# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前几天在 Milvus 社区,一位做以图搜图的朋友提了一个问题:
“我们要对2500 万张图片(转为1280 维向量)做以图搜图,单机支撑亿级数据的查询。但内存配置只有64GB,其中能分给向量数据库的最多32GB。但我用 Sizing Tool 算了一下,说要 139GB 内存,是不是没戏了?"
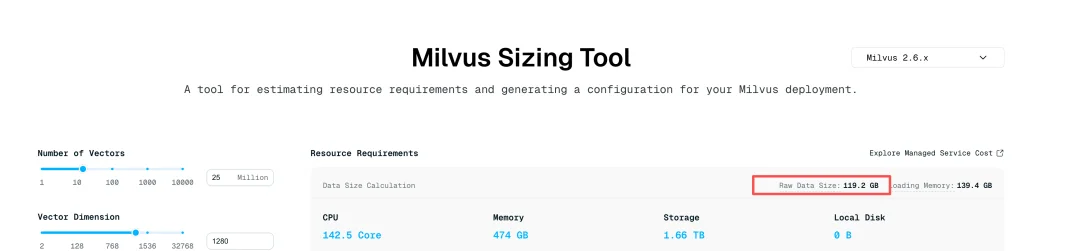
▲ Sizing Tool 估算结果:25M × 1280 维向量,Raw DataSize 119.2GB,Loading Memory 139.4GB
用HNSW之类看起来很高效的索引来看,这的确跑不通,但我们换个思路,试试最基础的FLAT 呢?
实践下来,借助FLAT ,不到 1GB 内存,查询延迟稳定在 100 毫秒以内,就能搞定2500 万向量的高效检索。
以下是我们的实践经验复盘。
在最终确定FLAT 之前,这个朋友先做了两轮其他索引的选型摸索:
第一次:AISAQ 索引。这是一种新的磁盘索引,理论上内存占用很低。但索引构建需要写入大量临时文件。之前测试过 5500万向量,load 一次集合,磁盘写入量达到 249GB,并且加载速度也非常慢,既费盘又费时间。
第二次:IVF_FLAT 索引。创建完索引后 load 集合,进度到 14% 就 一直挂着,最终失败。
两次碰壁后,他决定干脆用最基础的 FLAT 索引试试,没想到直接跑通了。
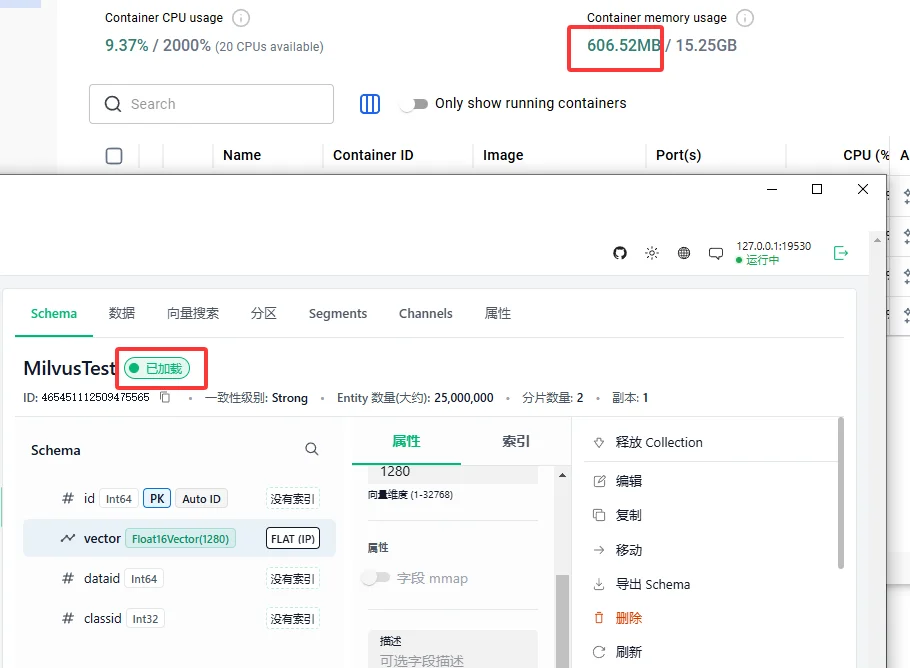
最后实际内存只用了不到 1GB,容器常驻内存也就 600MB 左右。启动峰值内存冲到 12.5GB,稳定后完全可控,查询首访约 30 秒,后续延迟稳稳控制在 100 毫秒内。
FLAT 是 Milvus 里最基础的索引类型——不建树、不建图、不聚类,查询时在原始向量上做暴力遍历。
按常理,2500 万条暴力搜索,内存和延迟都不可能达标。但milvus的三层优化叠加在一起,让它成了最优解。
存储时把向量精度从 FP32 降到 FP16:
单条向量:1280 维 × 4 字节 = 5120 字节 → 1280 维 × 2 字节 = 2560 字节
2500 万条总量:约 120GB → 约 60GB
FP16 在绝大多数检索场景下精度损失极小(Recall 差异通常 < 0.1%),但存储和内存占用直接对半砍。
即使用了 FP16,60GB 也远超 16GB 物理内存。第二把钥匙是 mmap。
FLAT 没有额外索引数据,所有数据就是原始向量本身。mmap 开启后,向量数据不再全量加载到内存,而是以内存映射文件的方式存在磁盘上,操作系统按需将访问到的数据页加载进内存,内存大幅节省!
