# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
UniGeo通过视频模型的连续视角先验与统一几何引导,实现稳定、高质量的相机可控图像生成,全面超越现有方法,在不同幅度的相机运动中提升跨视角一致性与结构稳定性。
当前主流的相机可控图像编辑主要基于图像扩散模型,通过处理离散视角映射,在场景生成和新视角合成领域取得了显著成功。
然而,图像模型天生的离散属性使其在应对连续相机运动时,极易出现几何漂移和结构退化。现有方法引入的几何引导也往往是碎片化的(如仅在表示层注入点云),这导致即使引入视频模型来克服图像模型的缺点,提供连续视角先验,模型也依然难以形成稳定的全局几何理解,无法彻底消除结构退化现象。
近日,浙大联合哈佛发布了全新的基于视频模型的统一几何引导相机可控编辑框架UniGeo。该框架系统性地打破了碎片化瓶颈,创新性地在决定生成输出的三个核心层面(表示层、架构层、损失函数层)全面注入了统一的几何引导。结合视频模型的连续先验与全局统一的几何引导,UniGeo 有效克服了结构退化问题,显著提升了在不同幅度的相机运动下的视觉质量与跨视角几何一致性。

模型代码网址:https://github.com/mo230761/UniGeo
英文技术报告网址:https://arxiv.org/pdf/2604.17565
Project Page网址:https://mo230761.github.io/UniGeo.github.io/
HF Space网址:https://huggingface.co/spaces/123123aa123/UniGeo
现有主流的相机可控图像编辑(Camera-controllable image editing)主要依托于图像扩散模型。其基本范式是:通过处理离散的二维视角映射,并辅以局部层面的几何信息(如仅在表示层注入点云),来合成不同相机姿态下的新场景。这一技术路径在二维视角的转换上取得了显著进展。
然而,这类方法在应对真实的连续相机运动时,面临着跨视角几何不一致和结构退化等严峻问题。真实物理世界中的相机运动在三维空间内是平滑且连续的,但受限于图像模型天生的「离散属性」,以及仅停留在单一层面的「碎片化」几何引导,现有模型内部难以形成全局协同的三维几何对应关系,导致生成过程常常发生几何漂移。
鉴此,研究团队认为,要实现高保真的相机可控图像生成,必须摒弃以往「离散生成+碎片化几何引导」的局限思路。视频模型天然具备连续视角建模的先验能力,这为攻克上述难题提供了绝佳基座。
但仅引入视频先验并不充分,研究团队在此基础上提出了一条系统性重构的新路径:即系统地将「统一几何引导」贯穿于生成模型的全链路,确保模型从特征输入到特征交互、再到最终优化的每一个环节,都遵循严格的三维几何引导。
在该思路的指引下,研究团队探索了连续视频先验与全局几何引导的深度融合,提出了全新的相机可控图像编辑框架 UniGeo。该框架系统地重构了决定生成输出的三大核心基石:在表示层实现帧解耦的几何参考注入,在架构层引入对齐多视角的几何锚点注意力,并在损失函数层强化轨迹端点的几何监督。
UniGeo 成功打通了视频模型与三维几何理解之间的壁垒,在不同幅度的相机运动下均实现了跨视角一致性的突破,或将为影视后期制作、具身智能感知等依赖高可靠渲染的前沿领域提供坚实的基础模型积累。
给定输入图像与相机控制指令,UniGeo 的目标是在严格保持三维几何结构的前提下合成新视角。为此,模型从表示层、架构层和损失函数层系统性地注入了统一几何引导(图1)。
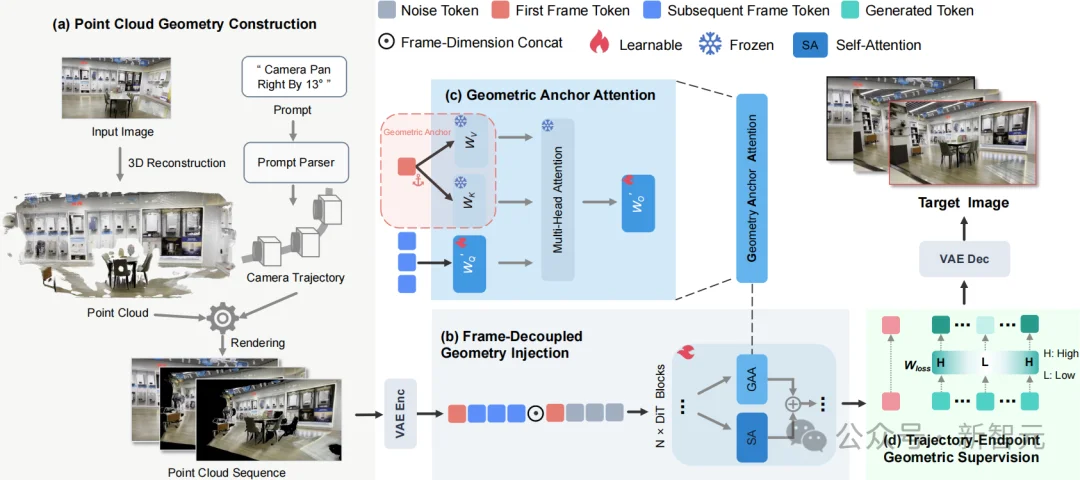
图1. UniGeo框架概览
在表示层,为避免直接输入相机参数带来的映射模糊,模型构建了帧解耦点云注入机制。该机制首先提取首帧点云并沿目标相机轨迹渲染,生成显式的 3D 几何先验序列。随后,区别于传统的通道拼接,模型将该渲染序列作为独立的几何上下文,与目标视频特征在帧维度(Frame-dim)进行拼接。这一解耦设计避免了强硬的像素级对齐,使几何先验能够与视频特征在网络中灵活交互并提升容错率。
在架构层,为维持连续生成中的跨视角结构一致性,模型引入了几何锚点注意力。该机制将序列首帧显式指定为「几何锚点」,后续所有帧均通过新增的少量可学习投影矩阵(Query 与 Output),持续与首帧的 Key 和 Value 进行注意力交互。这一设计在不破坏预训练视频生成先验的前提下,以极低的计算开销在微观特征层面实现了全局的结构对齐。
在损失函数层,为强化目标最终视角的结构保真度,模型提出了轨迹端点几何监督策略。在稀疏时间采样的基础上,模型将各时间步的损失权重设计为随时间中心距离递增的二次函数,从而增加对轨迹两端(特别是目标端点)的几何惩罚力度。进一步结合在序列末尾复制扩展目标帧的联合建模策略,模型以持续的几何引导严格锁定了最终视角的 3D 结构表达。
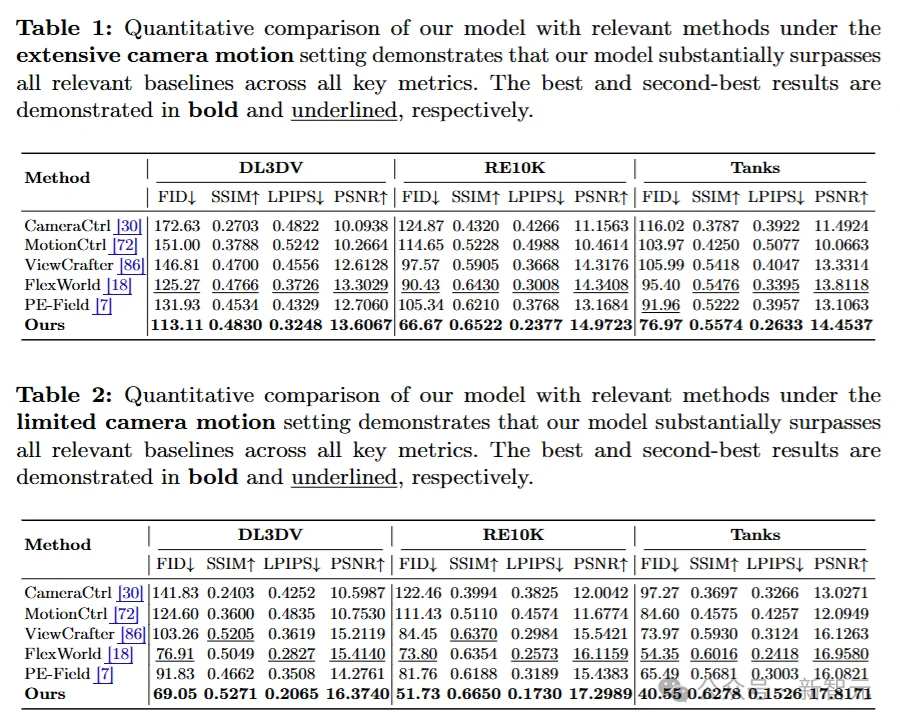
UniGeo 在跨视角几何一致性与高保真生成质量上实现了全面领跑。在 DL3DV、RE10K 以及 Tanks 等多个权威数据集上,面对大幅度(Extensive)和小幅度(Limited)相机运动的双重测试,UniGeo 全面超越了 CameraCtrl、MotionCtrl、ViewCrafter、FlexWorld 以及 PE-Field 等现有主流方法,在所有关键量化评估指标上均取得了最佳(SOTA)成绩。
在视觉生成效果层面,UniGeo 直击现有方法在物理结构上的痛点。定性对比结果显示,现有模型在相机运动(尤其是大范围视角转移)下,往往难以维持场景的底层几何结构,极易产生结构重叠、几何关系扭曲以及局部内容割裂等严重伪影。相比之下,UniGeo 凭借全局统一的几何引导,在跨视角转换中展现出了极高的结构稳定性,生成了极为自然、连贯的新视角画面(图2)。

