# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI能实现真正的沉浸式扮演了。
大语言模型在角色扮演任务上进展迅速,但现有系统往往缺乏沉浸感和适应性:
环境信息未被充分建模,场景与角色也多为静态,难以支撑多角色调度、场景切换、动态引入新人等复杂叙事需求。
现在,浙江大学联合腾讯优图实验室提出AdaMARP(Adaptive Multi-Agent Interaction Framework for General Immersive Role-Playing)——
一种面向通用沉浸式角色扮演的自适应多智能体交互框架。

该框架通过四通道消息格式和场景管理器,让AI不仅会「说」,还会「想」、会「动」、会「感知环境」,并在复杂叙事中灵活切换场景、动态引入新角色。
目前该工作已被ACL 2026接收。
大语言模型在角色扮演任务上的应用正快速普及:
用户可以设定任意角色(历史人物、小说角色、原创人设),与AI进行持续的叙事互动。
理想状态下,AI应当能够代入这个角色,在情境中保持人设一致、对环境敏感、对他人话语做出贴合关系的回应。
但现实中,大多数系统更像是会说话的聊天机器人:对话虽流畅,却缺少情境感和叙事张力。
以探案为例,故事往往在一个固定场景、固定人物之间反复进行,无法四处搜证、无法与不同证人轮番对质、无法让环境线索真正参与推理,缺乏真正的剧情推进和世界变化。
研究团队指出,当前角色扮演系统主要存在两类局限。
不少工作只建模角色的台词(Speech);后来有研究加入了动作(Action)或内心独白(Thought),但在叙事中,环境并非可有可无的装饰。
它会塑造氛围、推动因果,连接角色的行动、世界的变化与后续对话。
例如:案发现场地毯上的蜡痕、煤气灯照出的阴影角度、证人住所门口未干的泥渍……
这些环境信号既能支撑推理(蜡痕指向婚礼蜡烛,泥渍暗示来客方向),也能成为剧情转折的契机(换一个场景,就换一批证人和线索)。
若系统不把环境当作与台词、动作同等重要的信号来建模,角色就容易像是在一个空房间里自言自语,探案也就失去了「搜证」的实感。
多数系统假定:场景不变、人物不变、用户与某个固定角色一问一答。
但探案恰恰需要四处搜证:从案发现场到苏格兰场,从房东太太的公寓到嫌疑人的宅邸,每个场景都有不同的环境和证人。
谁来接下一句?是先问管家还是先问马车夫?何时换场景、何时引入新证人?
现有框架很少系统性地回答这些问题。
没有这些能力,故事就很难自然地「演下去」,更像是在一个封闭的聊天室里重复对话,而非一场真正的调查。
AdaMARP从两个方向回应上述问题。
AdaMARP 为每一轮交互定义了一种四通道交织的消息格式:
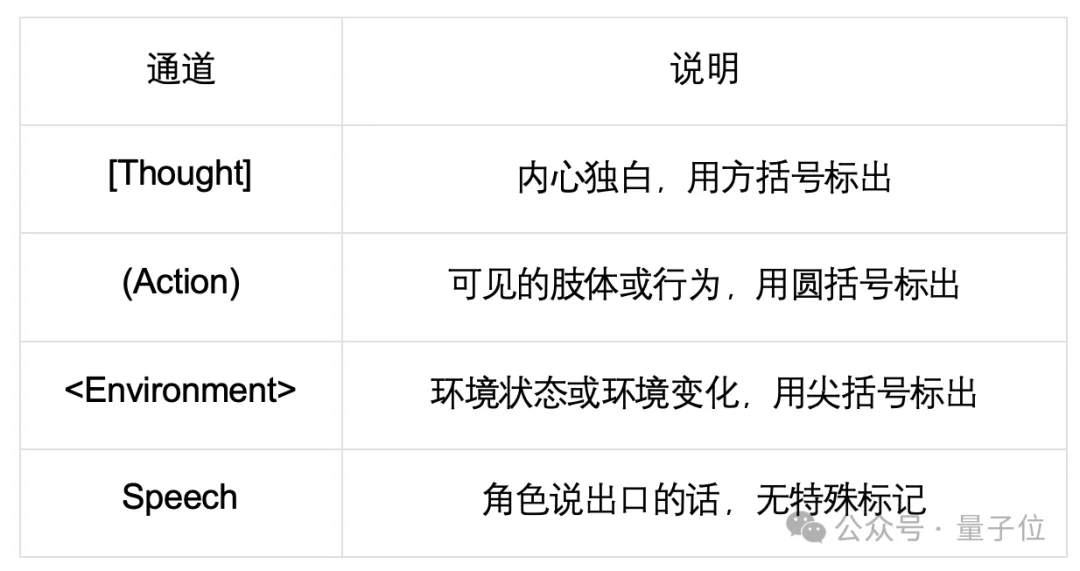
这样,一个完整的回应可以同时包含思考、动作、环境感知和言语,且顺序可灵活交织。
例如,福尔摩斯在讯问证人时:<煤气灯摇曳,证人下意识地瞥向壁炉上的时钟> [他在回避具体时间,那段时间他不在场](用烟斗轻轻敲了敲桌面)案发当晚八点到九点,您究竟在哪里?
