# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Noiz AI是一家低调务实的音频AI公司,由前Meta、字节员工,及清华、北大、港科大校友联合创立。团队大部分成员是00后,清北校友占据半数左右。
团队已经推出十几款全栈音频模型,自2025年发布Beta版以来,全球的创作者和开发者用户已突破100万。公司正式设立半年左右,ARR接近400万美元,已完成seed、seed+轮融资,投资方包括北极光创投、英诺天使基金。
Voice AI是硅谷VC“集体踏空”的一大遗憾。每当讨论到“你在AI赛道最后悔的项目是什么”,a16z、Lightspeed、Accel、BVP、Benchmark都公开坦言——是ElevenLabs。彼时,VC普遍认为“音频模型是巨头的战场,不是创业公司的机会”。也正是这条共识,让他们pass了早期的ElevenLabs。
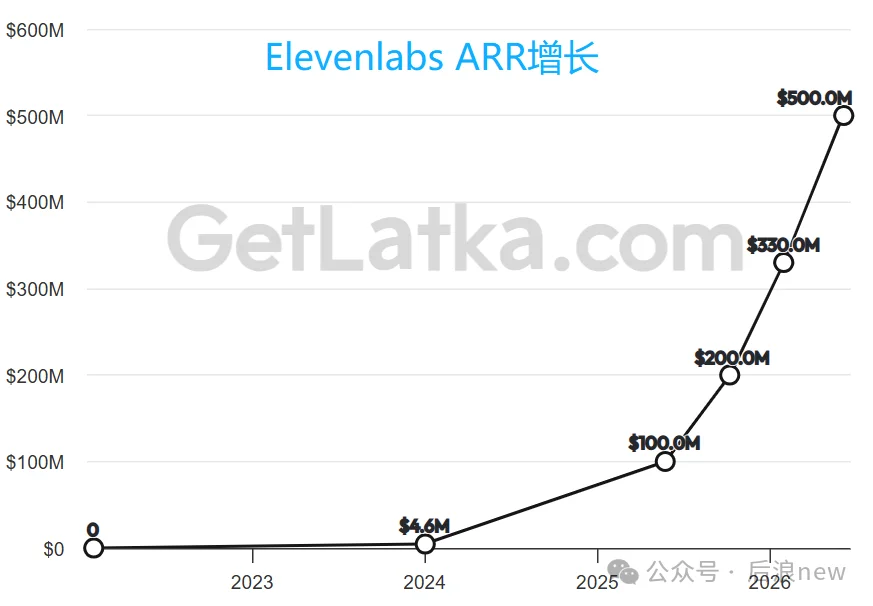
ElevenLabs的爆发力远超预期,ARR从2亿上升至3.3亿美元,只用了5个月,而后突破至5亿美元,仅用4个月。硅谷VC们后期不惜以数十倍的价格连续押注,D轮估值110亿美元,英伟达、Salesforce等产业方也参与投资。
为什么Voice AI是一个天花板高、爆发力强的独立赛道?并且能打破“巨头垄断”的固有认知?
我和Noiz AI CEO陈前进行了交流,他分享了行业洞察和创业故事。Noiz AI团队长期处于行业前沿,核心成员主导或参与开发了Mockingbird、MastGCT、index-tts-vllm、DeepAudit、YuE等多个具有广泛影响力的开源项目,累计50K+stars。
1. 介绍核心团队
陈前:Noiz AI目前整体近30人,以00后为主,清华、北大人才占据近半数,核心成员有几位:
我们团队launch了业界首个多语言语音克隆模型(2021) 、首个Audio-Editing Agent(2025),首个音频理解-生成-编辑大一统框架Audio-Omni等。
2. 我看到Noiz AI多位成员有艺术、音乐背景,也在网上看到很多用户对你们模型的评价,反复提及“审美感”,这种“感性审美”似乎映射到了产品上?
陈前:语音和文本、视觉模型不一样,不仅需要算法,也需要听觉审美与艺术感知。

4. 你们刚发表了Audio-Omni——理解-生成-编辑一体化框架,相较于MMAudio,这种架构训练和推理成本都比较高,一体化的底层考量是什么?

陈前:行业普遍采用的是拆分式研发,我们这套架构的研发逻辑是为了贴合创作者的真实生产链路。
现在音频AI行业还处在抽卡阶段,反复生成、效率很低。图像AI从“随机生成的Midjourney时期”进化到“精准编辑的NanoBanana时刻”,音频也一定会走到三位一体成熟阶段,短视频、配音、配乐等场景都需要先理解内容、再精准生成、最后精细编辑,这是必然趋势。
5. 现在多模态大模型逐步融合音视频,放到一起做,是否还有必要拆分独立音频模型?
陈前:光波和机械波在物理上完全是两种东西,图像引擎和音频引擎底层逻辑天生就是分开的。
就算多模态模型把音视频打包成一个黑盒输出,底层训练、数据、推理依然是独立的两套系统。视觉世界模型只关注物体物理碰撞,没有声音相关数据,无法生成符合物理逻辑的音效。像空间听觉、360°声场、远近音量衰减这些专属音频能力,也没法靠视觉数据训练出来。所以,独立的音频模型和音频引擎是长期刚需。轻量化融合模型虽然成本低,但效果上限不够,撑不起专业创作和空间音频这类复杂场景。
6. 你们已经有100万用户了,请介绍核心场景和客群分布
陈前:内容创作者目前占比最高,其次是电商从业者、影视制作团队、独立开发者用户。
7. 你们在OpenClaw上的TTS Skill装机量夺冠,这段经历是否让你们发现了一些新需求?

