# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在向量数据库的工程实践中,处理多模态数据,特别是结合地理位置(LBS)与非结构化语义数据,一直是一个复杂的架构挑战。
但随着 Milvus 2.6.4 版本的发布,原生 Geometry 数据类型与 R-Tree 索引的引入,向量数据库在处理空间+语义混合查询能力上,有了实质性的突破。
本文将深入剖析该特性的技术背景、实现原理、性能表现及工程实践指南。
在构建现代推荐系统、自动驾驶平台或本地生活服务应用时,工程团队常面临一个典型的数据割裂问题:语义理解与空间感知的存储分离。
以一个外卖配送场景为例:
在传统的架构中,这通常需要两套系统协同:
这种双库架构带来了显著的痛点:
通过在向量数据库内核层面集成空间几何计算能力,可以让查询引擎同时具备理解语义相似性与空间拓扑关系的能力,从而在一次检索路径中完成从粗筛到精排的全过程,消除以上所说的数据孤岛,实现单一系统内的混合高效检索。
在Milvus 2.6.4+ 中,引入了新的标量字段类型DataType.GEOMETRY。这是一个基于 OpenGIS Simple Features Access 标准的实现,支持以WKT (Well-Known Text)格式存储和查询地理空间数据。
该特性并不是简单的元数据过滤,而是引入了完整的几何对象模型,支持以下数据结构:
该特性赋予了 Milvus 处理复杂空间逻辑的能力,不再局限于简单的数值范围过滤。用户可以在search或query请求的filter表达式中使用专业的几何算子:
这意味着 Milvus 可以直接回答查找位于[多边形区域A]内,且与[查询向量V]语义最相似的 Top-K 个实体,这样的复杂查询
Milvus 对 Geometry 的支持没有停留在接口层,深入到了存储引擎与索引引擎的实现。
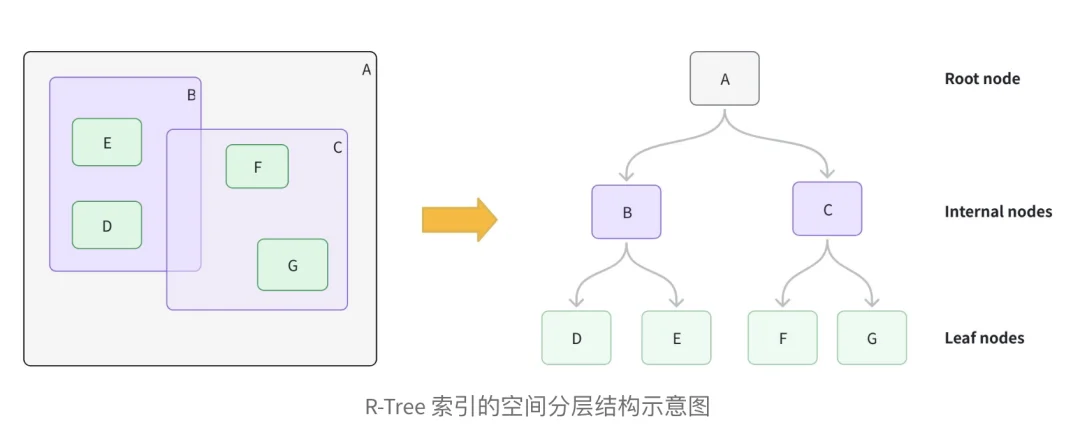
为了加速空间查询,Milvus 集成了R-Tree (Rectangle Tree)索引结构。R-Tree 是一种专门针对多维空间数据设计的平衡树结构,其核心思想是利用最小外包矩形 (MBR, Minimum Bounding Rectangle)对空间对象进行分层聚类。
在 Milvus 内部,R-Tree 的构建与查询流程如下:
索引构建 (Phase 1: Build):
两阶段过滤机制 (Two-Phase Filtering):
为了平衡性能与精度,Milvus 采用了粗筛+精筛的策略:
存储格式与编解码这里,值得一提的是,尽管用户通过 WKT (文本) 格式与系统交互,但在 Milvus 内部存储层,WKT 会被转换为WKB (Well-Known Binary)格式。WKB 是一种紧凑的二进制表示形式,能显著减少存储空间占用并提升 I/O 效率。对于内存映射(mmap)场景,Geometry字段同样支持,这对于大规模数据集的内存管理至关重要。
引入 R-Tree 索引后,空间过滤的性能不会再出现随数据量的线性增长而显著恶化的情况。
在没有 R-Tree 索引的情况下,执行ST_CONTAINS等操作会触发全表扫描(Brute Force Scan),系统必须逐行解析 WKB 并进行复杂的几何计算。随着数据量达到百万级或千万级,延迟将达到不可接受的程度。
