# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,腾讯混元团队提出HY-SOAR(Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
SOAR不依赖奖励模型、不用偏好标注、不靠负样本,直接从训练数据中挖掘轨迹级纠正信号,让模型在去噪过程中学会自我反思和纠偏——为视觉生成模型的后训练提供了一条全新的路径。
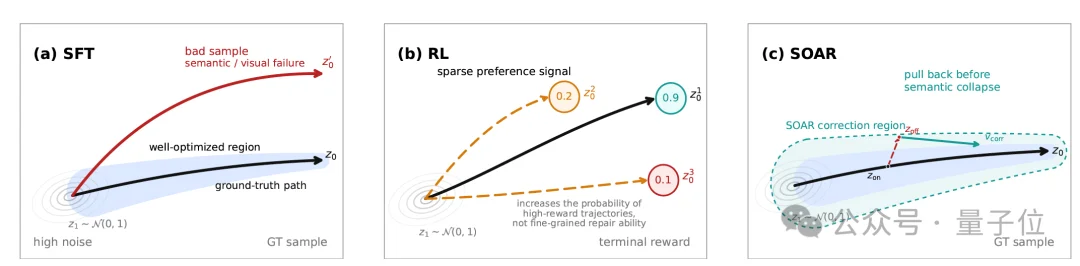
扩散模型后训练的两条主流路径——SFT和RL——都在数据利用上存在明显的短板。
SFT是只学 “标准答案”,不会 “改错”:SFT直接在高质量数据上做监督,但它只教模型处理“理想轨迹”。真实数据前向加噪得到的标准中间状态。问题在于,推理时模型走的是自己的轨迹,一旦早期去噪出现偏移,后续状态就进入了训练中从未见过的区域。数据中蕴含的“模型可能如何走偏、如何纠正”的信息,SFT完全没有利用。
RL则走了另一条弯路——把信息 “压缩丢了”:先把高质量数据通过奖励模型转化为终端打分,再用这个稀疏信号去优化整条生成轨迹。这本质上是一次有损压缩——数据中丰富的轨迹级信息被压缩成了一个标量奖励,大量可用于纠正中间步骤的信号在转化中丢失。更糟的是,奖励信号的稀疏性还会导致信用分配困难和奖励作弊(reward hacking)。
旗舰模型=数据质量×数据利用率。当数据质量足够高时,瓶颈在于利用率。RL在利用率上打了折扣,SOAR的目标是把这个折扣拿回来。
大语言模型的进化路线是:预训练→ SFT → RLHF →自我反思(以o1/o3为代表的self-correction)。视觉生成模型正在走同样的路,而SOAR正是这条路上的关键一步。
