# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
项目地址:htps://github.com/learningCatHD/telos-sdk
就在几天前(5月22日),DeepSeek官方扔出了一枚重磅炸弹:DeepSeek-V4-Pro将在5月底结束优惠后,永久降价至原价的四分之一。各大媒体瞬间被诸如“白菜价”、“夯爆了”的标题刷屏。看看这组惊人的新定价:每百万Token输出6元,输入(缓存未命中)3元,而输入(缓存命中)仅仅只要0.025元!

许多人欢呼雀跃,迫不及待地准备将便宜的V4接入Openclaw、Hermes等Agent框架中。但当你跑完长会话,仔细核对账单时,可能会发现一个悲催的问题:支付的绝大部分其实是那3元的“高价”输入,而不是0.025元的“白菜价”缓存。
为什么会出现这种偏差问题?这需要从大模型推理的底层机制KV Cache(键值缓存) 说起。LLM生成文本时,是基于历史所有Token的注意力机制计算出来的。为了不让LLM在每说一个字时都把前面的几十轮对话重新算一遍,推理引擎会将历史文本生成的键(Key)和值(Value)矩阵保存在显存中。下一轮对话时,只要新输入的开头字节与这些已经缓存的矩阵完全一致,模型就可以直接读取结果(cache_read),免去了高计算量的预填充(Pre-fill)过程。
本质上,API厂商打一折的底气,正是来自于用户对底层 KV Cache 的高比例复用。可遗憾的是,上层应用框架的混乱,正在导致底层的缓存设施全面溃败。
在真实的长会话运行中,智能体Token的实际利用率通常只有25%。剩余的75% 去哪了?TELOS的项目作者王政指出,把AI用进生产环境,开发者必然会撞上这“四堵墙”:

currentDate,整个段落的前缀哈希(prefix hash)就被污染,缓存命中直接归零。底层推理引擎(如vLLM)和各家API其实早就支持了高效的KV-Cache复用。但这一切生效的前提是:输入到引擎的Prompt必须在字节级别上绝对稳定。
现实情况是,大多数Agent框架在构造请求时毫无纪律性。日常实践中,系统常常无差别地将时间戳、动态工作目录(CWD)、进程ID(PID)强行塞进对话历史的早期位置。这些微小的变量瞬间破坏了前缀匹配,导致本该走0.025元通道的请求,被系统静默地按照3元全价收费。这是一种不会触发任何报错的“沉默失败”。
为了接住DeepSeek V4带来的算力红利,我们必须填补这道缝隙。为此,项目作者提出了一种名为TELOS的上下文中间表示协议。
为了从根本上消除这种“沉默失败”,TELOS协议来了。它的核心思想是将“保证缓存不失效”从以往的开发者经验启发式(heuristics)操作,转化为可通过系统静态验证的结构性约束。

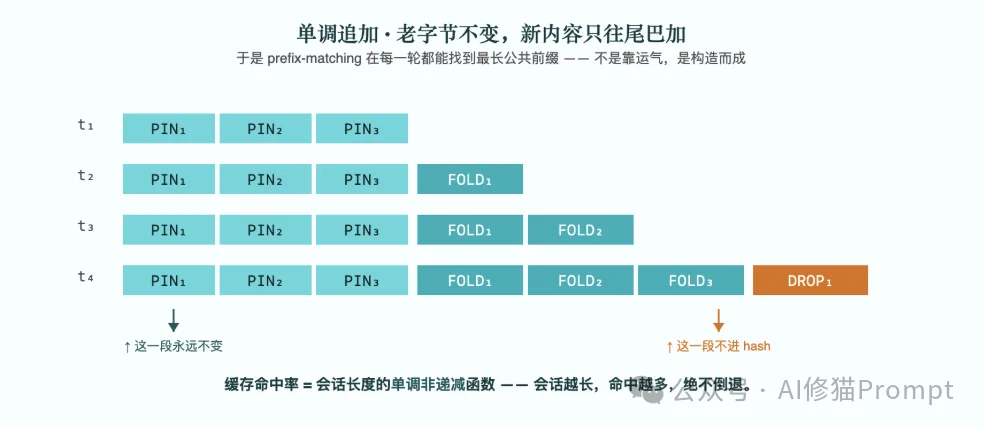
TELOS协议将完整的Prompt划分为三种具有明确生命周期的区块(Block),并通过颜色进行直观区分,这并非装饰,而是Prompt字节的一级类型:

TELOS对上述区块提出了严格的形式化约束。假设Prompt是一个由有限内容块构成的序列


命题的数学保证:只要遵循上述三个条件,无论底层推理引擎采用何种前缀匹配缓存策略,该会话的缓存命中率必定是会话长度的单调不下降函数。因为新一轮的内容仅仅是追加在尾部,前方的字节永远保持绝对一致,引擎不需要靠运气,而是靠结构必然能找到最长公共前缀,这就是TELOS厉害的地方。
一个明确的对比:
在LLM的评测文献中,事后挑选样本来粉饰数据的行为(p-hacking)被反复批评。为了保证研究的科学严肃性,项目作者采用了一次严谨的“预先登记(pre-registered)”实验,即在跑数据之前,就已经将任务分配、抽样方法和统计检验标准完全固定下来。
deepseek/deepseek-v4-flash 模型。由于DeepSeek的接口原生提供字节稳定的隐式前缀缓存功能,符合实验所需。为了进行配对统计推断,研究设定了固定的随机种子(seed = 7),从8个知名开源仓库中分层随机抽取了100个实例。抽样分布包含了 sphinx (33)、matplotlib (19)、xarray (19)、pytest (16) 等仓库。
实验设计了两个严格平行的对照组(Arms),两组接收到的任务实例集合完全一致:
为了保证统计的严谨,项目作者公开了实验中遭遇的不可抗力损耗:
matplotlib 仓库的12个实例在拉取环境配置时遭遇HTTP 503报错,导致两组对称失败退出。
实验得出的量化结果有力地支持了项目作者的核心假说:我们完全可以在不牺牲模型推理能力的前提下,从协议层将无效消耗挤干。
在最终完成的评测中,修复率(解决数量/总提交数量)的对比如下:
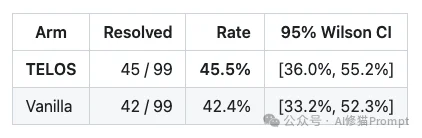
从绝对数值上看,实验组仅比对照组少了2个解决实例,差异为 -3.6个百分点。更关键的是,两个组别的95% 置信区间几乎完全重叠。


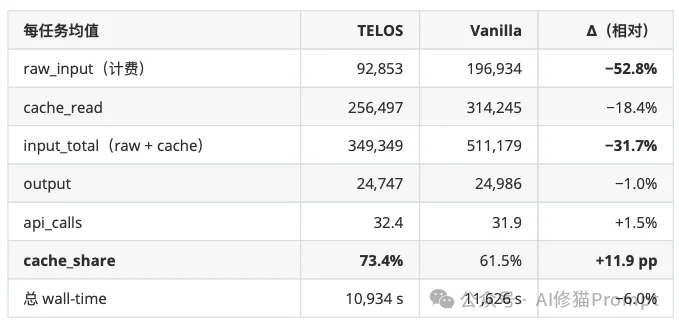
一个常见的质疑是:“节省的资源是不是因为模型变笨了,思考得更少了?” 项目作者提供的核心反证在于对输出行为的监控。
这两项关键指标的近零差异有力地证明:节省全部来源于输入端协议对于字节稳定性的约束,系统并没有通过削减推理深度或切断工具调用来换取成本的降低。优化与能力在此实现了完美的分离。
若以公开的市场报价(原始输入 $0.27/M,缓存读取 $0.07/M,输出 $1.10/M)计算绝对经济账本,TELOS使每任务的原始输入成本从$0.0532暴降至 $0.0251,单次任务总成本从 $0.1027降至 $0.0703。总体绝对成本压降比例达到了-31.5%。
项目组还为此配备了本地可视化的Dashboard,能够脱离云端依赖,按绝对美元汇率对多维度的账单进行审计。
安装只要一行命令
pip install -U telos-sdk
然后再只需要一行命令,即可对你设备上的四个Harness完成配置。TELOS目前支持CC、OpenClaw、Harmes、Codex这四个用户最多的Agent框架。
telos init
当然如果你只想给单个Agent配置TELOS,比如只给OpenClaw配置,也可以使用以下命令