启用 R-Tree 后,查询路径转变为树的遍历。理论性能模型显示:X轴为数据量级 [10K, 100K, 1M, 10M],Y轴为查询延迟 (ms)。”Full Scan” 曲线呈线性陡峭上升,而 “R-Tree Index” 曲线呈平缓的对数增长趋势,在百万级数据量下差距可达数个数量级。
由于采用了基于 GEOS 的精筛机制,Milvus 的几何查询保证了 100% 的几何计算准确性(Accuracy)。与某些为了速度而仅使用 MBR 近似计算的系统不同,Milvus 能够正确处理边缘情况,例如一个点位于 MBR 内部但位于实际多边形外部的情况,会被正确过滤。
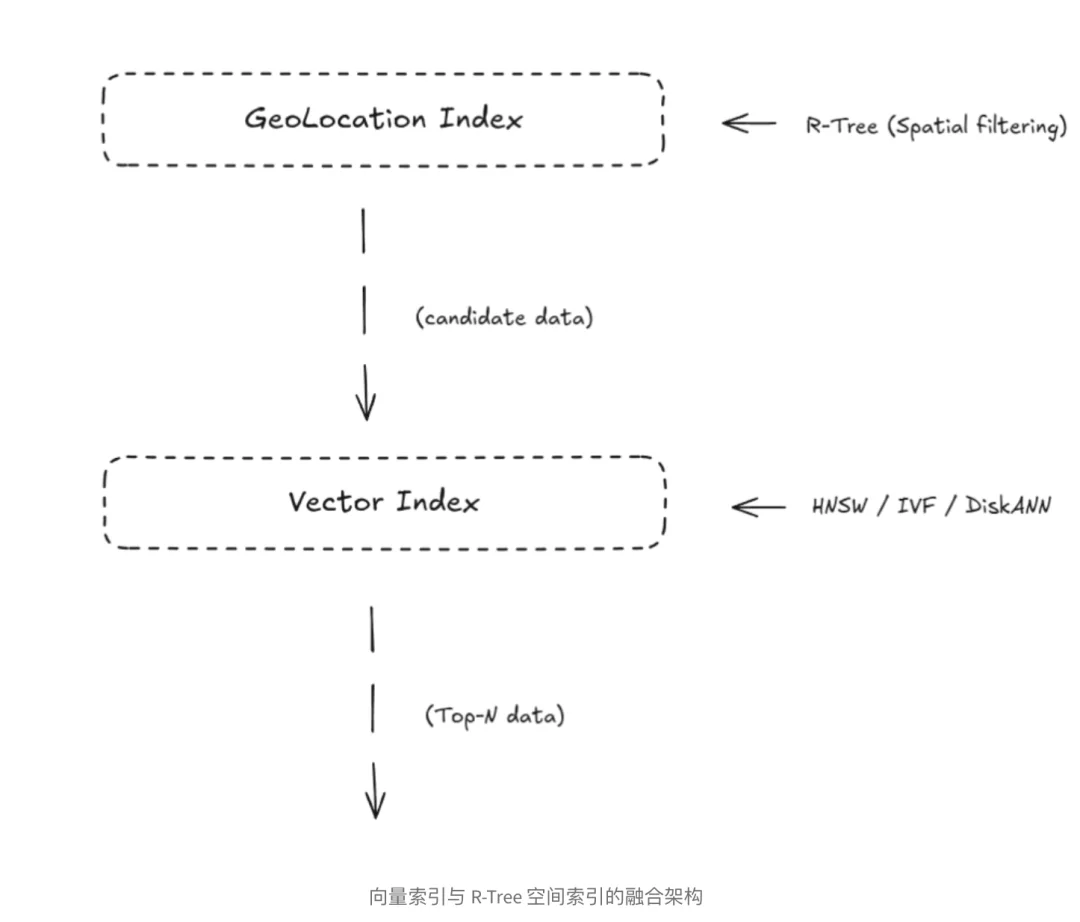
在 “Vector Search + Geometry Filter” 的混合场景中,R-Tree 充当了极其高效的前置过滤器(Pre-filter)。通过高效剪枝,参与向量距离计算(L2/IP/Cosine)的实体数量被大幅减少,从而显著提升了整体 QPS(每秒查询数)。
本节将通过 Python SDK (pymilvus) 演示如何在一个集合中启用 Geometry 特性,并执行混合检索。
首先,需要在 Schema 中显式定义DataType.GEOMETRY字段。
from pymilvus import MilvusClient, DataType
import numpy as np
# 连接 Milvus
milvus_client = MilvusClient("http://localhost:19530")
collection_name = "lb_service_demo"
dim = 128
# 1. 定义 Schema
schema = milvus_client.create_schema(enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=dim)
schema.add_field("location", DataType.GEOMETRY) # 定义几何字段
schema.add_field("poi_name", DataType.VARCHAR, max_length=128)
# 2. 创建索引参数
index_params = milvus_client.prepare_index_params()
# 为向量字段创建索引 (如 IVF_FLAT)
index_params.add_index(
field_name="vector",
index_type="IVF_FLAT",
metric_type="L2",
params={"nlist": 128}
)
# 为几何字段创建 R-Tree 索引 (关键步骤)
index_params.add_index(
field_name="location",
index_type="RTREE" # 指定索引类型为 RTREE
)
# 3. 创建集合
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
milvus_client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params, # 创建集合时即挂载索引
consistency_level="Strong"
)
print(f"Collection {collection_name} created with R-Tree index.")
