# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI 很快就能自己改造自己了?
Anthropic 联合创始人 Jack Clark 发帖称,他最近几周阅读了大量公开的 AI 开发数据后,认为到 2028 年底,递归自我改进(recursive self-improvement)发生的概率有 60%。
也就是说,AI 系统可能很快就能自主构建和改进自己,进入自我加速的阶段。

这一观点并非凭空而来。他看了一堆公开基准,发现 AI 在 AI 研发相关任务上进步非常快。
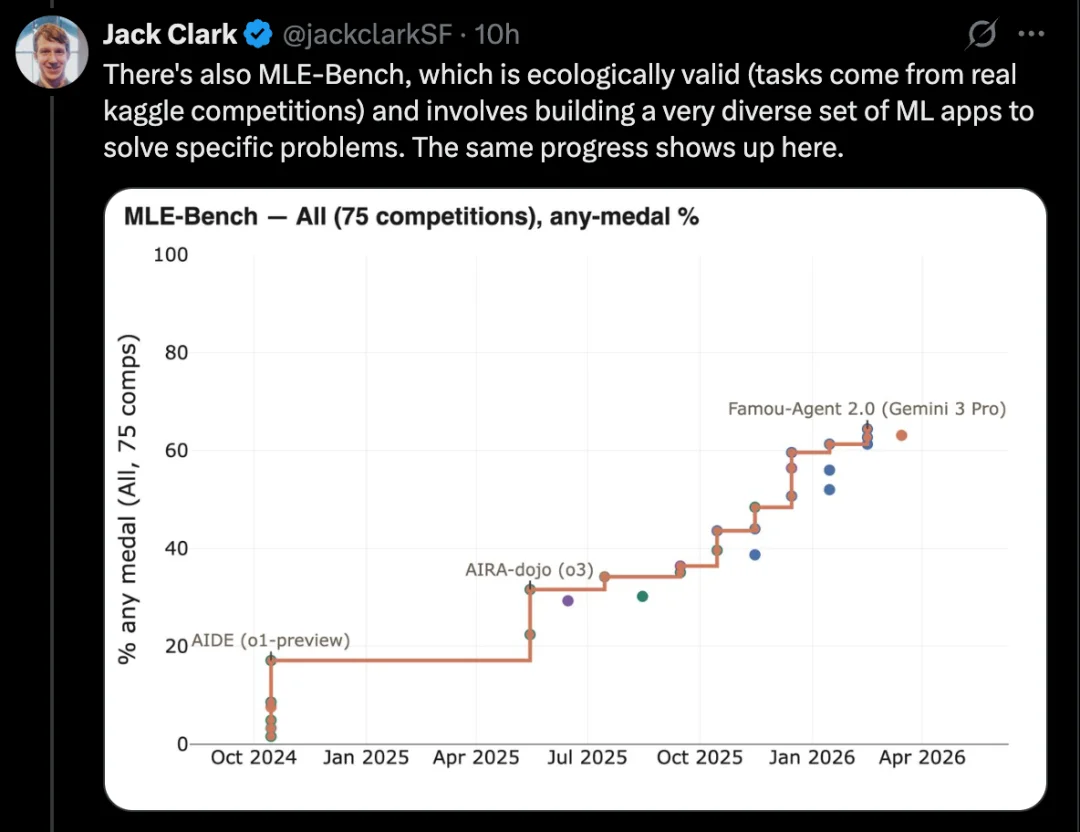
比如,CORE-Bench 考察 AI 实现他人研究论文的能力,这是 AI 研究中至关重要的一环。
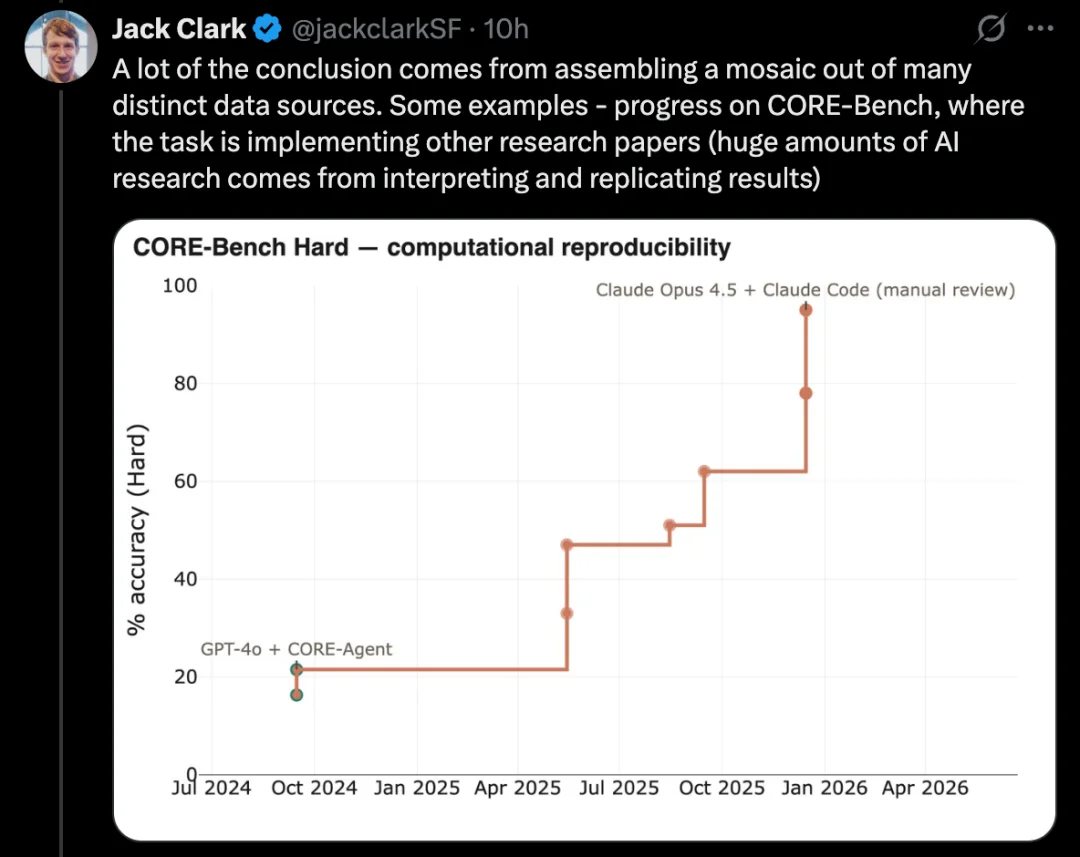
PostTrainBench 则测试强大模型能否自主微调较弱的开源模型以提升性能,这正是 AI 研发任务的一个关键子集。