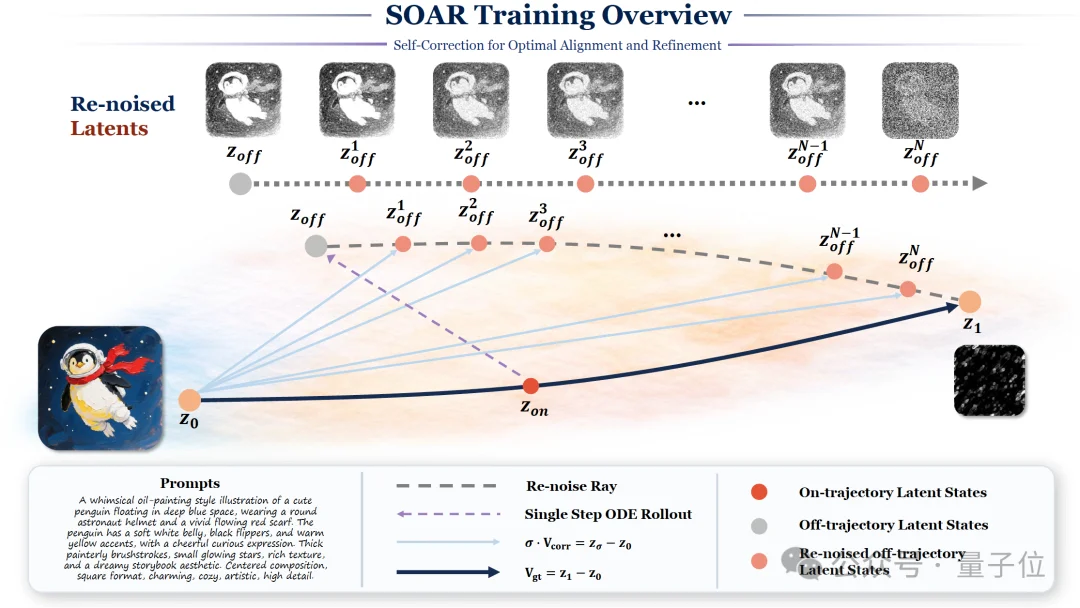
SOAR让扩散模型第一次具备了“在生成过程中审视并修正自身行为”的能力,它的工作逻辑很清晰:
整个过程不需要奖励模型、不需要偏好标注、不需要负样本——纠正信号完全从数据本身解析得到。
这使SOAR具备三个关键优势:
数据利用率最高:从同一份数据中同时提取“标准答案”和“纠偏信号”,无需经过奖励模型的有损转换。
稠密信号:在去噪中间步骤即获得纠正监督,而非等到生成完成后才得到一个终端奖励。
在线学习*(on-policy)*:偏离状态来自当前模型自身的推理,训练分布随模型更新而自适应变化。
这不再只是一个训练技巧的改进,而是生成模型从“被动执行指令”走向“主动审视和纠正自身行为”的范式跃迁。
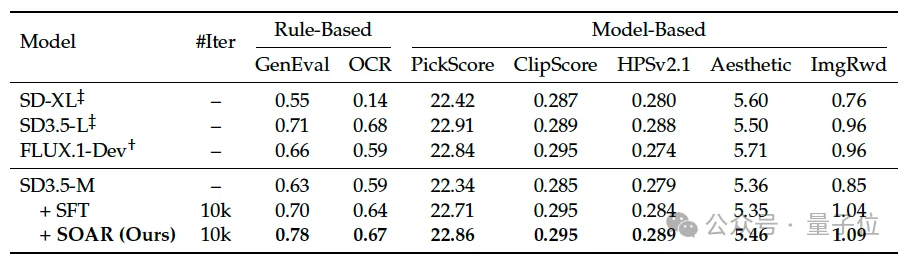
基于SD3.5-Medium、286K图文样本训练,不使用任何奖励标注。SOAR在所有报告指标上均优于SFT:GenEval 0.70→0.78,OCR 0.64→0.67,DrawBench上PickScore、HPSv2.1、Aesthetic、ImageReward同步提升。
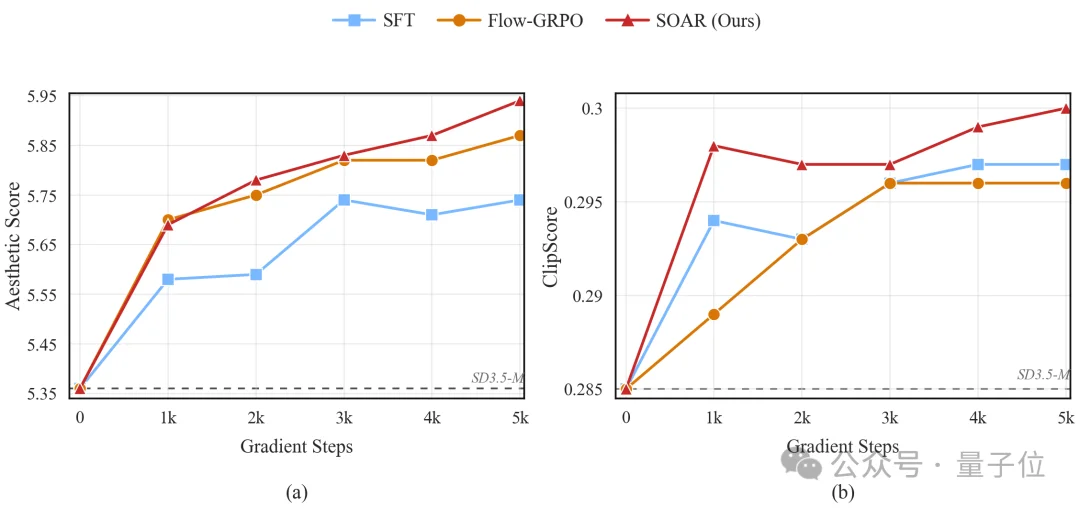
在高美学和高CLIPScore子集上的专项对比中,SOAR不仅在目标指标上呈现稳定的单调提升,最终数值还优于直接优化对应奖励的Flow-GRPO(Aesthetic 5.94 vs 5.87;ClipScore 0.300 vs 0.296)。换言之,不用奖励模型的SOAR,比用奖励模型做RL的Flow-GRPO效果更好——这正是更高数据利用率带来的红利。
