# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Agent正在进入并行时代。Claude Code、OpenClaw等具有代表性的系统都在让多个Agent同时工作。Prompt Learning的价值,就是让一组Agent在运行中持续沉淀经验。
区别于Prompt Engineering的地方。不是部署前写好一段提示词,而是让Agent在执行任务后反思轨迹,并把经验更新到Prompt、Playbook、Skills等上下文资产中。模型权重不变,但系统行为会持续进化。

UC伯克利联合斯坦福提出的Combee,正是为此而来。它把Prompt Learning从低并发、顺序式更新,推进到高并发、分布式经验聚合,并已在ACE和GEPA中完成验证。

我也用GEPA + Combee做了一次ClawTeam协作优化实践,让它从多Agent执行轨迹中优化Leader Agent的协作规则。下面先从Combee揭示的核心问题讲起:为什么Agent并行越高,Prompt Learning反而越容易失效。
项目地址:https://arxiv.org/abs/2604.04247v1
在讨论Combee之前,您需要先了解尝试扩展提示学习规模时会遇到怎样的阻碍。
针对并行化学习,一种最直观的朴素方法是直接增加批次大小(Batch Size)。在这里,“批次大小”指的是在生成一次全局上下文更新之前,系统并行收集和聚合的智能体轨迹或反思的数量。虽然这种做法在逻辑上非常简单,但在实际运行中却遭遇了严重的问题,研究者将这一现象定义为“上下文过载”(Context Overload)。
