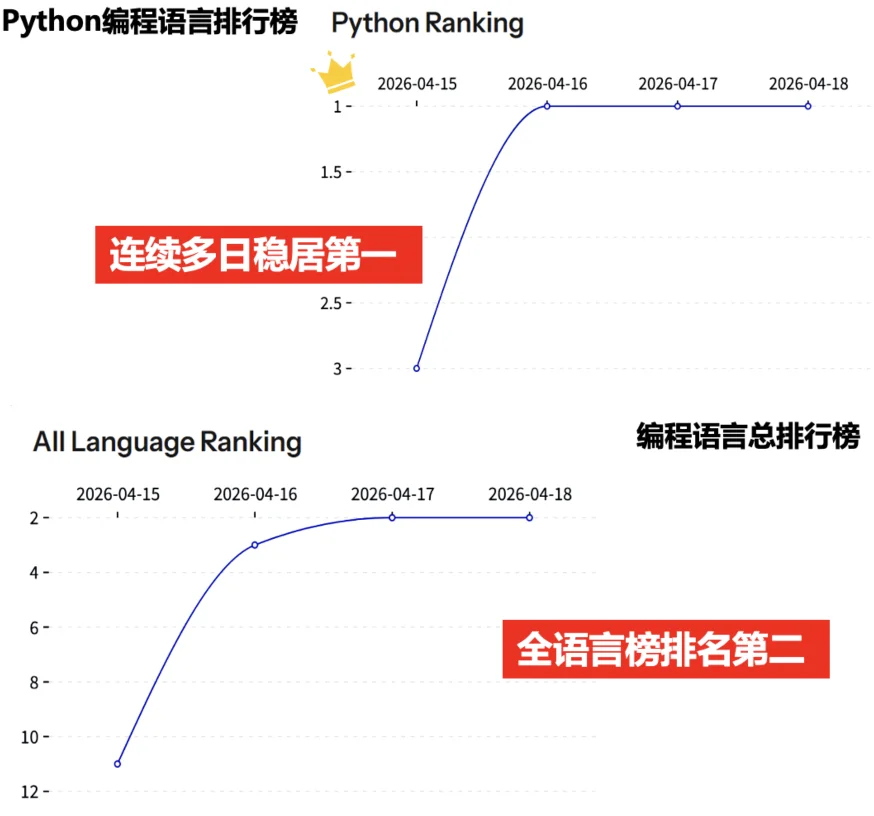
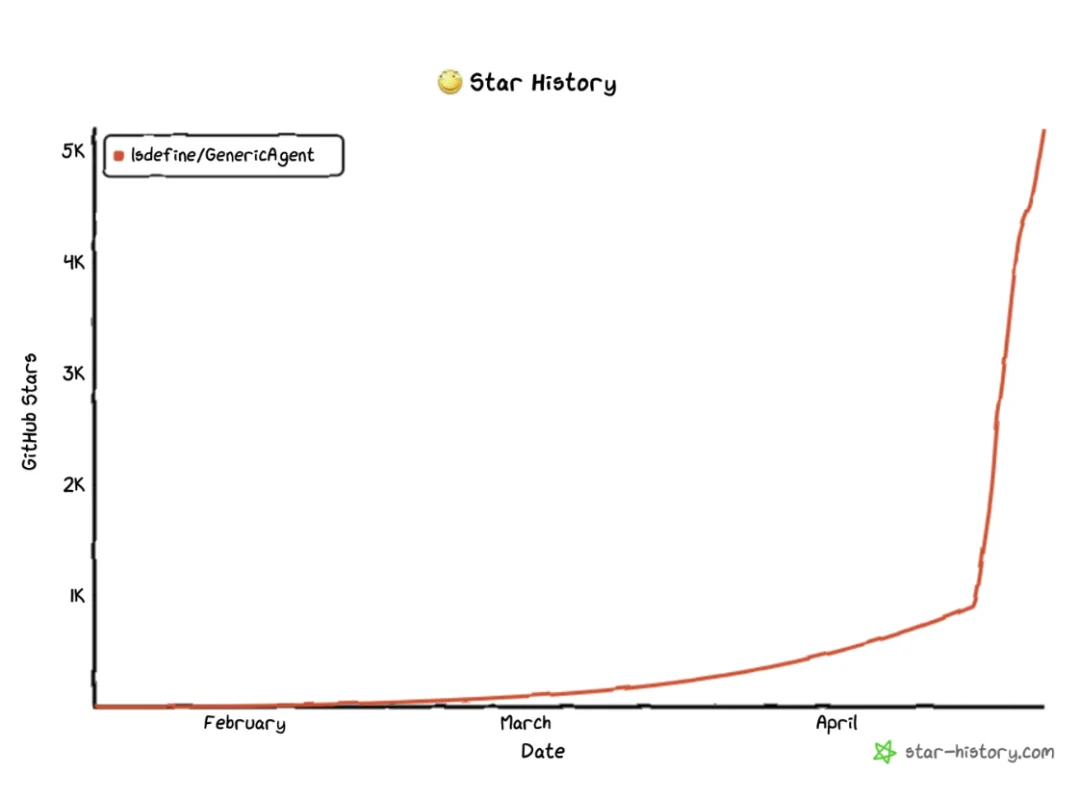
GA 自 2026 年 1 月 11 日开源以来,一度在 github trending python 编程语言登顶第一。力压OpenAI、Google 等头部AI企业的开源系统。
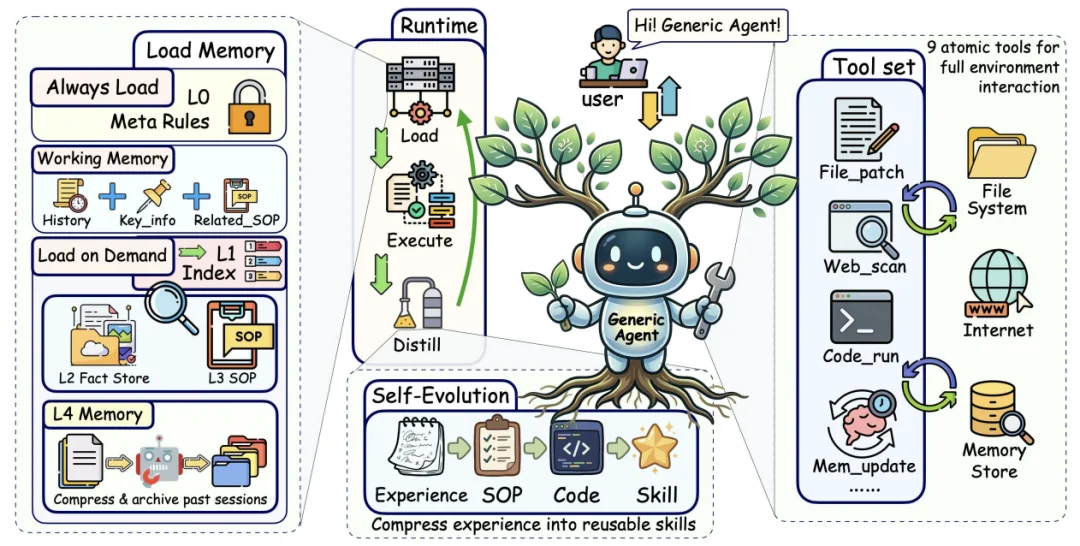
GenericAgent 整体架构图
最近,从 Claude Code、OpenAI Codex 到 Openclaw,AI 正在从被动的文本生成器,转变为能够主动操作终端、文件系统、浏览器的「目标导向型代理」。但是,一个直接的问题摆在用户面前:「他们真的好用吗?」
传统智能体随着交互增多,上下文越来越长,即「上下文爆炸」。关键信息反而被淹没。结果就是:步骤越多,出错率越高。
今天总结的经验,明天换个会话就没了。智能体一直在「重复造轮子」。Token 消耗随任务数量线性增长,但有效能力却保持停滞,形成一个没有累积交互回报的「停滞循环」。
面对这些问题,研究团队提出了一个重磅观点:
长周期性能的决定因素,不是上下文长度,而是在有限的上下文预算内能够维持多少与决策相关的信息。
换句话说,上下文信息密度才是核心。通过最大化上下文信息密度可以保证:决策信息不遗漏、冗余信息被消除、上下文可读性高(次要但重要)。
基于「上下文信息密度最大化」这一核心原则,GA 通过四个紧密关联的组件实现了 Agent:
