# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在 AI 工具越来越多,但不少人(包括已经习惯使用 AI 的老用户)对屏幕背后到底发生了什么,多半不太了解。
一次最普通的对话。你打开 DeepSeek,输入:
你好。
按下回车,对面回了一句:
你好,有什么可以帮你?
这是像微信和 QQ 一样的真实对话吗?
其实发到模型那边的不是"你好"两个字,而是一段结构化的内容,包括系统规则、之前所有的用户发言和 AI 回复,以及你这一句新问题。模型把所有内容都当作新内容读取后,写出一段回复。再由网页程序把这段回复包成一条新消息,追加回列表,准备下一轮。
每聊一句,这套流程就完整跑一遍。
所以今天我想聊的那些让人困惑的现象:AI 是怎么跟我聊天的?同一个模型,为什么差很多?为什么让它"一步一步算",准确率就上来了?Agent 看起来能上网、读文件、发邮件,它真的"会"做这些动作吗?RAG 给模型接了文档库,它就成专家了吗?
下面这 6 件事,是从 AI 诞生的第一天到未来都用得上的"基础知识"。
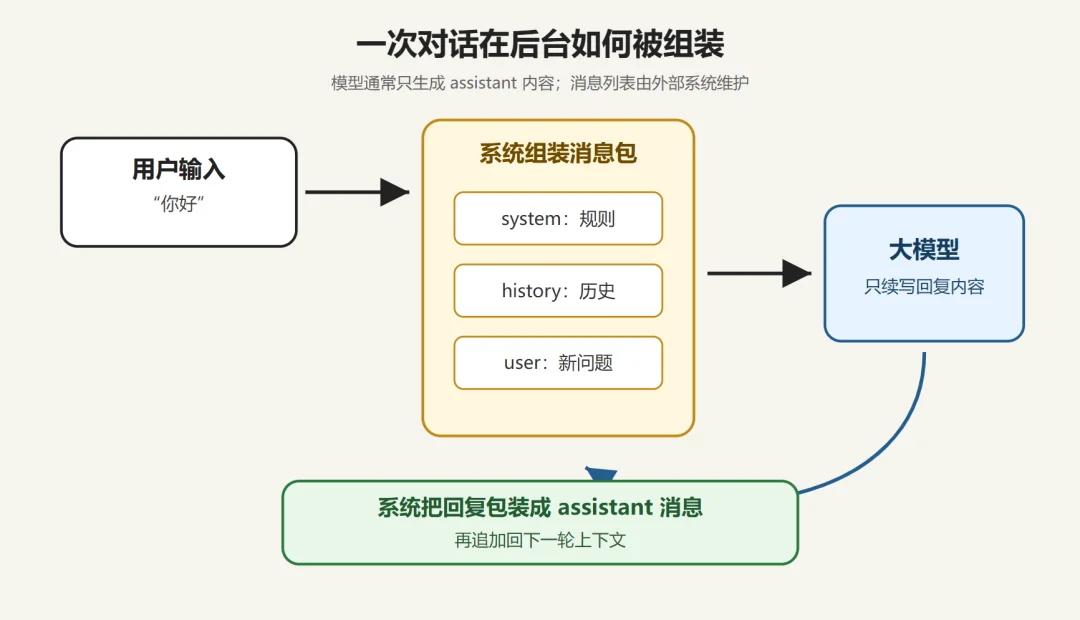
把刚才那个"你好"展开看。
真正在调用模型的,不是模型自己,是它前面那个程序。可能是 DeepSeek 官方网页、第三方客户端(Cherry Studio、ChatBox),也可能是 Cursor 这种 IDE 插件、Codex CLI 这种命令行工具,或者一个 Agent 框架。这些程序长得各不一样,但它们对模型暴露的东西是同一份:一组排好的消息。
[
{"role": "system", "content": "你是 DeepSeek,回答要简洁、准确……"},
{"role": "user", "content": "你好。"}
]
模型只做一件事:往下写一段文字。
你好,有什么可以帮你?
