# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
用过推理型大模型的人,大概率都熟悉这种体验:模型似乎在认真思考,但屏幕上长时间没有真正有用的内容;如果让它一开始就输出,又很容易出现仓促判断,后面的推理还要被早期错误牵着走。
这正是论文 When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning 试图解决的问题。作者把这种矛盾称为单流自回归接口下的 “silence tax”(沉默税):在传统单一可见流里,每个生成 token 既更新模型状态,又构成不可撤回的公开承诺。模型多想一会儿,用户就多等一会儿;模型早说一点,又可能过早承诺。
为此,来自纽约州立大学石溪分校、浙江大学、威廉玛丽学院、伊利诺伊大学香槟分校、英属哥伦比亚大学、香港中文大学、以及复旦大学的研究人员提出 Side-by-Side(SxS)Interleaved Reasoning(并列式交错推理),把 “何时披露内容” 变成一个可学习的决策。模型可以在同一个自回归上下文里交替执行两类动作:继续思考,或披露已经被当前推理支持的答案片段。这样一来,流式生成不再只是前端展示策略,而变成了模型自身学到的 “披露策略”。

SxS Interleaved Reasoning 让大模型在推理过程中学会 “边想边说”:只有当答案片段已经被当前推理前缀支持时,才把它作为用户可见内容披露出来;其余推理继续保留在同一上下文中,帮助模型完成后续推理。
这不是简单地让模型更快输出第一个 token,也不是鼓励它用 “我正在思考” 之类的空话填充等待时间。论文关注的是内容延迟,也就是用户什么时候能看到真正和任务相关、且有依据的内容。