机制一:最小原子工具集
工具最小化不是限制,而是 GA 在减少交互开销的同时保持通用能力的核心机制。
GA 只保留了 9 个原子工具,分为五类能力:文件操作、代码执行、网页交互、记忆管理、人在回路。并且,这几个原子工具能够通过组合泛化,造出新的工具来解决复杂任务。
有趣的是,仅「code_run」这一个工具在理论上就是图灵完备的,可以复制所有其他工具的功能。那为什么还要保留其他 8 个工具?答案是:最小原子工具集可以降低任务的决策成本。

上表为长程复杂任务结果。五项任务涵盖文档生成(PDF/PPT 创建)、SQL 协作查询生成、实验分析报告撰写、结合网络检索的采购决策,以及研究论文复现可行性分析,本表报告的是长程任务集上的平均结果。
机制二:分层按需记忆
记忆的核心是按需存取。GA 的关键设计是默认仅注入元记忆和 L1 索引层,遵循 L1→L2/L3 路由链,仅在需要时检索更深层的事实或程序知识。这样,记忆不会稳步挤占当前任务所需的活跃上下文预算。
GA 将记忆组织为四层架构
更巧妙的是,随着 L2 和 L3 增长,L1 保持有界。每个 L1 条目仅记录知识类别的「存在性」—— 而非其内容。
这种极端压缩之所以可行,是因为 LLM 本身充当解码器:一旦它识别出相关能力或事实存在,就可以通过工具调用从更深层检索完整内容。
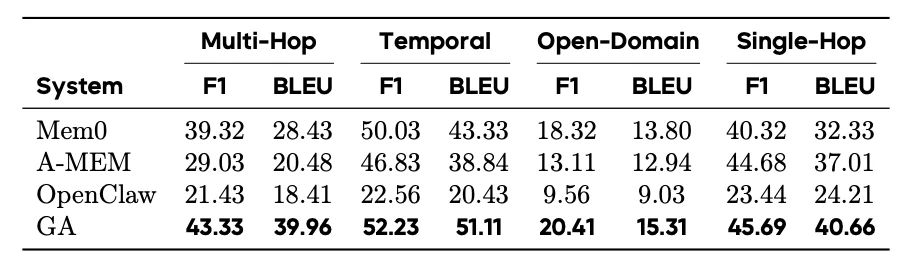
上表为 GA 等在 LoCoMo 上的长期事实记忆评估。GA 基于自身优越的记忆架构设计,确保了记忆的高效召回。
