# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

专为 AI 构建搜索引擎的基础设施公司 Exa 宣布完成 2.5 亿美元 C 轮融资,投后估值达到 22 亿美元,由 a16z 领投,a16z 合伙人 Sarah Wang 主导了本轮交易。
此前,Exa 在 2024 年 7 月和 2025 年 9 月分别完成了 2,200 万美元 A 轮和 8,500 万美元 B 轮,B 轮由 Benchmark 合伙人 Peter Fenton 领投并加入董事会,估值 7 亿美元。不到一年,估值翻了三倍。
新一轮资金将用于把索引范围扩展到开放网页之外,训练下一代检索模型,以及将基础设施扩容到每秒处理数十万次搜索请求。与此同时,Exa 也在积极扩张市场团队。联合创始人 Jeffrey Wang 在接受 DeepTech 采访时表示,“关于这些资金的规划用途其实非常简单,技术和市场两边都需要继续提速。”
Exa 目前服务超过 5,000 家企业客户和 40 万开发者,客户名单里有 Cursor、HubSpot、OpenRouter、Gamma、Lovable 等公司。据 Exa 披露,其客户查询量从 2025 年 4 月的约 1 亿次增长到 2026 年 4 月的约 10 亿次,一年翻了十倍。它的爬虫追踪着超过 5,000 亿个 URL,背后是自建的索引系统、自训练的 embedding 模型、自研的向量数据库,以及一个由 H200 GPU 组成的自有训练集群。
这些数字背后的故事开始于 2021 年。那时候 ChatGPT 还没出现,“AI 需要搜索引擎”这个判断甚至显得有些超前。
Jeffrey Wang 本科毕业于哈佛大学,毕业后在金融科技公司 Plaid 工作了三年,负责数据与网络基础设施。2021 年,他和大学室友 Will Bryk 联合创办了 Exa(当时叫 Metaphor),Bryk 担任 CEO。两人当时的信念很大胆:世界需要一个比谷歌更好的搜索引擎,而他们能做到。

图丨Will Bryk 和 Jeffrey Wang(来源:Exa)
在创业早期,他们就下重注,花 5百万美元买了一个 GPU 集群,以便快速构建大规模索引系统,尝试了多种新型搜索技术。目标是开发一个让用户能以谷歌做不到的方式搜索网络的引擎。比如,“给我找出所有在纽约、拥有博客的机器学习工程师,按经验年限排序。”
2022 年 11 月,Exa 推出了第一款搜索引擎产品。两周后,ChatGPT 上线。
很快,需求涌了过来。大量公司开始研发 AI 应用,而这些应用需要从网上获取信息。Wang 和 Bryk 意识到了两件事:AI 也需要搜索,而且 AI 的搜索频率很快就会远超人类。
谷歌搜索被设计出来服务人类用户,人类想要的是十个蓝色链接。AI 想要的完全不同:它需要的是高质量的完整页面内容,而不是 SEO 内容或广告;它对延迟极其敏感,因为在单个请求中搜索往往只是多个工具调用之一;它要求零数据保留,因为企业客户的查询往往高度敏感。
Wang 告诉我们,Exa 产品的底层是同一个引擎:自己的爬虫,自己的索引,自己的 embedding 模型,自己的向量数据库。网站上每个产品只是用不同方式向这个引擎提问。
搜索 API 是最原始的接口,按照延迟和质量的不同,分为几个层级。Exa Instant 响应时间低于 200 毫秒,为实时对话、语音助手和编程 agent 而生,Wang 称之为“全球最快的搜索 API”。Exa Auto 大约 1 秒,是默认模式,提供最好的单次查询质量。