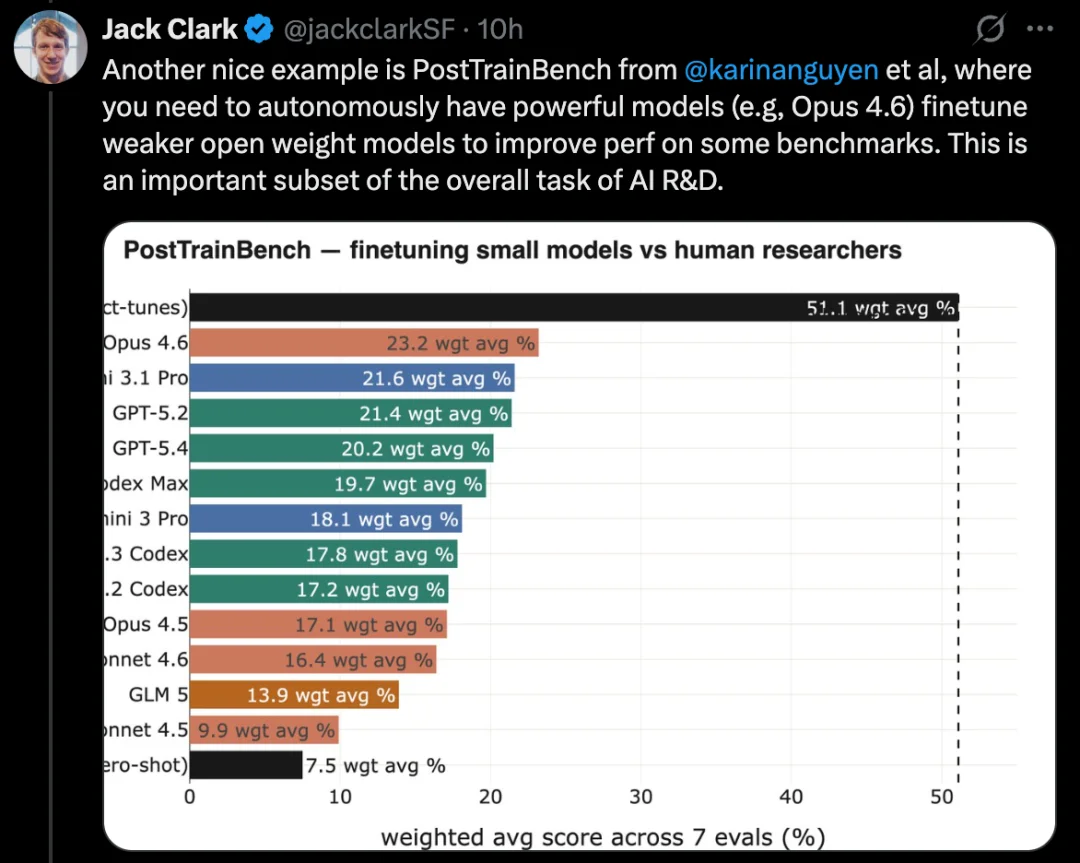
MLE-Bench 基于真实 Kaggle 竞赛任务,要求构建多样化的机器学习应用程序来解决特定问题。此外,像 SWE-Bench 这样广为人知的编码基准,也展现出类似的进步。
Jack Clark 将这一现象描述为「分形」式的向上向右趋势,即在不同分辨率和尺度上,都能观察到有意义的进展。他认为,AI 正在逐步接近端到端自动化研发的能力,一旦实现,AI 将能够自主构建自己的后继系统,开启自我迭代的循环。

此言论一出,在社交媒体引发不少讨论。
一些人视其为迈向 ASI 和奇点的关键第一步,可能彻底改变科技发展的节奏。

然而,也存在不同声音。
华盛顿大学计算机科学教授 Pedro Domingos 指出,AI 系统早在上世纪 50 年代 LISP 语言发明时就具备了「构建自身」的能力,真正的问题在于能否获得递增回报,而目前还没有明显证据支持这一点。

有网友质疑,从 2027 年到 2028 年,概率一下子增加 30%,这暗示 AI 能力会在 2027 年底前后出现一次突然的重大突破。到底哪一个具体的里程碑或事件,会让 AI 实现递归自我改进的概率在短时间内大幅提升?

还有网友表示,Jack Clark 是 Anthropic 新上任的公关负责人,这正是他们新战略的一部分:我们并非危言耸听者,有大量的论文都印证了我们一直以来警告你们的事情。
Jack Clark 专门在 Import AI 455 这期 newsletter 里写了一篇长文详细阐述。
文章地址:https://importai.substack.com/p/import-ai-455-automating-ai-research?r=1ds20&utm_campaign=post&utm_medium=email&triedRedirect=true
接下来,我们完整看一下这篇文章。
AI 系统即将开始自我构建,这意味着什么?
