# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
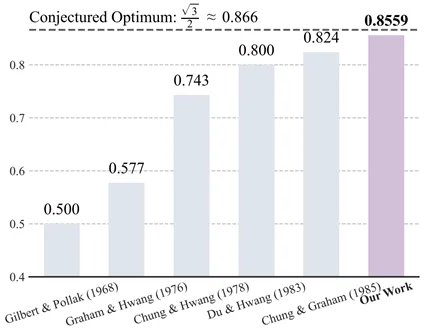
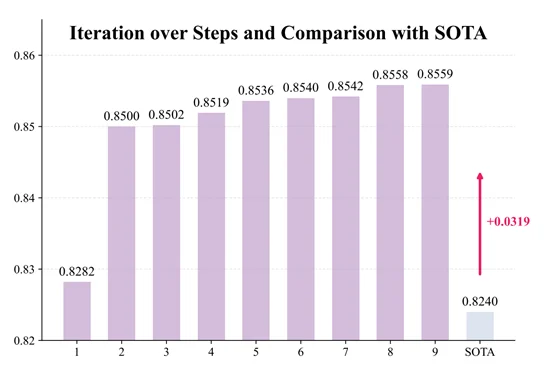
近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?在本工作中,北大王立威教授团队构建了一套基于 LLM 的框架,聚焦 Gilbert-Pollak 猜想(斯坦纳比猜想),成功将二维平面的斯坦纳比从 1985 年证明的 0.824 改进到了 0.8559,距离猜想目标仅差 0.01,一步之遥!
该进展已被陶哲轩 Terence Tao 收录组合数学优化中的常数列表中!问题编号 43。
这个问题有多大影响力?在上个世纪,该问题由贝尔实验室科学家 Gilbert 和 Pollak 提出。著名数学家、美国数学学会(AMS)前主席 Ronald Graham(葛立恒)、美国国家科学院院士 Fan Chung(金芳蓉)都对该问题进行过系统深入的研究。1990 年,堵丁柱教授和 Frank Hwang(黄光明)研究员进行了一系列相关研究,曾被誉为 1989 年 - 1990 年度美国离散数学界和理论计算机科学界重大成果。围绕该问题的研究论文众多,是一个饱受数学家关注的猜想。
目前该工作已被 ICML 2026 接收,相关代码和数学证明均已开源。


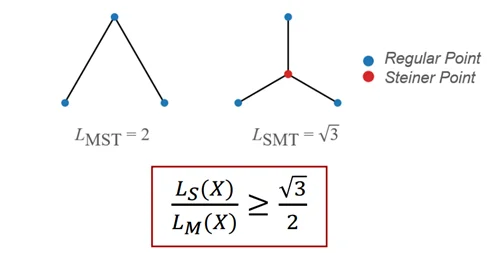
形象点说:给定平面上 n 个城市,最小生成树(MST)就是修建 n - 1 条铁路将它们连起来。最小斯坦纳树(SMT)就是可以额外修建若干个中转站,再修建铁路将它们连起来。可以看出,合适地建立中转站会让路程变短,但猜想指出:并不会短太多。

之前一系列 AI4Math 的工作,要么是数学证明的长度较短(如 IMO 问题),要么是针对构造性的、非严谨证明性的组合构造问题。
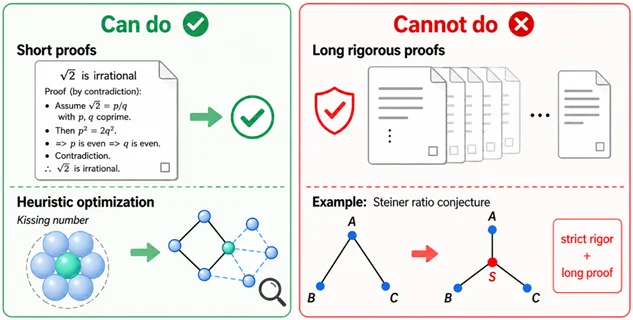
让 LLM 直接去写几十页的严谨数学证明,还要有创新性,对于目前 LLM 能力来说为时过早。为了解决斯坦纳比猜想,必须减少证明长度,或者向构造性的方向转换。
回顾人类数学家的工作,发现大家都是采取了归纳法:对于一棵很大的斯坦纳树,只去考虑一个局部,从中摘除(prune)掉一小部分的点,并将剩下的点重连成斯坦纳树。
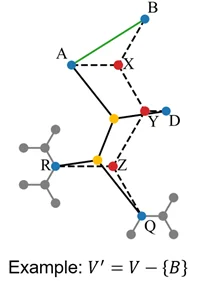
