到底是谁会相信RAG已死啊?
到底是谁会相信RAG已死啊?最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。
来自主题: AI技术研报
9580 点击 2026-06-01 09:27
 搜索
搜索
最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

在这些场景,一个集合也许一个月只被查询几次,运行时间不超过5小时,用户也并不需要为此投入向量数据库级别的资源建设,让高性能资源一个月时间里有715小时都被浪费。相应的,成本也就成了这一场景下的优先考量要素。而解决这一问题,也是我们选择在近期推出Vector Lakebase 产品的初心所在。

RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。
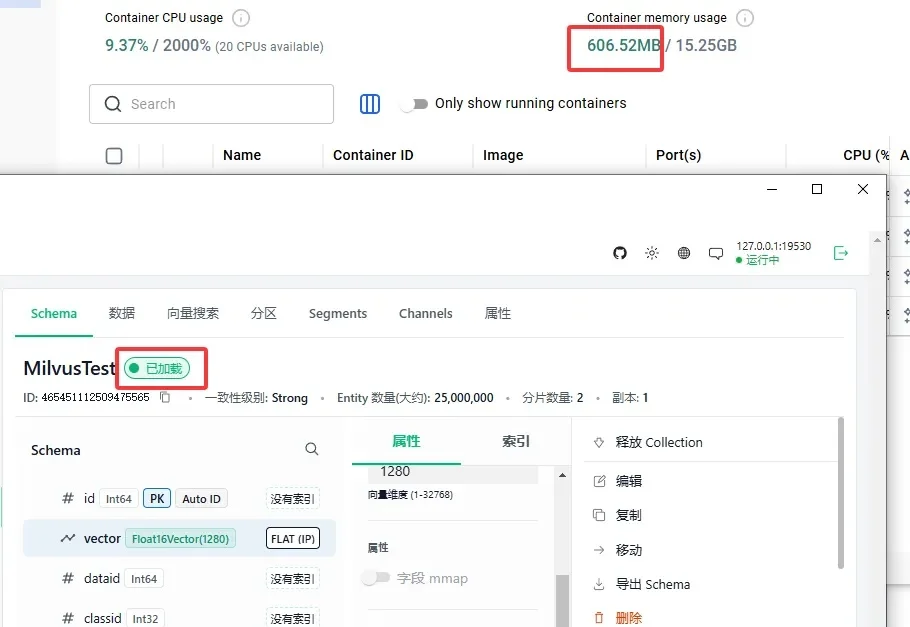