环境线索 → 内心推理 → 施压动作 → 追问话语,四者形成一条清晰的因果链,更贴近真实探案的节奏。
同时,环境不再只是点缀。
案发现场的物证摆放会支撑角色的推理链条;证人住所的布置(凌乱的书桌、未拆的信件)可以暗示性格与行踪;场景切换则自然引入新的证人与线索。
环境既参与氛围营造,也参与推理与叙事的因果。
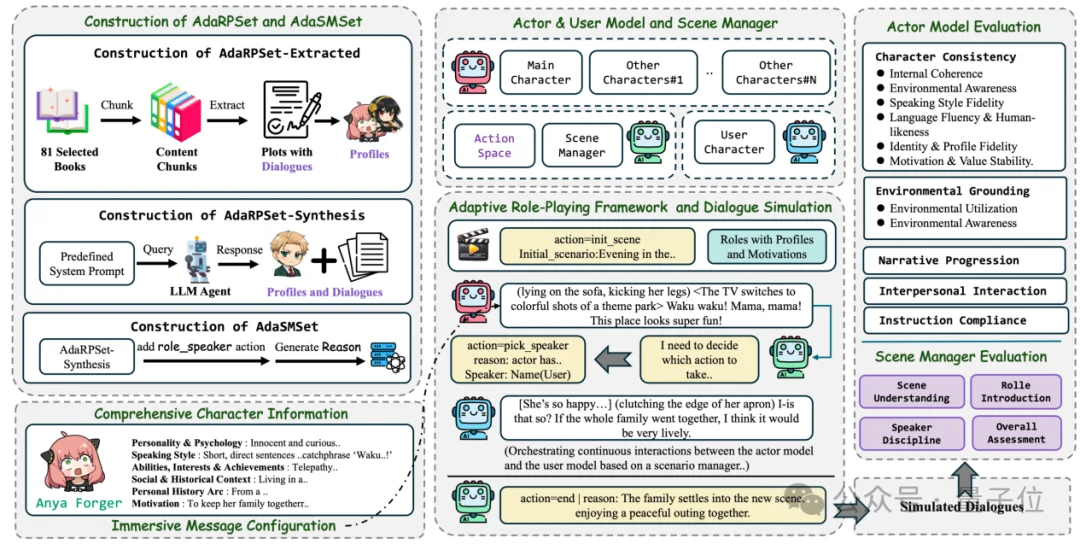
AdaMARP将角色扮演建模为三个智能体的协作:
场景管理器通过一组离散动作来驱动整场「演出」:
每一步决策都会输出对应的理由,使调度过程可解释、可约束。这样,系统既能决定「谁来接话」,也能决定「何时换场景搜证」「何时引入新证人」,从而支持更复杂、更开放的多角色探案叙事。

上述设计在实践中如何运转?不妨看一段福尔摩斯探案叙事的拆解。
各环节均由场景管理器调度,需要注意的是本案例仅仅用于理解,省略了部分细节例如详细的角色档案、角色动机场景管理器的原始输出等
角色:福尔摩斯、华生。
初始场景:伦敦东区某寓所三层,案发后的深夜。厚重的窗帘半掩,煤气灯在风中摇曳,在墙面上投下晃动的影子。壁炉已熄,余烬旁的地毯上有一小块凝固的蜡痕,不远处散落着几根烧尽的火柴。福尔摩斯与华生立于现场中央,窗外隐约传来泰晤士河上的汽笛声。
场景管理器
福尔摩斯:<煤气灯昏黄,蜡痕在阴影中隐约可见> [烛泪的位置和形状……婚礼蜡烛,而且是左手持烛](蹲下身捻起碎屑嗅了嗅,站起身)华生,去查查最近三个月内举办过婚礼、且家中有人左撇子的家庭。
场景管理器
华生:(点点头)明白(推门而出)<走廊里传来渐远的脚步声,随后是马车驶离的声响>
场景管理器
场景管理器
场景管理器
福尔摩斯:(摘下礼帽,微微颔首)夫人,案发当晚八点到九点,您是否听见三楼有任何异常声响?
场景管理器
房东太太:<下意识地瞥向壁炉上的时钟>
场景管理器
福尔摩斯:[她在回避具体时间](用烟斗轻轻敲了敲桌面)那段时间,您究竟在哪里?