telos init --harness openclaw
最后你就可以输入以下命令打开TELOS的面板,实时查看它帮你省了多少API费用了。
telos dashboard
我按照上述步骤安装好后简单实测了一下,Agent框架是Openclaw,模型用的DeepSeekV4-flash。在一次短时间的真实对话测试中,TELOS dashboard记录到6次模型调用:总raw input为20,906 tokens,cache read为248,320 tokens,prompt cache hit达到92.2%。
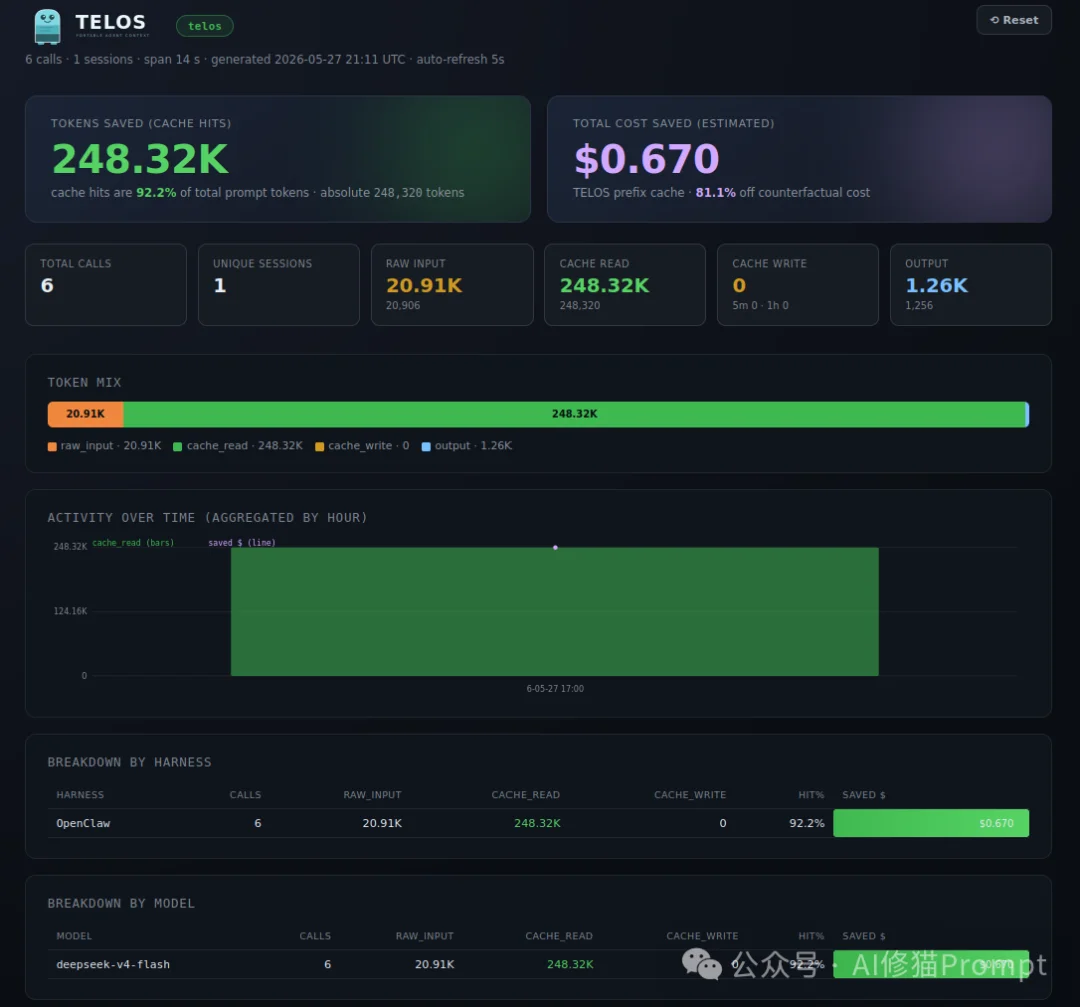
这不是benchmark,只是一次本地跑通验证,但这说明TELOS确实能在OpenClaw这类长上下文agent工作流里捕捉并量化重复上下文带来的缓存收益。
遵循严谨的科学态度,项目作者也主动指出了本次A/B评估的局限性。首先,目前的样本量使得95% 置信区间存在 [-21 pp, +14 pp] 的宽度,虽然可以排除发生超过21个百分点以上的重大劣化,但无法精细判定 ±5% 范围内的微小波动,这需要未来扩充到单组400个以上样本进行验证。其次,由于个别仓库因网络故障导致缺失,结果存在一定的子集偏置,不能武断地直接外推到全量500个测试集。
TELOS说明了:目前极大比例的大模型API成本消耗,并非源于模型自身的低效,而是因为上层调用脚手架缺乏协议纪律。通过引入带有三色带类型注解与单调追加不变量的TELOS上下文协议,开发者能够在保证代码修复正确率和工具调用深度几乎无损的前提下,将昂贵的原始输入Token削减掉一半以上。
如果您正面临大模型应用投入生产时的高昂账单,现在就可以开始审视自身的协议构建逻辑。TELOS是完全开源的,任何人都可以通过安装 telos-sdk 并在本地直接复现项目README所展示的资金审计工作。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
