# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
搭了个agent,结果该被记住的历史交互经验一点没记住,不该被记住的工具调用结果、过程输出被一股脑塞进上下文,导致输出质量下滑,类似的上下文失焦问题,这是多少人做agent时候的噩梦?

现如今,1M 上下文几乎已经成为各家大模型的标配能力。
但一个有意思的现象是,模型能力增强,反而助长了很多人不做上下文管理的风气,给对话窗口随意堆砌各类冗余内容。导致模型难以快速捕捉核心需求,只能反复输出同质化内容;输出质量下滑又会增加人机交互轮次。最终形成劣质上下文管理 — 低质量回复的恶性循环。
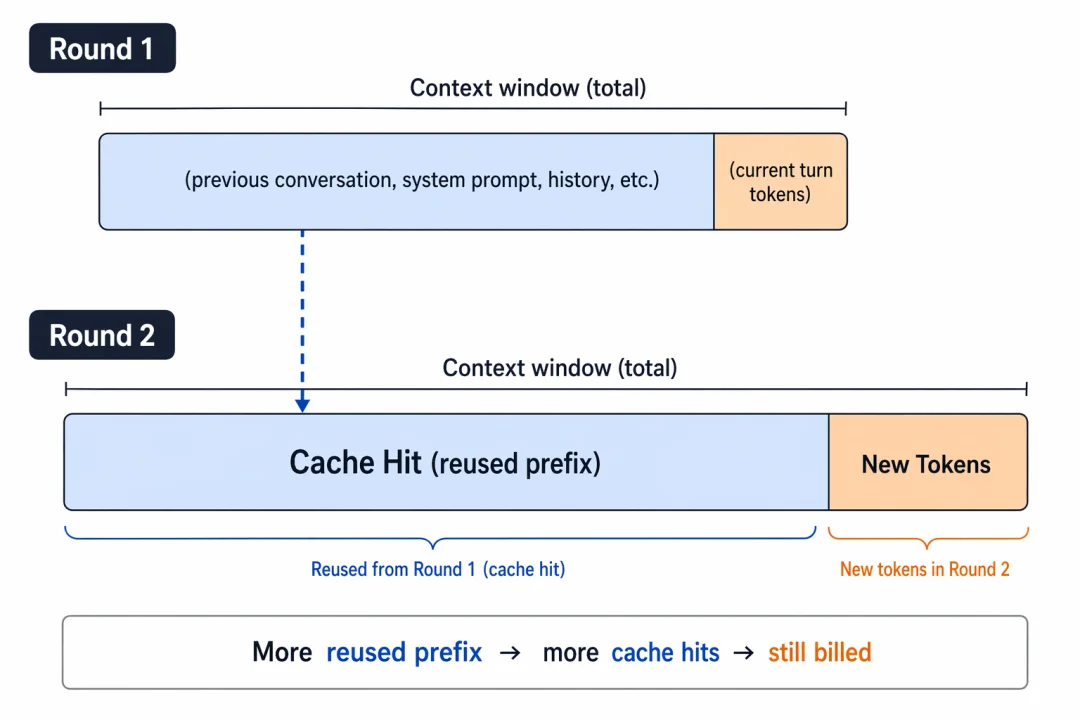
在 AI Agent 场景下,这类问题会更加严重:Agent 需要串联多轮任务、频繁调用工具,过程中会产生大量对结果没意义的交互记录。如果缺少主动过滤、清理冗余信息的机制,任由海量无效日志、过期指令、重复对话不断堆积,反而会让agent的输出结果大打折扣,成本急剧增加。
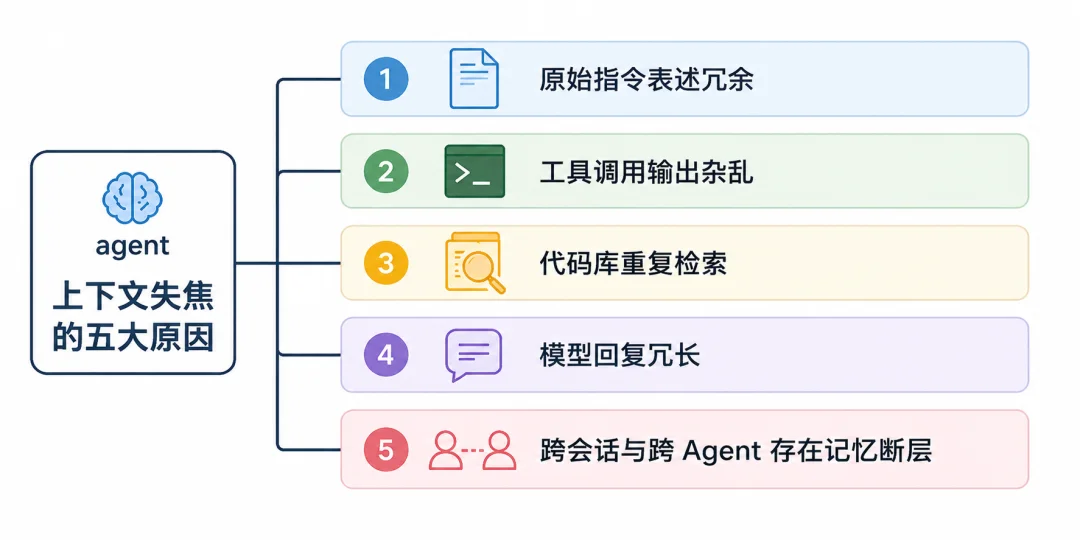
那么问题通常出在哪里?总的来说,有五个方面:原始指令表述冗余、工具调用输出杂乱、代码库重复检索、模型回复过于啰嗦、跨会话与跨 Agent 存在记忆断层。
针对以上高频痛点,本文整理了七款适配 Claude Code 的专用工具,分层解决上下文冗余问题。
项目地址:
https://github.com/rtk-ai/rtk
在 Claude Code 的常规使用中,git status、pytest、目录查看等命令,默认会输出大量环境信息、无关状态描述,但模型实际只需要关心:哪几个文件改了、哪个测试挂了、PR 卡在哪个 check、这个目录里最重要的文件是什么?
RTK 会介入 Shell 与 Claude 之间,用 Claude Code 的 PreToolUse hook 去拦截命令行噪音,把git status这种原命令透明改写成rtk git status,对命令输出做轻量化压缩,然后再交给大模型执行:
原版git status会展示完整分支描述、全量文本说明,压缩后仅保留修改文件、变更数量;
原版pytest充斥大量正常用例日志,压缩后只标注用例总数、失败用例与报错原因。
以下是对比展示:git status 原本喂给 Claude 的,常常是一整段状态说明:
On branch feat/payment-retry
Your branch is up to date with 'origin/feat/payment-retry'.
Changes not staged for commit:
modified: src/webhook/handler.ts
modified: src/queue/dlq.ts
modified: tests/webhook.test.ts
Untracked files:
docs/notes.md
no changes added to commit