从 Milvus 2.6 开始,向量原始数据的 mmap 默认开启。 这位朋友用的是 Milvus 2.6.14,并没有手动配置 mmap,但集群级默认配置已经帮他开了。
一个细节:Attu 界面显示的是 Schema 级别的 mmap 配置,不会反映集群级默认值。Attu 上看到 mmap 显示为"关闭",但实际上集群级已经启用了。
Trade-off:内存省下来了,但是对于原始向量开启mmap之后,磁盘会多占约 60GB。对于一台配了 SSD 的机器来说完全可以接受。
FP16 减半了数据量,mmap 解决了内存瓶颈,那 2500 万条暴力搜索的延迟呢?答案在查询模式里。他的每次查询都带标量过滤条件,类似如下表达式:
dataid in [123] AND classid in [0, 2, 3]
这个表达式先在标量字段上筛选,把 2500 万条候选集缩小到几百到几万条。然后 FLAT 的暴力搜索只需要在这个小子集上执行——几万条向量的暴力比较,现代 CPU 只需要毫秒级。同时结合前面的mmap,只需要把符合过滤条件的向量从磁盘加载到内存中计算,内存消耗也可以保持在很低的水平。
这也是为什么 FLAT 在这个场景下能赢过 IVF_FLAT 和 HNSW:当标量过滤已经把候选集压缩到很小的范围,额外的索引结构反而是负担——占内存、占构建时间,但对检索速度贡献微乎其微。
另外值得注意的一点,这个场景里的表达式比较简单,即使没有标量索引,过滤环节占用的耗时也比较低,对于 like,in 大的列表,json多层过滤 这些复杂的表达式,最好创建标量索引来降低过滤阶段的延时。
这个图搜案例的核心模式是:强标量过滤 + 实际搜索数据量远小于总量。符合这个模式的场景还有很多:
多租户 RAG:按 tenant_id 过滤,单个租户数据量通常只有几千到几万条,FLAT 绰绰有余
电商商品搜索:按品类、品牌过滤后在子集内搜索相似商品
日志和文档检索:按时间范围 + 来源过滤后做语义搜索
这类场景,都可以采用上面的 FLAT+FP16+Mmap 的方案,既享受到实惠的内存开销,又获得不错的检索性能。
另外,在这位社区朋友的案例中,Sizing Tool 按"全量数据加载到内存"估算,对于2500万 1280 维的向量计算出 139GB 的内存。这是一个保守的安全值——确保最坏情况下系统也能运行。
但实际部署中,向量精度,索引类型,标量过滤情况,mmap模式 都会影响真实内存需求,建议根据自己的真实负载,进行实际测试为准。

李成龙
Zilliz 资深开源布道师
文章来自于"Zilliz",作者 "李成龙"。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