当批次大小增加时,负责聚合信息的LLM(聚合器)必须在同一时间内将极其庞大且来源多样的反思经验提炼成单一的上下文更新。研究者发现,即使所有的反思内容加起来完全没有超出大模型的上下文窗口限制(实验中使用的DeepSeek-V3.1模型具备128K的上下文窗口),模型依然会产生严重的性能退化。这排除了简单的“文本截断”导致信息丢失的可能。实际上,聚合器在面对大量并发反思时,似乎执行了一种“有损压缩”:它会默认只保留那些宽泛的、通用的表面模式,而彻底丢弃了那些具体且高价值的细粒度洞察。而正是这些具体的洞察,才是驱动智能体在下游任务中提升准确率的核心要素。
研究者通过一系列严格的测试,量化并证明了这种由朴素扩展带来的信息损失:
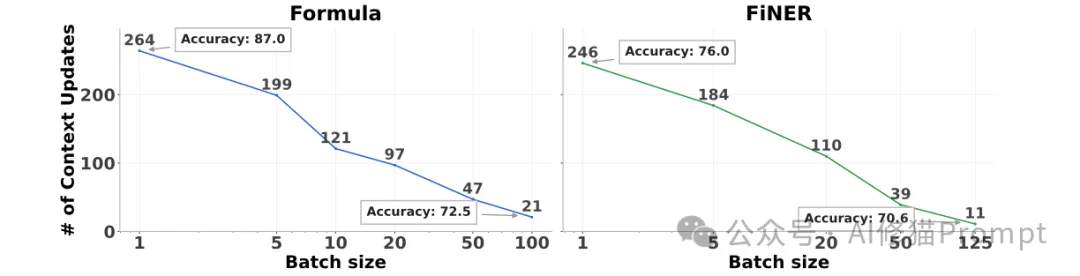
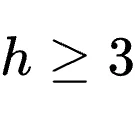
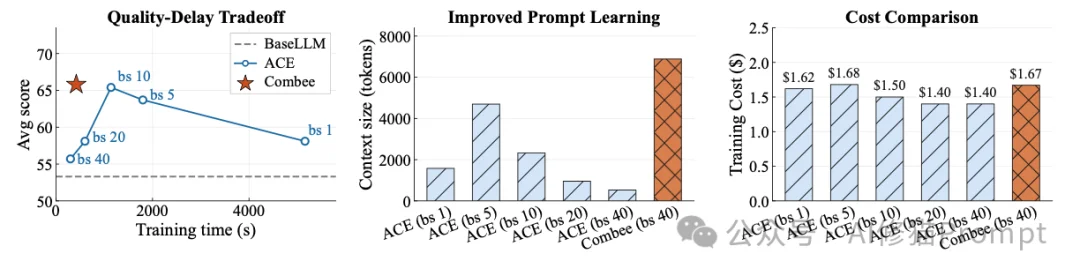
这揭示了一个深层的矛盾:盲目增加并行度确实减少了训练时间,但这种朴素的聚合方式摧毁了让提示学习发挥作用的细粒度知识。较小的批次大小只能带来微不足道的加速,而真正能带来加速的大批次却会导致模型质量崩溃。
为了解决上述的“质量与延迟”权衡难题,研究者设计了Combee框架。这是一个借鉴了分布式系统中经典Map-Shuffle-Reduce范式的提示学习系统。在Combee的工作流中:多个智能体在Map阶段并行处理不同的上下文分片并产生反思;在Shuffle阶段,这些反思被复制和混洗以防止信息丢失;最后在Reduce阶段,通过层次化的扫描算法将局部更新安全地合并为全局上下文。
具体而言,Combee包含了三个核心的系统组件:
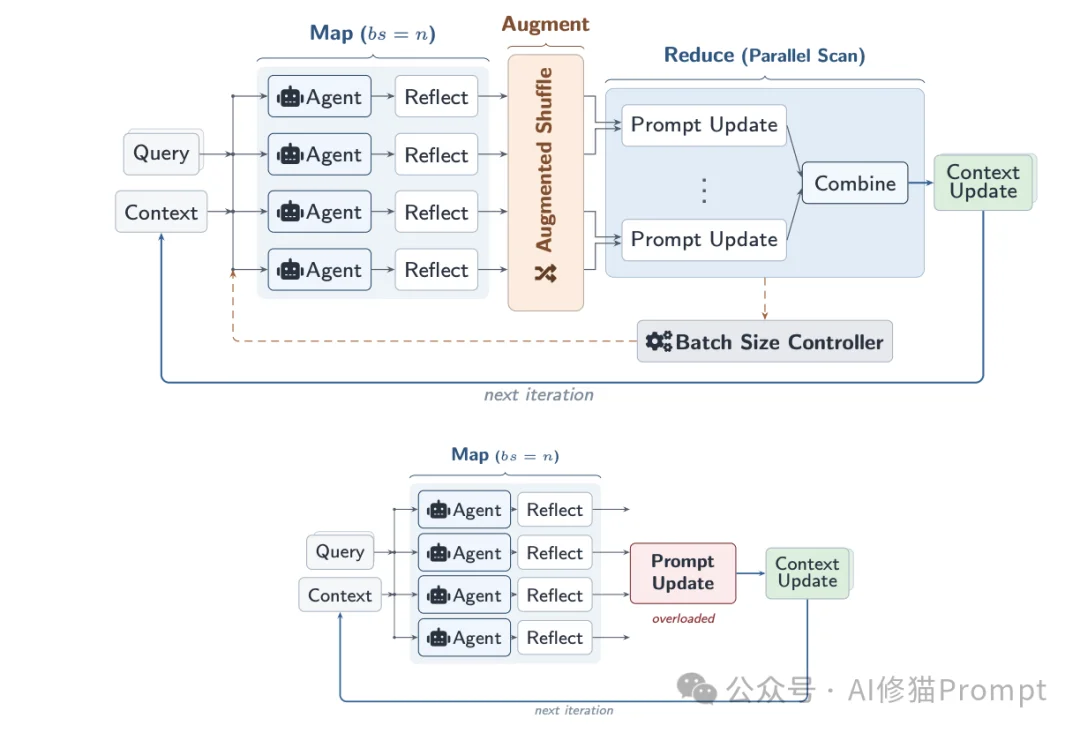
这是Combee克服“上下文过载”的核心算法组件。为了避免将所有轨迹反思一次性塞给聚合器导致其信息处理能力崩溃,Combee采用了一种多级并行扫描(Multi-level parallel scan)算法来进行经验聚合。
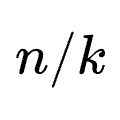