但真正有用的,往往只有这几行:
3 modified, 1 untracked
- src/webhook/handler.ts
- src/queue/dlq.ts
- tests/webhook.test.ts
pytest 也一样。原始输出里有大量通过项和环境信息:
============================= test session starts =============================
platform darwin -- Python 3.12.4, pytest-8.4.1
collected 128 items
tests/test_auth.py ....................................
tests/test_webhook.py ....F....
tests/test_queue.py ...................................
================================== FAILURES ==================================
________________ test_retry_to_dlq __________________
E AssertionError: expected status code 202, got 500
压完之后,重点就很明确:
128 tests collected, 1 failed
FAIL tests/test_webhook.py::test_retry_to_dlq
AssertionError: expected status code 202, got 500
另外,RTK还为git、gh、pytest、aws、文件检索等常用工具单独配置压缩规则,我们用的时候,直接在原有命令前追加调用即可。
rtk git status
rtk pytest
rtk playwright test
rtk gh pr view 42
rtk aws lambda list-functions
项目地址:https://github.com/mksglu/context-mode
如果说 RTK 负责精简终端,Context Mode 则专门治理工具返回的超大段冗余文本。
运行自动化测试、读取超长日志、抓取页面 DOM 时,用户通常只需关注报错节点、异常链接、定位失效元素等关键信息,但工具会直接返回完整 DOM、全量调试日志、重复状态数据,大量低密度文本挤占上下文空间。
Context Mode 的做法是,把所有大块工具内容会隔离存储在本地沙盒与 SQLite 数据库,不将工具原始输出直接灌入主对话。
具体来说,PreToolUse前置拦截工具调用请求并启动沙箱隔离执行,PostToolUse阻断海量原始工具输出直接注入上下文,基于上下文虚拟化将全量原始数据本地索引持久化,仅向模型传递极简摘要与索引标记;PreCompact阶段自动压缩无效上下文密度,模型需细节时通过 Hook 回调触发精准按需检索。