Exa Deep 和 Deep Max 则是 agentic search,系统自主推理、并行展开多个子查询、汇总结果,Deep Max 在 Google DeepMind 的 DeepSearchQA 基准测试和 FRAMES 等评测中拿到了 SOTA。

图丨Deep Max 在 Google DeepMind 的 DeepSearchQA 基准测试达到 SOTA(来源:Exa)
在 API 之上还有两个产品。Highlights 是 Exa 的文本提取模型,能从页面中抽取最相关的段落。Wang 提到一个数据:在 SimpleQA 评测上,500 个字符的 Highlights 输出匹配了 8,000 个字符完整页面的准确度,token 消耗降低了约 20 倍。
Websets 则是异步、大规模的产品,用户给出自然语言描述和验证条件,比如“美国做农业科技的 A 轮公司”,系统会自行搜索、逐一验证、丰富数据。企业 GTM 和运营团队是 Websets 的重度用户。
Jeff Wang 把这概括为“一条从 200 毫秒到数分钟的曲线”,认为用同一套引擎覆盖“快”和“准确”的两端是 Exa 的关键差异。同样的索引、模型和向量数据库,通过调整计算预算和路由,一端做到 200 毫秒以下,另一端做到分钟级的 agentic 搜索。“只有自己造引擎才能做到这一点,套壳产品是做不到的。”
Exa 最近发布的一项研究佐证了 Wang 的判断。他们发现,用 Exa 而非 Google 作为搜索后端来训练 RL 搜索 agent,agent 学得更快、最终表现更好。具体数字是:训练同样的 pass@k 水平,用 Exa 比用传统搜索引擎结果页(SERP)基线节省了 69% 的 token 消耗,搜索调用次数减少 62%,交互轮数减少 58%。
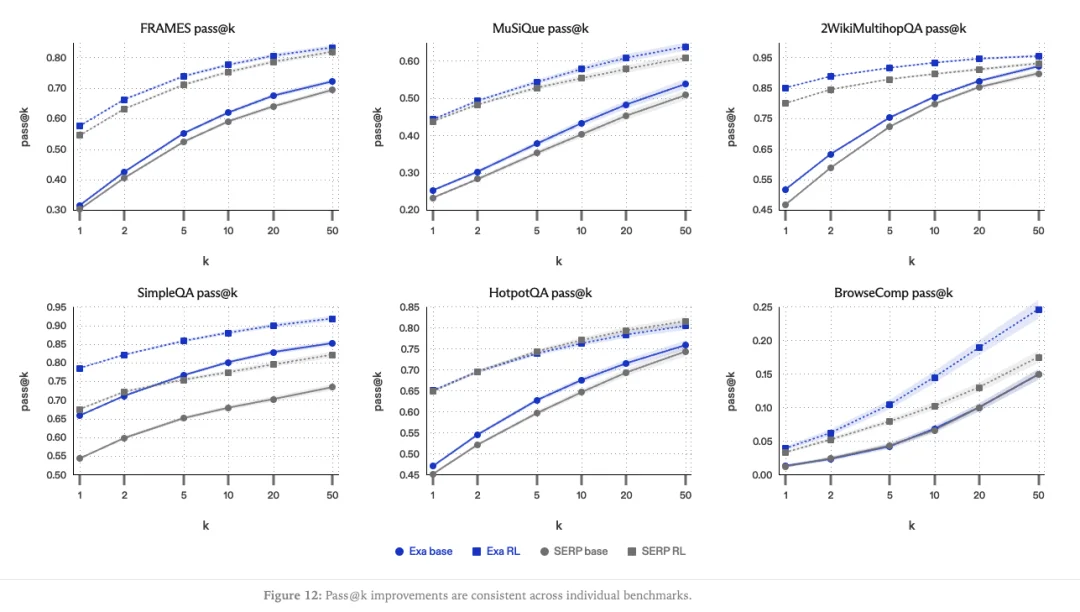
图丨Pass@k 的提升在各个独立基准测试中保持一致(来源:Exa)
Wang 认为这个结果虽然事后看很符合直觉,但其意义重大:“搜索不仅仅是推理时的工具,它也是训练时的基底(substrate),这个区分值真金白银。”RL 训练是当下 AI 领域最耗 token 的工作负载之一,60% 到 70% 的削减意味着完全不同的训练账单。而且用 Exa 训练出来的 agent 在推理时也更高效,每个查询使用更少的 token、更少的轮数和更少的搜索调用。
随着越来越多的实验室开始构建搜索 agent,Wang 预判它们会需要一个专为此目的打造的训练环境,“而不是套壳一个本来为人类点击蓝色链接而优化的消费级搜索引擎。”
这一判断指向了 Exa 反复强调的核心护城河:自建 vs.套壳(wrapper)。Wang 向我们解释,大多数搜索 API 提供商在底层封装的是谷歌搜索。“这是行业里一个鲜为人知的秘密。”当查询到达这些服务商时,会被路由到某个匿名服务器上的浏览器,在谷歌搜索中执行查询,再把结果返回。这意味着至少 700 毫秒的中位延迟,意味着无法真正实现零数据保留(因为谷歌搜索本身会记录查询),也意味着无法为特定用例深度定制。
“六个月前我们的代码搜索还不如谷歌,”Wang 说,“现在我们训练了代码专用模型之后,几乎所有编程 agent 都在用我们。这件事如果你只是谷歌上面的一层套壳,根本做不到。”
Wang 还提到一个更现实的威胁:谷歌不会永远允许自己 90% 的流量来自机器人。一旦谷歌收紧政策,所有依赖它的套壳产品都会同时失去根基。
Exa 去年在旧金山竖过一块广告牌,上面写着“10^18>10^100”(10^18 对应国际单位制前缀 exa,10^100 是数学术语 googol,即 Google 名字的由来),意思不言自明。Wang 说他们仍然认同广告牌传达的观点:为 AI 构建的搜索和为人类构建的搜索是不同的产品,这个差异很重要。

