# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文第一作者李淳誉为复旦大学博士生,主要研究方向为视频生成扩散模型;复旦大学硕士生李佳烨为共同一作。复旦大学教授,上海创智学院全时导师朱思语为通讯作者。
文本驱动的音视频数字人,正在从 “能生成” 走向 “能实时交互”。但这条路并不好走。一方面,视频和语音的联合生成本身就是高维、重计算任务;另一方面,一旦为了速度做激进加速,嘴型同步、语音自然度和人物细节往往会一起下滑。
最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来,在两张 NVIDIA H200 GPU 上实现了 20.38FPS 的吞吐与 0.94 秒 的端到端延迟;相较教师模型 Ovi,吞吐提升 16.0 倍,延迟下降 99.3%,同时仍保持接近教师模型的视觉质量和音画同步效果。


此 demo 展示了 Hallo-Live 在动漫风格、写实人物和 Multi-speaker 场景下的实时文本驱动音视频生成效果。
为什么实时音视频生成这么难?
和传统的音频驱动数字人不同,文本驱动音视频生成要同时完成两件事:先 “理解” 文本里的人物、场景、语气和声学环境,再同步生成对应的说话视频与语音。这意味着模型不仅要保证画面质量和语音自然度,还要把嘴型、发音、表情甚至上半身动作卡在同一个时间轴上。
已有工作里,Ovi 等双流扩散模型已经证明,音频流和视频流分开建模、再做跨模态融合,是一条有效路线。但问题在于,这类模型通常更偏向离线高质量生成,离实时交互还有明显距离。作者指出,真正把它改造成流式系统时,会遇到两个核心瓶颈:
Hallo-Live 整体框架
Hallo-Live 包含两个训练阶段。Stage 1 是Dual-Stream ODE Init:模型同时输入不同 noise level 的音视频 blocks,基于单模态和跨模态的 Block-Causal Mask 训练双流 DiT,使训练阶段的可见性约束和流式推理保持一致。Stage 2 是Self-Rollout + Dual-Stream DMD:学生模型基于音视频 KV Cache 自回归生成完整音视频,再引入音频、视频和音视频同步相关的 reward,对双流 DMD 损失进行加权,从而把教师模型蒸馏为 few-step 模型。