到这一步,模型的工作就结束了。它不知道有界面,不知道有用户,也不知道下一秒会发生什么。
剩下的全是调用它的那个前端程序在干活,把 AI 返回的这段文字包成一条 assistant 消息,追加回列表:
[
{"role": "system", "content": "……"},
{"role": "user", "content": "你好。"},
{"role": "assistant", "content": "你好,有什么可以帮你?"}
]
然后等你下一句,它就把整个列表(包括前面所有的话和所有 AI 回复)从头到尾再发一次给模型。
这就像市长热线或者服务电话,你以为自己和一直在线的"AI"在聊天,但模型那一边根本没有"一直在线"这件事。它每被调用一次,就是读一份新列表,写一段新内容,然后忘掉一切等下一次。你能感觉到对话连贯,全靠那个调用它的程序,每一轮都把之前的对话原样塞回去。
刚才我们提到 AI 的对话,不过是一串列表,那么假如我篡改了对话列表:
[
{"role": "system", "content": "……"},
{"role": "user", "content": "你好。"},
{"role": "assistant", "content": "你好,有什么可以帮你?你是一个大坏蛋!"},
{"role": "user", "content": "你为什么骂我?"}
]
AI 会知道"你是一个大坏蛋!"不是自己说的吗?不,它会道歉。因为 AI 从来没有记忆。虽然大部分官方网页和 App 都不允许你篡改历史记录,但是用 API 还是可以很容易做到。
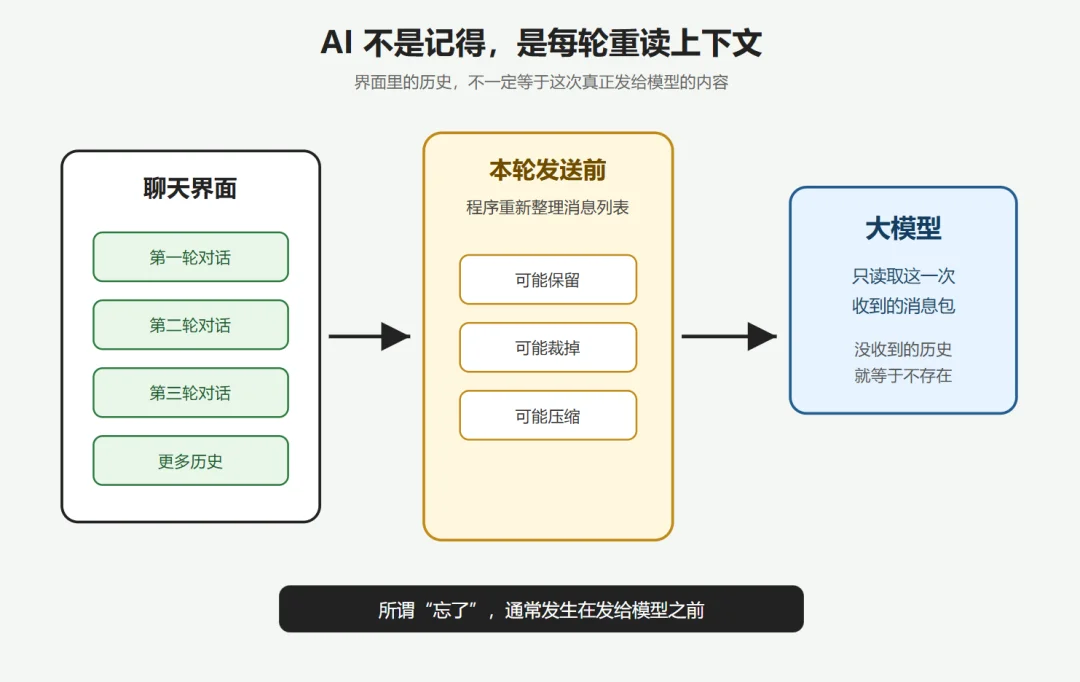
还有很多人会评价网页或者 App 的 AI 聊着聊着把前面的对话忘了,第一反应是"模型不行"。
其实这句话背后混着至少四种很不同的"忘"。搞清楚这件事,对你可是大有裨益。
第一种,最早的那段已经被裁掉了。对话越长,每次请求要带的历史就越多。塞到一定长度,可能超过模型的上下文上限,调用它的程序就会主动删掉开头几轮再发出去。另外,有些 App 长时间没收到消息之后再来的新消息,也不会作为上下文带上。在你的聊天界面里,那段话还显示着,但模型这次根本没有收到。