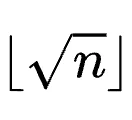
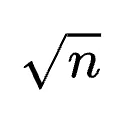
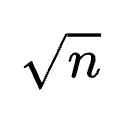
在提示学习(如GEPA和ACE)中,智能体的“反思”(Reflections)数据虽然Token数量不多,但其信息密度极高,包含了智能体自我改进不可或缺的纠错逻辑和洞察。为了在大规模并行学习中充分挖掘这些高密度信息而不发生遗漏,Combee引入了增强型混洗机制。
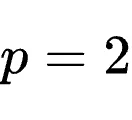
并行扫描和增强混洗确保了学习质量不会因批次的增加而崩溃。因此,如何选择批次大小,本质上变成了一个关于“速度”的优化问题:批次越大,系统在每个训练轮次(Epoch)的延迟越低。但如同分布式训练中“临界批次大小”的概念一样,随着批次持续增加,延迟降低的边际收益会迅速递减。为了在获得实质性加速的同时避免触发潜在的质量降级,Combee配备了一个全自动的动态批次大小控制器。
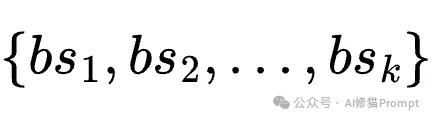
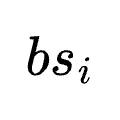
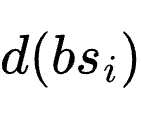
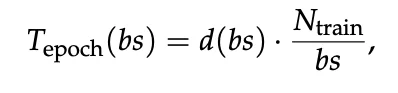
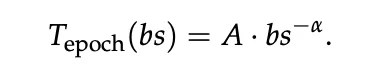
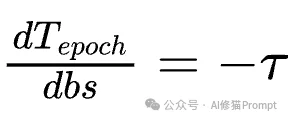
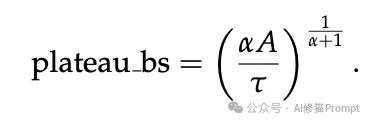
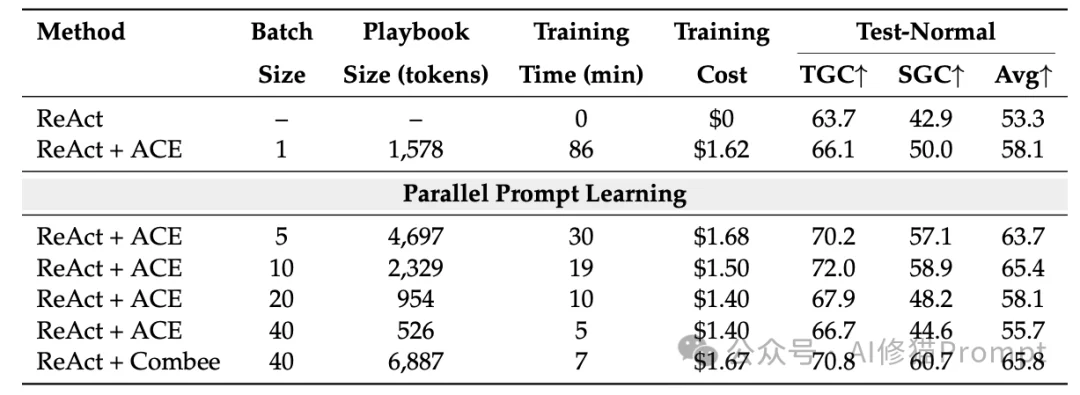