Clark 表示,他写下这篇文章,是因为在梳理所有公开可获得的信息后,他不得不形成一个并不轻松的判断:到 2028 年底之前,出现无人类参与的 AI 研发的可能性已经相当高,或许超过 60%。
这里所谓的无人类参与的 AI 研发,指的是一种足够强大的 AI 系统:它不仅能辅助人类做研究,还可能自主完成关键研发流程,甚至构建出自己的下一代系统。
在 Clark 看来,这显然是一件大事。
他坦言,自己也很难完全消化这件事的含义。
之所以称这是一个不情愿的判断,是因为它背后的影响过于巨大,让他感到难以把握。Clark 也不确定,整个社会是否已经准备好迎接 AI 研发自动化所带来的深层变化。
他现在相信,人类可能正生活在一个特殊时间点:AI 研究即将被端到端自动化。如果这一刻真的到来,人类就像跨过了卢比孔河,进入一个几乎无法预测的未来。
Clark 表示,这篇文章的目的,是解释他为什么认为,通向完全自动化 AI 研发的起飞正在发生。
他会讨论这一趋势可能带来的一些后果,但文章的大部分篇幅,都会集中在支撑这一判断的证据上。至于更深层的影响,Clark 计划在今年的大部分时间里继续梳理。
从时间点来看,Clark 并不认为这件事会在 2026 年真正发生。但他认为,未来一两年内,我们可能会看到某种模型端到端训练出自己后继者的案例。至少在非前沿模型层面,出现一个概念验证是很有可能的;至于最前沿模型,难度会更高,因为它们成本极其昂贵,也依赖大量人类研究员的高强度工作。
Clark 的判断主要来自公开信息:包括 arXiv、bioRxiv 和 NBER 上的论文,以及前沿 AI 公司已经部署到现实世界中的产品。基于这些信息,他得出一个结论:自动化生产当下 AI 系统所需的各个环节,尤其是 AI 开发中的工程组件,基本已经具备。
如果 scaling 趋势继续延续,我们就应该开始准备面对这样一种情况:模型会变得足够有创造力,不仅能自动改进已知方法,还可能在提出全新研究方向和原创想法方面替代人类研究员,从而自行推动 AI 前沿继续向前发展。
编码奇点:能力随时间的变化
AI 系统是通过软件实现的,而软件由代码构成。
AI 系统已经彻底改变了代码生产方式。这背后有两个相关趋势:一方面,AI 系统越来越擅长编写复杂的真实世界代码;另一方面,AI 系统也越来越擅长在几乎不依赖人类监督的情况下,把许多线性的编码任务串联起来完成,比如先写代码,再进行测试。
体现这一趋势的两个典型例子,是 SWE-Bench 和 METR time horizons plot。
解决真实世界的软件工程问题
SWE-Bench 是一个被广泛使用的编程测试,用来评估 AI 系统解决真实 GitHub issue 的能力。
当 SWE-Bench 在 2023 年底推出时,当时表现最好的模型是 Claude 2,整体成功率大约只有 2%。而 Claude Mythos Preview 的成绩已经达到 93.9%,基本上接近打满这个 benchmark。
当然,所有 benchmark 本身都会有一定噪声,所以通常会出现这样一个阶段:当分数高到某个程度之后,你碰到的可能不再是方法本身的限制,而是 benchmark 自身的限制。比如在 ImageNet 验证集中,大约 6% 的标签就是错误或存在歧义的。
SWE-Bench 可以被视为衡量通用编程能力,以及 AI 对软件工程影响的一个可靠指标。Clark 表示,他在前沿 AI 实验室和硅谷接触到的大多数人,现在几乎都已经完全通过 AI 系统来写代码,并且越来越多的人开始用 AI 系统来编写测试、检查代码。
换句话说,AI 系统已经足够强,能够自动化 AI 研发中的一个重要组成部分,并显著加速所有参与 AI 研发的人类研究员和工程师。