数据插入时,几何字段需符合 WKT 字符串格式。
# 模拟数据:北京某区域的随机 POI
data = []
# 示例 WKT: POINT(经度 纬度)
geo_points = [
"POINT(116.4074 39.9042)", # 故宫附近
"POINT(116.4600 39.9140)", # 国贸附近
"POINT(116.3200 39.9900)", # 清华附近
]
for i, wkt in enumerate(geo_points):
vec = np.random.random(dim).tolist()
data.append({
"id": i,
"vector": vec,
"location": wkt,
"poi_name": f"POI_{i}"
})
res = milvus_client.insert(collection_name=collection_name, data=data)
print(f"Inserted {res['insert_count']} entities.")
场景:查找距离特定坐标(如用户位置)2公里以内,且向量特征最相似的 Top 3 POI。
使用ST_DWITHIN算子进行过滤。注意ST_DWITHIN的距离单位是米。
# 加载集合到内存
milvus_client.load_collection(collection_name)
# 用户位置 (WKT)
user_loc_wkt = "POINT(116.4070 39.9040)"
search_vec = np.random.random(dim).tolist()
# 构造过滤表达式:利用 ST_DWITHIN 进行半径 2000 米的过滤
filter_expr = f"ST_DWITHIN(location, '{user_loc_wkt}', 2000)"
# 执行搜索
search_res = milvus_client.search(
collection_name=collection_name,
data=[search_vec],
filter=filter_expr, # 注入几何过滤
limit=3,
output_fields=["poi_name", "location"]
)
print("Search Results:")
for hits in search_res:
for hit in hits:
print(f"ID: {hit['id']}, Score: {hit['distance']:.4f}, Name: {hit['entity']['poi_name']}")
显式创建索引:对于大规模数据(>10k entities),务必为 Geometry 字段创建RTREE索引。未建立索引时,所有几何过滤都会回退到全表扫描,严重影响性能。
未建立 R-Tree 索引时,几何过滤会回退到全表扫描,在大规模数据集上性能将严重下降。
坐标系一致性:Milvus 内部计算假设坐标系是平面的或标准的经纬度映射。在应用层应确保所有插入的 WKT 数据使用相同的坐标参考系(如 WGS84),以保证计算逻辑的正确性。
算子选择:
空值处理:如果在 Schema 中定义了nullable=True,在进行几何运算过滤时,值为 Null 的实体会被自动排除,无需额外的IS NOT NULL检查,除非逻辑需要显式处理。
为了在生产环境中使用上述特性,请确保基础设施满足以下要求:
Milvus 版本:必须为2.6.4或更高版本。早期版本不支持DataType.GEOMETRY及RTREE索引类型。
SDK 版本:
PyMilvus:需升级至最新版(推荐 2.6.x 系列),以支持 WKT 数据的序列化和 RTREE 索引参数的传递。
Java/Go/Node SDK:需检查对应语言 SDK 的 Release Note,确认已对齐 2.6.4 的 Proto 定义。
依赖库:Milvus 服务端镜像已内置Boost Geometry和GEOS库,用户无需在部署容器或宿主机上手动安装这些 C++ 依赖。
资源限制:R-Tree 索引会占用额外的内存空间。在规划内存容量(Capacity Planning)时,除了向量索引(如 HNSW/IVF),需预留几何索引的内存开销。Geometry 字段本身支持 Mmap,可在内存受限场景下通过磁盘映射缓解压力。

Alden,LLM应用工程师,聚焦生命科学行业解决方案
文章来自于“Zilliz”,作者 “Alden”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