它比较适合两种人。第一种是重度 Playwright、GitHub、日志流用户。第二种是已经挂了不少 MCP server,结果 session 一开,光工具定义和工具输出就先吃掉一大块上下文的人。
项目地址:https://github.com/tirth8205/code-review-graph
这个项目很适合仓库过大导致Claude 一上来就开始迷路的情况。
比如你只是想问一句:
这个登录逻辑改了之后,会影响哪些文件和测试?
Claude 如果没图谱,常见动作就是:
read auth.ts
grep login
read middleware
read tests
再继续猜
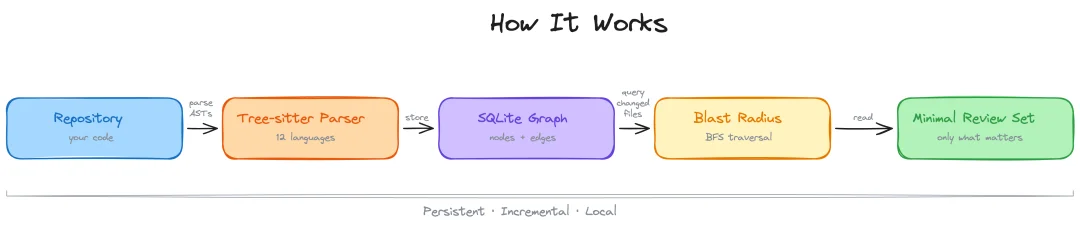
code-review-graph 做得更靠前一步。它先把代码库做成一张结构图。
它用 Tree-sitter 解析代码,把函数、类、导入、调用、继承、测试依赖这些信息抽成节点和边,再写进 SQLite。然后 Claude 不用先读全仓库,而是先拿一小块最相关的结构信息。
code-review-graph install --platform claude-code
code-review-graph build
先给 Claude 一张地图,再让它进仓库。在大型 monorepo 里,它的收益会更明显;普通 review 场景下,Claude 乱翻文件的时间也会短很多。地图一旦有了,探索成本就会往下掉。
实现上它也很完整。底层是 FastMCP server,对外给 Claude 一组图谱查询工具;同时又配了 hooks 做增量更新,还会装自己的 skills。所以它本质上是 MCP + hooks + skill 三件套。
项目地址:https://github.com/Mibayy/token-savior
Token Savior 很好懂的一点,在于它不默认给全文。
假设你在大仓库里问:
payment webhook 现在到底在哪处理?
很多工具会直接把相关代码整段吐给你。Token Savior 会分层给:
第 1 层:先给索引和短摘要
第 2 层:再给一小段 snippet
第 3 层:确认真有必要,再给全文
Token Savior 里还有个 Compact Symbol Cache。它的价值点在于,如果发现同一个 symbol 你刚刚读过,下一次回复,它就会先给你一个概要版本;只有代码真变了,或者你明确要全文,再展开。
这很像人自己读代码。很多时候我们要的不是全文,只是想确认一下:是不是这个函数、最近改没改、要不要继续往下看。Token Savior 的好处也在这儿,先给最少的,再按需要逐级展开。
Token Savior 也是 MCP server,但它比很多检索工具更激进地用了 Claude Code 生命周期 hooks,包括 SessionStart、Stop、SessionEnd、PreCompact、PreToolUse、PostToolUse、UserPromptSubmit 在内的多个 hook 都有用到。相应的,它管的不光是搜索这一小段,是整轮会话里 token 的整体流动。
项目地址:https://github.com/JuliusBrussee/caveman
这是专治 Claude 话太多、太啰嗦的插件,和之前的 Context Mode(管工具输出)、RTK(管终端噪音)互补,Caveman专门解决Claude 自身输出冗余浪费 token的问题。
工作原理上,Caveman整个插件依托 Claude Code 的 Skill/Plugin 层运行,会依靠 SessionStart、UserPromptSubmit 这类hooks 自动生效,无需手动触发,从根源收紧 Claude 的表达习惯。
看一组 before / after,就很容易懂了。
普通模式:
The reason your React component is re-rendering is likely because...
Caveman 模式:
New object ref each render. Inline object prop = new ref = re-render. Wrap in useMemo.
它砍的基本都是礼貌、连接词、包装句、过度解释、无意义的三段论这类东西,知识本身不做改动。
另外,它还有个很实用的小延伸,就是自动压缩每次会话都会加载的 CLAUDE.md 长文本,在这个过程中,它会完好保留代码块、路径、命令、URL 这类关键内容,只精简纯自然语言的废话。
如果说前五个项目,解决的是agent不该记的内容别记的问题,那么以下两个产品,解决的则是该记得的内容,应该以何种方式低成本的被记起的问题。
项目地址:https://github.com/zilliztech/claude-context