衡量 AI 系统完成长时任务的能力
METR 制作了一张图,用来衡量 AI 能完成多复杂的任务。这里的复杂度,是按照一个熟练人类完成这些任务大概需要多少小时来计算的。
其中最关键的指标,是 AI 系统在一组任务上达到 50% 可靠性时,对应的大致任务时间跨度。
在这一点上,进展非常惊人:
在 METR 工作、长期关注 AI 预测的 Ajeya Cotra 认为,到 2026 年底,AI 系统能够完成相当于人类需要 100 小时的任务,并不是一个不合理的预期。
AI 系统能够独立工作的时间跨度显著增长,也和 agentic coding 工具的爆发高度相关。所谓 agentic coding 工具,本质上就是把能替人完成工作的 AI 系统产品化:它们可以代表人类行动,并在相当长一段时间内相对独立地推进任务。
这也重新指向 AI 研发本身。仔细观察许多 AI 研究员的日常工作会发现,其中大量任务其实都可以拆解成几个小时级别的工作,比如清洗数据、读取数据、启动实验等等。
而这类工作,如今已经落入现代 AI 系统能够覆盖的时间跨度之内。
AI 系统越熟练,越能独立于人类工作,就越能帮助自动化 AI 研发中的一部分工作。
任务委托的关键因素主要有两个:
当用户在观察 AI 在编程方面的能力时,会发现 AI 系统不仅变得越来越熟练,也越来越能在不需要人类重新校准的情况下,独立工作更长时间。
这也和我们身边正在发生的事情相吻合,工程师和研究员正在把越来越大块的工作交给 AI 系统完成。随着 AI 能力持续提升,被委托给 AI 的工作也变得越来越复杂、越来越重要。
AI 正在掌握 AI 研发所必需的核心科学技能
想想现代科学研究是怎么进行的,其中很大一部分工作,其实就是先确定一个方向,明确自己想获得哪类经验性信息;然后设计并运行实验,生成这些信息;最后再对实验结果进行合理性检查。
随着 AI 编程能力不断提升,再加上大语言模型越来越强的世界建模能力,如今已经出现了一批工具,能够帮助人类科学家提速,并在更广泛的研发场景中部分自动化某些环节。
在这里,我们可以观察 AI 在几项关键科学技能上的进展速度,而这些能力本身也正是 AI 研究不可或缺的一部分:
实现整篇科学论文,并完成相关实验
AI 研究中的一项核心工作,是阅读科学论文,并复现其中的结果。在这方面,AI 已经在一系列 benchmark 上取得了显著进展。
一个很好的例子是 CORE-Bench,也就是 Computational Reproducibility Agent Benchmark。
这个 benchmark 要求 AI 系统在给定一篇论文及其代码仓库的情况下,复现论文中的结果。具体来说,Agent 需要安装相关库、软件包和依赖,运行代码;如果代码成功运行,它还需要搜索所有输出结果,并回答任务中的问题。
CORE-Bench 于 2024 年 9 月提出。当时表现最好的系统,是运行在 CORE-Agent scaffold 中的 GPT-4o 模型。在该 benchmark 最困难的一组任务上,它的得分约为 21.5%。
而到了 2025 年 12 月,CORE-Bench 的一位作者宣布,这个 benchmark 已经被解决了:Opus 4.5 模型取得了 95.5% 的成绩。
构建完整的机器学习系统,解决 Kaggle 竞赛问题
MLE-Bench 是 OpenAI 构建的一个 benchmark,用来测试 AI 系统在离线环境中参加 Kaggle 竞赛的能力。
它覆盖了 75 个不同类型的 Kaggle 竞赛,涉及多个领域,包括自然语言处理、计算机视觉和信号处理等。
MLE-Bench 于 2024 年 10 月发布。发布时,表现最好的系统是一个运行在 agent scaffold 中的 o1 模型,得分为 16.9%。