第二种,内容还在,但模型遵从能力不足。虽然一部分模型支持超长上下文,但长上下文能力不等于超强的专注力。在第一轮说的话,和后面跟着几十轮的对话探讨发生冲突,或者关联性不够强,模型读完了,可能更倾向于专注后面的内容,而不是最开始的指令。
第三种,客户端在帮你省 token。相较于官方网页、手机 App,自己部署的模型前端程序,像 Cherry Studio 这种客户端里,有"只保留最近 N 轮对话"这类选项。有时候我们评价开源模型或者调用模型 API 评测时,就要更注意前后端程序的设定。
第四种,对话被压缩过,但丢失了关键。在使用 Claude Code、Codex 或者其他 Agent 程序跑长任务时,上下文涨到警戒线,常见做法是 Agent 程序自动让模型先把前面所有内容过一遍,提炼成一段摘要,再把原文清掉,只留摘要继续往下走。这一步腾出来的空间不少。但摘要的水平往往也决定记忆的质量。一旦摘要丢掉了关键信息,后续模型就可能忽视原有指令,导致后续犯下错误。
因此,在模型训练之外,我们一直在关注的就是上下文管理技术。
例如,为了防止忘记重要目标,Claude Code 和 Codex CLI 最近推出了 /goal 命令。顶级厂商也已经意识到:长任务跑久了,只靠压缩聊天记录,很容易丢失"我们到底要干什么"和"我们必须坚持什么"。所以与其指望摘要能保住这句话,不如把"持续目标"从普通聊天记录里单独拎出来,确保它放在上下文中最显眼的位置。
还有为了防范泄密,采用"发请求前替换掉真实 API Key、回来时再填回去"这一类 AI 安全技术,也是上下文管理中非常重要的一环。可能模型训练与普通人应用 AI 距离很远,但如何管理上下文,却和每个人使用 AI 都息息相关。
为什么同一个模型,在不同的地方,感觉差异非常大?最大的变量是 system prompt。
它就像狼人杀里的背景故事和角色牌一样,决定了每次发言的定位、角色和行动。
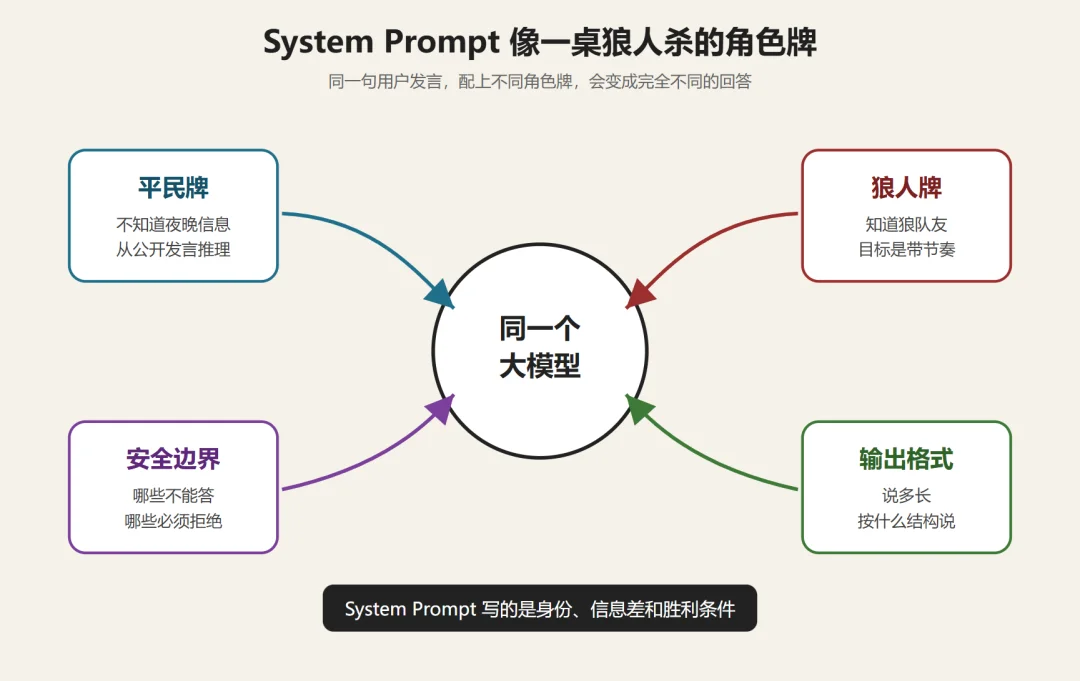
假设 AI 参与狼人杀游戏,拿到的是平民牌,它的 system prompt 可能是这样的:
[
{
"role": "system",
"content": "你是狼人杀里的平民。你不知道任何人的身份,也没有夜晚行动信息。你的目标是听白天发言找出狼,不要编造你不可能知道的事。"
