# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?
Microsoft最近一项名为《Terminus-4B: Can a Smaller Model Replace Frontier LLMs at Agentic Execution Tasks?》的研究给出的答案是:不一定。

他们提出了一个名为Execution Subagent的执行子Agent,并训练了一个基于Qwen3-4B的小模型 Terminus-4B。这个模型专门负责终端执行任务,最终能做到在不降低代码Agent解题成功率的前提下,Terminus-4B最多可以让主Agent的token使用量下降约30%,并且在一些指标上接近甚至超过Claude Sonnet、Claude Opus、GPT-5.3-Codex作为子Agent时的表现。这可能预示着未来Coding Agent会进入“专用小模型Sub Agent化”的阶段。
编程智能体在处理实际工作流时,不可避免地需要进行终端执行。这些操作包括:
尽管这些步骤必不可少,但它们给智能体带来了一个灾难性的后果:终端输出会迅速淹没智能体的上下文窗口。
目前的常规做法是采用“直接执行模式”,即主智能体在自己的上下文窗口中直接运行命令并吸收全部的输出结果。研究者指出,这种架构设计是非常原始且低效的。
实际上,主智能体从这些终端执行中需要获取的信息,通常只是一个关于发生了什么的简明摘要。例如,代表错误原因的一行代码,或者日志末尾的测试结果统计表,而不是整个Shell命令返回的完整原始输出。
为了清晰地展示这一问题,研究者提供了一个来自真实GitHub仓库(Serilog C# 仓库,Issue #2053)的对比案例。该任务要求智能体添加一个新的批处理API接口。由于这是一个全新功能,智能体必须构建解决方案、运行单元测试、识别失败原因并应用修复。
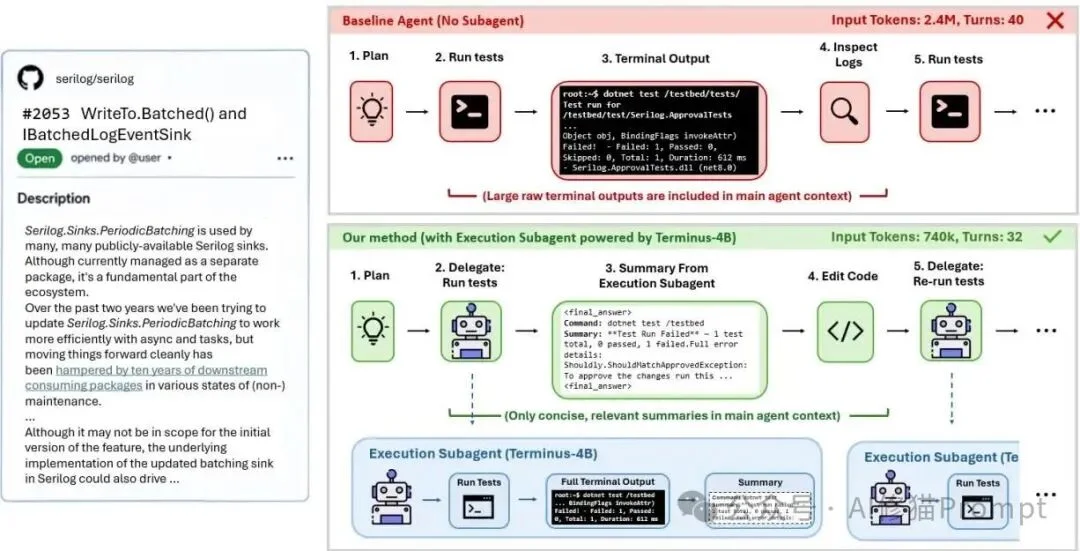
上半部分展示无子代理时主智能体被迫直接处理构建和测试日志;下半部分展示引入Execution Subagent后,原始终端输出被隔离在子代理上下文中,主智能体只接收压缩后的关键结论。
grep 和 tail 等命令过滤输出。论文提出的解决方案是:不要让主Agent直接处理终端原始输出,而是把终端任务交给一个专门的执行子Agent。
这个子Agent叫Execution Subagent。它不是一个通用代码Agent,而是一个极窄任务Agent,只做一件事:
根据主Agent的请求运行终端命令,并把结果压缩成结构化摘要返回。
它有两个输入参数:
它返回的结果必须放在 <final_answer> 标签里,并按命令逐条总结:
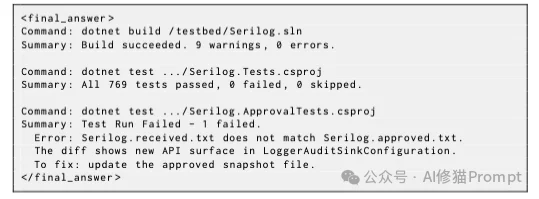
这种设计的关键点是:主Agent只看到压缩后的有效信息,不看到完整日志。
没有子Agent时,主Agent的路径中充满终端输出;使用Execution Subagent后,终端输出被隔离在子Agent上下文里,主Agent只接收摘要。
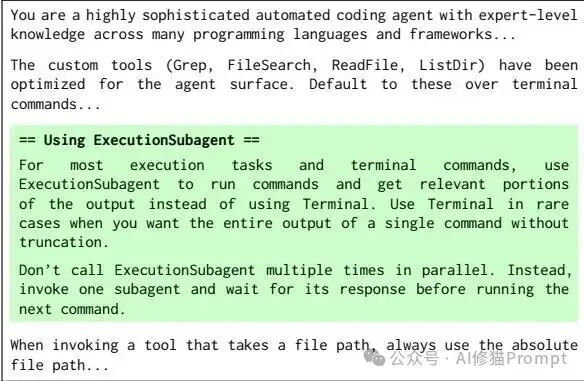
论文在主智能体提示词中显式加入绿色高亮的委托规则,要求主Agent把构建、测试、依赖安装和错误诊断等终端执行任务交给Execution Subagent。
Execution Subagent被刻意限制得很窄:

它不能读文件、不能改代码、不能搜索仓库,只能运行终端命令。Terminal工具接收:
命令输出会被截断到60KB。
论文明确限制它不能并行工具调用。这样做的好处是:
如果子Agent到达轮次上限还没主动结束,系统会插入一条消息,要求它输出 <final_answer>。
系统提示词要求它最终只输出 <final_answer>,里面包含每个命令和结果摘要。这个prompt的核心:使用同步模式、显式timeout、每轮一个命令、自动确认提示、最后输出结构化摘要。
这个设计说明作者不是单纯“让小模型跑终端”,而是通过工具权限、轮次限制、输出格式、系统prompt共同塑造一个稳定的执行型子Agent。
这篇论文最有价值的判断是:终端执行不是开放式智能任务,而是一个边界清晰、格式稳定、可训练的小任务。
主Agent要做的是复杂任务,比如:理解issue、定位代码结构、规划修复方案、权衡架构影响、判断补丁是否合理。
而Execution Subagent只做:
这类任务更像“工具执行+日志归纳”,不是完整的软件工程推理。因此,用Claude Opus或GPT-5.3-Codex来做这件事,在研究者看来是能力浪费。
论文的假设是:
如果任务足够窄,经过专门训练的小模型可以替代前沿大模型,承担Agent系统中的局部执行环节。
这也是Terminus-4B的定位:它不是要替代Claude Code式主Agent,而是要替代主Agent体系里的执行型子Agent模型。
为了替换子代理中的前沿大模型,研究者基于Qwen3-4B模型,专门针对代理终端执行任务进行了后训练(Post-Training),最终得到了Terminus-4B模型。训练分为两个关键阶段。
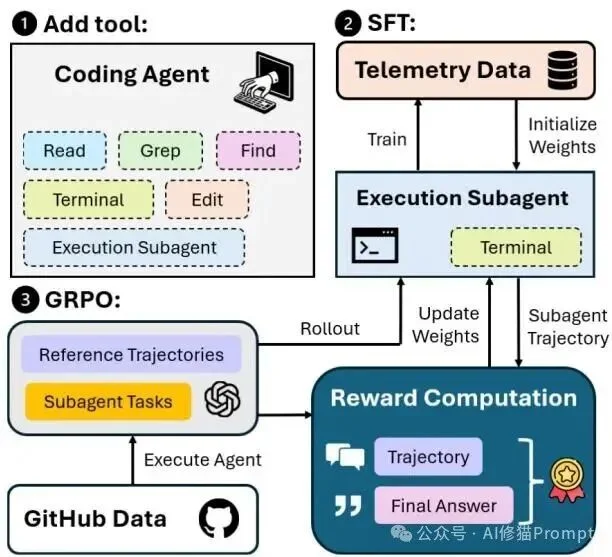
训练流程先把Execution Subagent接入主智能体框架,再用遥测专家轨迹进行SFT,最后通过GRPO强化学习和基于rubric的LLM裁判奖励进一步优化执行与摘要质量。
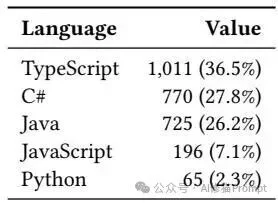

