# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。
然而,随着任务复杂度不断提升,一个新的问题也逐渐浮现:未来的智能系统,是否一定要依赖一个越来越大的“单体模型”?还是可以像人类社会、神经系统和计算网络一样,通过多个智能单元之间的连接、通信与协同,形成更强大的系统能力?
围绕这一问题,清华大学姚权铭团队提出了一种新的 AI 系统组织方式:Language Model Networks。相关论文发表于 ICML 2026,作者为 Shiguang Wu、Yaqing Wang 和 Quanming Yao。该工作进一步设计了 LMNet,让语言模型之间能够通过稠密、可微、可训练的方式进行通信,从而探索从“单模型智能”走向“模型网络智能”的新路径。

过去几年,大模型研究很大程度上围绕“规模”展开:更大的参数量、更多的数据、更长的上下文、更强的训练策略。规模扩展带来了能力跃迁,也推动了大模型在真实场景中的广泛应用。
但当模型开始承担更复杂、更持续、更需要分工的任务时,单体模型也面临新的边界:它需要同时完成规划、推理、检索、验证、调用工具和生成结果,系统压力不断集中在一个模型内部。
Language Model Networks 提供了另一种视角:预训练语言模型不必只被看作一个独立预测器,也可以被看作可复用的计算节点;模型之间的连接、通信和协同,也可以成为智能能力的重要来源。
换句话说,AI 的能力不只来自“模型本身有多强”,也来自“模型被如何组织起来”。
在现有的大模型推理 test-time scaling、多模型协作和多智能体系统中,模型之间通常通过自然语言进行交流。例如,一个模型先生成一段文字,另一个模型再读取这段文字并继续推理。这种方式直观、易用,也方便人类理解,因此非常适合快速搭建应用型系统。