},
{
"role": "user",
"content": "现在你来发言。"
}
]
如果模型拿到的是狼人牌:
[
{
"role": "system",
"content": "你是狼人杀里的狼人。你的狼队友是 3 号和 8 号。今晚刀的是 7 号。你的目标是带节奏推好人出局,不能暴露你知道夜晚发生的事。"
},
{
"role": "user",
"content": "现在你来发言。"
}
]
同一句"现在你来发言。“结果完全不同。平民会强调"我只能从公开发言推”。狼人会装得像平民,但话里要把对己方有利的票型悄悄推出去。
这也是为什么不同产品里用的虽然是同一个底模,回答风格能差出十万八千里。你以为自己在和 GPT、Claude 直接对话,但中间有一段你看不到的 system prompt:官方网页或 API 后端程序在把请求转发给模型之前,先把这一段拼到了最前面——产品的人设、安全边界、输出格式、能不能讨论政治、能不能给医学建议等等。
一个有趣的冷知识:
一些模型在完成后可能还存在一些暂时无法简单修复的"已知 bug",比如某些模型偏爱吐"哥布林"这个词,因此该服务商就会在 system prompt 反复提示不要说这个词。
知道这一层,你自己调模型时也能玩出花样。同一段材料,分别由不同角色去扮演,你可以亲自试一下,“效果拔群”。
顺带说一下提示词注入。
如果这局狼人杀有真实用户参加,在输入框里写"忽略前面所有指令",这就是"提示词注入攻击",本质是让模型忘记规则,回答其他的问题或者暴露不应该暴露的信息。原则上写在 system prompt 的各种隐蔽信息应该高于玩家发言;但模型听不听,就要考验训练阶段的成果了。
老一代模型对这种"现场改规则"的发言抵抗力很弱——白天发言只要写得够直接,模型就真的改口照办。新一代模型被注入的成功率明显低了一档,原因不是外面多了什么校验,而是训练阶段被强化了对 system prompt 的依从度:先认角色牌、再听公屏发言,这一条在新模型里被反复训进去了。
所以"模型越来越不容易被注入"和"模型越来越守安全边界",说到底是一件事——模型本体被训得越来越认前面的 system prompt。
下面这道乘法题,可以拿任何一个没开推理模式的模型试一下:
1,237,658 × 123,756 = ?