图丨Exa 去年火出圈的广告牌(来源:Reddit)
但 Google Cloud 和 Gemini 是另一回事。几周前的 Google Next 大会上,Exa 成为 Gemini Enterprise 新推出的 Agent Marketplace 的首批合作伙伴。Vertex AI 上线了“Grounding with Exa”功能,Gemini 企业客户可以直接用 Exa 做搜索落地,从 Google commit 中直接调用。Exa 的 Highlights 模型为 Gemini 提供高密度、高相关性的上下文,在新闻、产品数据、技术文档等时效性敏感的场景里尤其关键。
“竞争者 or 合作伙伴的二元框架并不是理解这件事的正确方式”Wang 说,“Google Cloud 有庞大的企业客户群,他们在构建 agent,而 agent 需要高质量的实时网页信息。我们很乐意服务这些客户。”
赛道上其他玩家的动态也在印证这个领域受到的关注正在日益提高。Tavily 在 2026 年 2 月被云计算公司 Nebius 收购,Parallel AI 拿到了 1 亿美元 A 轮融资。
两年前,“为 AI 做搜索”还只是别人产品里的一个功能。如今它被资本市场确认为独立的基础设施层。Wang 对这个赛道未来一到两年的判断是:自建引擎和套壳谷歌之间的差距会变得非常明显。“随着 agent 做越来越重要的工作,它们对质量、延迟、时效性和定制化的要求只会不断提高,而只有拥有全栈技术的产品才能满足。”
Exa 的团队也在快速变化。最近加入的人包括 Meta 检索基础设施负责人、Yandex 搜索后端负责人,以及一支来自 Google Search 苏黎世团队的研究组。“人们来这里,是因为这里正在真正建造搜索引擎,”Wang 说。
Exa 已在新加坡开设了亚洲办公室,并在快速扩张。Wang 提到 Exa 的亚洲客户已经涵盖日本大型商社、千亿美元级金融机构、科技巨头、云和推理服务商、风险投资机构,以及一大批“Global First”的 agent 创业公司。
截至目前,Exa 累计融资约 3.6 亿美元,团队规模过百人。Wang 在采访中重复了他经常说的一句话:全世界真正独立的搜索引擎数量比能发射火箭的公司还少。造搜索引擎极其困难,但也极其必要。
当数万亿 agent 在未来几年陆续上线,搜索需求将增长到谷歌今天总搜索量的千倍以上。而当 agent 开始为人类做出越来越重要的商业决策,它们对全面性、时效性和精确性的要求会远远超出人类自身的标准。如何来为这些 agent 提供可信赖的信息基础设施,仍是一个开放的问题。Exa 押注的答案是:从第一性出发,一切从零重造。
“信息是我们这个 AI 时代的文明基座。政治在分裂,战争在蔓延,AI 在加速——我们需要值得信赖的工具,来告诉我们这个世界究竟在发生什么。完美的搜索,让每个 AI 都能获取最高质量的信息,进而让每个人也能。”
参考资料:
1.https://exa.ai/blog/webcode
2.https://exa.ai/blog/deep-max
3.https://exa.ai/blog/composing-a-search-engine
4.https://exa.ai/blog/rl-search-outcomes
文章来自于"DeepTech深科技",作者 "加洋"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