研究团队从GitHub上收集了约3200个真实的执行任务,跨越TypeScript、C#、Java、JavaScript和Python5种编程语言,涵盖730个代码仓库。任务类型主要集中在测试执行(97.3%)、错误诊断(78.3%)和项目构建(35.0%)。训练数据覆盖TypeScript、C#、Java、JavaScript和Python五种语言,其中TypeScript、C#和Java占比最高。 他们使用前沿LLM作为主智能体并在这些代码仓库中运行,捕获主智能体调用子代理时的完整上下文(包括系统提示、用户查询、终端输出轨迹以及最终的摘要答案),从而构建了“黄金标准”的参考轨迹(Reference Trajectories)。任务类型以测试执行、错误诊断和构建/编译为主,说明该子代理训练目标高度聚焦于终端执行与日志归纳场景。
团队首先在基础模型(Qwen3-4B-Instruct-2507)上使用内部遥测数据中的专家轨迹进行 SFT。
<final_answer> 格式编写最终摘要。公式表达如下:
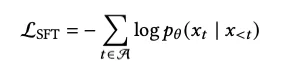

SFT只能让模型“形似”,为了让模型“神似”(即输出真正高度准确、具备可行细节的摘要),研究团队引入了使用组相对策略优化(GRPO)的在线策略强化学习。
由于智能体任务的特殊性,强化学习rollout(轨迹展开)需要完整的端到端环境执行。这里团队提出了两个极具价值的创新:
如果每次强化学习 rollout 都要启动庞大的主智能体(前沿 LLM),成本将极其高昂且难以控制一致性。团队巧妙地将主副代理解耦:
query 转发给执行子代理。这种方法彻底摆脱了对昂贵前沿LLM的依赖,实现了快速、廉价且起点高度一致的大规模并行 Rollout。


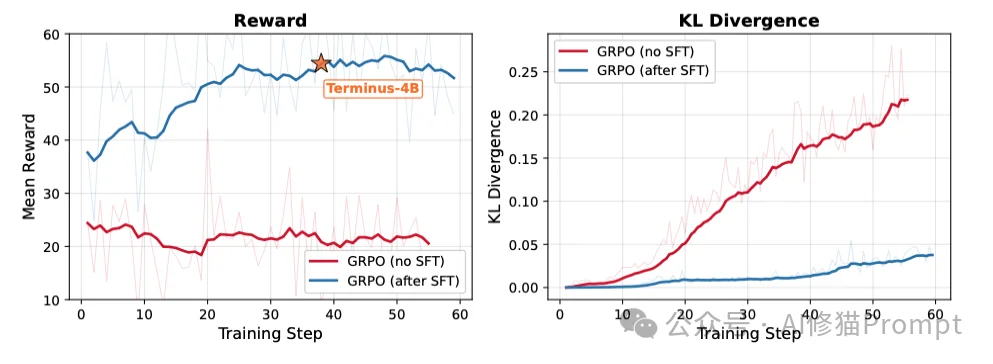
论文在后面的训练曲线中明确指出,如果不经过SFT直接做强化学习,模型的奖励得分会停滞在 ~20 分,且KL散度暴增;而基于SFT初始化的强化学习模型则能稳步攀升至 50+ 分以上,证明了两阶段训练缺一不可。
为了全面验证Terminus-4B的实力,研究者设置了严谨的离线评估实验。
研究者对比了五种不同的子代理配置:
为了验证跨模型兼容性,研究者在测试中分别搭配了三种不同能力级别的主智能体:GPT-5.3-Codex、Claude Sonnet 4.6以及Claude Opus 4.6。
研究者不仅关注任务是否解决,更深度关注智能体的内部行为模式转变。
各项实验结果一致表明,Terminus-4B在执行特定任务时,完全具备替换庞大前沿模型的能力。
在训练曲线的监控中,研究者观察到了SFT阶段的决定性作用。