当前大模型的流式交互通常默认一个设计:模型生成什么,用户就立即看到什么。这种设计简单、稳定,也方便部署,但它把两个原本不同的问题绑在了一起。
在简单问答里,这个耦合问题不明显;但在数学、科学问答、代码推理等任务里,模型往往需要较长的中间推理。若先完整思考再回答,用户会经历长时间沉默;若一开始就把中间想法或候选答案显示出来,错误前缀又可能造成 “过早承诺”。
论文的关键判断是:真正值得优化的不是 Time to First Token, TTFT(首 token 延迟)这种系统层面的指标,而是 “第一个有用内容何时出现,以及两次有用更新之间间隔多久”。这也是 SxS 后续评测里使用 ARI、ABO、AIRW 等内容延迟指标的原因。
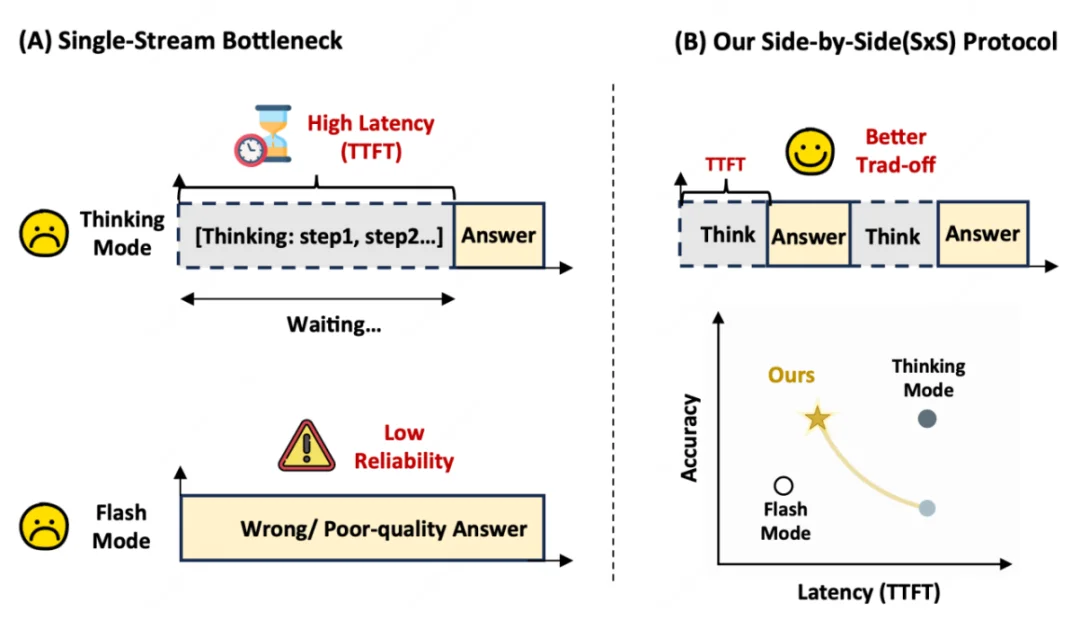
SxS 的设计很直接:模型仍然是标准自回归生成,不需要第二个模型、第二套隐藏状态或专门的推理架构;不同之处在于,它在生成流里通过轻量标签区分两类 token。
可以把它理解成一种 “可控可见性” 的单流生成。所有内容仍在同一上下文里,因此模型不会丢失前面推理;但用户看到的,只是模型选择披露的答案流。
这带来的变化很重要:模型不必在 “沉默到最后” 和 “马上冒险回答” 之间二选一。它可以先披露一个已经被当前推理支持的答案前缀或部分答案,再继续推理剩余部分,随后逐步补全最终回答。
论文的训练分成两个阶段,核心目标是避免一个常见副作用:如果只奖励早输出,模型可能学会说废话;如果只学交错格式,模型准确率又可能下滑。
这套流程的一个实用点是:它没有把 “早输出” 写成硬规则,而是把 “有依据地早披露” 作为监督和优化目标。换句话说,早不是目的,早且可支持才是目的。
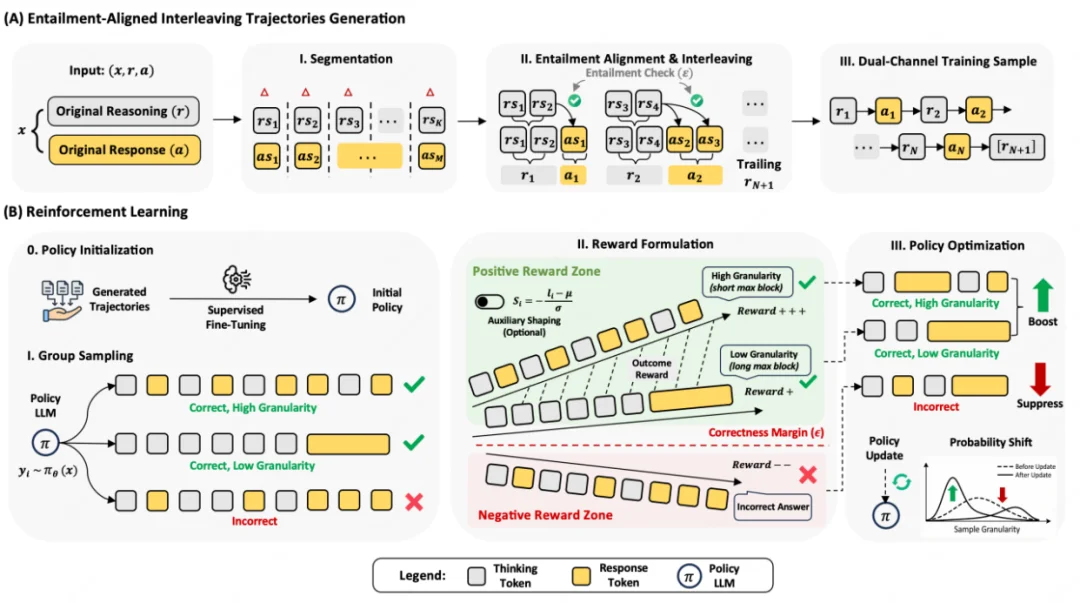