截至 2026 年 2 月,表现最好的系统已经变成了运行在带搜索能力的 agent harness 中的 Gemini 3,得分达到 64.4%。
Kernel 设计
AI 开发中一项更难的任务是 kernel 优化。所谓 kernel 优化,就是编写并改进底层代码,把矩阵乘法这类特定运算更高效地映射到底层硬件上。
Kernel 优化之所以是 AI 开发的核心,是因为它决定了训练和推理的效率:一方面,它影响你在开发 AI 系统时,究竟能有效利用多少算力;另一方面,当模型训练完成后,它也决定你能多高效地把算力转化为推理能力。
近年来,用 AI 做 kernel 设计,已经从一个有趣的小方向,变成了一个竞争激烈的研究领域,并且出现了多个 benchmark。不过,这些 benchmark 目前还没有特别流行,所以我们很难像其他领域那样清晰地建模它的长期进展。另一方面,我们可以通过一些正在进行的研究,感受这个方向的推进速度。
相关工作包括:
这里需要补充一点:kernel 设计确实具备一些特别适合 AI 驱动研发的属性,比如结果容易验证、奖励信号比较明确。
通过 PostTrainBench 微调语言模型
这类测试的一个更困难版本是 PostTrainBench。它测试的是,不同前沿模型能否接手较小的开源权重模型,并通过微调提升它们在某些 benchmark 上的表现。
这个 benchmark 的一个优点是,它有非常强的人类基线:这些小模型现有的 instruct-tuned 版本。这些版本通常由前沿实验室中优秀的人类 AI 研究员开发,已经经过非常有能力的研究员和工程师打磨,并被部署到真实世界中。因此,它们构成了一个很难超越的人类基准。
截至 2026 年 3 月,AI 系统已经能够对模型进行后训练,并获得大约相当于人类训练结果一半的性能提升。
具体评估分数来自一个加权平均:它会综合多个后训练的大语言模型,包括 Qwen 3 1.7B、Qwen 3 4B、SmolLM3-3B、Gemma 3 4B,以及多个 benchmark,包括 AIME 2025、Arena Hard、BFCL、GPQA Main、GSM8K、HealthBench、HumanEval。
在每次运行中,评测方会要求一个 CLI agent,尽可能提升某个特定基础模型在某个特定 benchmark 上的表现。
截至 2026 年 4 月,得分最高的 AI 系统大约能达到 25% 到 28%,代表模型包括 Opus 4.6 和 GPT 5.4;相比之下,人类得分为 51%。
这已经是一个相当有意义的结果。
优化语言模型训练
过去一年,Anthropic 一直在报告其系统在一项 LLM 训练任务上的表现。这个任务要求模型优化一个仅使用 CPU 的小型语言模型训练实现,让它尽可能快地运行。
评分方式是:相较于未修改的初始代码,模型实现的平均加速倍数。
这项结果进展非常显著:
为了理解这些数字的含义,可以做一个参照:在人类研究员身上,这项任务通常需要 4 到 8 小时工作,才能实现 4 倍加速。
元技能:管理
AI 系统也正在学习如何管理其他 AI 系统。
这一点已经可以在一些广泛部署的产品中看到,比如 Claude Code 或 OpenCode。在这些产品里,一个主 agent 可以监督多个 sub-agent。
这让 AI 系统能够处理更大规模的项目:项目中可能需要多个具备不同专长的智能体并行工作,而它们通常由一个单一的 AI 管理者来协调。这里的管理者本身也是一个 AI 系统。
AI 研究更像发现广义相对论,还是搭乐高?
一个关键问题是:AI 能否发明出新的想法,帮助它改进自身?还是说,这些系统更适合完成研究中那些不那么光鲜、但必须一砖一瓦推进的工作?