在以Claude Opus 4.6为主智能体的SWE-Bench Pro测试中,Terminus-4B展现出了优异的多语言泛化能力。在跨语言SWE-Bench Pro中,Terminus-4B基本维持解决率,同时显著减少主智能体Token消耗和直接终端调用次数。
研究者进一步在C# 基准上,测试了Terminus-4B配合不同主智能体时的普适性。
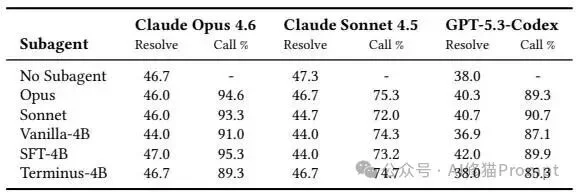
不同主模型下,Terminus-4B都能保持接近基线的解决率;能力更强的主模型通常更频繁地调用Execution Subagent。
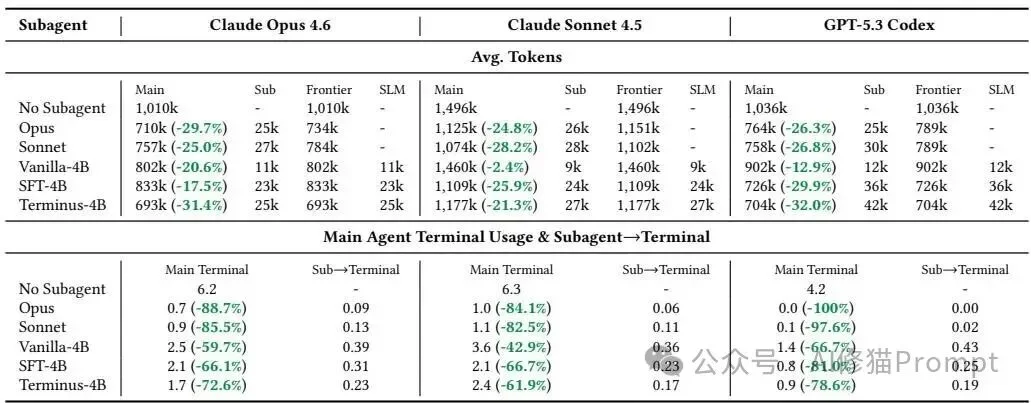
Terminus-4B在Opus和GPT-5.3-Codex主智能体下带来最大的前沿LLM Token下降,并持续压低主智能体直接调用终端的次数。
为了纯粹地比较不同子代理模型的质量,研究者进行了一项终极消融实验:直接没收主智能体的基础终端工具。这意味着主智能体如果想运行任何命令,唯一且必须的途径就是通过子代理。

当所有终端执行都必须经过子代理时,Terminus-4B的Subagent->Subagent重复调用率与Opus持平,显示其摘要质量已经足以让主智能体继续推进。
在这里,研究者引入了一个新的复读机指标:Subagent -> Subagent(即主智能体连续重复调用子代理的频率)。
除了客观指标,研究者还请来了大模型“评委(Claude Opus-4.6)”,让它站在主智能体的视角对子代理的输出文本进行评分。
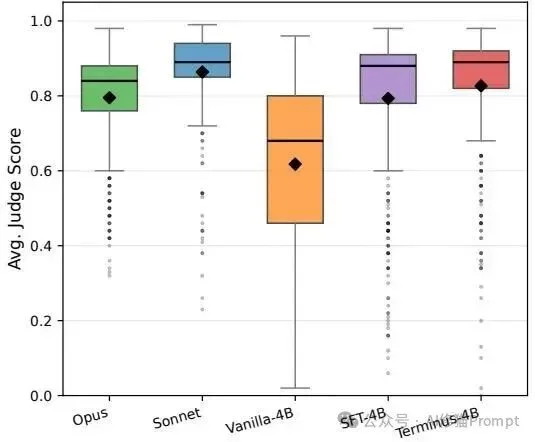
从主智能体视角出发,Terminus-4B的回答质量评分已经接近Sonnet,并略优于Opus,这与其较低的重复调用率相互印证。
尽管研究结果极具说服力,研究者也客观地指出了当前工作面临的三个主要局限性:
通过这篇深度论文,我们见证了一种实用且高效的新型AI工程架构设计思想。《Terminus-4B》向我们明确展示了:通过两阶段后训练流水线,即使是参数量只有4B的小语言模型,在高度受限的特定细分任务(如终端执行和日志归纳)上,也能够匹敌甚至超越那些极其昂贵的前沿语言模型。这项工作更深远的意义在于:它证实了将复杂任务解耦为更小的子任务,并分配给不同能力级别的专业化模型来协同处理,是一条极具性价比和扩展性的道路。未来,随着更多种类的子代理被开发出来,我们必将迎来计算成本更低、解决能力更加卓越的下一代编程智能体生态。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