图2. 定性对比结果
进一步的中间连续轨迹可视化彻底展现了 UniGeo 的过程优势。模型能够极其平滑且精准地模拟由相机运动驱动的连续几何变换,在整个视角的中间推演过程中保持了高度的结构连贯性。这种平滑的过渡完美契合了真实的物理相机运动规律,从而在全链路上保证了最终渲染新视角时的绝对精准与极高画质(图3)。

图3. 中间轨迹可视化
本次发布的相机可控图像编辑框架 UniGeo 深度探索了视频扩散模型的连续性先验与三维几何约束之间的内在联系,系统性地在表示层、架构层和损失函数层贯穿了统一的几何引导,通过全链路的三维对齐克服了传统碎片化几何注入带来的结构退化局限,在确保场景结构完整性的同时,建立了极其可靠的跨视角对应关系。
这种具备高度一致性的连续视角建模能力,在面对各类复杂且大范围的相机运动时,不仅全面超越了现有方法的几何可靠性与视觉质量,也为影视后期制作、具身智能感知等高度依赖严格空间连贯性的视觉生成任务,提供了原则性且高效的解决方案。
未来,该团队将进一步探索连续视频先验与真实世界三维空间物理结构之间的深度耦合机制,构建二维视频生成与三维空间智能之间的桥梁,期望通过整合统一的几何引导理念来突破现有离散图像生成模型的局限,进而实现高结构保真、支持复杂场景自由漫游的下一代可控视觉生成模型,为未来的三维视觉生成生态提供重要启发。
参考资料:
https://arxiv.org/pdf/2604.17565
文章来自于"新智元",作者 "LRST"。