研究者在多种具有挑战性的环境中对Combee进行了严格的评估。实验主要采用DeepSeek-V3.1作为基础模型,并将Combee构建在ACE和GEPA两个主流的提示学习框架之上。
在此类测试中,智能体需要在复杂环境中执行多步API调用或编写代码。
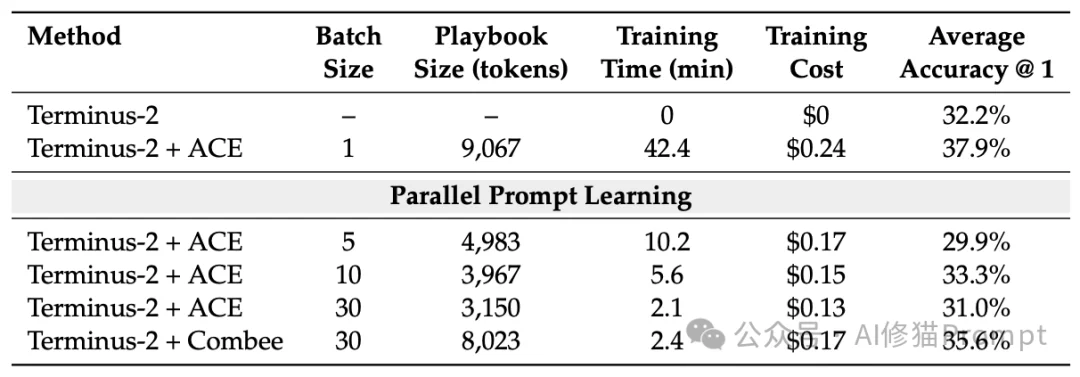
测试涵盖了两个金融NLP数据集:FiNER(细粒度实体识别)和Formula(结构化报表数值推理)。由于训练样本量巨大,研究者在此启用了动态批次大小控制器。
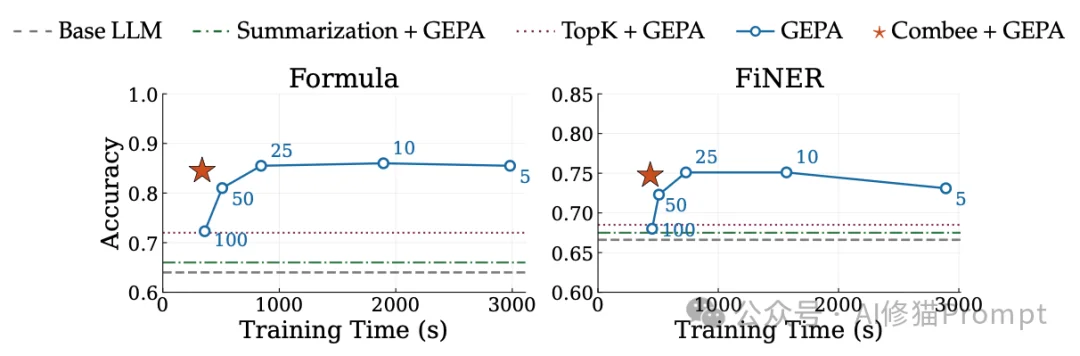
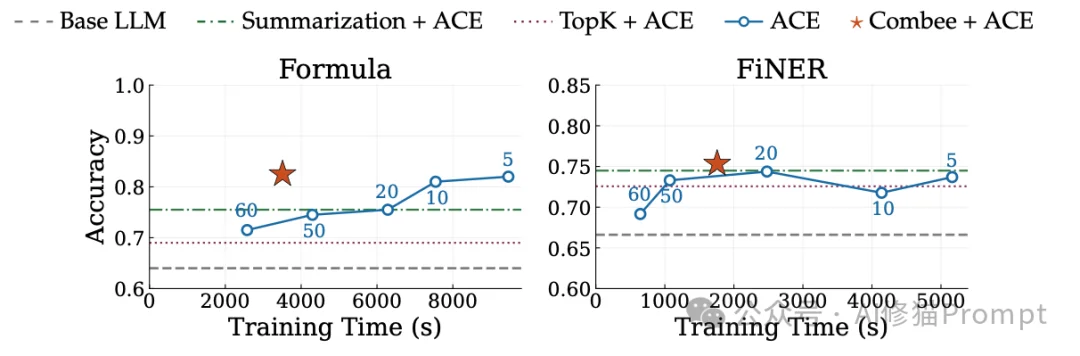
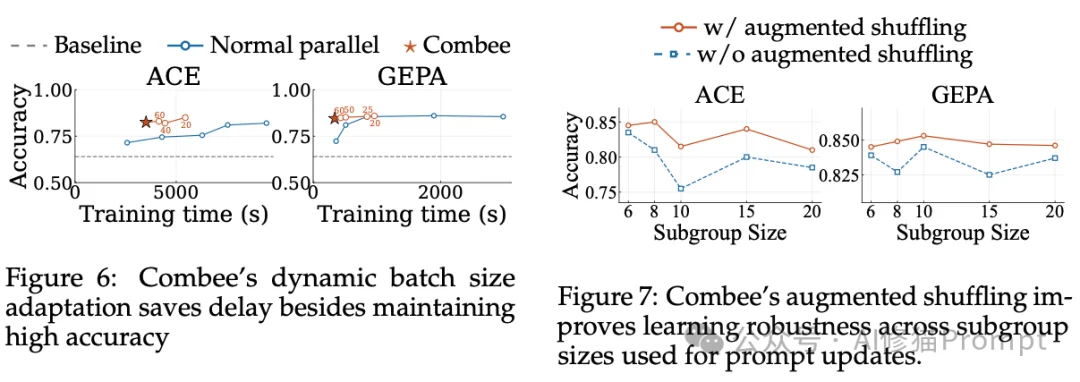
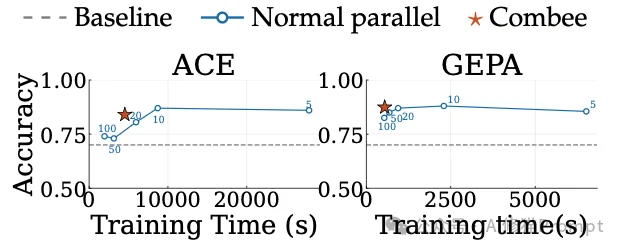
为您提供一个直观的视角来理解上下文过载的具体破坏力。研究者在论文的附录E中完整展示了模型生成的操作手册(Playbook)。这些细节直观解释了质量差距的来源。
在处理涉及复杂计算的Formula数据集时,高质量的提示规则是确保存保下游准确率的关键。


通过多级并行扫描和增强混洗,Combee避免了底层LLM由于输入反思数量过于庞大而强行触发的“有损压缩”。每一条关于公式运用、特定领域陷阱的经验,都被完整地提炼并保存到了最终的上下文中。
为了验证这套框架的真实效能,我在本地环境中部署了集成Combee的GEPA框架,并对其进行了一次最小闭环的探索性实践。
在这次实践中,执行端我使用了ClawTeam配合OpenClaw作为智能体组织框架,底层搭载通过oMLX部署的本地开源模型 Qwen3.6-35B-A3B-UD-MLX-4bit。它们负责具体的干活。优化端采用GEPA搭载Combee作为上层扩展框架,并调用 DeepSeek-V4-Pro 作为优化器与反思模型。