陈前:我们发现下一阶段核心增量是Agent专属音频能力,从服务人类扩展到赋能Agent。我认为语音将是未来3年最先爆发的interface。
对比视觉,音频具备天然优势:视觉交互受光线、角度、存储成本限制,而音频硬件可以低功耗、低成本always On。复杂声场下的人声分离、定向收音、情绪识别,是下一代听觉智能的核心需求,目前几乎处于空白状态。
8. Lightspeed说Elenvenlabs在creator群体的占有率是60%,在企业级市场渗透了40%的财富500强。 在Elenvenlabs已经占据一定优势的情况下,Noiz的市场定位和目标什么?
陈前:音频模型厂商远未到存量博弈阶段,而是处于正和博弈、把蛋糕做大的早期。AI语音工具在创作者群体的渗透率还不到10%,Elenvenlabs的ARR仅一个季度净增1亿美元,足以印证赛道高增长潜力。
现在有一大变量是短视频、短剧爆发,“短内容”逻辑和“长内容”完全不一样,需要emotional、dramatic、强张力的声音,要适配5秒留人要求、高密度内容节奏,这恰恰是我们擅长的方向。
9. 如果要适配短内容场景,需要从模型层重新训练吗?
陈前:是的,短内容对模型层直接提出了全新要求。Elevenlabs更专精于长内容,注重音色稳定性、电影版的质感。我们针对短内容优化了几个方向:
10. Elenvenlabs创始人认为音频模型有几个“制胜点”:模型架构创新、高质量的语音数据、人才。他说全球语音AI顶尖人才仅50-100人。我想请教的是,你们认为音频AI模型的难点有哪些?
陈前:Voice AI确实是一个高门槛赛道。我觉得最核心的还是高质量语料,除了合规获取,数据筛选与匹配能力也是核心竞争力。人才确实很稀缺,Elenvenlabs的说法一点都不夸张,我们的算法负责人田泽越就是顶尖researcher之一。模型架构很关键,但如果有顶级算法人才,架构就很难成为长期壁垒了。
11. Elenvenlabs说过,用户要的不仅仅是音频片段,核心要求不在于“清晰度”,而是“配对的质量”,高质量的数据应包含丰富的上下文信息,你刚刚也强调了匹配能力
陈前:是的,匹配度的重要性大于清晰度。影视配音需要棚录纯净音质,但电商配音不能追求超高清晰度,必须有生活化环境噪音才写实,场景化匹配能力也是关键差异之一。
12. 我们再聊聊“模应一体化”。你们采用了模型和产品层并行模式,Elenvenlabs也是这个模式。我想起来闫俊杰分享过,Minimax的AI陪伴应用比其他同类产品的持续性更强,他认为核心在于“模应一体”——模型迭代太快了,每一次模型进步都会推着自家应用自然进化。我想请教你,对语音模型厂商而言,垂直一体化是主动的战略选择,还是因为生态不成熟而不得不走的路径?
陈前:对Noiz AI而言,是主动选择,模型和产品层是互为杠杆的。垂直一体化能让模型迭代直接对齐真实的用户场景,形成模型迭代→产品迭代→用户反馈→模型优化的高信噪比数据飞轮,必须两条腿走路。模型迭代牵引产品落地,真实应用反馈反向指导模型研发方向。
13. 你们认为语音模型会商品化吗?
陈前:现在有这个趋势。但我们认为,即便底层模型商品化,品牌、听觉审美、场景化能力、产品工具链、生态依然会形成长期差异化,因为语音本质具备艺术属性,和音乐一样,无法变成标准化售卖的标品。短视频、影视、音乐、硬件交互等细分赛道会诞生专属音频解决方案,具备长期生存空间。
14. 你们目前的商业模式是什么?
陈前:现阶段以C端订阅为主,也有B端API服务。目前海外用户居多,但国内也有不少用户,我们投放规模很小,大部分是“自来水”。
15. 收费模式为什么没和token消耗量挂钩?
陈前:token成本加成逻辑在文本、视频领域行得通,因为token消耗很快,但不适用于音频领域,因为音频生成的算力消耗本身不高,用户不是为用量付费,而是为效果、情绪、场景化功能付费,属于典型的价值定价。
16. 最后想问你的是,Noiz AI接下来的业务目标是什么?
陈前:短期有几个重心:
文章来自于"后浪new",作者 "Evelyn"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