机制三:自进化机制
GA 将自进化是一个显式且可检查的流程。
什么在进化?解决任务的 策略,而非原子工具。工具接口和用户交互是任务无关的,在运行时保持不变。相反,所有任务特定能力都编码在 SOP 文件和可复用脚本中。
知识如何积累? 通过分层记忆,GA 确保在一个会话中获得的知识在后续会话中立即可用。
进化的质量如何控制? GA 在低记忆层级(L4)保留原始行动轨迹,但不允许它们直接向上传播。L3 的可复用程序仅通过显式整合步骤创建,在子目标完成或成功从失败中恢复等有意义的时间点触发。
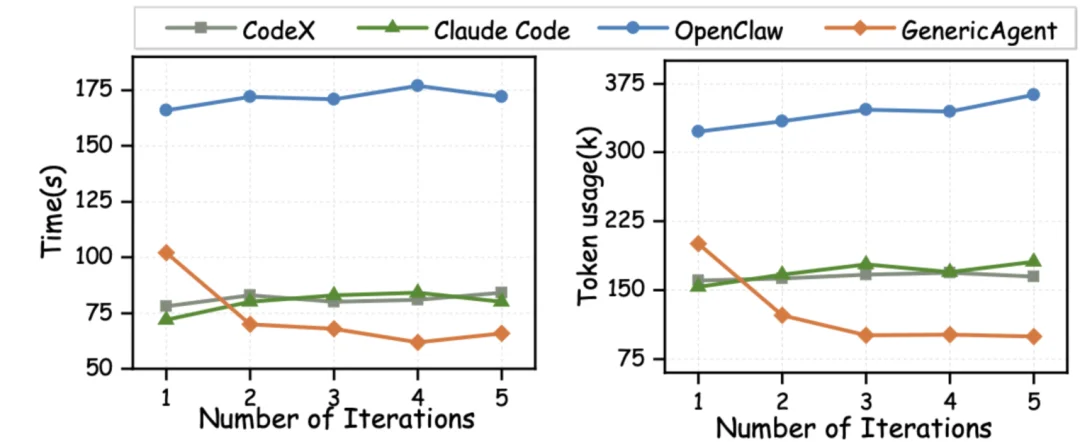
在相同任务五次重复运行中,只有 GenericAgent 随着任务经验的积累不断提升工作效率。
机制四:上下文截断与压缩
GA 聚焦于压缩而非扩展 —— 将更高密度的信息打包到更小的窗口中,优于将稀释的内容输入更大的窗口。
GA 使用四种不同粒度的上下文修剪机制:
这四种机制协同工作,确保活跃上下文不随交互轮数线性增长。
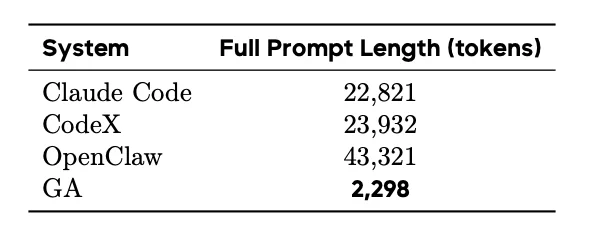
在安装 20 个技能并经过高强度使用后,只有 GA 有效防止了上下文膨胀。
研究团队在多个基准测试上对 GA 进行了全面评估。
核心结论:性能更强,成本更低
先来看最硬核的评测结果。在 SOP-bench、Lifelong AgentBench 和 RealFinBench 三大基准测试中,GA 的表现堪称惊艳。