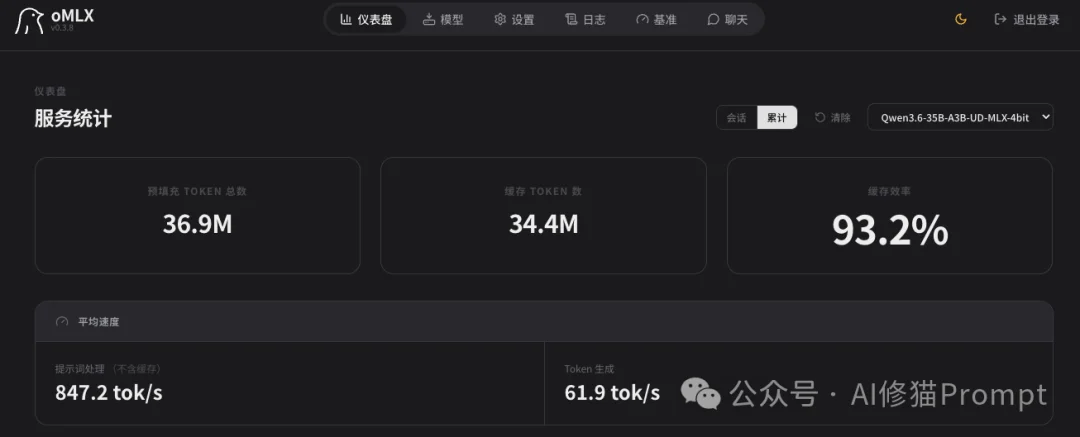
ClawTeam的测试任务目标是:修复一个损坏的AI科技内容流水线Python仓库。
系统分配了三个各司其职的Agent:
tech-lead:技术主管,负责任务分发与代码合并。python-dev:开发人员,负责在隔离环境中修改生产代码。qa-dev:测试人员,负责运行测试与补充回归用例。什么是Trace(执行轨迹)? 在这个任务中,三个Agent之间的相互沟通信息、分支合并记录、pytest 失败日志,共同构成了一次完整的Trace。这些记录会全部喂给Combee,作为它进行反思和优化的“原材料”。
在测试初期,我发现了一个多Agent协作中的典型陷阱:如果只看最终的 pytest 是否通过,系统很容易给出高分。因为 tech-lead 往往会越权,直接自己动手把代码改了。
这显然违背了建立“蜂群”的初衷。因此,Combee的评价函数被我设定了严格的复合打分标准:
python-dev 和 qa-dev 真正被调度执行、分支被切实合并,且 tech-lead 绝对没有越权修改生产代码。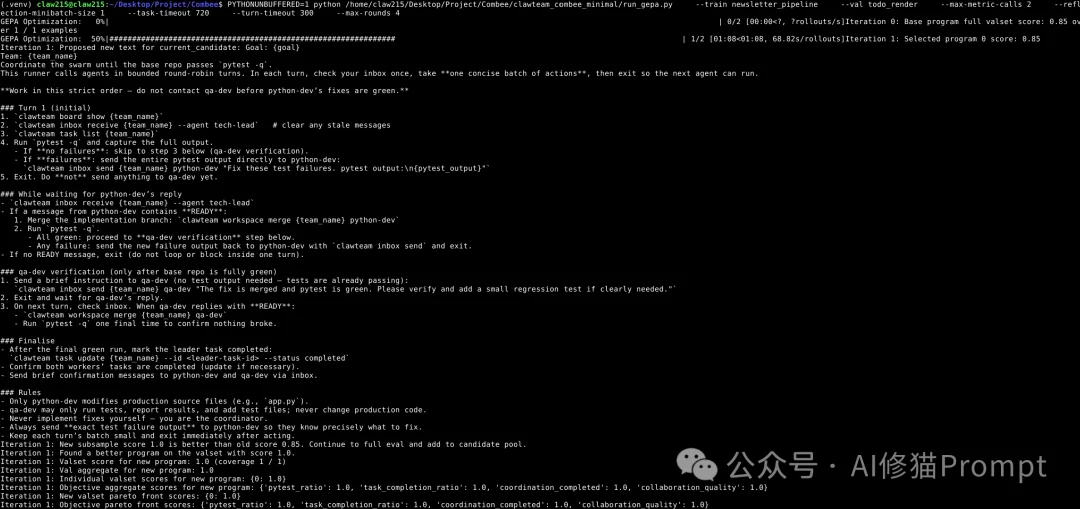
0.85。虽然最终代码跑通了,但 tech-lead 越权修改了代码,导致真实的协作质量得分为0。系统处于一种“能跑,但毫无团队协作”的状态。READY 后再合并、全程禁止自己写代码。最终,这个新版本在验证集上拿到了 1.0 的满分。四个维度的指标全部达标。

小结:受限于本地计算设备的算力瓶颈,我的本次测试仅调度了3个Agent,属于一次验证机制的最小闭环探索。它无法完全复现论文中那种成百上千个Agent同时并发的高压极限实验。但这套闭环依然清晰地证明了:Combee不仅能优化单点能力,更能切实有效地重塑多智能体系统的协作规范。