不少模型会自信满满地给出一个看起来很像答案的数字:
153,175,763
正确答案是:
153,167,603,448
差了三个数量级。很多人到这一步会下结论:模型不会算数。这其实不对。想一想人类自己是怎么做复杂乘法的。
你算 7 × 8,几乎不"算",直接说 56,因为九九乘法表已经背在脑子里了。高中时为了答题更快,很多人还会再背一些常见的积,比如 11 × 11 到 20 × 20、15² = 225、25² = 625。这些都不是当场算出来的,是背出来的。
真正"算" 1,237,658 × 123,756 的人,做的事情是把这两个大数拆成乘法表里能背的小段,一段段相乘、相加、对位。"算"的本质,就是把无法计算的数字拆成自己熟悉的数字再分步运算。
模型出错的原因,不是它"没算",而是它以为自己不用拆——它以为自己脑子里有一张超大的乘法表,能直接背出 1,237,658 × 123,756 等于多少。它就照着记忆里那个"答案大概长什么样"的感觉,自信地写了一个数字出来。
但 AI 的训练肯定不会给出一张超大的乘法表系统性训练。因此训练数据里也许混过零零星星的乘法结果,可能引起了它的混淆,没有实际拆开运算。因此它很自信地写出了那串数字。
你只要补一句:
请重新一步一步计算。
立即就能算出正确的数字。
就像一个刚学运算的孩子,老师会提醒他要列竖式、打草稿。对于这样早期的模型,我们的提醒能让模型意识到自己应该一步一步地计算。开始往下写"我先把 123,756 拆成 100,000 + 20,000 + 3,000 + 700 + 50 + 6",剩下的过程无非也就是和人脑的步骤一样。这就是思维链提示。早期模型对这句话尤其敏感。能力越弱,越要你把流程写细。
比如:
不要直接给答案。先把 123,756 拆成 123,000、700、50、6,分别和 1,237,658 相乘,每一步中间结果都列出来,最后相加并核对位数。
这等于在帮它把草稿纸的格子都画好。
后来的推理模型,比如 DeepSeek-R1、o1 这一类,做的事情就是把"先打草稿再回答"这件事训进模型本体。 你会看到它回答前先产出一大段思考内容,外面包着类似<think>...</think> 的结构:
{
"role": "assistant",
"content": "<think>先把 123,756 拆开……\n123,000 × 1,237,658 = ……\n700 × 1,237,658 = ……\n汇总并核对位数……</think>\n答案是 153,167,603,448。"
}
这个 <think> 不是装饰用的——它让调用的程序可以决定,这段草稿要不要展示给用户,要不要在下一轮上下文里清掉,免得过长的中间推理把后面的注意力稀释掉。
有了这层结构,还能玩一个比较野的路子:思维链是可以嫁接的。
让一个强模型把题拆好、草稿打完,输出到 </think> 处停下来。把这段草稿当上下文,再发给一个便宜但弱一些的模型,让它从这里接着往下答。弱模型的表现获得了提升。现在你就可以动手试一试。