在 SOP-bench 和 Lifelong AgentBench 上,GA 以 100% 的准确率全面领先;在更贴近真实场景的 RealFinBench 上,GA 以 65% 的准确率登顶行业第一。
同等任务下,GA 的 Token 消耗仅为其它主流智能体系统的 15% 到 35%,真正做到了「花小钱办大事」。
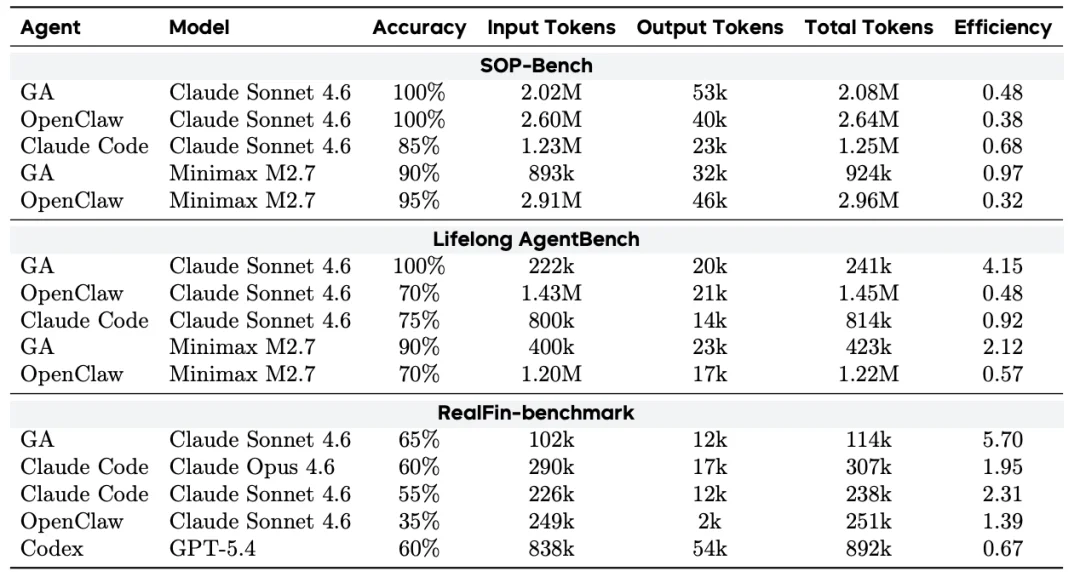
任务完成率与 Token 效率对比图
越用越聪明:重复执行效率跃迁
GA 自进化能力保证了它的高效。
当其他系统在重复执行同类任务时,耗时和 Token 消耗基本是一条直线,只有 GA 越用越好用。5 次重复运行后,运行时间从 102 秒降至 66 秒,Token 消耗从 20 万直接腰斩至 10 万。
这不是简单的缓存复用,而是 GA 把第一次试错的经验,自动提炼成了可复用的标准操作流程,让后续任务真正实现了「站在肩膀上出发」。
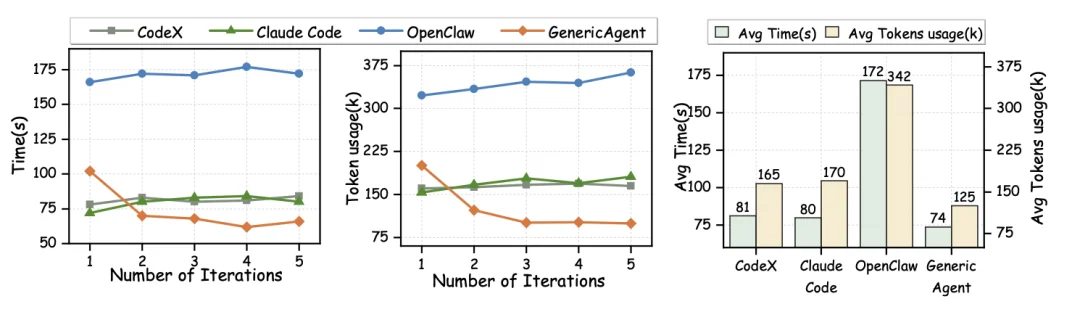
重复运行效率提升曲线图
这种进化能力还能跨任务泛化。在 8 个不同网页任务的重复测试中,GA 后续执行的 Token 消耗平均下降 79.3%,最高单任务节省达 92.4%。任务越复杂、依赖链条越长,节省效果越显著。
相比之下,主流智能体系统在多次运行中数据波动不定,仍在重复探索,而 GA 展现出清晰的「冷启动→快速收敛」模式,真正学会了如何学习。
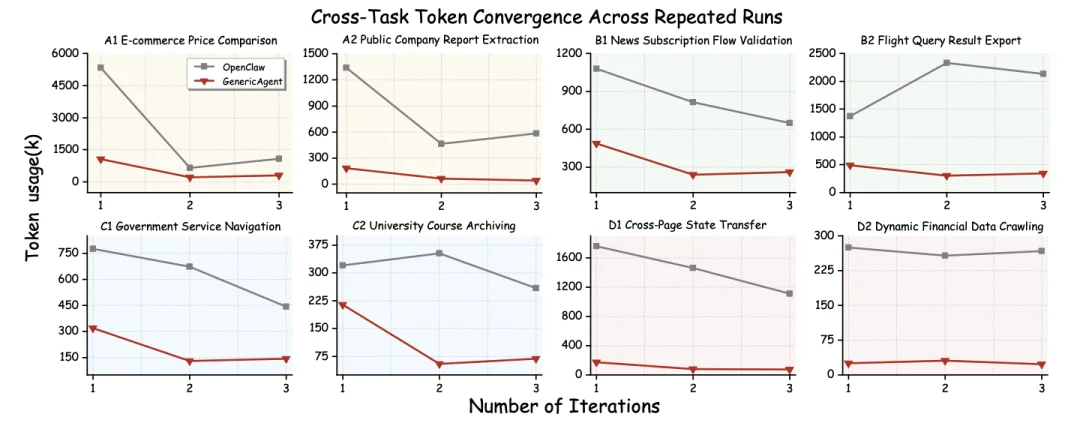