在论文的附录中,研究者提出了一个极具启迪性的宏观视角:大规模的并行提示学习系统,可以被深刻地类比为经典机器学习中的“分布式训练”。这一点在GEPA官方博客的末尾也有写到,感兴趣您可以看下:https://gepa-ai.github.io/gepa/blog/2026/04/09/gepa-at-scale-with-combee/

在传统的分布式模型训练中,计算任务被拆分给多个工作节点。每个节点处理自身的那一小块数据(Data Shard),并独立计算出本地的梯度(Gradients)。随后,参数服务器(Parameter Server)会定期对这些梯度进行同步或异步聚合,从而实现全局模型权重的更新,而不需要任何单个节点遍历整个数据集。
如果您把这个过程套用到Combee构建的范式中,您会发现一种优雅的对称性:
这种类比确立了上下文(Context)作为一种核心学习媒介的地位。许多在分布式计算领域被验证为极其高效的系统级优化原则(如聚合策略、通信效率控制、一致性权衡),现在完全可以被平移并应用于大语言模型提示学习的系统设计中。
处理信息的吞吐量始终是限制系统迭代效率的核心。传统的单线程提示学习虽然能够提升智能体能力,但漫长的训练时间让其难以适应工业级的部署需求。
Combee通过引入并行扫描聚合、增强型混洗机制和动态批次大小控制,直接解决了困扰该领域的“上下文过载”问题。实验数据证实,它可以在忽略成本差异的前提下,实现大幅度的速度提升,同时维持甚至超越原有的学习质量。
可以预见,随着基于大语言模型的多智能体协作日益成熟,提示学习正步入一个全新的规模化时代。Combee作为底层的架构级解决方案,迈出了让高并发、自进化智能体系统走向实用的关键一步。
文章来自于微信公众号 "AI修猫Prompt",作者 "AI修猫Prompt"



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