前几天在 Milvus 社区,一位做以图搜图的朋友提了一个问题:
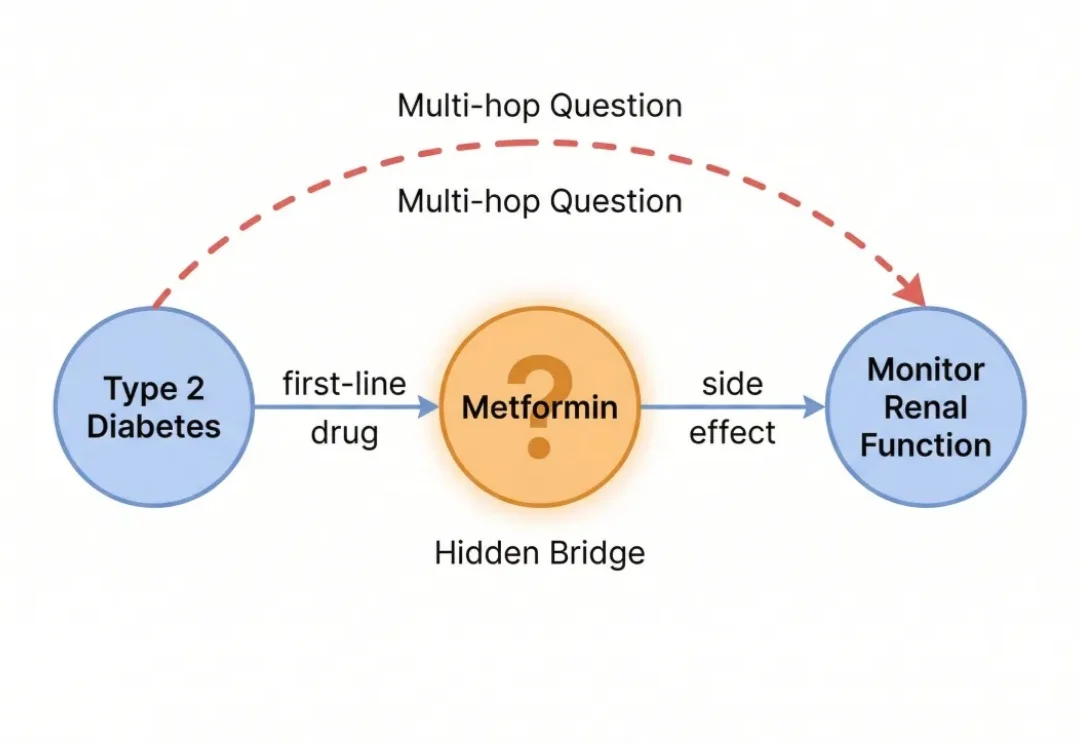
做 RAG 多跳问答的朋友,应该没有人还没被图数据库PUA 过。
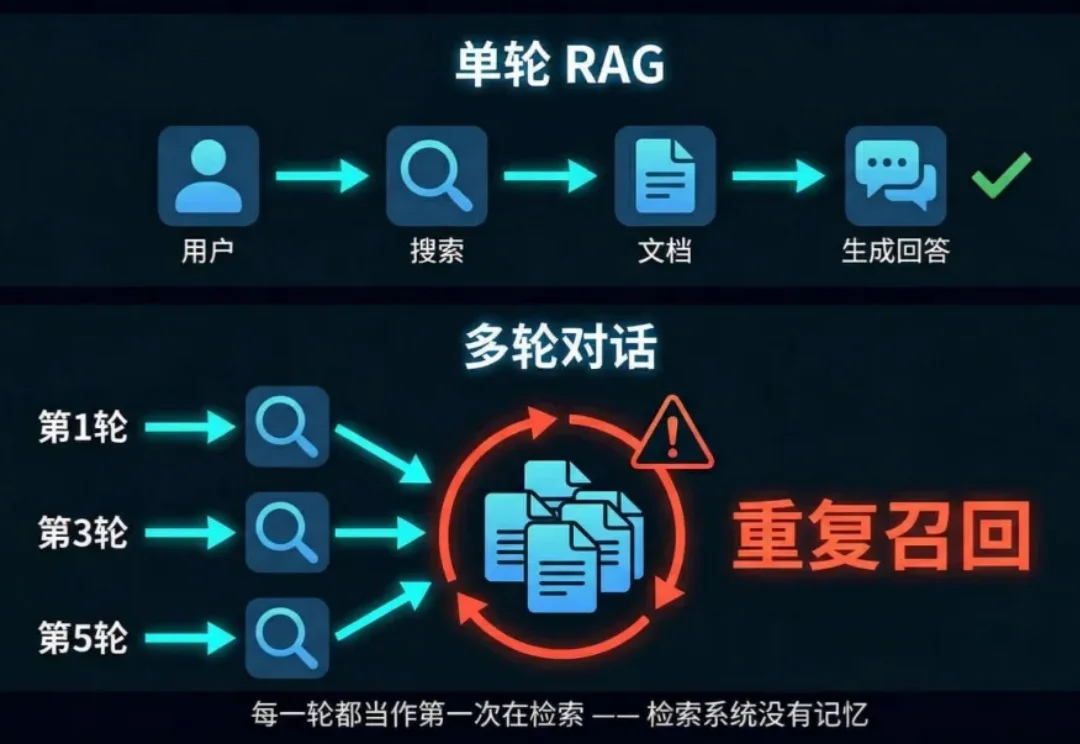
做 RAG 的团队,基本都会在多轮对话上吃过亏。

AI产品、生态协同双升级,中兴通讯交出战略升级满新答卷。