跨任务 Token 收敛对比图
长期进化:从「学徒」到「专家」的蜕变
长期进化的性能更高。第一轮执行时,GA 需要 7 分 30 秒、调用 32 次大模型、消耗 22.2 万 Token;而到了第九轮,仅需 1 分 38 秒、5 次调用、2.3 万 Token 即可完成同等任务,Token 消耗减少 89.6%,调用次数减少 84.4%。
这种从探索到执行、从文本 SOP 到可执行代码的进化,不是人工干预的结果,而是系统自主完成的。
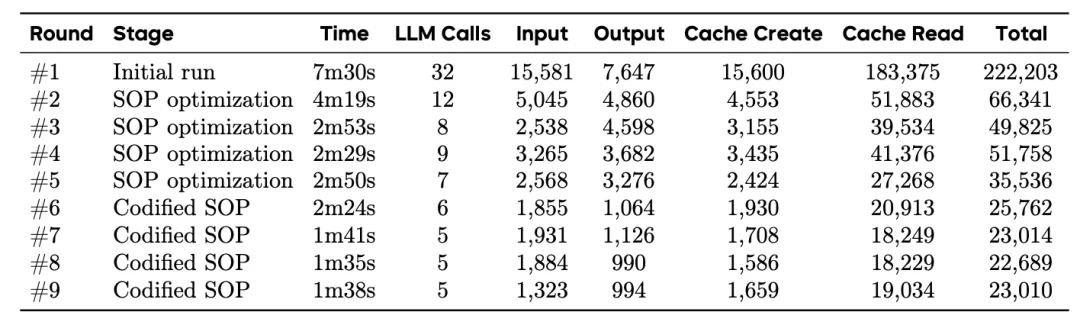
九轮进化轨迹数据图
网页浏览:在混乱中保持清醒
网页是智能体的「终极考场」,一个网页的访问动辄为 Agent 引入上百万 token 开销,而 GA 在这里同样表现出色。
在最具挑战的 BrowseComp-ZH 多跳推理任务中,GA 准确率达到 0.60,是主流智能体系统 0.20 的整整 3 倍,同时 Token 消耗仅为其三分之一;在真实网页任务中,GA 以 0.26M Token 获得 0.577 分,主流智能体系统消耗 0.76M Token 仅得 0.50 分。
面对海量 HTML 噪声和动态 DOM 元素,GA 的上下文压缩与分层记忆机制展现出压倒性优势,真正做到「在复杂环境中不迷路」。
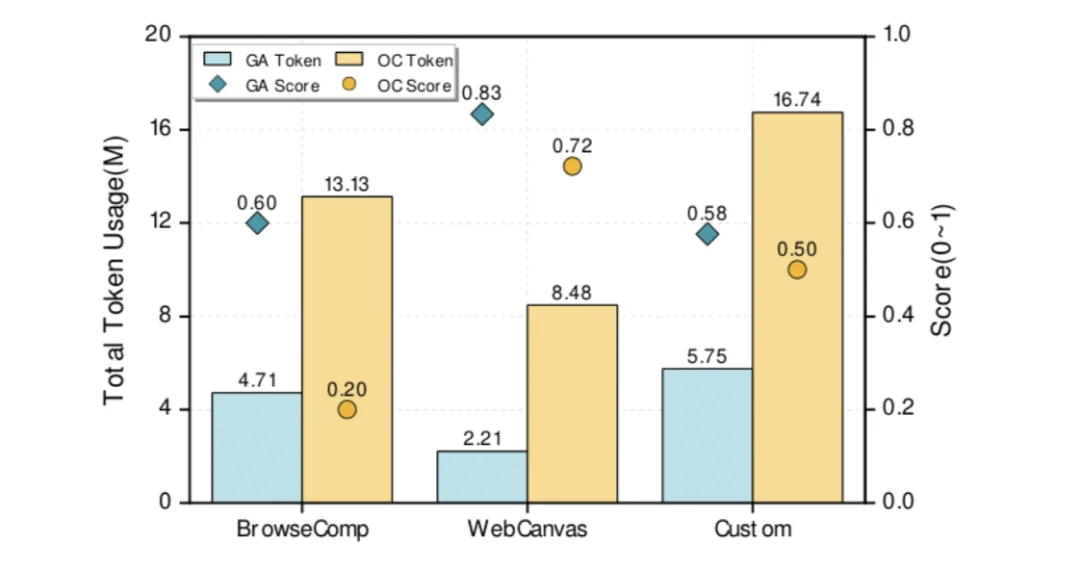
网页浏览性能对比图
从 GenericAgent 的开发中,研究团队提炼出五个关键发现,这些发现对 LLM 智能体系统的设计具有广泛相关性。