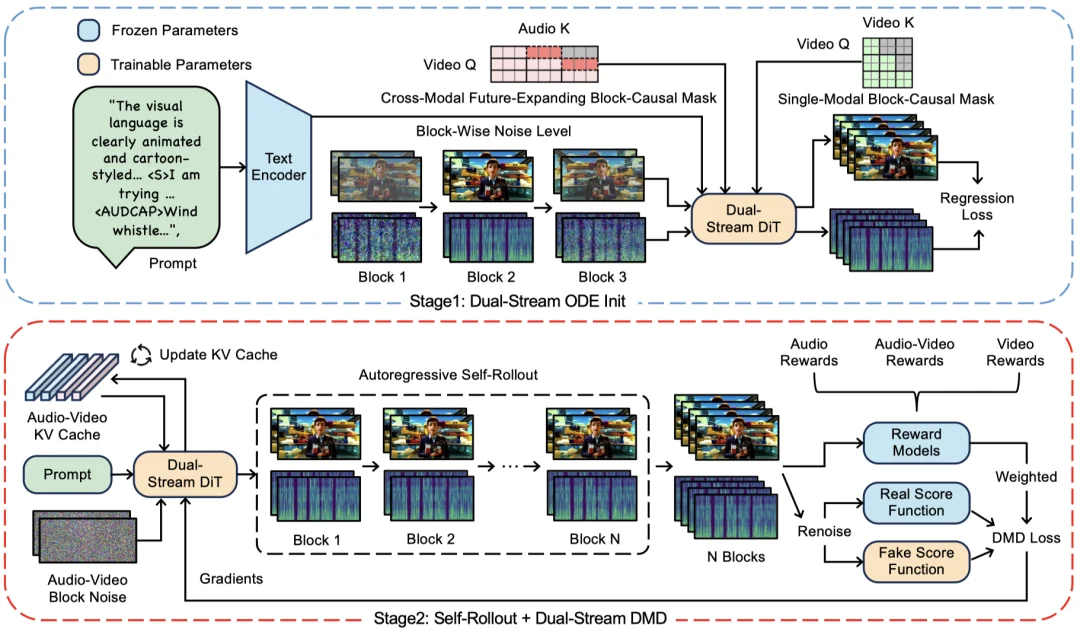
Causal Fusion Block 则是 Hallo-Live 双流 DiT 的核心单元:视频流和音频流先分别做单模态 Block-Causal Self-Attention,再注入文本条件,随后通过跨模态 Block-Causal Cross-Attention 交换信息,在流式生成下完成音视频融合。其中,视频到音频的注意力使用 Future-Expanding Block-Causal Mask,让当前视频块能够看到少量未来音频上下文。
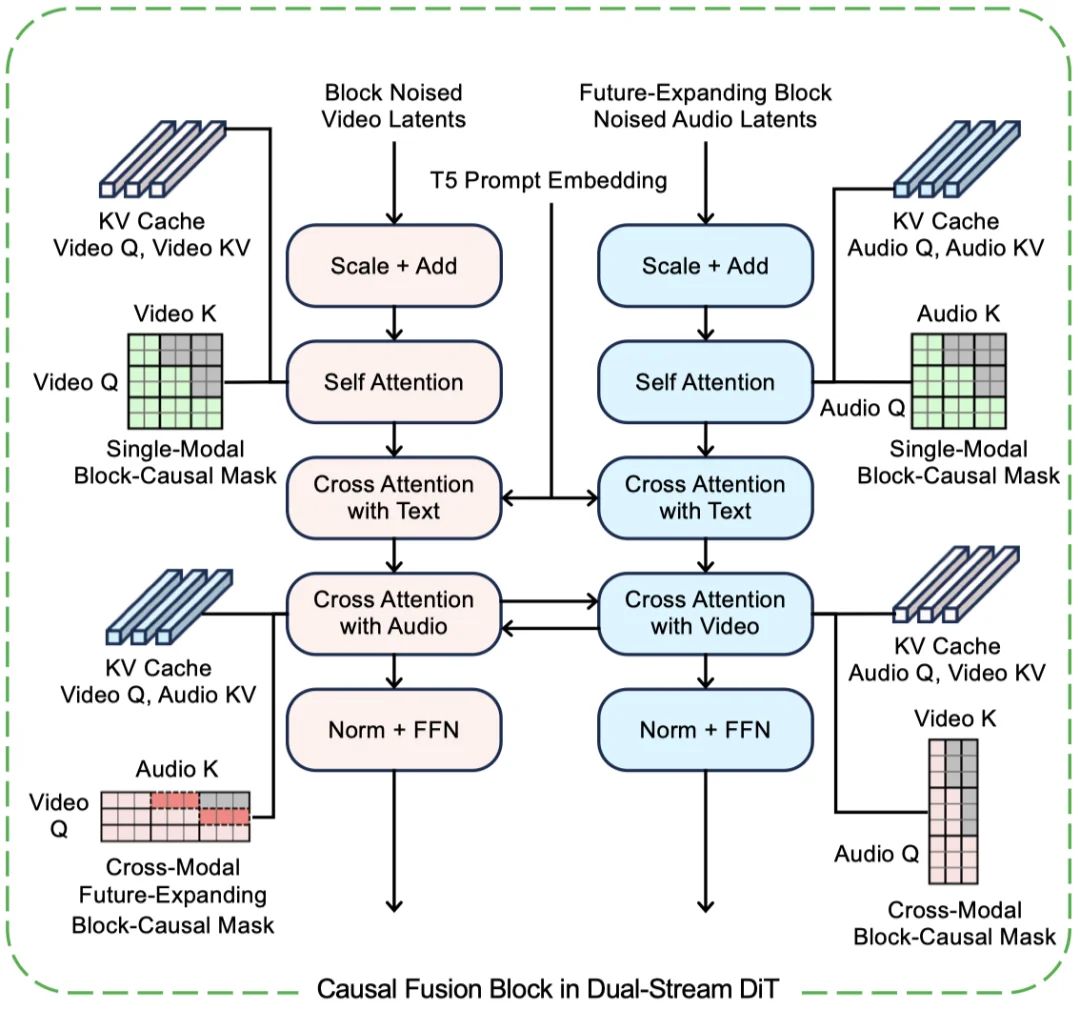
关键技术 1:
Future-Expanding Attention
论文第一个创新设计,是 Future-Expanding Attention。作者观察到,如果视频流只能看到当前和过去的音频块,那么模型很难做出自然的提前张口、闭口、唇齿过渡等动作。于是,他们把视频到音频的跨模态注意力做成 “非对称” 的:视频仍然聚焦当前块,但音频键值范围会额外向前扩一小段 look-ahead 窗口。
这相当于给视频流一个短时的 “预读区”。重要的是,这个未来音频块并不是最终输出,而是一个临时的、可被下一步覆盖的过渡块,因此不会损失最终生成的音频质量。
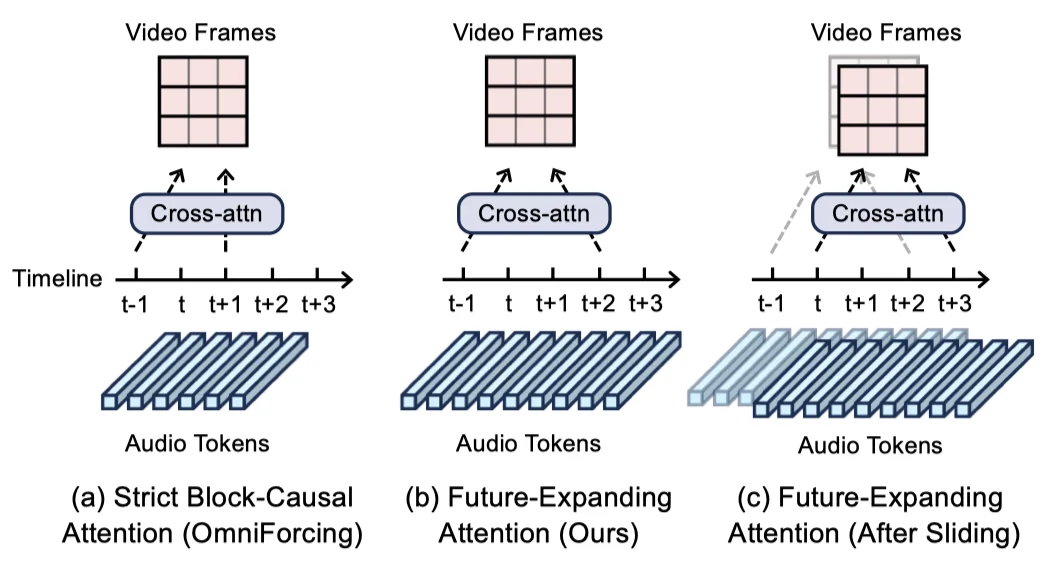
从直觉上看,Strict Block-Causal Attention 只能看当前音频,而 Future-Expanding Attention 允许视频块访问少量未来音频,从而改善口型同步效果。
关键技术 2:
把 “偏好” 直接蒸馏进学生模型
如果说 Future-Expanding Attention 解决的是 “看不见未来语音” 的问题,那么 HP-DMD 解决的则是 “加速以后为什么会变丑、变僵、变不同步”。