SOAR不是要替代RL,而是为RL提供一个更稳定的起点。
当前RL后训练面临的一个核心挑战是:基础模型本身的生成轨迹还不够稳定,直接用奖励信号驱动探索,模型容易在不稳定的区域做出过激调整,导致某个指标提升但其他维度崩塌。
SOAR可以先把模型的轨迹稳定性拉到一个更高的基线——语义不崩塌、结构不走形、文字不乱码——在此基础上再接入RL做偏好探索,模型就能在一个更安全的区间内进行风格调整和质量优化。
类比来说:先学会走稳,再学会按需变换步伐——而不是还没站稳就让奖励信号拽着跑。
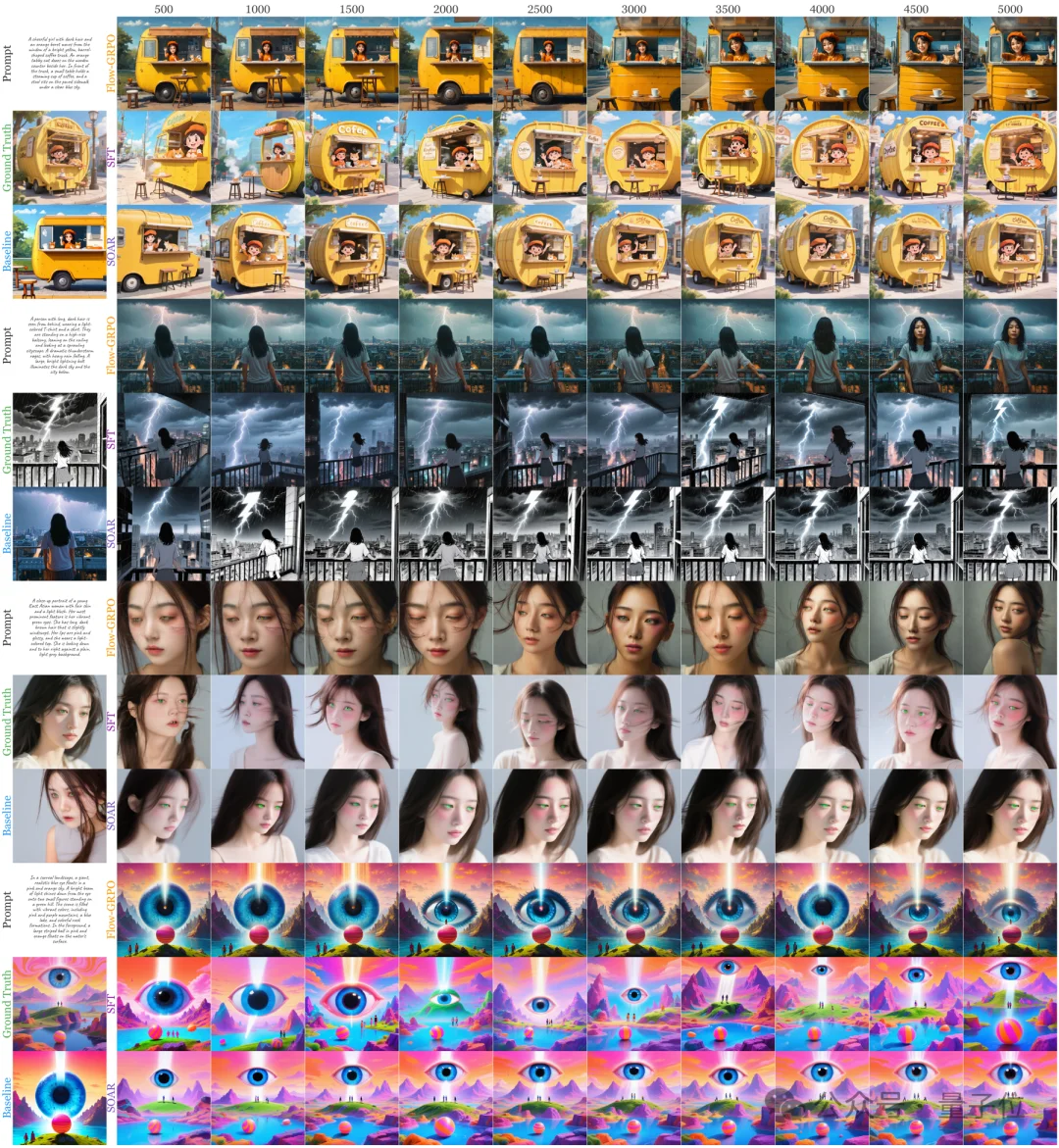


SOAR为扩散模型后训练提供了一条全新路径:不依赖奖励模型,直接从数据中挖掘轨迹级纠正信号,让模型学会在生成过程中自我反思和纠偏。
当数据质量已经足够高时,决定模型上限的不再是数据本身,而是训练方法能从数据中提取多少有效信号。
SFT只用了“标准答案”,RL把数据压缩成了稀疏奖励,而SOAR直接在轨迹层面榨取每一份数据的纠偏价值。这种从“被动模仿”到“主动自纠正”的能力跃迁,有望成为图像、视频、3D及更广义的世界生成模型走向下一阶段智能化的关键基础设施。
目前,HY-SOAR相关论文与代码已公开,欢迎研究者和开发者继续测试、复现和探索。
项目主页:https://hy-soar.github.io
技术报告:https://arxiv.org/abs/2604.12617
GitHub:https://github.com/Tencent-Hunyuan/HY-SOAR
Huggingface: https://huggingface.co/papers/2604.12617
文章来自于"量子位",作者 "腾讯混元团队"。