场景管理器
房东太太:(咬了咬嘴唇,正要开口——)
场景管理器
场景管理器
雷斯垂德:福尔摩斯先生,我们发现了新的证人,马车夫说他当晚载过一名黑衣男子…………
初始场景、发言调度、场景切换、角色引入均由场景管理器驱动,且每步均以「选择的动作为:Action_name | 理由:Reason」的形式可解释。
这种结构化、多通道、多场景、多角色的连贯叙事,恰恰是AdaMARP旨在支撑的探案节奏。
训练数据:从文学提取+从主题合成
为训练上述能力,研究团队构建了两个数据集,分别面向Actor模型和场景管理器。
AdaRPSet面向Actor模型,由两个互补子集构成:
从Goodreads「最佳书籍」榜单选取81本代表性文学作品,经三阶段管道构建:
(1) 分块:按章节切分并合并为合适长度的文本块;
(2) LLM提取:识别连贯场景与多角色互动轨迹,将对话直接转化为统一的Thought–Action–Environment–Speech 格式,严格区分角色动作与环境信号;
(3) 角色画像生成:按角色聚合全书证据,合成七维画像(身份与外貌、性格与心理、说话风格、能力兴趣、社会背景、个人经历、人际关系)。
每条轨迹采用多视角增强:同一场景下,轮流指定不同角色为主角,其余为NPC,从而扩展训练样本。
提取数据天然具有文学质感与人味,适合学习格式规范与基础演绎能力。
文学提取的轨迹多为单场景、角色固定的互动,对场景切换与动态引入新角色的覆盖不足。
研究团队因此构建合成数据:在20类主题(冒险、探索、探案、解谜、密谋、营救、逃亡、战斗、浪漫、友谊、竞争、背叛、和解、谈判、策略、魔法、末世等)下,由LLM生成情节级轨迹。
每条轨迹明确包含:初始情境、主控角色与多个辅助角色、多轮对话(统一格式),以及场景管理器的控制消息(如 switch_scene、add_role)。
每条轨迹至少包含一次场景切换和一次角色引入,用以强化模型对动态叙事的适应能力。
合成数据与提取数据在训练时合并,使Actor模型既能学格式与人味,又能学动态调度下的演绎。
关于两个互补子集对应的细节信息如下表所示。
其中Plots指的是初始情节片段(包含初始场景和初始角色)的数量,Roles指的是不重复的角色数量,Convs指的是指的是完整的角色扮演记录(初始情节片段和衍生的不同对话轨迹)的数量,Utterances指的是所有角色扮演记录中对话的数量,Avg. Turns 指的是每个角色扮演记录的平均对话数量。

AdaSMSet面向场景管理器,在AdaRPSet-Synthesis的基础上构建。
合成轨迹已包含init_scene、switch_scene、add_role、end等控制动作,但缺少最核心的发言者选择监督。
研究团队在每两段角色发言之间插入 pick_speaker 动作,由强指令遵循模型为每次选择生成自然语言理由(reason),并约束理由需具体、上下文相关,避免套路化表述。
AdaSMSet因而覆盖场景管理器的全部五类动作,为「何时换场景」「何时加人」「谁来接下一句」及对应理由提供端到端监督。
由于AdaSMSet源于AdaRPSet-Synthesis,因此对应的Plots、Roles和Convs的统计信息与其一致,由于添加了pick_speaker记录,因此最终的Utterances数量为496493,Avg.Turns为50.15。
AdaRPSet与AdaSMSet共同支撑AdaMARP:前者让角色「会演」(保持人设、响应环境、推进剧情),后者让系统「会导」(合理切换场景、引入角色、安排发言顺序)。
二者共享统一的角色画像与消息格式,确保Actor与场景管理器在同一叙事框架下协同工作。
有了训练数据和框架,还需要回答一个关键问题:
怎样评估「沉浸式、可适应」的角色扮演是否真的做得好?
现有很多评测更偏向「一句话好不好」或「单轮对话像不像这个人设」,难以覆盖AdaMARP所关心的几点:
为此,研究团队提出了AdaptiveBench:一个面向自适应角色扮演的仿真评测框架。
它从AdaRPSet-Synthesis的保留子集中选取剧情种子(20个话题,每个话题5个初始Plots,总共100个评估样本),在每个种子上同时运行三方角色:
在每个种子上,场景管理器连续发出若干轮pick_speaker、switch_scene、add_role动作,驱动Actor与用户侧完成一整段多轮对话。完整轨迹生成后,再由评估模型从轨迹级别给出多维评分。
具体而言,AdaptiveBench主要从轨迹级别(Trajectory-level)评估模型,评分包含以下维度:
通过 AdaptiveBench,AdaMARP 不只是「有一个好看的框架设计」,而是可以在统一的仿真环境下,对不同模型、不同训练方式的优劣进行可重复、可量化的比较。
从叙事逻辑与情境交互能力来看,AdaMARP能够产出更连贯的内心—行为—言语链,更好地利用环境推动叙事(例如探案中的物证与场景线索),并在多角色、多场景的复杂情境中实现灵活调度(例如切换场景搜证、与不同证人轮番对质)。
这为无论是探案推理、冒险叙事还是其他需要情境与调度的互动的更沉浸式的AI角色扮演提供了一个新的技术路径。
项目主页:https://xuzhenhua55.github.io/AdaMARP/#overview
文章来自于"量子位",作者 "AdaMARP团队"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