这个问题很重要,因为它关系到 AI 系统能在多大程度上端到端自动化 AI 研究本身。
作者的判断是:AI 目前还不能提出真正激进的全新思想。但要实现自身研发自动化,它或许并不一定需要做到这一点。
作为一个领域,AI 的进步很大程度上依赖于越来越大的实验,以及越来越多的输入,比如数据和算力。
偶尔,人类会提出一些改变范式的想法,使整个领域的资源效率大幅提升。Transformer 架构就是一个很好的例子,混合专家模型,也就是 mixture-of-experts,也是另一个例子。
但更多时候,AI 领域的推进方式其实更朴素:人类会拿一个表现良好的系统,扩大其中某个方面,比如训练数据和算力;观察扩大规模后哪里出问题;找到工程上的修复方案,让系统能够继续扩展;然后再次扩大规模。
这个过程里,真正需要洞见的部分其实很少。大量工作更像是不那么耀眼、但非常扎实的基础工程。
类似地,很多 AI 研究其实是在运行现有实验的各种变体,探索不同参数设置会带来什么结果。研究直觉当然能帮助人类挑选最值得尝试的参数,但这件事本身也可以被自动化,让 AI 自己判断哪些参数值得调整。早期的神经架构搜索,就是这类思路的一个版本。
爱迪生曾说:天才是 1% 的灵感,加上 99% 的汗水。即便过去 150 年,这句话依然很贴切。
偶尔,确实会出现彻底改变一个领域的新洞见。但大多数时候,领域进步是靠人类在改进和调试各种系统的艰苦过程中,一点点推进出来的。
而前面提到的公开数据表明,AI 已经非常擅长执行 AI 开发中许多必要的苦活累活。
与此同时,还有一个更大的趋势:基础能力,比如编程能力,正在和不断扩展的任务时间跨度结合起来。这意味着 AI 系统可以把越来越多这类任务串联起来,形成复杂的工作序列。
因此,即便 AI 系统目前相对缺乏创造力,也有理由相信,它们仍然能够推动自身继续向前发展。只是相比能够产生全新洞见的情况,这种推进速度可能会更慢。
但如果继续观察公开数据,会发现另一个令人好奇的信号:AI 系统也许正在展现出某种创造力,而这种创造力可能让它们以更令人惊讶的方式推动自身进步。
推动科学前沿继续向前
目前已经有一些非常初步的迹象表明,通用 AI 系统有能力推动人类科学前沿继续向前发展。不过到目前为止,这种情况只发生在少数几个领域,主要是计算机科学和数学。而且很多时候,并不是 AI 系统单独完成突破,而是以人机协作的方式,与人类研究者共同推进。
尽管如此,这些趋势仍然值得观察:
Erdős 问题:一组数学家与 Gemini 模型合作,测试它在解决一些 Erdős 数学问题上的表现。他们引导系统尝试了大约 700 个问题,最终得到了 13 个解答。在这些解答中,有 1 个被他们认为是有趣的。
研究者写道,他们初步认为,Aletheia(一套基于 Gemini 3 Deep Think 的 AI 系统) 对 Erdős-1051 的解答,代表了一个早期案例:一个 AI 系统自主解决了一个略具非平凡性、并且有一定更广泛数学兴趣的开放 Erdős 问题。该问题此前已有一些 closely-related 的相关研究文献。
如果往乐观方向理解,这些案例可以被看作一个信号:AI 系统正在发展出某种能够推动领域前沿的创造性直觉,而这种直觉过去主要属于人类。
但也可以从另一面解释:数学和计算机科学可能本身就是特别适合 AI 驱动发明的领域,因此它们或许只是例外,并不能代表更广泛的科学研究都会被 AI 以同样方式推进。
另一个类似例子是 AlphaGo 的第 37 手。不过 Clark 认为,距离 AlphaGo 那次结果已经过去十年,而第 37 手之后并没有被某个更现代、更惊人的洞见所取代,这本身也可以被视为一个略偏悲观的信号。
AI 已经可以自动化 AI 工程中的大片工作
如果把上面所有证据放在一起,我们可以看到这样一幅图景:
在 Clark 看来,这些证据已经非常有说服力地表明:今天的 AI 已经可以自动化 AI 工程中的大片工作,甚至可能覆盖其中的全部环节。
不过,目前还不清楚 AI 能在多大程度上自动化 AI 研究本身。因为研究中的某些部分,可能不同于纯工程技能,仍然依赖更高层次的判断、问题意识和创造性。
但无论如何,一个清晰信号已经出现:今天的 AI 正在大幅加速从事 AI 开发的人类,让这些研究员和工程师可以通过与无数合成同事配对协作,放大自己的工作能力。
最后,AI 行业本身也几乎是在明说:自动化 AI 研发就是它们的目标。
OpenAI 希望在 2026 年 9 月之前构建一个自动化 AI 研究实习生。Anthropic 正在发表关于构建自动化 AI 对齐研究员的工作。DeepMind 在三大实验室中显得最谨慎,但也表示,在可行时应该推进对齐研究自动化。
自动化 AI 研发也已经成为许多创业公司的目标。Recursive Superintelligence 刚刚融资 5 亿美元,目标就是自动化 AI 研究。
换句话说,数千亿美元级别的既有资本和新增资本,正在投入到一批以自动化 AI 研发为目标的机构中。
因此,我们当然应该预期,这个方向至少会取得某种程度的进展。
为什么这很重要
这带来的影响深远,但在大众媒体对 AI 研发的报道中却鲜有讨论。以下这几个方面可以反映出 AI 研发带来的巨大挑战。
1. 我们必须把对齐做好:如今有效的对齐技术可能会在递归式自我改进中失效,因为 AI 系统会变得比监督它们的人员或系统智能得多。这是一个已被广泛研究的领域,所以他只简要概述一些问题:
2.AI 涉及的每一件事都会获得巨大的生产力倍增: 就像 AI 显著提高软件工程师的生产力一样,我们应该预期 AI 涉及的其他领域也会如此。这带来几个需要应对的问题:
3. 资本密集型、人力轻型经济的形成 :上述所有关于 AI 研发的证据也表明,AI 系统越来越有能力自主运营企业。这意味着我们可以预期,经济中的一部分将被新一代公司占据,这些公司可能是资本密集型(因为它们拥有大量计算机),或运营开支密集型(因为它们在 AI 服务上花费大量资金并在其基础上创造价值),相比今天的企业,它们对人力的依赖相对较低 —— 因为随着 AI 系统能力持续增强,投入 AI 的边际价值会不断增长。实际上,这将表现为「机器经济」在更大「人类经济」中逐渐形成,随着时间推移,AI 运营的公司可能会开始相互交易,从而改变经济结构,并引发关于不平等和再分配的各种问题。最终,可能会出现完全由 AI 系统自主运营的公司,这将加剧上述问题,同时带来许多新的治理挑战。
凝视黑洞
基于以上分析,作者认为到 2028 年底,我们看到自动化 AI 研发(即前沿模型能够自主训练其继任版本)的概率约为 60%。为什么不预期它在 2027 年出现?原因是作者认为 AI 研究仍然需要创造力和异议见解才能前进,到目前为止,AI 系统尚未以变革性和重大方式展示这一点(尽管在加速数学研究上的一些结果有启示)。如果非要他给出 2027 年的概率,他会说 30%。
如果到 2028 年底还没有出现,我们可能就会揭示当前技术范式中的一些根本性缺陷,需要人类发明推动进一步发展。
参考链接:
https://x.com/jackclarkSF/status/2051312759594471886
https://importai.substack.com/p/import-ai-455-automating-ai-research?r=1ds20&utm_campaign=post&utm_medium=email&triedRedirect=true
文章来自于微信公众号 "机器之心",作者 "机器之心"



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