作者的做法是把蒸馏目标从单纯模仿教师分布,转向 “奖励加权后的教师分布”。其中:
如果用更接近 RL / reward optimization 的语言来写,Hallo-Live 的核心不是直接做 policy gradient,而是先给学生模型生成的样本打分,再把这些 reward 通过指数重加权注入蒸馏目标。从分布视角看,它等价于不再单纯拟合教师分布 p_T,而是去拟合一个被 reward 倾斜过的新目标分布:
直观理解,这套写法更像 “reward-weighted distillation” 而不是传统强化学习里的策略梯度更新:模型并不直接对动作概率做 RL 优化,而是通过 reward 重新塑形 student 要逼近的目标分布。
结果如何?
速度几乎 “断层领先”,质量接近重型教师模型
从主要结果来看,Hallo-Live 最突出的优势就是把文本到音视频生成首次真正推入了实时区间。
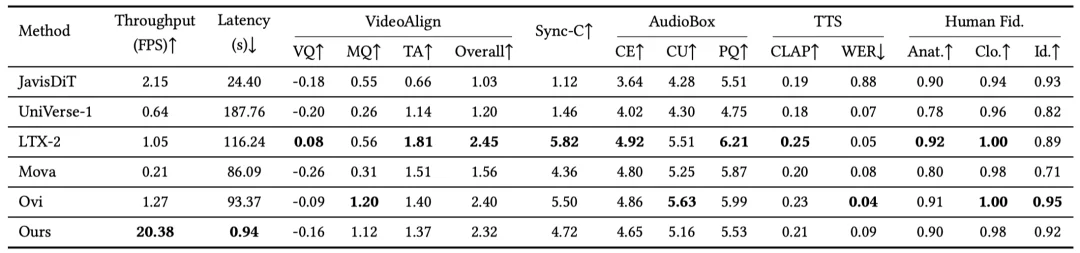
从指标结果来看:
这组结果说明,Hallo-Live 并不是用极端牺牲质量去换取速度,而是在质量基本守住的前提下,把系统推到了可交互的速度等级。对于数字人直播、角色扮演和虚拟主持等场景,这一点非常关键。
意义与展望
Hallo-Live 的价值,不只是把速度做快了一点,而是提出了一种很有代表性的技术路线:在保持流式因果生成框架的前提下,完成视频和语音的联合生成。对数字人行业来说,提供了一种可部署、可交互、可扩展的模型形态。
当然,论文也没有宣称问题已经被完全解决。比如,从指标看,Hallo-Live 在同步和语音质量上仍未全面超过最强离线或重型模型;另一方面,当前实验平台仍依赖两张 NVIDIA H200,距离更低成本硬件部署还有优化空间。不过,如果把“实时文本驱动音视频数字人”看作一个长期目标,Hallo-Live 已经给出了一份相当明确的阶段性答案。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