那么,只要剩下的部分满足比例(归纳假设)+ 摘除过程的变化量满足比例,就可以合并得到原问题满足比例!写成一行公式就是:
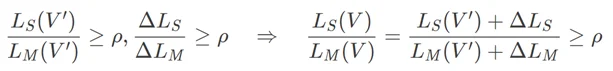
从而,问题的关键就是找到更好的摘除 / 分割树的方式。
本工作中提出了一个叫做验证函数(verification functions)的数学工具,一个验证函数就代表了一种分割树的方式。归纳法就是要求:任意的树形态,存在一种分割,使得比例成立。其实这就是一个 max-min 问题:最大的树形态 w ——最小的验证函数 F。
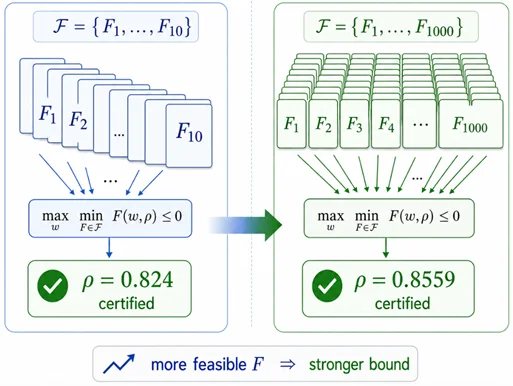
人类数学家尝试了 10 种不同的 F,可以得到 0.824 的下界。如果 LLM 能帮助人类尝试 1000 种不同的 F,就有机会得到更好的下界!
本工作设计了一个 Reward Model,自动化了这一 max-min 问题的求解过程,通过证明单调性,并配合分治法,为所有树形态 w 找到一个验证函数 F 进行覆盖。以前人类数学家需要手动进行启发式的参数空间划分,现在一个代码自动搞定。下图是假设参数空间是 2 维的一个例子:
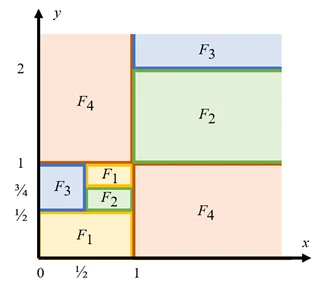
至此,LLM 不再需要证明完整的猜想,它只需要找到更多的验证函数 F,再与 reward model 交互就可以了!
想要生成 1000+ 个 F,只需要反复调用 LLM 即可。但基于自然语言推理的 LLM,你能相信它的严谨性吗?如果让人类一个一个检查,时间开销不可估量,难以 scale up。
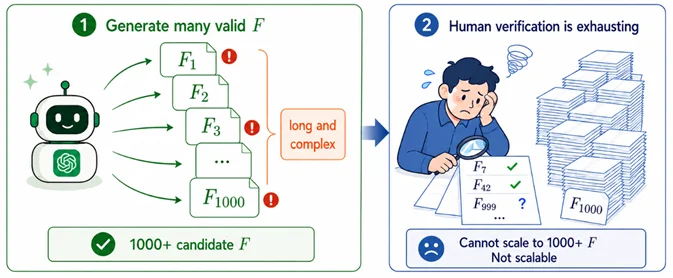
因此,我们必须让 LLM 在正确性可验证的框架中运行。
本工作通过数学变换,证明了一个事实:找更多的 F 函数,可以通过找两类引理的方式实现:一类是 Trapped Regular Point Lemma,另一类是 4-Point Steiner Tree Lemma。
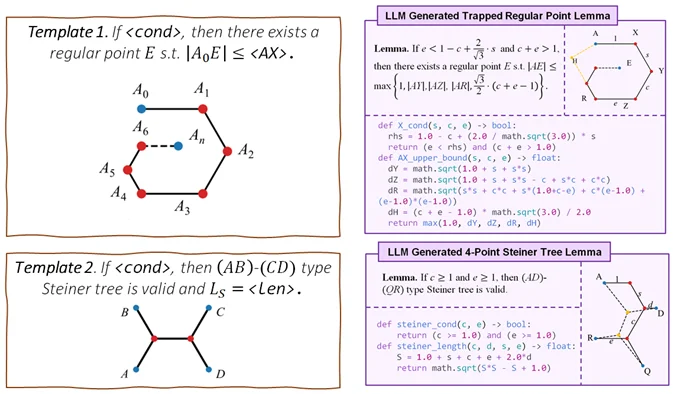
LLM 只需要负责填入结构化的参数,通过代码片段进行表达,系统就可以通过翻译(嵌入代码片段)的方式产生一系列合法的 F。以第 1 类为例,这个翻译过程可以是构造分段函数:
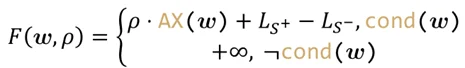