发现一:上下文信息密度是结构性约束
上下文信息密度不是「可选」的优化目标,而是每个智能体系统必须通过设计面对的结构性约束。只要智能体使用 LLM 作为其推理引擎,每个决策步骤的质量最终在单次前向传播内确定,无论工具、记忆容量或工作流复杂度如何,都无法规避此约束。
发现二:存在智能体系统的最小完备能力集
在信息密度的结构性约束下,智能体只需实现三种能力。任何不服务于这三种能力之一的设计都在引入额外复杂度,从而降低信息密度。
发现三:更低 Token 消耗对应更好任务性能
这一发现违反直觉,因为普遍假设是更长的推理链和更多交互轮次反映更彻底的深思熟虑,因此应产生更好结果。然而,实验结果在长周期智能体执行设置中系统地指向相反结论。
在 Lifelong AgentBench 上,GA 仅消耗 Claude Code 输入 Token 的 27.7% 和 OpenClaw 的 15.5%,同时实现更高的 100% 任务完成率。
超过某个点后,额外 Token 不会引入更多有用信息,反而通过位置偏差、注意力稀释和有效窗口收缩降低推理质量。消耗更多 Token 的智能体更是上下文管理的系统性失效导致的,通过额外交互补偿每步决策质量的退化,而非改进它。
发现四:权限定义智能体能力的上限
智能体能接触多少环境,就能获得多少智能。