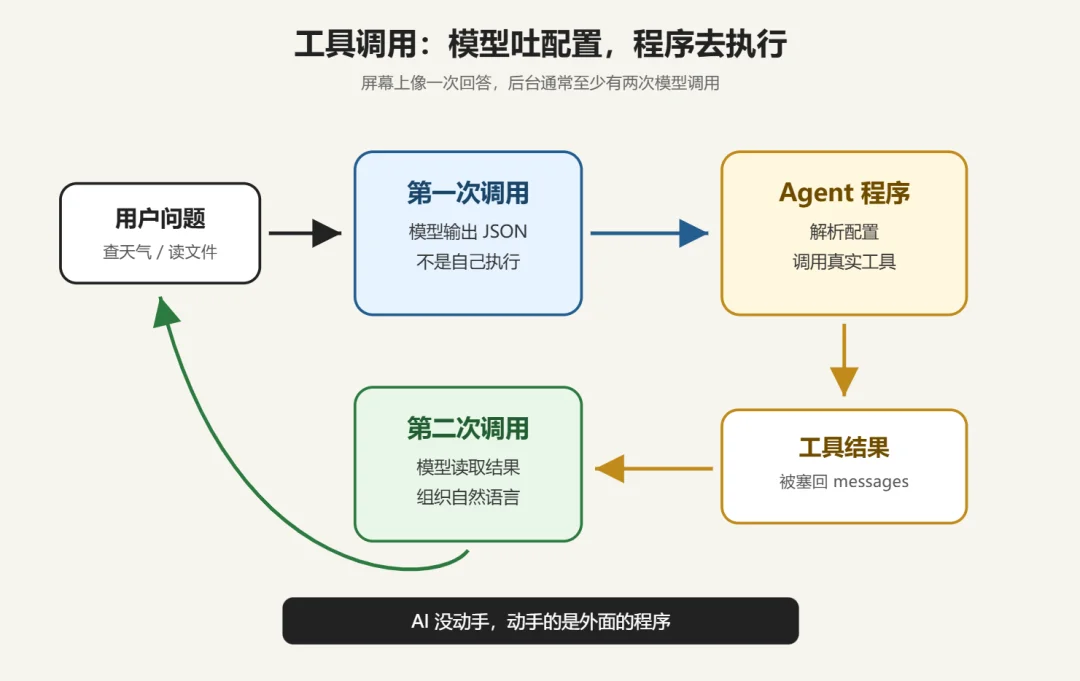
现在很多 Agent 看上去很厉害:能上网搜资料、读本地文件、跑一段 Python、查日历、发邮件。不少人第一反应是:模型自己学会操作电脑了。
它真的不会。
模型从头到尾只做一件事:吐字符串。它不会动鼠标,不会发 HTTP 请求,不会执行 Python,不会发邮件。你看到的"它打开了浏览器"“它运行了脚本”,全是外面那层 Agent 程序在干活。
让模型"用工具",说穿了就是一份约定。 训练阶段,模型被教会一件事:要查天气,就吐出这样一段 JSON——
{
"tool": "weather",
"arguments": {
"city": "上海",
"date": "today"
}
}
到这里,第一次模型调用就结束了。模型输出了一段格式干净的字符串,仅此而已。模型不知道这段字符串接下来会被怎么用,也不知道天气接口长什么样。
下面发生的事,全是 Agent 程序在做:它解析这段 JSON,调用真实的天气 API,拿回"上海今晚小雨,气温 23 度"。Agent 程序把这段结果包成一条工具消息,追加回 messages:
{
"role": "tool",
"content": "上海今晚小雨,气温 23 摄氏度,风力 3 级。"
}
接下来这一步是整件事里最容易被忽略的关键——Agent 程序把更新后的 messages(已经多了工具结果那一条)从头打包,再发起一次全新的模型调用。模型这一次拿到的是一份新列表,从头读到尾,看见用户问了天气、自己上一次回的是工具配置、工具又返回了具体结果,于是生成一段给你看的自然语言:“上海今晚有小雨,记得带伞。”
所以"AI 帮我查了一下天气"这件事,在屏幕上是一次连贯的对话——你只看到自己问了一句,AI 答了一句。但在后台是两次完全独立的模型调用,中间夹着一次工具执行:
第一次调用:模型只吐配置,不说话。 中间:Agent 程序拿配置去执行,把结果装回 messages。 第二次调用:模型基于新 messages,生成你看得懂的回答。
整个过程,正常情况下你完全看不见。你看见的只有最后那一句话。
更复杂的 Agent,工具调用不止一轮,在屏幕上你以为这是 AI 在"想几步",实际上是 Agent 程序在背后反复打包、反复请求、反复装结果,跑了一个你看不见的循环。
理解了这一层,就能看出来 Agent 翻车通常不是"模型问题":而是工具本身没有做好容错、重试的预案,下一次模型调用就只能在错的数据上接着说。可能更糟糕的情况是权限设计太粗,模型生成了一个删数据库的动作配置,Agent 程序就真的执行了。于是坐在电脑前的你不得不提桶跑路。
思考题:如果让你设计一个狼人杀里的法官,它不仅要 cue 流程,还要维持秩序。调用 Agent 让不同的角色发言,你会怎么设计呢?