生成结构化的代码片段仍然可能会出错。必须要让 LLM 像「搭积木」一样,拼凑人类提供的规则(rules),让数学软件 Mathematica「合成」保对的引理,才能从根本上保证正确性。
以第 1 类引理为例,本工作提出了 A、B 两类规则,分别代表斯坦纳树必须满足的性质,和确保点存在性的条件。LLM 要做的,就是去选择 2 - 3 个规则,调用 Mathematica 去化简「什么条件下,若干个 A 能推出一个 B」。
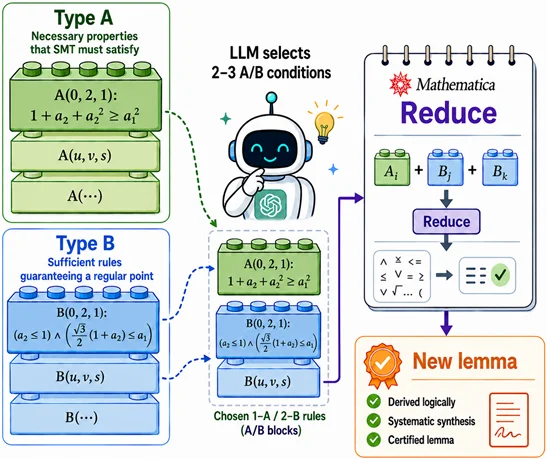
通过这种方法,LLM 能在多轮的 tools 调用中,充分探索这个推理空间。而且这是保对的——任何的创意搭建,都不会产生逻辑的错误。
目前为止,系统看似很完美,实则还有一个隐藏的大问题:只是重复运行,生成 1000+ 个 F,很可能其中很多是平凡的甚至重复的,根本对斯坦纳比没有提升!
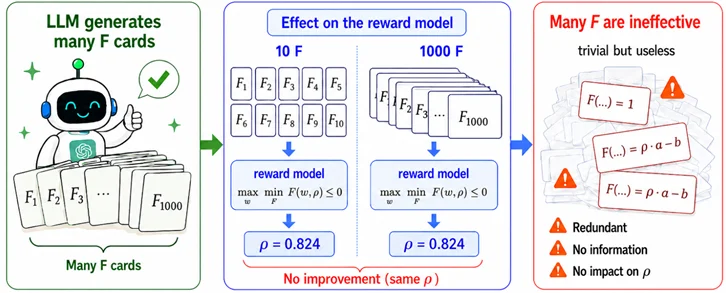
如何让 LLM 真正生成有效的 F?必须给它针对性的迭代引导信号。
本工作提出了瓶颈(bottleneck)的概念:在 reward model 运行完成后,把得到的提升一个小量 δ(比如 0.0001),再让 reward model 运行——此时必然反馈失败,未被 F 覆盖的部分的 bounding box,就是瓶颈区域。
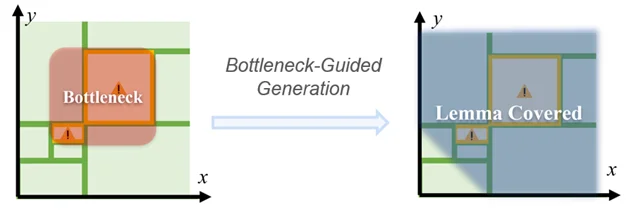
换言之,瓶颈就是让 ρ += δ 必须克服的参数区域。在下一轮生成 F 时,LLM 必须确保能够覆盖瓶颈区域。从而为每一轮的高效提升提供了保障。
通过「重复生成 Reward → 确定瓶颈 → LLM Agent 提出引理 → 翻译并开始下一轮」这个迭代范式,系统成功在 ~10 轮迭代中,将斯坦纳比改进到了 0.8559。最终的成果通过了人类的检查。

本文基于 GPT-5 系列构建了系统,并验证了模型鲁棒性:其余模型如 Gemini 3 和 Claude 4.6 均可得到类似的结果。下图展示了迭代轮次和斯坦纳比的关系。
本工作证明了 LLM 有能力为研究级数学提供帮助,但要设计合适的运作框架。
在这个过程中,人类的 insight 仍然是必要的。同时,人类检查也是必不可少的部分。
如果要用 LLM 去处理其他数学问题,可以参考的内容包括,设计一个「搭积木」式的结构化推理空间,以及设计瓶颈反省机制。
文章来自于"机器之心",作者 "柯绎思、疏彦凯、黄天域"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