智能体能感知什么、能作用于什么、能从什么反馈中学习,直接决定它能发展的推理链复杂度和能解决的任务难度。一个小规模沙箱中的 agent,不论他多么安全,他的智能水平是极其有限的。在智能体探索阶段锁定行动边界,等同于在系统设计阶段预先封顶其能力上限。缩小探索边界不是构建有用智能体的路径,其终点是一个安全但无用的系统。
发现五:最小架构是智能体自主进化的必要前提
开发团队提出一个新的、更长远意义的「自进化」三个维度:
因此,当架构足够精简时,Agent 可以审视和修改自身,最终实现 Agent 的自进化。一个拥有数十万行代码的系统对智能体是不透明的 —— 它既无法理解也无法修改。相比之下,几千行的核心代码库是可读、可理解、可修改的。在 GA 的最小架构中,作为原生执行面的自托管 CLI 自然使子智能体能够读取和修改核心代码库,使架构自更新成为实际的、可实现的。
GenericAgent 的技术报告拆解出了一套全新的智能体架构设计框架,它揭示了大量现有 Agent 的设计是盲目的。GenericAgent 仅用 3000 多行核心代码实现的能力,充分展示了智能体未来发展的无限前景。
GenericAgent 自 2026 年 1 月 11 日起已经开源,目前在 Github 已获超过 5.2K+ Star,进入 Github 趋势榜。欢迎大家一起见证智能体的进化时刻!
敬请关注 GenericAgent 的商业落地版本,更智能、更省钱、更安全、更稳定的 Dintal Claw 的最新动态!
团队以往研究工作:
文章来自于"机器之心",作者 "机器之心"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