但从机器通信的角度看,自然语言并不是最高效的媒介。
语言是离散的、符号化的,模型之间每次交流都需要经历“内部表示到文本、文本再到内部表示”的转换过程。这个过程可能带来信息损失,也会打断梯度传播,使得整个系统很难直接根据最终任务目标进行端到端优化。
对于模型与模型之间的协同而言,真正关键的问题不只是“怎样写提示词”,而是“怎样让通信本身变成可以学习的对象”。
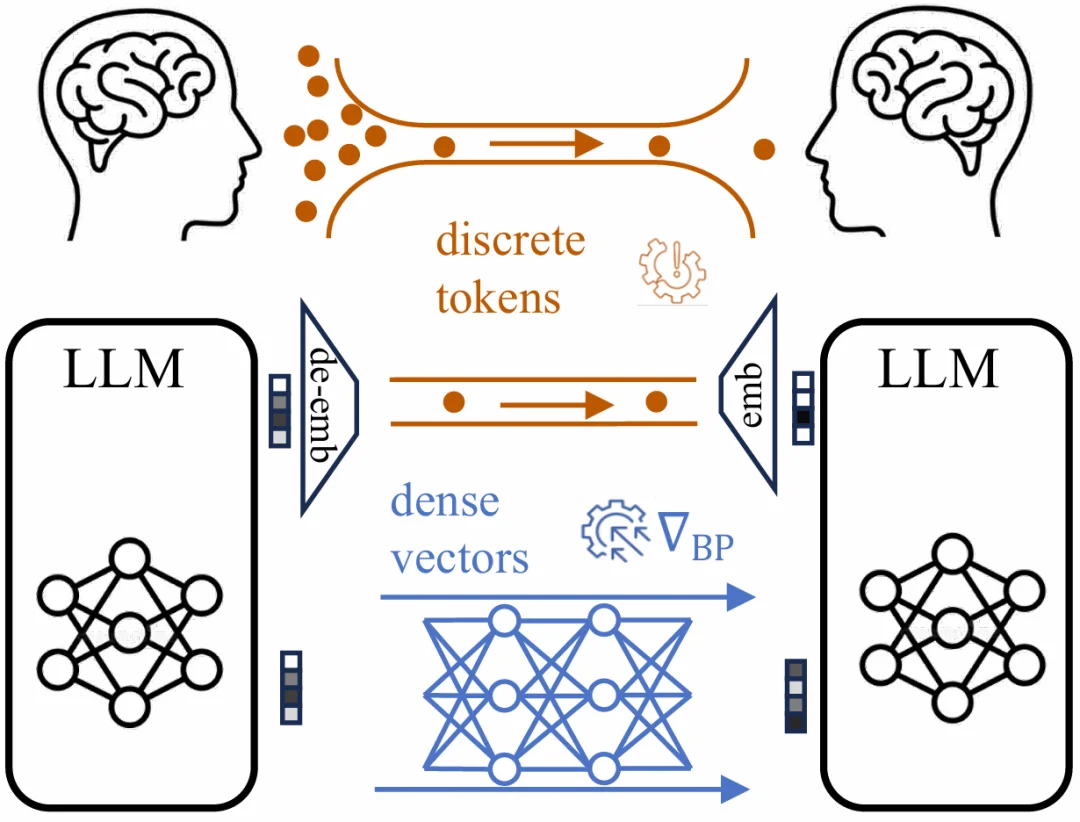
图 1 :离散的自然语言对于模型间通信是非必需的,且传递信息效率低、难以优化;LMNet 利用稠密连续向量进行模型间通信。
LMNet 的设计可以被直观理解为:在语言模型之上,再构建一个“模型级神经网络”。
在普通神经网络中,神经元通过连接形成层级结构;而在 LMNet 中,预训练语言模型被视为可复用的计算节点,模型之间的通信模块则构成可训练的连接边。
具体来说,LMNet 保留系统最外层的自然语言输入和输出,但在中间模型节点之间,尽量绕开反复的文本生成与文本理解过程,让节点直接交换连续的稠密向量。这样一来,模型之间的沟通不再完全依赖人工设计的提示词、角色分工或中间推理文本,而是可以在训练过程中自动学习出来。
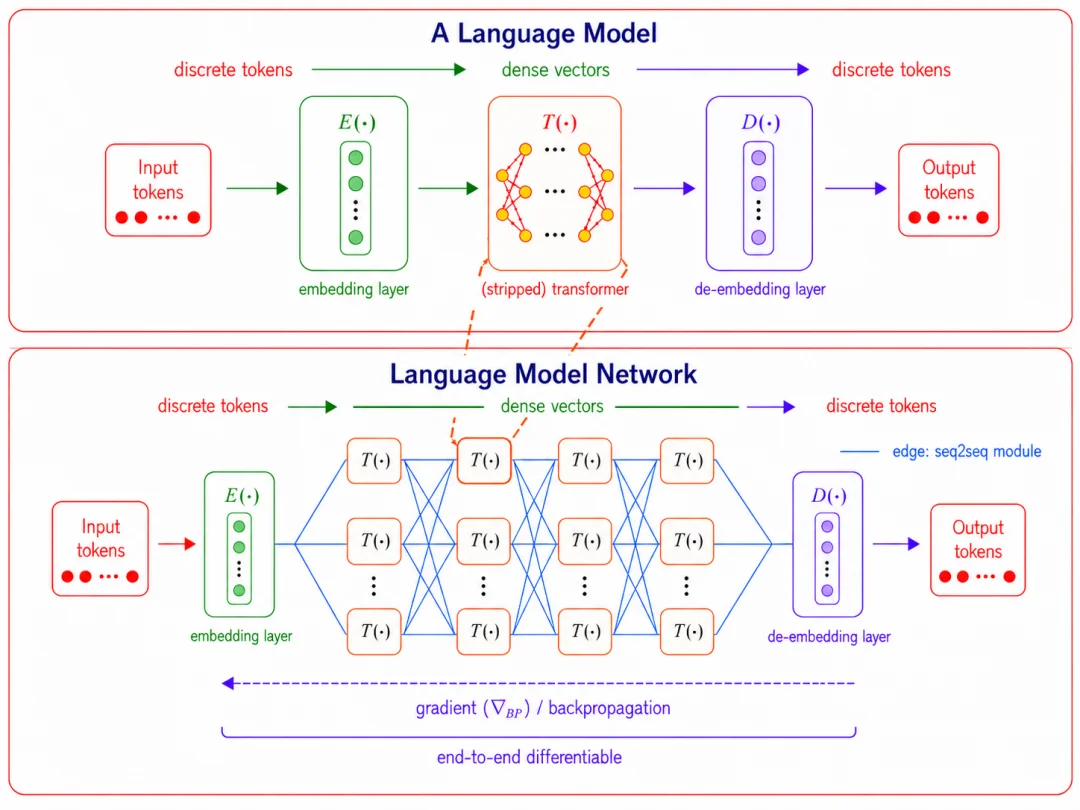
图 2 :LMNet 模型网络结构示意图。语言模型作为节点,通信模块(如 attention block)作为边,形成可端到端优化的模型网络。
这项工作的关键意义在于,它把“通信”从外部设计的规则,推进为系统内部可优化的能力。系统不需要人为标注每个中间节点应该说什么,也不需要提前规定每个模型必须扮演什么角色。只要最终任务有监督信号,LMNet 就可以通过梯度优化自动调整模型节点之间的信息流,学习“谁该向谁传递什么信息”。