论文在两类 Qwen3 模型上验证方法:MoE 架构 Qwen3-30B-A3B,以及 dense 架构 Qwen3-4B。主实验覆盖数学推理 AIME25 和跨域科学问答 GPQA-Diamond。除最终准确率外,作者还报告了 Average Inter-Response Wait, AIRW(平均响应间等待),即两次 speak(披露) 更新之间平均隔了多少 think(思考) token。
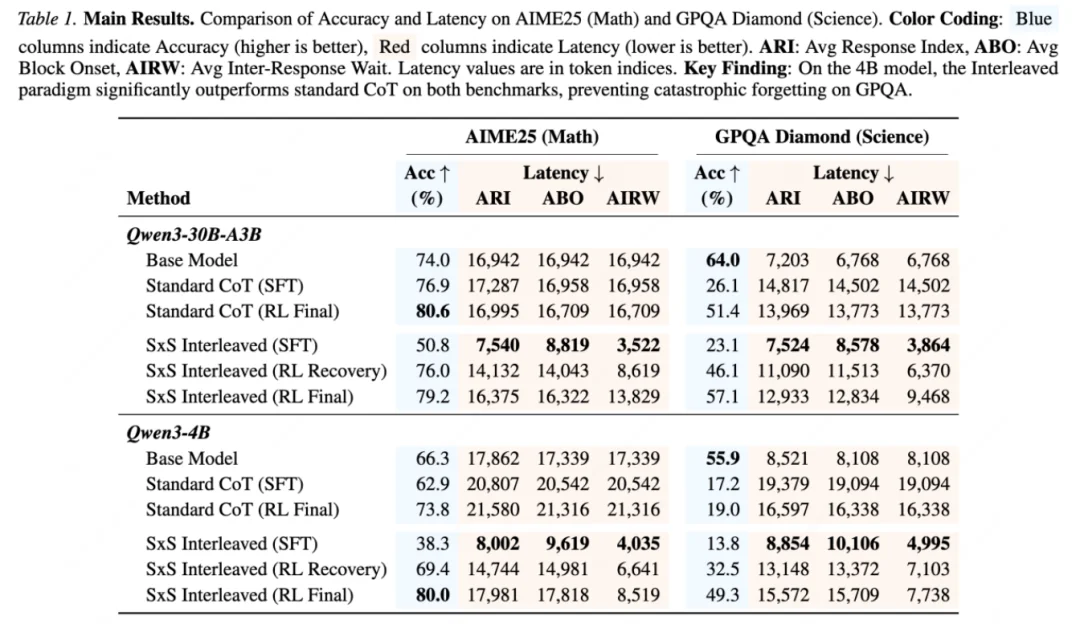
注:表中 AIRW 为 token-level 内容延迟代理指标,越低表示两次用户可见更新之间的平均间隔越短。
最值得注意的是 Qwen3-4B:在 AIME25 上,Qwen3-4B 的 SxS RL Final 达到 80.0%,高于 Standard CoT RL Final 的 73.8%;AIRW 也从 21,316 降到 8,519。在 GPQA-Diamond 上,SxS RL Final 达到 49.3%,高于 Standard CoT RL Final 的 19.0%;AIRW 从 16,338 降到 7,738。
这说明 SxS 的收益不是单纯 “把答案提前挪到前面”,而是改变了推理过程中的披露节奏:用户能更早、更频繁地看到有任务意义的内容,同时最终答案质量并没有被牺牲。
论文还在 LiveCodeBench 和 KOR-Bench 上做了额外分析。总体趋势和主实验一致:SxS 不一定在所有设置里追求最高原始准确率,但通常能给出更好的后训练行为,尤其是在小模型上。
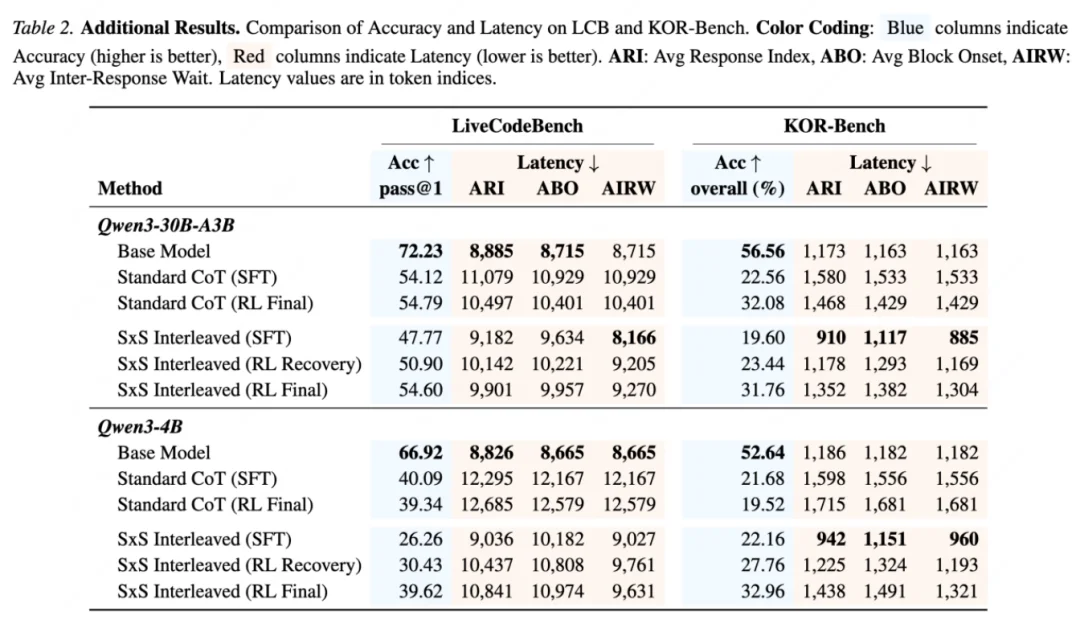