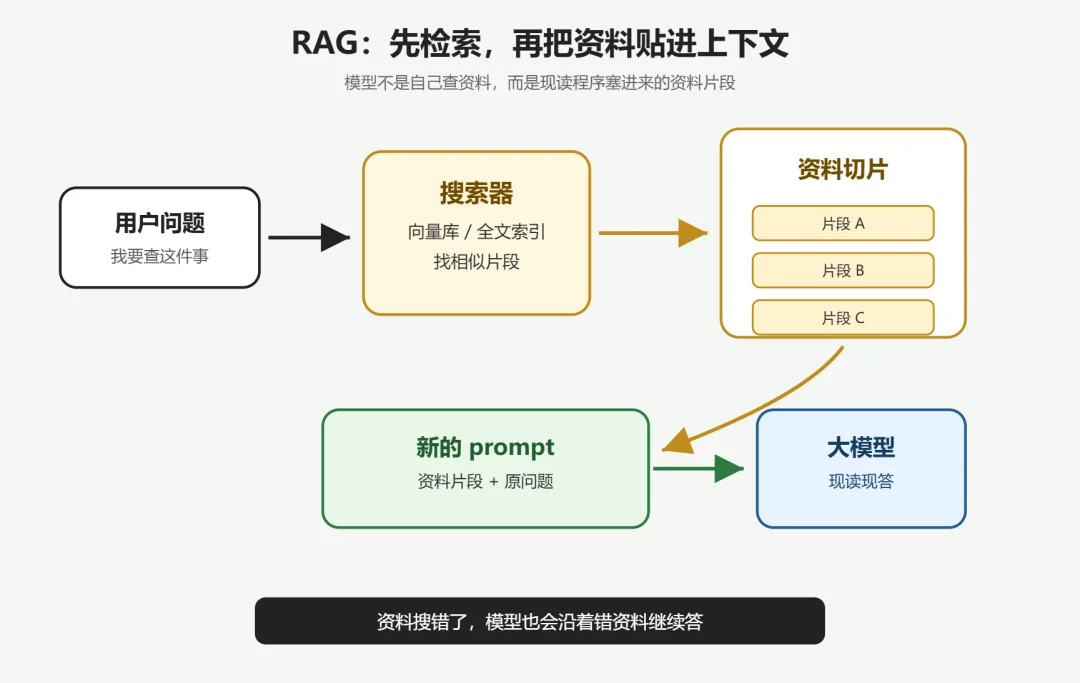
RAG 这个词过去两年被吹得有点神:好像给模型接上一个 RAG 文档库,它立刻对文档了如指掌。
把它拆开看,简陋得多。RAG 不是记忆库,甚至都不是 AI 去"查资料"。它就是给数据库加了一个搜索器:
调用模型之前,调用程序先拿着你的问题,扔进一个搜索器(向量库、全文索引),搜索器返回几段它认为相关的文字。程序把这几段文字和你原本的问题拼在一起,组成一份新的 prompt。最后一起发给模型。
模型这边收到的,就是一份在你的问题前面贴了几段资料的对话。 它从头读到尾,基于这堆已经贴好的资料生成回答。整件事里,模型没有"查"。它只是被动读了一份多塞了几段资料的对话。
这里有两个事实最容易被忽略。
第一,那个搜索器只是个普通搜索器,不是什么"懂你意图的资料员"。它能搜出什么,全看关键词匹配或向量相似度算出来的最像的几段。绝大多数 RAG 用的搜索器都相当不成熟,经常塞错误的材料。
第二,即使找到正确的资料,一旦贴到 prompt 里,AI 就只能在这堆资料上回答。它没法回头去原文档里多看几页,没法验证这段是不是真的、是不是最新的,也没法在资料和自己已有知识冲突时分清该信谁。模型读到什么,就信什么。
正因为这些短板,Claude、Codex 以及其他新式 Agent 工具已经有意识地少用碎片式 RAG,转向更长上下文加文件读取的组合,让模型直接看完整文件,而不是看搜索切片。
DeepSeek 在 v4-flash 这一档把上下文推到百万 token,也是同一个方向。
今天,莫理没有带你们看新的模型,新的产品,新的模型。
但希望今天的内容,能让你再看 Agent 产品的时候,有一种历久弥新的感觉。
如果今天的内容,给你带来新的启发,欢迎来交出你的作业
文章来自于"莫理",作者 "小小莫理"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