从这个意义上看,LMNet 更像是一项关于“智能组织方式”的探索。它将大语言模型从单个预测器,推进为可连接、可组合、可协同的网络化组件;也将 AI 系统设计从“如何提示一个模型”,进一步推进到“如何组织一组模型”。
这与测试时推理、多智能体协作、工作流优化等方向存在自然联系,但 LMNet 更进一步关注底层通信机制本身:让通信变成可微、可训练、可优化的系统能力。
实验结果显示,LMNet 在通用能力提升和有限监督适应两个场景中均展现出良好效果。
在通用能力提升实验中,研究团队以 Qwen2.5-0.5B 作为基础语言模型节点,构建 1/4/4/4/1 结构(共 4 层通信,14 个节点共享参数)的约 1.14B 参数的 LMNet-1B。在额外训练 token 少于 0.1T、训练成本不到基础模型预训练成本 0.2% 的情况下,LMNet 在多个通用任务上取得了明显提升(图 3)。
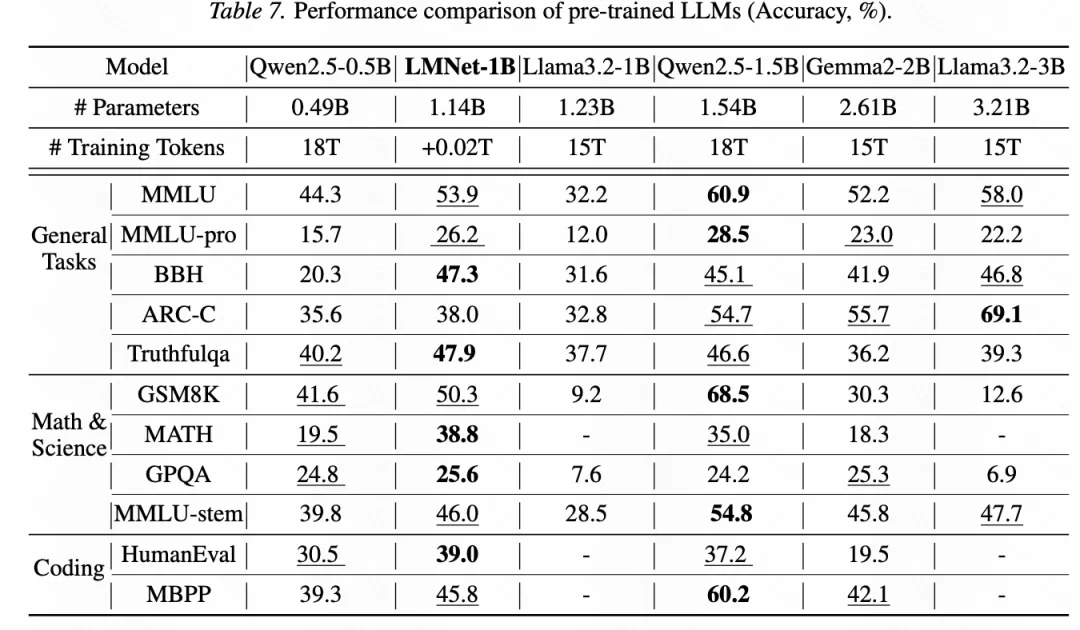
图 3:相近参数规模 LLM 的性能比较
此外,考虑利用单个模型进行推理时 test-time scaling 的方法,以在接近的推理时间开销的条件下进行比较,LMNet 同样展现了明显的性能优势(图 4)。
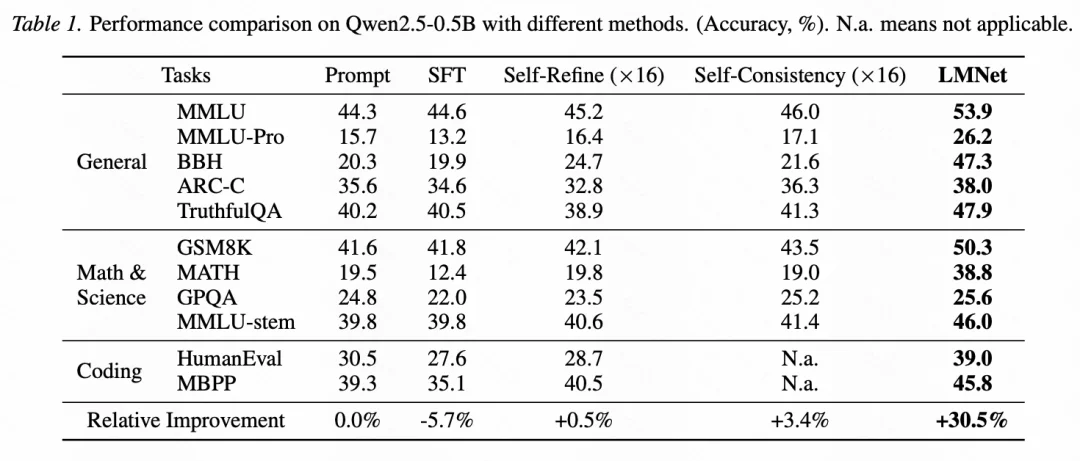
图 4:Qwen2.5-0.5B 不同的 test-time scaling 方法的性能比较
在有限监督适应的场景中,LMNet 通过学习如何交流通信来进行适应。构造更小型的 LMNet,并冻结节点大模型参数只训练边模型的参数,以防止更新大量参数导致的过拟合。和其他 SFT 包括 PEFT 方法相比,LMNet 也展现出明显性能优势(图 5、6)。