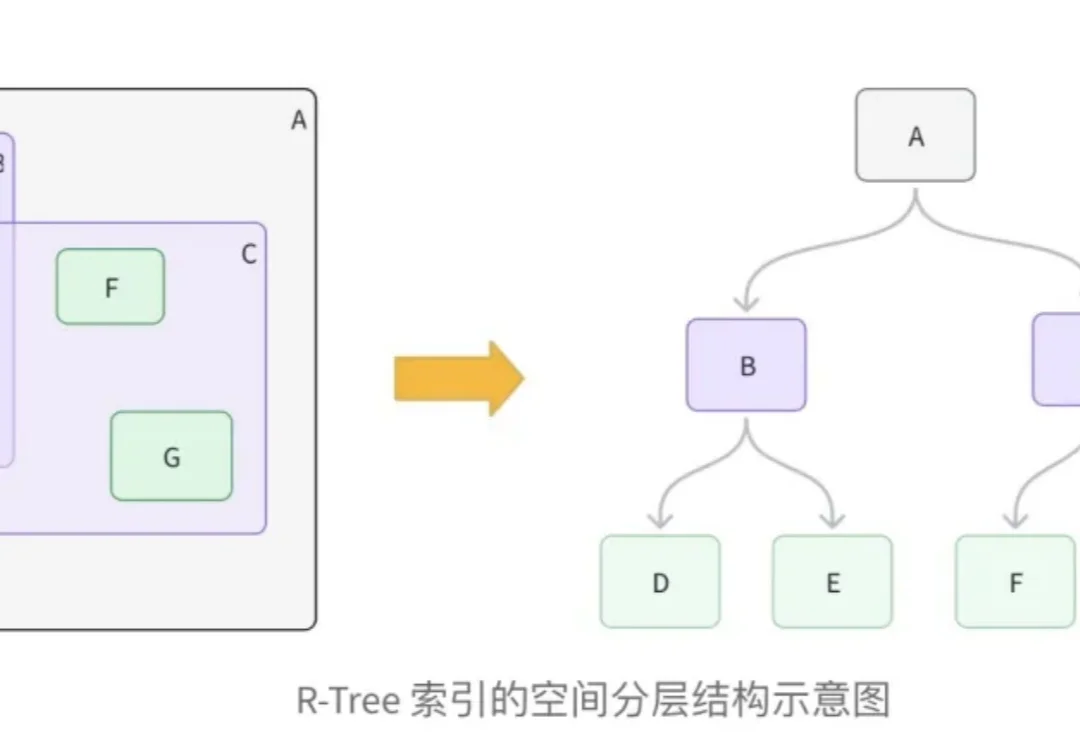
在向量数据库的工程实践中,处理多模态数据,特别是结合地理位置(LBS)与非结构化语义数据,一直是一个复杂的架构挑战。
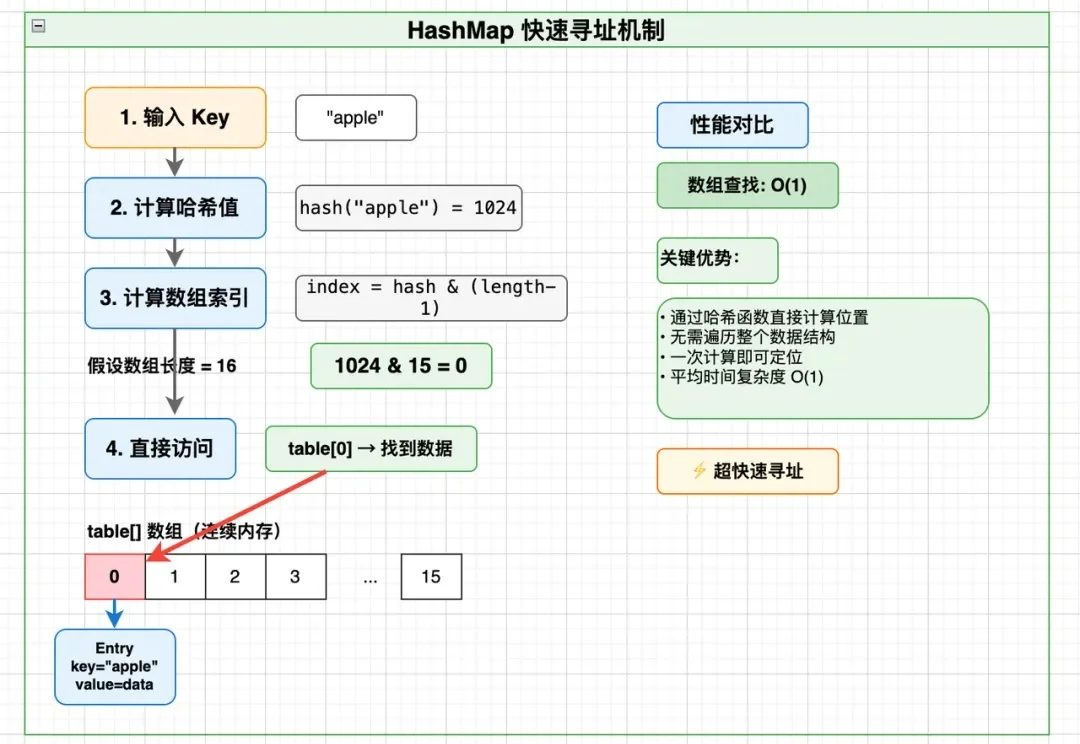
做后端、大数据、分布式存储的同学,大概率都遇到过这样的问题:
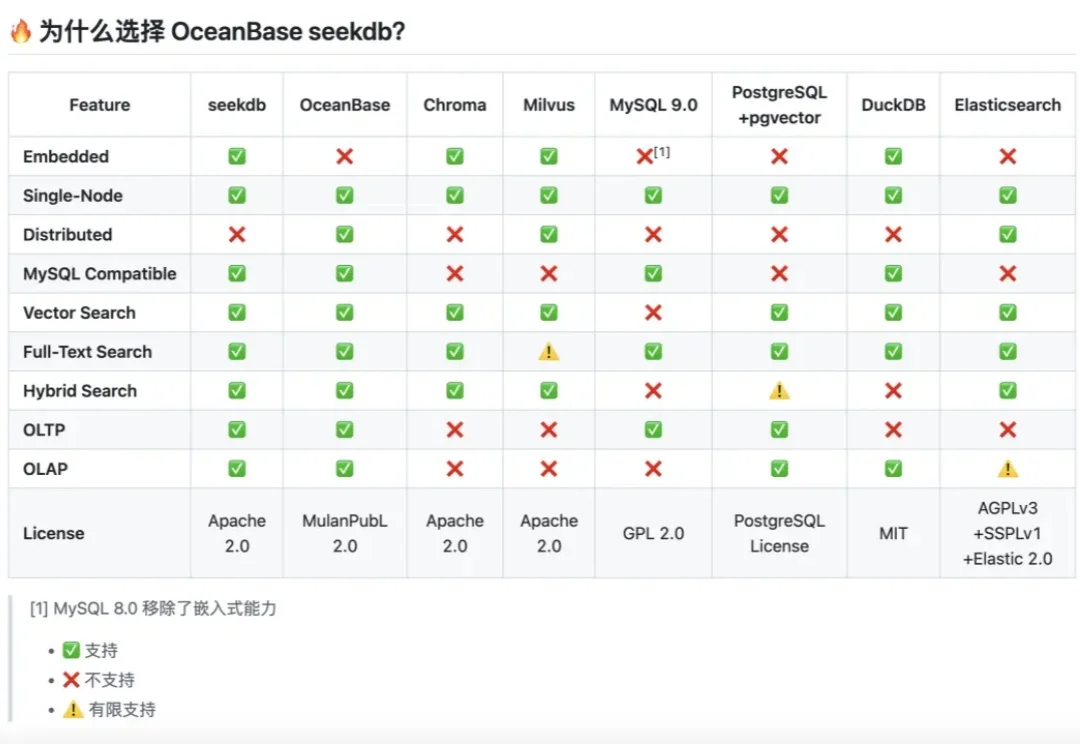
故事得从我们那个行业交流群说起。