这篇工作的有趣之处,不只是提出了一个新格式,而是把 “流式回答” 从工程显示问题推进到了模型学习问题。过去我们通常把交互体验交给前端、系统吞吐或固定模板;SxS 则指出,模型本身可以学习何时披露,且披露必须受到当前推理的支持。
这项工作也不是在声称解决了所有流式推理问题。首先,论文里的延迟指标是 token-level proxy(token 级代理指标),并不等同于真实系统的 wall-clock latency(真实时钟延迟);真实产品还会受到推理框架、批处理、网络、前端刷新等因素影响。
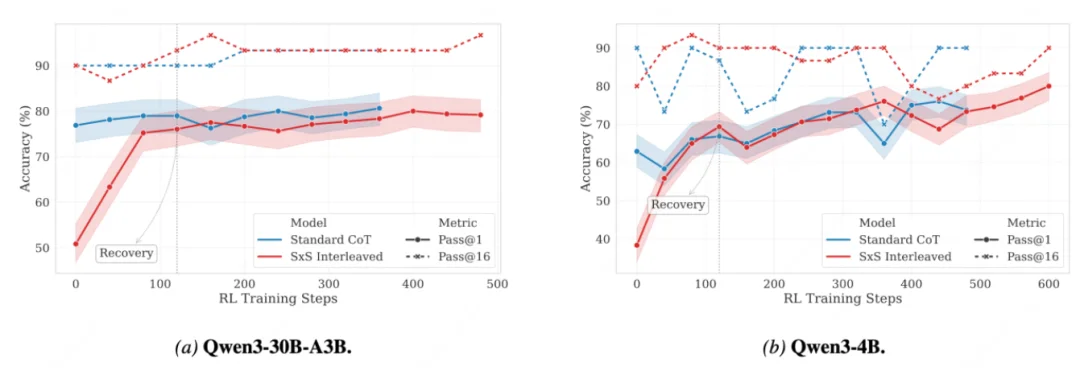
其次,SFT-only 的交错模型会出现明显准确率下降,说明 “学会交错格式” 不等于 “保持强推理”。论文用 RL Recovery / RL Final 修复这一点,也意味着这个方法的关键成本在后续强化学习阶段。
最后,SxS 的披露粒度虽然可以通过奖励塑形进一步控制,但更高粒度会带来训练效率成本。也就是说,披露越频繁不一定越好,真正目标仍然是准确率和内容延迟之间的 Pareto trade-off(帕累托权衡)。
随着推理型大模型越来越多进入真实交互场景,用户关心的不只是最终答案对不对,还包括等待过程中能不能看到可靠进展。SxS Interleaved Reasoning 给出的答案是:不要简单地让模型更早吐字,而是让模型学习 “何时可以披露已经被支持的内容”。
从这个角度看,这篇论文把大模型推理交互中的一个常见体验问题,转化成了可监督、可强化学习优化的披露策略问题。它让 “边想边说” 不再只是产品话术,而成为可以训练、可以评测、可以和准确率一起优化的模型行为。
文章来自于"机器之心",作者 "机器之心"。



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