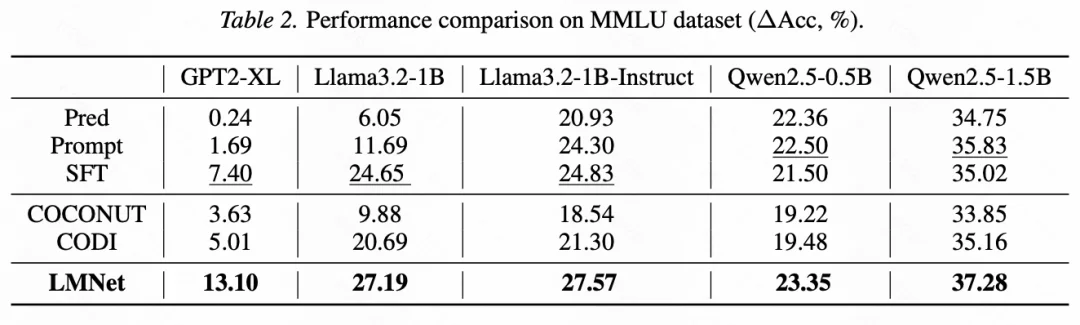
图 5:以不同的 LLM 为底座/节点,在 MMLU 上微调并测试的性能比较
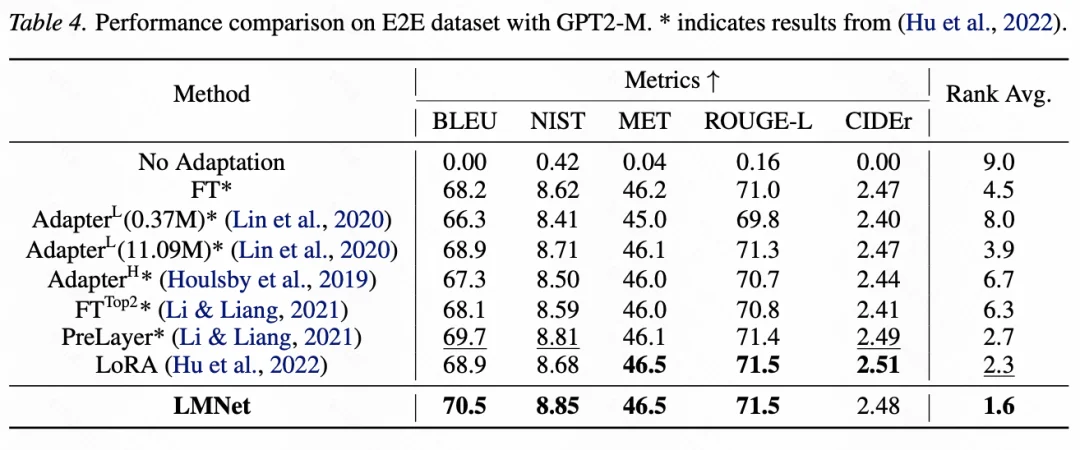
图 6:在 E2E 数据集上用不同的 PEFT 方法微调 GPT2-M 并测试的性能比较
这些数字并不是全文最重要的部分,但它们提供了一个清晰信号:模型之间的可学习通信,确实可能成为提升系统能力的一条有效路径。LMNet 的价值不只在于某个 benchmark 的提升,更在于它证明了一个方向:通信方式本身可以被学习,模型网络可以从最终任务监督中自动形成更有效的信息流。
这项工作提示了一种可能的未来方向:下一代 AI 系统未必只是一个不断扩大的模型,而可能是由多个模型、工具、记忆和反馈模块共同构成的可学习网络。
在这样的系统中,智能不只来自单个模块的能力,也来自模块之间如何连接、如何交流、如何共同适应任务。
“沟通即智能”并不是一句简单的口号,而是对未来 AI 系统形态的一种判断。当语言模型开始学会自己“组网”,人工智能将从单体模型能力的竞争,走向系统组织能力、通信效率和协同学习能力的竞争。
值得注意的是,这一方向与技术已经受到大模型系统应用的国际前沿研究的持续关注。如近期的 Google DeepMind 和 AWS Agentic AI。这些工作也从不同角度说明:模型间通信媒介、通信拓扑和可学习接口,正在成为构建下一代 AI 系统的重要技术方向。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