claude-context 是最近一直挂在 GitHub Trending 首页的热门项目,star数量已经突破一万。它解决的是大模型如何在大型仓库里,高效检索代码的问题。
在大仓库里,我们经常会问 Claude 一类问题:
帮我看看这个 bug 可能和哪几段代码有关。
如果没有额外检索层,Claude 往往就会这样干:
先列目录
再 grep
再 read 一堆文件
再继续猜
claude-context 的办法是,先把仓库切块、做 embedding、写进向量数据库。后面真要回答问题时,先召回最相关的代码块,而不是让 Claude 重新在整个仓库里摸一遍。

它做的,就是给 Claude 补一层语义检索,省掉每次开工前找相关代码那一整轮试错。
它的实现方式相对纯粹,就是 MCP。它本质上是一个语义检索 MCP server,先把仓库做向量化和混合检索,再把相关代码块召回给 Claude。
项目地址:https://github.com/zilliztech/memsearch

这个项目也用一个场景就能讲清楚。
星期一你跟 Claude 说:
我们项目的 webhook 不能重试,失败后要进 dead letter queue。
星期三你重新开一个 session,甚至换了模型,再问:
现在 webhook 这一层还能优化什么?
没有记忆层的话,Claude 很可能会把星期一那段背景当没发生过。你又得重新解释一遍。
memsearch 就是来解决跨session、跨平台的记忆复用问题的。
它的工作原理,类似Openclaw的记忆管理机制,完全按跳出了行业单纯用向量数据库存储记忆的固有模式,核心逻辑是把可读可编辑的本地 Markdown 文件当作唯一真实记忆源,向量数据库只充当临时、可重建的检索索引,从从而完成高效的记忆管理与检索问题。
它有一点我很喜欢,没把“记忆”做成黑盒数据库。它是 Markdown-first 的,人工可以直接阅读、修改、删减,记忆文件可以随意复制迁移,不存在平台锁定,还能依托版本工具实现多人协作编辑、变更追溯,让 AI 记忆变成人机可以共同维护的内容。
它在 Claude Code 里的实现过程如下:
检索时,它也不会把所有旧记录一股脑塞回上下文,而是按三层 progressive retrieval 去拿:
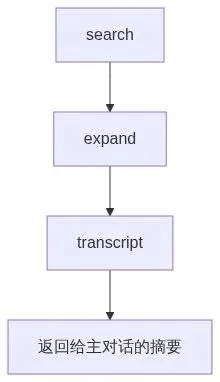
先搜,再展开,必要时才下钻到原始 transcript。还有个很关键的细节,memory-recall skill 是在 forked context 里跑的,所以主对话不会被整段记忆检索过程污染,最后回来的只是整理过的结果。
它实现上最有意思的地方也在这儿。memsearch 走的是 Claude Code plugin:用 SessionStart、UserPromptSubmit、Stop、SessionEnd 这 4 个 hooks 负责捕获和注入记忆,再用一个 memory-recall skill 在 forked context 里做检索。记忆处理就是这么接进会话生命周期里的。
memsearch 带来的好处,不光是让 Claude 记住昨天讨论过 Redis TTL 这种细节,还能让新 session 不用再从头喂背景、换 agent 不用再重讲约束、长项目里,过去的决策和踩过的坑不会凭空消失
对频繁切 session、切 agent、做长周期项目的人来说,这种收益远比单轮省几个百分点 token 更实在。它省掉的是那部分最烦、最反复、最磨耐心的体力活。
以下是七大工具的组合选用指南:
要是受不了终端一堆杂乱日志、测试乱七八糟的输出,先用 RTK。如果挂了太多服务,聊天页面全是工具刷屏的垃圾内容,界面乱糟糟的,就开 Context Mode。项目代码库越堆越大,AI 每次新建对话都像从没见过这个项目,看不懂代码、摸不清项目结构,那就一定要配上code-review-graph 或 claude-context这类代码检索类工具。AI 回答总是长篇大论、废话太多,就用 Caveman 精简内容。每次关掉对话、切换 AI 之后,之前聊的东西全清空、记不住任何内容,长期记忆没法留存,直接用 memsearch 就能解决。
实际搭配使用,推荐按这个顺序来:
简单总结就是,先清噪音减负,再让 AI 看懂代码,最后精简回答、留住所有历史记忆。
RTK:https://github.com/rtk-ai/rtk
Context Mode:https://github.com/mksglu/context-mode
code-review-graph:https://github.com/tirth8205/code-review-graph
Token Savior:https://github.com/Mibayy/token-savior
Caveman:https://github.com/JuliusBrussee/caveman
claude-context:https://github.com/zilliztech/claude-context
memsearch:https://github.com/zilliztech/memsearch
Anthropic Pricing:https://docs.anthropic.com/en/docs/about-claude/pricing
Anthropic Prompt Caching:https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching

文章来自于微信公众号 "Zilliz",作者 "Zilliz"



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
